Буферы передачи и приема что это такое
Высокий пинг в игре? Лезем в настройки сетевой карты. Часть 2
В этой статье будут рассмотрены настройки сетевой платы, которые теоретически могут снизить высокий пинг в игре, победить лаги и как то повлиять на fps. Из первой части мы поняли, что динамичные многопользовательские онлайн игры используют протокол UDP, поэтому при ее настройке будем это учитывать. Обращаю внимание, что так сбить высокий пинг и убрать лаги получится, если у вас слабый компьютер и "хорошая" сетевуха или наоборот. Играясь с этими параметрами, нужно пробовать переложить нагрузку на то железо, которое у вас не испытывает проблем с производительностью. И итогом всей этой битвы и мучений, может быть станет выигрыш в несколько миллисекунд.Почему пинг высокий и как его понизить?
В первой части (из серии статей) мы пробовали победить высокую сетевую задержку с помощью настройки MTU. В этой рассмотрим и узнаем, какие настройки сетевой платы пригодятся любителям игр.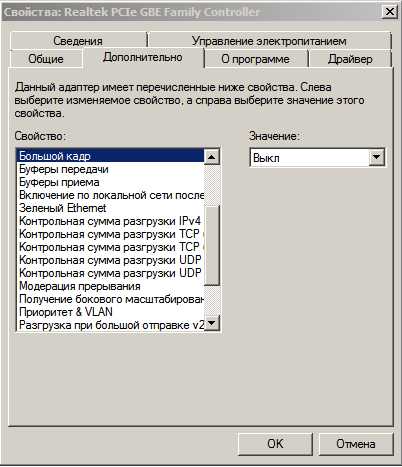 Jumbo Frame - Jumbo Packet - Большой кадр:
Jumbo Frame - Jumbo Packet - Большой кадр:
Использование этого параметра, наверно только гипотетически поможет снизить пинг в играх и наверно какая то выгода будет во время долгих массовых сражений и осад, когда в одну секунду генерируется очень приличное количество трафика. Дело в том, что использование больших кадров должно быть настроено у всех участников взаимодействия, как у клиента и сервера, так и транзитных узлов. Но за пределами вашего провайдера (да и у самого провайдера) mtu всегда примерно равен 1,5 кб плюс\минус десятки байтов. Если использовать его в локальных сетях (где можно точно проконтролировать эту настройку у всех), то там пинг зачастую и так достаточно низкий.
В чем плюс? Если использовать 9 кб у всех участников, вместо 1,5 кб, то для обсчета одного кадра потребуется в 6 раз реже задействовать процессор. Что должно лучше сказаться на прибавке фпс.
В чем минус? Если использовать его только на клиенте, при отсылке на остальных узлах пакет будет фрагментирован, в лучшем случаем на 6 частей, а при mtu <1500 может и на более. Которые в итоге будут переданы на каждый последующий узел, и где он должен попасть на сервер без потерь и корректно собран в один целый. В век высоких технологий, сбор и разбиение проходят быстро, но тем не менее, не всегда возможно предсказать насколько будет загружено оборудование обрабатывающее эти фрагменты. И эта фрагментация и загрузка транзитных узлов и может привести к росту пинга.
Значение: Выкл.
Checksum Offload - IPv4 Checksum Offload - Контрольная сумма разгрузки IPv4:
Если ваш адаптер имеет такую функцию, то включите ее. Это позволит освободить центральный процессор от расчета и проверки контрольных сумм для отправляемых и принимаемых пакетов. Что должно положительно сказаться на фпс в игре. Но бывают и обратные случаи, когда отключение это функции позволяет улучшить пинг и снизить лаги. Так что, попробуйте поиграться с этим параметром, при наличии лагом и скачущего пинга.
Значение: Вкл для Tx и Rx
Speed & Duplex - Link Speed/Duplex Mode - Скорость и дуплекс
Тут нужно проверить, что у вас стоит 10\100\1 Гб дуплекс. При использовании режима полудуплекс, пинг становится выше.
Можете в этом убедиться, переключив режимы и пингануть любой сервер.
Значение: Дуплексный режим
Flow Control - Управление потоком
Данная настройка призвана решать проблему, когда входящий трафик приходит с такой скоростью, что создает угрозу переполнения буфера на сетевом оборудовании и тогда источнику отправляется команда, чтобы он выждал паузу и снова повторил отправку данных, через какой-то промежуток времени. Если же такой команды не послать, то из-за перегрузки часть данных просто потеряется, т.е. в игре это гарантированный лаг. Вроде бы хорошая и правильная и нужная функция, но только для тех кто скачивает большие объемы. В играх как правило трафик приходит не в таком интенсивном режиме. Если же кадр паузы будет послан, то одномоментно увеличится пинг. Т.е. если у вас в играх частые лаги и высокая сетевая задержка, попробуйте поиграться с этим параметром.
Значение: Выключить
Transmit Buffers - Буферы передачи / Receive Buffers - Буферы приема
Зачастую буфер приема имеет в настройках больший размер, так как трафика мы скачиваем больше, чем отдаем. Здесь главное придерживаться правила, что буфер приема минимум должен быть равен 100*mtu. Если mtu=1500 байт, то размер буфера должен быть не меньше 147 кб. Если будет меньше, то в массовых событиях в игре, с генерацией большого количества трафика, возможна потеря пакетов. Прямого влияние на пинг, данные настройки не оказывают. Скорее это касается лагов. Так что убедитесь, что данные параметры выставлены по умолчанию и не имеют слишком малого размера.
Для буфера передачи вполне подойдет заводское значение. Вряд ли на клиенте в игре можно на генерировать столько трафика, чтобы пакеты при этом не поместились в буфер.
TCP/UDP Checksum Offload IPv4/IPv6 - Контрольная сумма разгрузки TCP/UDP IPv4/IPv6
Чтобы узнать, дошел ли пакет до адресата целый и без ошибок, для проверки на другой стороне в него добавляют контрольную сумму, которая рассчитывается на основании данных пакета. Если у вас имеется данная функция в настройке, попробуйте ее включить для обоих типов трафика. Таким образом все вычисления будет проводить не процессор, а сетевой адаптер, что в итоге должно положительно сказаться на фпс в игре.
Значение: Rx & Tx Включить
Interrupt Moderation - Модерация прерывания
При получении одного пакета, сетевой адаптер вызывает прерывание. Когда идет интенсивный обмен трафиком такие прерывания создают нагрузку на процессор. И чтобы снизить ее, придумали накапливать события в течении какого-то времени и после этого вызывать прерывание (IRQ). Таким образом реже задействуя процессор. У такого способа есть свои плюсы, описанный ранее и так же можно сказать, что вся прелесть этой функции раскрывается для тех, кто много качает.
Из минусов, чтобы пакет был обработан, он ожидает, пока отработает таймер. Это то и добавляет пинга в игре.
Значение: Выключить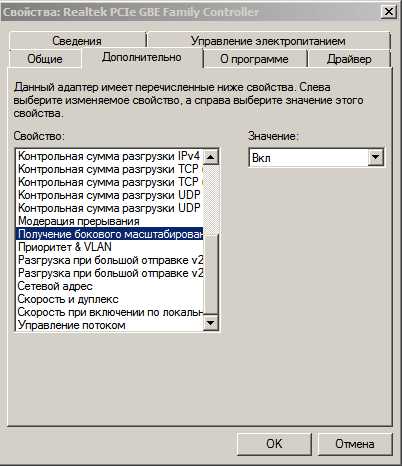 Receive Side Scaling - RSS - Получение бокового масштабирования
Receive Side Scaling - RSS - Получение бокового масштабирования
Это интересный и нужный механизм для обладателей многоядерных процессоров. При включении его, пакеты делятся по потокам и каждый поток может обрабатывать отдельный процессор. Т.е. задействуются все ядра, что должно положительно сказаться на производительности в целом и на пинге в частности. Если эта функция выключена, весь трафик обрабатывается одним ядром.
Но все эти преимущества будут, если драйвер написан без ошибок. Иначе, бывают случаи, когда после включения начинаются проблемы и деградация производительности. Если вы впервые включаете его, внимательно понаблюдайте за сетью какое-то время.
Значение: Включить
Large Send Offload IPv4/IPv6 - Giant Send Offload - Разгрузка при большой отправке IPv4/IPv6
Фрагментацией пакетов данных при отправке будет заниматься сетевой адаптер, а не программное обеспечение. В идеале аппаратное фрагментирование проходит быстрее, меньше задействуется процессор, что в итоге для любителей игр должно положительно сказаться на пинге и фпс.
Есть еще настройка Large Send Offload v2, она выполняет ту же функцию, только для пакетов покрупнее. Иногда ее включение плохо влияет на производительность сети.
Значение: Включить
И в заключении коротко про пинг и представленные настройки
Некоторые параметры у разных производителей называются по-разному. Если вы у себя их не нашли, значит производитель не предусмотрел их настройку.
Вы должны понимать, что рекомендуемые здесь значения ориентированы на снижение пинга. Поэтому для любителей торрентов, данные параметры могут негативно сказаться на производительности и вызвать повышенную нагрузку на систему.
Все манипуляции с настройками сетевого адаптера обязательно проводите поэтапно. Не стоит все увиденое применять на практике сразу и одномоментно. На разных сетевых платах, эти настройки могут показать разное поведение.
Так же конечный результат зависит и от прямоты рук программистов, которые писали драйвера.
Надеюсь эта статья открыла что то новое для вас и помогла, хоть чуть-чуть, снизить высокий пинг в любимой игре.
Продолжение тут: третья и четвертая части
- Подробности
- Опубликовано: 01.09.2016 г.
Сетевые адаптеры настройки производительности | Microsoft Docs
- Время чтения: 11 мин
В этой статье
Область применения: Windows Server 2019, Windows Server 2016, Windows Server (Semi-Annual Channel)Applies to: Windows Server 2019, Windows Server 2016, Windows Server (Semi-Annual Channel)
Используйте сведения в этом разделе для настройки сетевых адаптеров производительности для компьютеров под управлением Windows Server 2016 и более поздних версий.Use the information in this topic to tune the performance network adapters for computers that are running Windows Server 2016 and later versions. Если сетевые адаптеры предоставляют параметры настройки, эти параметры можно использовать для оптимизации пропускной способности сети и использования ресурсов.If your network adapters provide tuning options, you can use these options to optimize network throughput and resource usage.
Правильные параметры настройки для сетевых адаптеров зависят от следующих переменных.The correct tuning settings for your network adapters depend on the following variables:
- сетевой адаптер и набор его функций;The network adapter and its feature set
- Тип рабочей нагрузки, выполняемой серверомThe type of workload that the server performs
- аппаратные и программные ресурсы сервера;The server hardware and software resources
- задачи настройки сервера.Your performance goals for the server
В следующих разделах описывается ряд параметров настройки производительности.The following sections describe some of your performance tuning options.
Включение функций разгрузкиEnabling offload features
Включение функций разгрузки на сетевом адаптере обычно имеет положительный эффект.Turning on network adapter offload features is usually beneficial. Однако сетевой адаптер может оказаться недостаточно мощным для обработки возможностей разгрузки с высокой пропускной способностью.However, the network adapter might not be powerful enough to handle the offload capabilities with high throughput.
Важно!
Не используйте разгрузку задач IPSec функции разгрузки или разгрузку TCP Chimney.Do not use the offload features IPsec Task Offload or TCP Chimney Offload. Эти технологии являются устаревшими в Windows Server 2016 и могут негативно сказаться на производительности сервера и сети.These technologies are deprecated in Windows Server 2016, and might adversely affect server and networking performance. Кроме того, эти технологии могут не поддерживаться корпорацией Майкрософт в будущем.In addition, these technologies might not be supported by Microsoft in the future.
Например, рассмотрим сетевой адаптер с ограниченными аппаратными ресурсами.For example, consider a network adapter that has limited hardware resources. В этом случае включение возможности разгрузки сегментации может снизить максимальную устойчивую пропускную способность адаптера.In that case, enabling segmentation offload features might reduce the maximum sustainable throughput of the adapter. Однако если приемлема пропускная способность, следует включить функции сегментирования разгрузки.However, if the reduced throughput is acceptable, you should go ahead an enable the segmentation offload features.
Примечание
Для некоторых сетевых адаптеров требуется включить разгрузку компонентов независимо для путей отправки и получения.Some network adapters require you to enable offload features independently for the send and receive paths.
Включение масштабирования на стороне приема (RSS) для веб-серверовEnabling receive-side scaling (RSS) for web servers
RSS способно повысить веб-масштабируемость и производительность, когда число сетевых адаптеров меньше количества логических процессоров на сервере.RSS can improve web scalability and performance when there are fewer network adapters than logical processors on the server. Когда весь веб-трафик проходит через сетевые адаптеры, поддерживающие RSS, сервер может обрабатывать входящие веб-запросы с разных соединений одновременно на разных процессорах.When all the web traffic is going through the RSS-capable network adapters, the server can process incoming web requests from different connections simultaneously across different CPUs.
Важно!
Избегайте использования сетевых адаптеров, отличных от RSS, и сетевых адаптеров, поддерживающих RSS, на одном сервере.Avoid using both non-RSS network adapters and RSS-capable network adapters on the same server. Из-за логики распределения нагрузки в RSS и протоколе HTTP, производительность может быть значительно снижена, если сетевой адаптер, не поддерживающий RSS, принимает веб-трафик на сервере с одним или несколькими сетевыми адаптерами, поддерживающими RSS.Because of the load distribution logic in RSS and Hypertext Transfer Protocol (HTTP), performance might be severely degraded if a non-RSS-capable network adapter accepts web traffic on a server that has one or more RSS-capable network adapters. В этом случае необходимо использовать сетевые адаптеры, поддерживающие RSS, или отключить RSS на вкладке Дополнительные свойства в свойствах сетевого адаптера.In this circumstance, you should use RSS-capable network adapters or disable RSS on the network adapter properties Advanced Properties tab.
Чтобы определить, поддерживает ли сетевой адаптер RSS, можно просмотреть сведения RSS на вкладке Дополнительные свойства в свойствах сетевого адаптера.To determine whether a network adapter is RSS-capable, you can view the RSS information on the network adapter properties Advanced Properties tab.
Профили RSS и очереди RSSRSS Profiles and RSS Queues
Стандартный профиль RSS по умолчанию — нумастатик, который отличается от используемого по умолчанию предыдущих версий Windows.The default RSS predefined profile is NUMAStatic, which differs from the default that the previous versions of Windows used. Прежде чем приступить к использованию профилей RSS, ознакомьтесь с доступными профилями, чтобы понять, когда они полезны и как они применяются к сетевой среде и оборудованию.Before you start using RSS profiles, review the available profiles to understand when they are beneficial and how they apply to your network environment and hardware.
Например, если открыть диспетчер задач и проверить логические процессоры на сервере и они будут недостаточно загружены для приема трафика, можно попробовать увеличить число очередей RSS по умолчанию, равное двум, до максимума, поддерживаемого сетевым адаптером.For example, if you open Task Manager and review the logical processors on your server, and they seem to be underutilized for receive traffic, you can try increasing the number of RSS queues from the default of two to the maximum that your network adapter supports. В используемом сетевом адаптере могут быть параметры для изменения числа очередей RSS в драйвере.Your network adapter might have options to change the number of RSS queues as part of the driver.
Увеличение ресурсов сетевого адаптераIncreasing network adapter resources
Для сетевых адаптеров, позволяющих вручную настраивать ресурсы, такие как буферы приема и отправки, следует увеличить выделенные ресурсы.For network adapters that allow you to manually configure resources such as receive and send buffers, you should increase the allocated resources.
В некоторых сетевых адаптерах устанавливаются небольшие буферы приема для экономии выделенной памяти от узла.Some network adapters set their receive buffers low to conserve allocated memory from the host. Это ведет к потере пакетов и снижению производительности.The low value results in dropped packets and decreased performance. Поэтому для сценариев с интенсивным приемом рекомендуется увеличить буфер приема до максимума.Therefore, for receive-intensive scenarios, we recommend that you increase the receive buffer value to the maximum.
Примечание
Если сетевой адаптер не предоставляет настройки ресурсов вручную, он динамически настраивает ресурсы, или для ресурсов задано фиксированное значение, которое нельзя изменить.If a network adapter does not expose manual resource configuration, either it dynamically configures the resources, or the resources are set to a fixed value that cannot be changed.
Включение контроля прерыванийEnabling interrupt moderation
Для управления прерываниями прерываний некоторые сетевые адаптеры предоставляют различные уровни управления прерываниями, различные параметры объединения буфера (иногда отдельно для буферов отправки и получения) или и то, и другое.To control interrupt moderation, some network adapters expose different interrupt moderation levels, different buffer coalescing parameters (sometimes separately for send and receive buffers), or both.
Следует рассмотреть возможность контроля прерываний для рабочих нагрузок, привязанных к ЦП.You should consider interrupt moderation for CPU-bound workloads. При использовании управления прерываниями учитывайте компромисс между экономией ЦП узла и задержкой, а также увеличением экономии ресурсов узла из-за большего количества прерываний и снижения задержки.When using interrupt moderation, consider the trade-off between the host CPU savings and latency versus the increased host CPU savings because of more interrupts and less latency. Если сетевой адаптер не выполняет контроль прерываний, но он предоставляет объединение буферов, можно повысить производительность, увеличив число Объединенных буферов, чтобы освободить больше буферов на отправку или получение.If the network adapter does not perform interrupt moderation, but it does expose buffer coalescing, you can improve performance by increasing the number of coalesced buffers to allow more buffers per send or receive.
Настройка производительности для обработки пакетов с низкой задержкойPerformance tuning for low-latency packet processing
Многие сетевые адаптеры позволяют настраивать параметры для оптимизации системной задержки.Many network adapters provide options to optimize operating system-induced latency. Задержка — это время между обработкой входящего пакета сетевым драйвером и отправкой этого пакета обратно.Latency is the elapsed time between the network driver processing an incoming packet and the network driver sending the packet back. Обычно это время измеряется в микросекундах.This time is usually measured in microseconds. Для сравнения время передачи пакетов на длинные дистанции обычно измеряется в миллисекундах (это на порядок дольше).For comparison, the transmission time for packet transmissions over long distances is usually measured in milliseconds (an order of magnitude larger). Эта настройка не сокращает время прохождения пакета.This tuning will not reduce the time a packet spends in transit.
Ниже приведены некоторые советы по настройке производительности для загруженных сетей, в которых на счету каждая микросекунда.Following are some performance tuning suggestions for microsecond-sensitive networks.
В BIOS компьютера установите значение High Performance (Высокая производительность) и отключите C-состояния.Set the computer BIOS to High Performance, with C-states disabled. Однако имейте в виду, что это зависит от системы и BIOS, и некоторые системы обеспечивают большую производительность, если операционная система управляет электропитанием.However, note that this is system and BIOS dependent, and some systems will provide higher performance if the operating system controls power management. Проверить и настроить параметры управления питанием можно на странице Параметры или с помощью команды powercfg .You can check and adjust your power management settings from Settings or by using the powercfg command. Дополнительные сведения см. в разделе Параметры командной строки Powercfg.For more information, see Powercfg Command-Line Options.
Установите в операционной системе профиль управления электропитанием Высокая производительность.Set the operating system power management profile to High Performance System.
Примечание
Этот параметр не работает должным образом, если BIOS системы имеет значение отключить управление питанием в операционной системе.This setting does not work properly if the system BIOS has been set to disable operating system control of power management.
Включить статические разгрузки.Enable static offloads. Например, включите контрольные суммы UDP, контрольные суммы TCP и отправку параметров большой разгрузки (LSO).For example, enable the UDP Checksums, TCP Checksums, and Send Large Offload (LSO) settings.
Если трафик проходит через несколько потоков, например при получении многоуровневого трафика многоадресной рассылки, включите RSS.If the traffic is multi-streamed, such as when receiving high-volume multicast traffic, enable RSS.
Отключите Управление прерываниями в драйверах сетевых адаптеров, которым требуется самая низкая задержка.Disable the Interrupt Moderation setting for network card drivers that require the lowest possible latency. Помните, что эта конфигурация может использовать больше времени ЦП и представляет компромисс.Remember, this configuration can use more CPU time and it represents a tradeoff.
Обрабатывайте прерывания сетевого адаптера и DPC на основном процессоре, который совместно использует процессорный кэш с ядром, которое используется программой (пользовательским потоком), обрабатывающей пакет.Handle network adapter interrupts and DPCs on a core processor that shares CPU cache with the core that is being used by the program (user thread) that is handling the packet. Для передачи процесса конкретным логическим процессорам можно использовать настройку фиксации ЦП вместе с настройкой RSS.CPU affinity tuning can be used to direct a process to certain logical processors in conjunction with RSS configuration to accomplish this. Использование одного ядра для прерываний, DPC и пользовательского потока ведет к снижению производительности из-за увеличения нагрузки, поскольку ISR, DPC и поток будут конкурировать за ядро.Using the same core for the interrupt, DPC, and user mode thread exhibits worse performance as load increases because the ISR, DPC, and thread contend for the use of the core.
Прерывания управления системойSystem management interrupts
Многие аппаратные системы используют прерывания управления системой (SMI) для различных функций обслуживания, таких как сообщения об ошибках с кодом коррекции ошибок (ECC), поддержка устаревшей совместимости с USB, управление вентилятором и управление питанием, управляемым BIOS Параметры.Many hardware systems use System Management Interrupts (SMI) for a variety of maintenance functions, such as reporting error correction code (ECC) memory errors, maintaining legacy USB compatibility, controlling the fan, and managing BIOS-controlled power settings.
SMI — это прерывание с наивысшим приоритетом в системе и помещает ЦП в режим управления.The SMI is the highest-priority interrupt on the system, and places the CPU in a management mode. Этот режим загружает все остальные действия, в то время как SMI запускает подпрограммы службы прерываний, обычно содержащиеся в BIOS.This mode preempts all other activity while SMI runs an interrupt service routine, typically contained in BIOS.
К сожалению, такое поведение может привести к скачкам задержки 100 микросекунд или более.Unfortunately, this behavior can result in latency spikes of 100 microseconds or more.
Когда необходимо обеспечить минимальную задержку, следует запросить у поставщика оборудования версию BIOS, в которой прерывания SMI имеют наименьший возможный приоритет.If you need to achieve the lowest latency, you should request a BIOS version from your hardware provider that reduces SMIs to the lowest degree possible. Эти версии BIOS часто называются "BIOS с низкой задержкой" или "SMI Free BIOS".These BIOS versions are frequently referred to as "low latency BIOS" or "SMI free BIOS." В некоторых случаях аппаратная платформа не может полностью устранить операции SMI, поскольку они используются для управления важными функциями (например для вентиляторов).In some cases, it is not possible for a hardware platform to eliminate SMI activity altogether because it is used to control essential functions (for example, cooling fans).
Примечание
Операционная система не может управлять SMIs, так как логический процессор работает в специальном режиме обслуживания, что предотвращает вмешательство пользователя операционной системы.The operating system cannot control SMIs because the logical processor is running in a special maintenance mode, which prevents operating system intervention.
Настройка производительности TCPPerformance tuning TCP
Для настройки производительности TCP можно использовать следующие элементы.You can use the following items to tune TCP performance.
Автоматическая настройка окна приема TCPTCP receive window autotuning
В Windows Vista, Windows Server 2008 и более поздних версиях в сетевом стеке Windows для согласования размера окна приема TCP используется функция, называемая режимом автонастройки окна приема TCP.In Windows Vista, Windows Server 2008, and later versions of Windows, the Windows network stack uses a feature that is named TCP receive window autotuning level to negotiate the TCP receive window size. Эта функция может согласовать определенный размер окна приема для каждого подключения TCP во время подтверждения TCP.This feature can negotiate a defined receive window size for every TCP communication during the TCP Handshake.
В более ранних версиях Windows сетевой стек Windows использовал окно приема фиксированного размера (65 535 байт), которое ограничивает общую возможную пропускную способность для подключений.In earlier versions of Windows, the Windows network stack used a fixed-size receive window (65,535 bytes) that limited the overall potential throughput for connections. Общая пропускная способность подключений TCP может ограничивать сценарии использования сети.The total achievable throughput of TCP connections could limit network usage scenarios. Автоматическая настройка окна приема TCP позволяет этим сценариям полностью использовать сеть.TCP receive window autotuning enables these scenarios to fully use the network.
Для окна приема TCP, имеющего определенный размер, можно использовать следующее уравнение для вычисления общей пропускной способности отдельного соединения.For a TCP receive window that has a particular size, you can use the following equation to calculate the total throughput of a single connection.
Общая пропускная способность в байтах = Размер окна приема TCP в байтах * (1/ Задержка подключения в секундах)Total achievable throughput in bytes = TCP receive window size in bytes * (1 / connection latency in seconds)
Например, для соединения с задержкой 10 мс общая пропускная способность составляет только 51 Мбит/с.For example, for a connection that has a latency of 10 ms, the total achievable throughput is only 51 Mbps. Это значение целесообразно для большой корпоративной сетевой инфраструктуры.This value is reasonable for a large corporate network infrastructure. Однако с помощью автонастройки для настройки окна приема подключение может обеспечить полную скорость линии для подключения 1 Гбит/с.However, by using autotuning to adjust the receive window, the connection can achieve the full line rate of a 1-Gbps connection.
Некоторые приложения определяют размер окна приема TCP.Some applications define the size of the TCP receive window. Если приложение не определяет размер окна приема, скорость связи определяется следующим образом:If the application does not define the receive window size, the link speed determines the size as follows:
- Менее 1 мегабит в секунду (Мбит/с): 8 килобайт (КБ)Less than 1 megabit per second (Mbps): 8 kilobytes (KB)
- от 1 Мбит/с до 100 Мбит/с: 17 КБ1 Mbps to 100 Mbps: 17 KB
- от 100 Мбит/с до 10 гигабит в секунду (Гбит/с): 64 КБ100 Mbps to 10 gigabits per second (Gbps): 64 KB
- 10 Гбит/с или более: 128 КБ10 Gbps or faster: 128 KB
Например, на компьютере с установленным сетевым адаптером с 1 Гбит/с размер окна должен быть 64 КБ.For example, on a computer that has a 1-Gbps network adapter installed, the window size should be 64 KB.
Эта функция также обеспечивает полное использование других функций для повышения производительности сети.This feature also makes full use of other features to improve network performance. Эти функции включают остальные параметры TCP, определенные в RFC 1323.These features include the rest of the TCP options that are defined in RFC 1323. С помощью этих функций компьютеры под управлением Windows могут согласовать размеры окна приема TCP, которые меньше, но масштабируются по определенному значению в зависимости от конфигурации.By using these features, Windows-based computers can negotiate TCP receive window sizes that are smaller but are scaled at a defined value, depending on the configuration. Такое поведение упрощает обработку размеров для сетевых устройств.This behavior the sizes easier to handle for networking devices.
Примечание
Может возникнуть проблема, при которой сетевое устройство не соответствует параметру TCP Window Scale, как определено в RFC 1323 и, следовательно, не поддерживает коэффициент масштабирования.You may experience an issue in which the network device is not compliant with the TCP window scale option, as defined in RFC 1323 and, therefore, doesn't support the scale factor. В таких случаях см. статью KB 934430, сетевое подключение завершается сбоем при попытке использовать Windows Vista за устройством брандмауэра или обратитесь в службу поддержки для поставщика сетевых устройств.In such cases, refer to this KB 934430, Network connectivity fails when you try to use Windows Vista behind a firewall device or contact the Support team for your network device vendor.
Проверка и настройка уровня автонастройки окна приема TCPReview and configure TCP receive window autotuning level
Для просмотра или изменения уровня автонастройки окна приема TCP можно использовать команды netsh или командлеты Windows PowerShell.You can use either netsh commands or Windows PowerShell cmdlets to review or modify the TCP receive window autotuning level.
Примечание
В отличие от версий Windows, предшествующих Windows 10 или Windows Server 2019, вы больше не можете использовать реестр для настройки размера окна приема TCP.Unlike in versions of Windows that pre-date Windows 10 or Windows Server 2019, you can no longer use the registry to configure the TCP receive window size. Дополнительные сведения об устаревших параметрах TCPсм. здесь.For more information about the deprecated settings, see Deprecated TCP parameters.
Использование команды Netsh для просмотра или изменения уровня автонастройкиTo use netsh to review or modify the autotuning level
Чтобы проверить текущие параметры, откройте окно командной строки и выполните следующую команду:To review the current settings, open a Command Prompt window and run the following command:
netsh interface tcp show global Выходные данные этой команды должны выглядеть следующим образом:The output of this command should resemble the following:
Querying active state... TCP Global Parameters ----- Receive-Side Scaling State : enabled Chimney Offload State : disabled Receive Window Auto-Tuning Level : normal Add-On Congestion Control Provider : default ECN Capability : disabled RFC 1323 Timestamps : disabled Initial RTO : 3000 Receive Segment Coalescing State : enabled Non Sack Rtt Resiliency : disabled Max SYN Retransmissions : 2 Fast Open : enabled Fast Open Fallback : enabled Pacing Profile : off Чтобы изменить этот параметр, выполните в командной строке следующую команду:To modify the setting, run the following command at the command prompt:
netsh interface tcp set global autotuninglevel=<Value> Примечание
В предыдущей команде <значение> представляет новое значение для уровня автоматической настройки.In the preceding command, <Value> represents the new value for the auto tuning level.
Дополнительные сведения об этой команде см. в разделе команды Netsh для протокола управления передачей интерфейса.For more information about this command, see Netsh commands for Interface Transmission Control Protocol.
Использование PowerShell для просмотра или изменения уровня автонастройкиTo use Powershell to review or modify the autotuning level
Чтобы проверить текущие параметры, откройте окно PowerShell и выполните следующий командлет.To review the current settings, open a PowerShell window and run the following cmdlet.
Get-NetTCPSetting | Select SettingName,AutoTuningLevelLocal Выходные данные этого командлета должны выглядеть следующим образом.The output of this cmdlet should resemble the following.
SettingName AutoTuningLevelLocal ----------- -------------------- Automatic InternetCustom Normal DatacenterCustom Normal Compat Normal Datacenter Normal Internet Normal Чтобы изменить этот параметр, выполните следующий командлет в командной строке PowerShell.To modify the setting, run the following cmdlet at the PowerShell command prompt.
Set-NetTCPSetting -AutoTuningLevelLocal <Value> Примечание
В предыдущей команде <значение> представляет новое значение для уровня автоматической настройки.In the preceding command, <Value> represents the new value for the auto tuning level.
Дополнительные сведения об этих командлетах см. в следующих статьях:For more information about these cmdlets, see the following articles:
Уровни автонастройкиAutotuning levels
Можно настроить автоматическую настройку окна приема на любой из пяти уровней.You can set receive window autotuning to any of five levels. Уровень по умолчанию — Обычная.The default level is Normal. В следующей таблице описаны уровни.The following table describes the levels.
| УровеньLevel | Шестнадцатеричное значениеHexadecimal value | CommentsComments |
|---|---|---|
| Normal (по умолчанию)Normal (default) | 0x8 (коэффициент масштабирования 8)0x8 (scale factor of 8) | Задайте для окна приема TCP значение рост в соответствии с практически всеми сценариями.Set the TCP receive window to grow to accommodate almost all scenarios. |
| Отключено.Disabled | Коэффициент масштабирования недоступенNo scale factor available | Задайте для окна приема TCP значение по умолчанию.Set the TCP receive window at its default value. |
| Restricted (Ограничено)Restricted | 0x4 (коэффициент масштабирования 4)0x4 (scale factor of 4) | Задайте размер окна приема TCP, превышающего значение по умолчанию, но ограничьте такой рост в некоторых сценариях.Set the TCP receive window to grow beyond its default value, but limit such growth in some scenarios. |
| С высоким уровнем ограниченийHighly Restricted | 0x2 (коэффициент масштабирования 2)0x2 (scale factor of 2) | Задайте размер окна приема TCP, превышающего значение по умолчанию, но это очень консервативно.Set the TCP receive window to grow beyond its default value, but do so very conservatively. |
| ПробExperimental | 0xE (коэффициент масштабирования 14)0xE (scale factor of 14) | Задайте для окна приема TCP значение рост в соответствии с экстремальными сценариями.Set the TCP receive window to grow to accommodate extreme scenarios. |
Если для записи сетевых пакетов используется приложение, приложение должно сообщить данные, аналогичные приведенным ниже, для различных параметров автонастройки окна.If you use an application to capture network packets, the application should report data that resembles the following for different window autotuning level settings.
Уровень автонастройки: нормальный (состояние по умолчанию)Autotuning level: Normal (default state)
Frame: Number = 492, Captured Frame Length = 66, MediaType = ETHERNET + Ethernet: Etype = Internet IP (IPv4),DestinationAddress:[D8-FE-E3-65-F3-FD],SourceAddress:[C8-5B-76-7D-FA-7F] + Ipv4: Src = 192.169.0.5, Dest = 192.169.0.4, Next Protocol = TCP, Packet ID = 2667, Total IP Length = 52 - Tcp: [Bad CheckSum]Flags=......S., SrcPort=60975, DstPort=Microsoft-DS(445), PayloadLen=0, Seq=4075590425, Ack=0, Win=64240 ( Negotiating scale factor 0x8 ) = 64240 SrcPort: 60975 DstPort: Microsoft-DS(445) SequenceNumber: 4075590425 (0xF2EC9319) AcknowledgementNumber: 0 (0x0) + DataOffset: 128 (0x80) + Flags: ......S. ---------------------------------------------------------> SYN Flag set Window: 64240 ( Negotiating scale factor 0x8 ) = 64240 ---------> TCP Receive Window set as 64K as per NIC Link bitrate. Note it shows the 0x8 Scale Factor. Checksum: 0x8182, Bad UrgentPointer: 0 (0x0) - TCPOptions: + MaxSegmentSize: 1 + NoOption: + WindowsScaleFactor: ShiftCount: 8 -----------------------------> Scale factor, defined by AutoTuningLevel + NoOption: + NoOption: + SACKPermitted:Уровень автонастройки: отключенAutotuning level: Disabled
Frame: Number = 353, Captured Frame Length = 62, MediaType = ETHERNET + Ethernet: Etype = Internet IP (IPv4),DestinationAddress:[D8-FE-E3-65-F3-FD],SourceAddress:[C8-5B-76-7D-FA-7F] + Ipv4: Src = 192.169.0.5, Dest = 192.169.0.4, Next Protocol = TCP, Packet ID = 2576, Total IP Length = 48 - Tcp: [Bad CheckSum]Flags=......S., SrcPort=60956, DstPort=Microsoft-DS(445), PayloadLen=0, Seq=2315885330, Ack=0, Win=64240 ( ) = 64240 SrcPort: 60956 DstPort: Microsoft-DS(445) SequenceNumber: 2315885330 (0x8A099B12) AcknowledgementNumber: 0 (0x0) + DataOffset: 112 (0x70) + Flags: ......S. ---------------------------------------------------------> SYN Flag set Window: 64240 ( ) = 64240 ----------------------------------------> TCP Receive Window set as 64K as per NIC Link bitrate. Note there is no Scale Factor defined. In this case, Scale factor is not being sent as a TCP Option, so it will not be used by Windows. Checksum: 0x817E, Bad UrgentPointer: 0 (0x0) - TCPOptions: + MaxSegmentSize: 1 + NoOption: + NoOption: + SACKPermitted:Уровень автонастройки: ограниченныйAutotuning level: Restricted
Frame: Number = 3, Captured Frame Length = 66, MediaType = ETHERNET + Ethernet: Etype = Internet IP (IPv4),DestinationAddress:[D8-FE-E3-65-F3-FD],SourceAddress:[C8-5B-76-7D-FA-7F] + Ipv4: Src = 192.169.0.5, Dest = 192.169.0.4, Next Protocol = TCP, Packet ID = 2319, Total IP Length = 52 - Tcp: [Bad CheckSum]Flags=......S., SrcPort=60890, DstPort=Microsoft-DS(445), PayloadLen=0, Seq=1966088568, Ack=0, Win=64240 ( Negotiating scale factor 0x4 ) = 64240 SrcPort: 60890 DstPort: Microsoft-DS(445) SequenceNumber: 1966088568 (0x75302178) AcknowledgementNumber: 0 (0x0) + DataOffset: 128 (0x80) + Flags: ......S. ---------------------------------------------------------> SYN Flag set Window: 64240 ( Negotiating scale factor 0x4 ) = 64240 ---------> TCP Receive Window set as 64K as per NIC Link bitrate. Note it shows the 0x4 Scale Factor. Checksum: 0x8182, Bad UrgentPointer: 0 (0x0) - TCPOptions: + MaxSegmentSize: 1 + NoOption: + WindowsScaleFactor: ShiftCount: 4 -------------------------------> Scale factor, defined by AutoTuningLevel. + NoOption: + NoOption: + SACKPermitted:Уровень автонастройки: очень ограниченныйAutotuning level: Highly restricted
Frame: Number = 115, Captured Frame Length = 66, MediaType = ETHERNET + Ethernet: Etype = Internet IP (IPv4),DestinationAddress:[D8-FE-E3-65-F3-FD],SourceAddress:[C8-5B-76-7D-FA-7F] + Ipv4: Src = 192.169.0.5, Dest = 192.169.0.4, Next Protocol = TCP, Packet ID = 2388, Total IP Length = 52 - Tcp: [Bad CheckSum]Flags=......S., SrcPort=60903, DstPort=Microsoft-DS(445), PayloadLen=0, Seq=1463725706, Ack=0, Win=64240 ( Negotiating scale factor 0x2 ) = 64240 SrcPort: 60903 DstPort: Microsoft-DS(445) SequenceNumber: 1463725706 (0x573EAE8A) AcknowledgementNumber: 0 (0x0) + DataOffset: 128 (0x80) + Flags: ......S. ---------------------------------------------------------> SYN Flag set Window: 64240 ( Negotiating scale factor 0x2 ) = 64240 ---------> TCP Receive Window set as 64K as per NIC Link bitrate. Note it shows the 0x2 Scale Factor. Checksum: 0x8182, Bad UrgentPointer: 0 (0x0) - TCPOptions: + MaxSegmentSize: 1 + NoOption: + WindowsScaleFactor: ShiftCount: 2 ------------------------------> Scale factor, defined by AutoTuningLevel + NoOption: + NoOption: + SACKPermitted:Уровень автонастройки: экспериментальныйAutotuning level: Experimental
Frame: Number = 238, Captured Frame Length = 66, MediaType = ETHERNET + Ethernet: Etype = Internet IP (IPv4),DestinationAddress:[D8-FE-E3-65-F3-FD],SourceAddress:[C8-5B-76-7D-FA-7F] + Ipv4: Src = 192.169.0.5, Dest = 192.169.0.4, Next Protocol = TCP, Packet ID = 2490, Total IP Length = 52 - Tcp: [Bad CheckSum]Flags=......S., SrcPort=60933, DstPort=Microsoft-DS(445), PayloadLen=0, Seq=2095111365, Ack=0, Win=64240 ( Negotiating scale factor 0xe ) = 64240 SrcPort: 60933 DstPort: Microsoft-DS(445) SequenceNumber: 2095111365 (0x7CE0DCC5) AcknowledgementNumber: 0 (0x0) + DataOffset: 128 (0x80) + Flags: ......S. ---------------------------------------------------------> SYN Flag set Window: 64240 ( Negotiating scale factor 0xe ) = 64240 ---------> TCP Receive Window set as 64K as per NIC Link bitrate. Note it shows the 0xe Scale Factor. Checksum: 0x8182, Bad UrgentPointer: 0 (0x0) - TCPOptions: + MaxSegmentSize: 1 + NoOption: + WindowsScaleFactor: ShiftCount: 14 -----------------------------> Scale factor, defined by AutoTuningLevel + NoOption: + NoOption: + SACKPermitted:
Устаревшие параметры TCPDeprecated TCP parameters
Следующие параметры реестра из Windows Server 2003 больше не поддерживаются и не учитываются в более поздних версиях.The following registry settings from Windows Server 2003 are no longer supported, and are ignored in later versions.
- TcpWindowSizeTcpWindowSize
- нумткбтаблепартитионсNumTcbTablePartitions
- максхаштаблесизеMaxHashTableSize
Все эти параметры были расположены в следующем подразделе реестра:All of these settings were located in the following registry subkey:
HKEY_LOCAL_MACHINE \Систем\куррентконтролсет\сервицес\ткпип\параметерсHKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Tcpip\Parameters
Платформа фильтрации WindowsWindows Filtering Platform
В Windows Vista и Windows Server 2008 появилась платформа фильтрации Windows (WFP).Windows Vista and Windows Server 2008 introduced the Windows Filtering Platform (WFP). WFP предоставляет интерфейсы API независимым поставщикам программного обеспечения (ISV) для создания фильтров обработки пакетов.WFP provides APIs to non-Microsoft independent software vendors (ISVs) to create packet processing filters. Например, для брандмауэров и антивирусного ПО.Examples include firewall and antivirus software.
Ссылки на все разделы данного руководства см. в разделе Настройка производительности сетевой подсистемы.For links to all topics in this guide, see Network Subsystem Performance Tuning.
Настройка сетевого адаптера для улучшения интернета
Иногда при подключении интернета или использовании ресурсов локальной сети возникают проблемы. Могут вылезать ошибки подключения, получения IP адресов или конфигурации сетевого оборудования. Внутри компьютера или ноутбука, функцией подключения к локальной или глобальной сети, занимается сетевой адаптер. В статье мы как раз и поговорим про настройку сетевого адаптера для улучшения связи в интернете. Инструкция будет ходовая для всех версий Windows 7, 8 и 10.
Более подробная настройка
Мне постоянно приходят письма с вопросами – как более детально настроить сетевой адаптер для меньшего пинга в играх, для лучшего просмотра кино и большей скорости скачивания. Поэтому я решил написать более детальную статью. Ну, поехали! По идее она настраивается автоматически под рациональное использование ресурсов системы и самого устройства. Но конфигурацию можно корректировать под свои нужды.
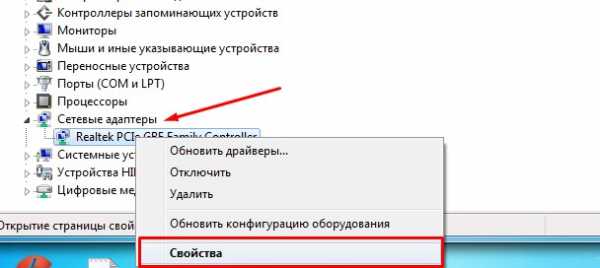
И так нажимаем одновременно на клавишу «R» и «WIN». Далее прописываем «mmc devmgmt.msc» и жмём «ОК». Теперь находим раздел «Сетевые адаптеры» и далее переходим в свойства того устройства, который вы хотите настроить.
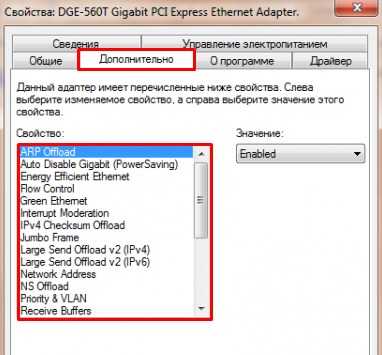
Переходим во вкладку «Дополнительно». И так смотрите, у нас есть определённые свойства, которые мы можем включать (Enebled) или выключать (Disable). На новых версиях «Виндовс» может быть написано «Вкл» или «Выкл». А теперь разбёрем каждое свойство:
ВНИМАНИЕ! Параметры адаптера могут в какой-то степени улучшить показатели, в каком-то моменте ухудшить. Изменяя установки сетевого адаптера, лучше возьмите листочек и выпишите – что именно вы изменили, чтобы в случаи чего вернуть параметры обратно. Также я рекомендую скачать последнюю версию драйвера для вашей сетевой карты или Wi-Fi модуля и установить его. Только после этого заходим в характеристики
- ARP Offload – данная функция включена автоматом. Позволяет игнорировать все ARP запросы. Нужна в качестве защиты. Но иногда в некоторых организациях ее включают для более детальной настройки сети.
- Large Send Offload IPv4/IPv6 – Giant Send Offload – функция перекладывает фрагментацию пакетов именно на адаптер. Включаем обязательно, чтобы снизить нагрузку на центральный процессор.
- Auto Disable Gigabit – если у вас роутер или коммутатор подключен с 4 жилами – 100 Мбит в секунду, то выключаем эту функцию. Она включает и отключает поддержку 1 Гбита. Если вы пользуетесь кабелями по 100 Мбит её можно также отключить. Для роутеров с портом на 1 Гбит – включаем.
- Energy Efficient Ethernet – включает энергосбережение – можно включить на ноутбуках, но если скорость станет ниже или будут проблемы с интернетом – сразу выключаем. Для игроманов – вообще ничего по энергосбережению включать не нужно, так как при этом будет сильно садиться показатель производительности обработки сетевого трафика.
- Flow Control – если пакеты данных не успели обработаться они стают в очереди. При этом на сервер отсылается команда, чтобы он подождал с отправкой данных. Так как если будет переполнен буфер памяти сетевой карты, информация может потеряться. В общем если сильные лаги, тормоза при просмотре видео – можете включить.
- Network Address – виртуальный МАК-адрес. Можно поменять, но бессмысленно, так как физический МАК остается. Этот пункт игнорируем.
- TCP/UDP Checksum Offload IPv4/IPv6 (контрольная сумма) – для обработки контрольной суммы будет выступать процессор, а не сетевая карта. Нужно включать, если есть интенсивная передача пакетов. Опять же для игр может уменьшить нагрузку на сетевую карту и уменьшить лаги. (Rx & Tx Включить)
- Transmit Buffers — это как раз тот самый буфер. Если будет сильно маленькое значение могут быть лаги в играх, так что лучше выставить значение по умолчанию – 147.
- Green Ethernet – опять сокращение энергопотребление, на ПК эту функцию лучше выключить. На ноутбуках – по ситуации.
- TCP Checksum Offload (IPv4)/ (IPv6) – Та же контрольная сумма, но для TCP. Ставим в режим «Вкл».
- Interrupt Moderation – если много качаете, включите. Если много играете, может повышать пинг в игре, из-за простоя пакетов – тогда вырубаем.
- Receive Side Scaling – RSS – для обработки нескольких потоков сразу всеми свободными ядрами процессора. Нужно для многоядерных процессоров. Если функция выключена, то все потоки по очереди будут обрабатываться одним ядром. В общем будут лаги и прерывания. Если при включении вы видите, что стало ещё хуже, значит нужно обновить драйвер на адаптер. Качаем только с официального сайта. Вообще это свойство обязательно включается по умолчанию.
- Priority & VLAN – при отправке пакета дополнительно записываем информацию, о важности и приоритете пакета. Можно включить. Если будут лаги и тормоза – выключаем.
- WOL & Shutdown Link Speed – стандартная скорость коннекта при отключении. Ставим на сотку.
- NS Offload – Включаем. Таким образом соседские Wi-Fi сети при отправке запроса к вам, не будут получать ответа.
- Jumbo Frame – Jumbo Packet – я бы эту функцию выключил, так как она снижает частоту обработки пакетов в 6 раз.
- Speed & Duplex – выставляет режим в «Дуплекс» или «Полудуплекс». Первый позволяет одновременно принимать и отправлять данные – ставим, если играем. Второй режим может одновременно принимать или отправлять данные. Ставим второй, если много качаем. Но честно сказать, полудуплекс сильно снижает нормальную работу очень многих сервисов. Поэтому лучше всегда ставить или «Автосогласование» или «Дуплекс».
- Wake on pattern match и Wake on Magic Packet – включаем.
- UDP Checksum Offload (IPv6)/ (IPv4) – включает обработку контрольной суммы пакетов UDP. Включаем для обработки процессором, а не «сетевухой».
После изменения, следует перезагрузить компьютер или ноутбук, чтобы некоторые изменения вступили в силу. Установки сетевого адаптера всегда можно откатить обратно, самое главное не потеряйте тот листок с настройками.
ПРОСЬБА! Если я что-то не указал, или написал что-то не так – пишите смело в комментариях свои исправления или замечания, буду рад поучиться чему-то у своих читателей.
Настройка сетевого адаптера » Полезные советы по работе с компьютером и не только:)

Интернет - это лучшее изобретение человечества, он объединяет более 35% населения Земли, а также открывает неограниченные возможности для обучения, работы, отдыха и общения. В вашем компьютере он появляется при помощи сетевого адаптера, имеющего беспроводной(Wi-Fi) или проводной интерфейс. В этой статье я расскажу о настройке адаптера для подключения к сети.
Есть несколько типов подключения интернета:
- Телефонная линия
- DSL, кабельная сеть или электропроводка
- Мобильная связь (2G,3G,4G - LTE)
- Оптоволокно
- Спутниковый интернет
Каждый из них имеет свои специфические особенности, однако компьютер чаще всего подключается при помощи обычной витой пары - кабеля RJ-45, либо при помощи Wi-Fi соединения с роутером(который, в свою очередь, тоже работает через витую пару или USB-модем).
Настройка. Так как большинство пользователей использует Windows 7, то рассказывать я буду на ее примере.
Для этого мы переходим в Панель управления -> Сеть и Интернет -> Центр управления сетями и общим доступом, затем слева в меню выбираем Изменение параметров адаптера.
Здесь Вы можете увидеть список всех адаптеров компьютера и их статус подключения, включая Bluetooth-адаптеры, а также виртуальные адаптеры типа Hamachi.
Обычное подключение через витую пару(без роутеров, модемов)

Кабель "Витая пара" - RJ-45 - 8P8C
Тут также есть 2 варианта: Вам необходимо настроить соединение и каждый раз выполнять подключение либо Ваш провайдер поддерживает технологию DHCP и Вам просто необходимо воткнуть кабель в разьем.
В зависимости от Вашего варианта нужно правильно настроить адаптер.
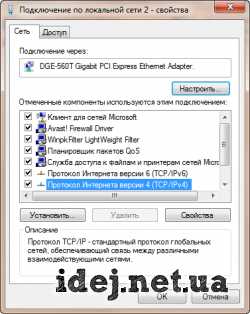
Вариант 1
Заходим в список адаптеров. Выбираем нужный(Подключение по локальной сети ...) и нажимаем на нем правую клавишу мыши(ПКМ), здесь выбираем Свойства. В открывшемся списке выбираем компомнент Протокол Интернета версии 4 и нажимаем кнопку Свойства. Сюда необходимо вписать настройки, выданные Вашим оператором.
Вариант 2
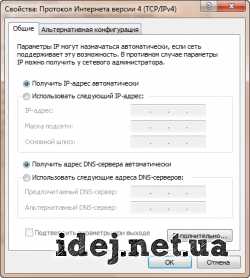
Операция аналогичная Варианту 1, только в свойствах протокола необходимо установить флажки Получить IP-адрес автоматически, Получить адрес DNS-сервера автоматически.
Подключение при помощи роутера
Обычно роутер имеет 5 разьемов(4 LAN и 1 WAN). Кабель от интернета вы подключаете в WAN порт(он отделен от остальных), а затем при помощи второго кабеля/Wi-Fi адаптера соединяете роутер и компьютер. После этого (Смотрите Вариант 2 в подключении через витую пару), в адаптере Wi-Fi эти настройки стоят по-умолчанию.
Для последующей настройки интернета Вы заходите по локальному адресу роутера(192.168.0.1 или 192.168.1.1 - по-умолчанию) и выполняете необходимые действия.
Как настроить роутер Asus Вы можете прочитать в этой статье - https://idej.net/peripheral/44-kak-nastroit-router-asus.html
Остальные типы я расписывать не буду, все вопросы можете задать в комментариях.
Теперь детальнее о настройках адаптера
Чтобы увидеть эти настройки надо зайти в список адаптеров, нажать ПКМ на нужном адаптере, выбрать Свойства, затем под строкой с полным именем адаптера нажать кнопку Настроить. Здесь перейти на вкладку Дополнительно.
В основном, свойства одинаковы у всех адаптеров, однако все же есть небольшая разница.
Я буду рассказывать на примере D-Link DGE-560T.
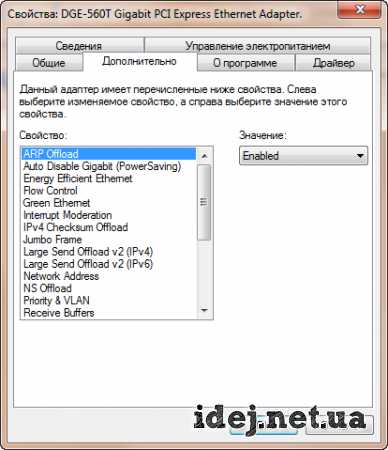
Ниже будет таблица с указанием имени свойства и его описанием.
| Название свойства | Описание | Значения |
| ARP Offload - ARP Разгрузка | Функция позволяет не включать адаптер для ответа на ARP запрос(определение MAC-адреса по IP) | Disable - функция отключена. Enable - адаптер не включается для ответа на запрос. |
| Auto Disable Gigabit (Powersaving) - Автоотключение скорости в 1 Гбит/С | Функция энергосбережения - отключает гигабитную скорость при переподключении кабеля. | Disable - функция выключена. Re-Link, Battery - отключение при работе от батареи. Re-Link, Battery or AC - отключается всегда. |
| Energy Efficient Ethernet - Энергоэффективный интернет | Сокращение энергопотребления адаптера. | Disable - функция отключена. Enable - включено энергосбережение. |
| Flow Control - Управление потоком | Специальная технология притормаживания потока данных, если адаптер не успел обработать предыдущую информацию. Увеличивает быстродействие сети. | Disable - функция отключена. Enable - включено упр. потоком. |
| Green Ethernet - Зеленый интернет | Сокращение энергопотребления адаптера. | Disable - функция отключена. Enable - включено энергосбережение. |
| Interrupt Moderation - Координация прерываний | Технология, которая позволяет прерывать поток для обработки всего один раз вместо нескольких. Снижает нагрузку на ЦП. | Disable - функция отключена. Enable - включено упр. потоком. |
| IPv4 Checksum Offload - Контрольная сумма разгрузки IPv4 | Если опция включена, рассчитывание контрольной суммы файла при отправке(Tx) и принятии(Rx) выполняет сам адаптер. Снижает нагрузку на ЦП. | Disable - функция отключена. Rx Enabled - функция включена для принятия файлов. Tx Enabled - функция включена для отправки файлов. Rx & Tx Enabled - функция включена для отправки и принятия файлов. |
| Jumbo Frame - Большой кадр | Данная настройка увеличивает стандартный размер кадра передаваемых данных. Увеличивает быстродействие сети, когда большие кадры составляют основную часть трафика. | Disable - функция отключена. Стандратное значени. xKB MTU - функция включена, где X - длина большого кадра в КБ. |
| Large Send Offload v2 (IPv4) - Разгрузка при большой отправке (IPv4) | Включает функцию фрагментирования пакетов данных. Фрагментирование происходит за счет адаптера. Увеличивается быстродействие сети, снижается нагрузка на ЦП. | Disable - функция отключена. Enable - включено фрагментирование. |
| Large Send Offload v2 (IPv6) - Разгрузка при большой отправке (IPv6) | Все тоже самое, только для протокола IPv6. | Disable - функция отключена. Enable - включено фрагментирование. |
| Network Address - Сетевой адрес | Позволяет сменить виртуальный MAC-адрес устройства, аппаратный(физический) MAC-адрес не меняется. | Отсутствует - функция отключена. Значение - необходимо ввести нужный MAC-адрес. |
| NS Offload - NS разгрузка | Функция позволяет не включать адаптер для ответа на NS запрос(протокол обнаружения соседей). | Disable - функция отключена. Enable - адаптер не включается для ответа на запрос. |
| Priority & VLAN - Приоритет и VLAN | Помимо основной информации добавляет информацию о приоритете пакета и идентификатор VLAN в Ethernet-кадр. | Disable - запрещает аппаратное тегирование VLAN. Enable - разрешает аппаратное тегирование VLAN. |
| Receive Buffers - Буферы приема | Данное свойство задает кол-во буферов памяти при приеме адаптером какой-либо информации. При увеличении значения увеличивается производителсть адаптера, однако также увеличивается расход системной памяти. | Можно задать значения от 1 до ...(В зависимости от адаптера.У меня до 512). |
| Receive Side Scaling(RSS) - Получение бокового масштабирования | Механизм распределения нагрузки, при котором распределение пакетов TCP может происходить на нескольких ядрах CPU. | Disable - запрещает RSS. Enable - разрешает RSS. |
| Shutdown Wake-On-Lan(WOL) - Включение по локальной сети после отключения | Разрешает или запрещает функцию включения компьютера по сети через адаптер. | Disable - запрещает WOL. Enable - разрешает WOL. |
| Speed & Duplex - Скорость и дуплекс | Позволяет выставить нужную скорость соединения и режим паралелльного приема\передачи данных. Дуплекс - устройство одновременно принимает и передает информацию. Полудуплекс - устройство либо передает, либо принимает информацию. | Auto Negotiation - автосогласование с сетевым устройством. 10/100Mbps / Half/Full Duplex, 1.0 Gbps/Full Duplex - Режимы работы. |
| TCP Checksum Offload (IPv4) - Контрольная сумма разгрузки TCP (IPv4) | Позволяет адаптеру проверять контрольную сумму для пакетов TCP.Увеличивается быстродействие сети, снижается нагрузка на ЦП. | Disable - функция отключена. Enable - включено фрагментирование. |
| TCP Checksum Offload (IPv6) - Контрольная сумма разгрузки TCP (IPv6) | Позволяет адаптеру проверять контрольную сумму для пакетов TCP.Увеличивается быстродействие сети, снижается нагрузка на ЦП. | Disable - функция отключена. Enable - включено фрагментирование. |
| Transmit Buffers - Буферы передачи | Данное свойство задает кол-во буферов памяти при передачи адаптером какой-либо информации. При увеличении значения увеличивается производителсть адаптера, однако также увеличивается расход системной памяти. | Можно задать значения от 1 до ...(В зависимости от адаптера.У меня до 128). |
| UDP Checksum Offload (IPv4) - Контрольная сумма разгрузки UDP (IPv4) | Позволяет адаптеру проверять контрольную сумму для пакетов UDP.Увеличивается быстродействие сети, снижается нагрузка на ЦП. | Disable - функция отключена. Enable - включено фрагментирование. |
| UDP Checksum Offload (IPv6) - Контрольная сумма разгрузки UDP (IPv6) | Позволяет адаптеру проверять контрольную сумму для пакетов UDP.Увеличивается быстродействие сети, снижается нагрузка на ЦП. | Disable - функция отключена. Enable - включено фрагментирование. |
| Wake on Magic Packet | Дополнительная настройка Wake-On-Lan | Disable - функция отключена. Enable - функция включена. |
| Wake on pattern match | Дополнительная настройка Wake-On-Lan | Disable - функция отключена. Enable - функция включена. |
| WOL & Shutdown Link Speed - Скорость при включении по локальной сети после отключения | Определяет начальную скорость соединения полсе Wake-On-Lan | 10Mbps First, 100Mbps First - устанавливает начальную скорость 10/100 Мбит/с |
У вас остались вопросы? Вы хотите дополнить статью? Вы заметили ошибку? Сообщите мне об этом ниже, я обязательно Вас услышу!
Если Вам помогла данная статья, то напишите об этом в комментариях. И не забывайте делиться статьей со своими друзьями в соц.сетях;)
Дополнительные настройки драйвера для серверных сетевых адаптеров...
Настройки на вкладке « Дополнительно » позволяют настроить, как адаптер управляет маркировкой пакетов QoS, крупными кадрами, разгрузкой и другими возможностями.
Эта страница не относится к адаптерам с названием Pro/10 . Дополнительные настройки для этих адаптеров см. в разделе « Расширенные настройки серверных сетевых адаптеров Intel® PRO/10GbE».
| Примечание |
|
Щелкните или тему, чтобы узнать подробности:
Управление потокомУправление потоком позволяет адаптерам генерировать или реагировать на кадры управления потоком, которые помогают регулировать сетевой трафик. Вы можете настроить управление потоком на вкладке « Параметры производительности» при установке Intel® PROSet для диспетчера устройств Windows.
Партнер по связыванию может стать перегруженным, если входящие кадры приходят быстрее, чем устройство может их обработать. Кадры отбрасываются до тех пор, пока не передается условие перегрузки. Механизм управления потоком устраняет эту проблему и исключает риск потери кадров.
Если возникает ситуация перегрузки, устройство генерирует кадр управления потоком. Перед повторной передачей партнеру-партнеру по передаче данных необходимо прекратить передачу данных.
| Примечание | Чтобы воспользоваться преимуществами адаптеров, партнеры по связи должны поддерживать фреймы управления потоком. |
| Используемый | ПРИЕМ и передача включены |
| Спектр | Отключено: управление потоком не осуществляется. Прием и передача включены: адаптер генерирует и реагирует на кадры управления потоком. RX включен: адаптер приостанавливает передачу данных, когда он получает кадр управления потоком от партнера по работе с каналом связи. TX включен: адаптер генерирует кадр управления потоком, когда его очередь Receive достигает заранее установленного ограничения. |
Разделение данных в верхней части позволяет адаптеру разделить информацию из входящего пакета таким образом, что ЦП не должен обрабатывать весь пакет. Это действие разбиения сокращает использование ЦП.
| Mac | Windows Server 2008 * |
| Используемый | Пользу |
| Спектр | Отключено, включено |
Контроль прерываний позволяет адаптеру умеренно отрывать работу.
При поступлении пакета адаптер генерирует прерывание, которое позволяет драйверу обрабатывать пакет. При увеличении скорости компоновки повышается количество прерываний, а также увеличивается использование ресурсов процессора. Это приводит к ухудшению производительности системы. Когда вы включите контроль прерываний, скорость прерываний ниже, а результат — выше производительность системы.
| Mac | Windows Server 2008 |
| Используемый | Пользу |
| Спектр | Отключено, включено |
Частота контроля прерываний устанавливает частоту, с которой контроллер является умеренным, или замедляет создание прерываний. Это помогает оптимизировать пропускную способность сети и использование ЦП. Значение по умолчанию (Адаптивное) регулирует частоту прерывания динамически, в зависимости от типа трафика и использования сети. Выбор другого параметра может повысить производительность сети и системы в некоторых конфигурациях. Вы можете настроить частоту контроля прерываний в разделе «Свойства: Параметры производительности» , если установлен Intel® PROSet для диспетчера устройств Windows.
Без контроля прерываний использование ресурсов процессора возрастает при увеличении скорости передачи данных, поскольку система должна обрабатывать большее количество прерываний. Благодаря управлению прерываниями сетевой драйвер накапливает прерывания и отправляют одно прерывание, а не серию прерываний. При повышении скорости передачи данных высокая скорость обработки данных может повысить производительность системы. При низкой скорости передачи данных более низкий уровень контроля прерываний является предпочтительным, так как отложенные прерывания вызывают задержки.
| Используемый | Средство |
| Спектр | Адаптивные, высокие, низкие, средние, Выкл. |
Разгрузка контрольной суммы IPv4 позволяет адаптеру проверять контрольную сумму TCP/IP на полученных пакетах (RX) и оценивать контрольную сумму по передаваемым пакетам (TX). Вы можете настроить отправку контрольной суммы IPv4 в разделе « варианты настройки разгрузки TCP/IP» в случае установки Intel® PROSet для диспетчера устройств Windows. Эта функция позволяет повысить производительность TCP/IP и сократить использование ЦП. При отключенном разгрузке операционная система вычисляет и проверяет контрольную сумму TCP/IP.
| Используемый | ПРИЕМ и передача включены |
| Спектр | Отключено, RX и TX включен, RX включен, TX включен |
Включает в себя большие возможности для пакетов TCP/IP. Когда большие пакеты занимают наибольшее количество трафика и могут допускать больше задержек, пакеты крупных размеров могут сократить загрузку ЦП и повысить эффективность работы в сети. Стандартный размер кадра Ethernet составляет 1514 байт, в то время как в крупных кадрах может содержаться 4088 или 9014 байт. Доступные настройки зависят от конкретного адаптера.
Пакеты крупных размеров можно использовать только в том случае, если устройства в сети поддерживают один и тот же размер кадра. При настройке крупных фреймов на других сетевых устройствах имейте в о том, что сетевые устройства рассчитывают крупные размеры фрейма по-другому. Некоторые устройства включают информацию о заголовках в размерах кадров, а другие — нет.
| Примечание | Адаптеры Intel не включают информацию о заголовках в размер кадра. |
| Используемый | Невозможно |
| Спектр | Отключено (1514), 4088 и 9014 байт (Установите переключатель в 4 байт выше для CRC, а 4 байта — при использовании виртуальных ЛС. или маркировка пакетов QoS) |
IPv4-разгрузка большого размера (IPv4) устанавливает адаптер, чтобы отгрузить задачу сегментации сообщений TCP в допустимые кадры Ethernet. Если на компьютере установлено Intel® PROSet для диспетчера устройств, можно настроить отгрузку больших приемов в свойствах « варианты разгрузки TCP/IP» .
Поскольку аппаратное обеспечение адаптера может завершить сегментацию данных гораздо быстрее, чем по операционной системе, эта функция может повысить производительность передачи данных. Кроме того, адаптер использует меньше ресурсов ЦП.
| Mac | Windows Server 2008 |
| Используемый | Пользу |
| Спектр | Отключено, включено |
Разгрузка большой отправки (IPv4) и разгрузка больших отправок (IPv6) позволяет адаптеру отгрузить задачу сегментации сообщений TCP в допустимые кадры Ethernet.
Поскольку аппаратное обеспечение адаптера может завершить сегментацию данных гораздо быстрее, чем по операционной системе, эта функция может повысить производительность передачи данных. Кроме того, адаптер использует меньше ресурсов ЦП.
| Mac | Windows Server 2008 |
| Используемый | Пользу |
| Спектр | Отключено, включено |
Локально администрируемый адрес переопределяет начальный MAC-адрес с помощью назначенного пользователем MAC-адреса. Чтобы ввести новый сетевой адрес, введите в это поле 12-значное шестнадцатеричное число.
| Используемый | Удаление |
| Спектр | 0000 0000 0001-FFFF FFFF FFFD Вызван
|
| Примечание | В команде Intel® PROSet использует одно из следующих:
Intel PROSet не использует адаптер ЛАА, если:
|
Регистрация события состояния связи позволяет регистрировать следующие изменения состояния связи в журнале системных событий:
- LINK_UP_CHANGE
Указывает, что адаптер установил ссылку. - LINK_DOWN_CHANGE
Указывает, что адаптер потерял связь. - LINK_DUPLEX_MISMATCH
Указывает на несоответствие дуплексов между адаптером и партнером по связи
Чтобы узнать о проблемах с подключением, перейдите на вкладку « скорость линии » и запустите диагностику. Вкладка «скорость линии» и средство диагностики доступны только в том случае, если установлена система Intel® PROSet для диспетчера устройств Windows.
Прерывания с низким уровнем задержекФункция прерывания с низким уровнем задержек позволяет адаптерам обходиться за прерывание и генерировать прерывание при поступлении определенных пакетов TCP. Затем система может обработать пакет быстрее. Некоторые приложения имеют более быстрый доступ к сетевым данным благодаря снижению задержек при работе с данными.
Intel PROSet для Windows Device Manager должен быть установлен с целью обеспечения конфигурации прерываний низкого уровня задержек. Вы можете настроить свойства прерываний низкого уровня задержек в свойствах « Параметры производительности ». Чтобы использовать прерывания с низким уровнем задержек, установите флажок « использовать прерывания низкого уровня задержек » и выберите один из следующих вариантов.
- Используйте для пакетов с флагом TCP ПШ: Любые входящие пакеты с флагом TCP ПШ инициируют мгновенное прерывание. На отправляющем устройстве устанавливается флаг ПШ.
- Использовать для этих TCP-портов: Каждый пакет, полученный на определенных портах, инициирует немедленное прерывание. Вы можете указать до восьми портов.
| Примечание | Если вы включите прерывания с низким уровнем задержек, можно увеличить загрузку процессора системы. |
Разгрузка TCP-сегментации позволяет адаптеру отгрузить задачу сегментации сообщений TCP в допустимые кадры Ethernet. Вы можете настроить разгрузку TCP-сегментации в свойствах « варианты разгрузки TCP/IP» , если установлено Intel® PROSet для диспетчера устройств Windows.
Поскольку аппаратное обеспечение адаптера выполняет сегментацию данных гораздо быстрее по сравнению с программным обеспечением операционной системы, эта функция может повысить производительность передачи данных. Кроме того, адаптер использует меньше ресурсов ЦП.
| Используемый | Вход |
| Спектр | Выкл., вкл. |
Приоритет и виртуальная ЛС позволяют отправлять и принимать промаркированные пакеты IEEE 802.3 AC, в том числе:
- Метки 802.1 p QoS (качество обслуживания) для пакетов с метками приоритета
- 802.1ные метки q для VLAN
Если эта функция включена, размеченные тегами пакеты используют настройки очередей, определенные определением уровня приоритета операционной системы. Приоритет & VLAN автоматически включается, когда вы устанавливаете виртуальную ЛС на вкладке VLAN. Запрещено отключать маркировку, поскольку для VLAN требуется маркировка.
| Примечание | Для настройки VLAN на сетевых адаптерах Intel® необходимо установить Intel® PROSet для Windows Device Manager и расширенные сетевые сервисы (ANS). |
| Используемый | Приоритет & VLAN включен |
| Спектр | Приоритет & VLAN отключен, приоритет & VLAN включен, приоритет включен, виртуальная ЛС активирована |
Устанавливает количество буферов приема, используемых адаптером при копировании данных в память. Увеличение этого значения может повысить производительность, но потребляет системную память. Вы можете настроить буферы приема в разделе «Свойства: Параметры производительности» , если установлен Intel® PROSet для диспетчера устройств Windows.
Вы можете увеличить количество буферов приема, если вы заметите значительное снижение производительности полученного трафика. Если при получении производительности не возникает проблемы, используйте настройки по умолчанию.
| Используемый | 512 |
| Спектр | 128 – 2048 при увеличении числа 64 |
Масштабирование на стороне приема (RSS) позволяет обрабатывать TCP-подключения по нескольким процессорам или ядрам процессора. Если адаптер не поддерживает RSS или если ваша операционная система не поддерживает его, Настройка RSS не отображается.
| Используемый | Пользу |
| Спектр | Отключено, включено |
Очереди масштабирования на стороне приема выделяют пространство очереди для буферизации транзакций между сетевым адаптером и процессором. Конфигурация очередей не поддерживается всеми адаптерами, поддерживающими RSS-канал. Количество поддерживаемых очередей варьируется в зависимости от адаптера и операционной системы. Вы можете использовать только настройки адаптера и операционной системы.
| Используемый | 2 очереди |
| Спектр | 1, 2 или 4 очереди |
Дополнительную информацию о масштабировании на стороне приема см. в руководстве пользователя .
Разгруженных контрольных сумм TCP (IPv4)Разгруженных контрольных сумм TCP и разгруженных контрольных сумм TCP (IPv6) позволяют адаптеру вычислять (TX) или проверять (RX) контрольную сумму TCP пакетов. Вы можете настроить отгрузку контрольных сумм TCP в свойствах « варианты разгрузки TCP/IP» , если установлена система Intel® PROSet для диспетчера устройств Windows. Эта функция может повысить производительность и сократить загрузку ЦП. С включенной разгрузкой адаптер вычисляет или проверяет контрольную сумму для операционной системы.
| Mac | Все для IPv4, Windows Server 2008 для IPv6 |
| Используемый | ПРИЕМ и передача включены |
| Спектр | Отключено, RX и TX включен, RX включен, TX включен |
Устанавливает количество буферов передачи, используемых адаптером при копировании данных в память. Увеличение этого значения может повысить производительность передачи данных, но также потребляет системную память. Вы можете настроить буферы передачи в разделе «Свойства: Параметры производительности» , если установлен Intel® PROSet для диспетчера устройств Windows.
Вы можете выбрать увеличение количества буферов передачи, если вы заметите значительное снижение производительности передаваемого трафика. Если производительность передачи данных не является проблемой, используйте настройки по умолчанию.
| Используемый | 512 |
| Спектр | 128 — 16384 с шагом в 64 |
Разгруженных контрольных сумм по протоколу UDP (IPv4) и разгруженных контрольных сумм UDP (IPv6) позволяют адаптеру вычислять (TX) или проверять (RX) контрольную сумму UDP для пакетов. Вы можете настроить отправку контрольных сумм UDP в свойствах « варианты разгрузки TCP/IP» в случае установки Intel® PROSet для диспетчера устройств Windows. Эта функция может повысить производительность и сократить загрузку ЦП. С включенной разгрузкой адаптер вычисляет или проверяет контрольную сумму для операционной системы.
| Используемый | ПРИЕМ и передача включены |
| Спектр | Отключено, RX и TX включен, RX включен, TX включен |
Компьютеры и Интернет
Я испытывал серьезные проблемы с производительностью сети в течение долгого времени и никогда не мог определить источник этих проблем. CS:GO была практически не играбельной, потому что вряд ли были когда-либо зарегистрированы в качестве таковых, хотя я был на 200% уверен, я справился с выстрелом в голову. И в последнее время в естественном отборе 2 (в ns2), атакуя врага не получилось его убить. Кто-то из команды разработчиков в ns2 и ТАВ в ns2 член клана (ТАВ DCDarkling) предложил проверить сетевую статистику игры (вы можете включить её в большинстве игр, открыв меню консоли в игре и с помощью команды “net_stats 1”, чтобы включить пакет статистики).
В статистике отобразилась большая потеря пакетов. И я придумал довольно простое решение без необходимости смены провайдера, так как изначально предложили другие люди. Я использую сетевую карту Intel LAN на моём ПК с чипсетом x99. И всё что я должен сделать, чтобы исправить проблемы было изменить дополнительные параметры для неё. Я помню такие же или аналогичные настройки на Marvell и контроллерах Realtek, поэтому вещи очень похожи.

Дело в том, что все эти технологии/настройки сетевых адаптеров обеспечивают надежность передачи данных за счет увеличения задержки. Что само по себе не является проблемой для обычных загрузок, но очень плохо для онлайн-игр. Ты не можешь исправить или изменить то, как игра ведет себя на сервере, но вы можете по крайней мере убедиться, что на стороне клиента (ваш компьютер) ведёт себя как можно лучше для игр. Я видел значительное улучшение, и работа может варьироваться в зависимости от многих других факторов, так что не ожидайте от этого руководства, что оно магически преодолеет старые медные соединения с вашим домом или плохо сделанную проводку интернета через Ваш дом.
Настройки сетевой карты в Windows 8.1 и Windows 10
Щёлкните правой кнопкой мыши на кнопку Пуск и выберите диспетчер устройств. Ищите Сетевые платы и дважды щелкните по ней. Щёлкните правой кнопкой мыши на сетевом адаптере, перечисленных в этой категории и выберите свойства. Нажмите на кнопку дополнительно.
Отключить адаптивный межкадровый интервала
Отключить все настройки энергосбережения (зеленый, eco, мощность и т. д.)
Отключить управление потоком
Отключить прерываниями
Набор прерываниями установить на off
Набор PME включить для гостей с ограниченными возможностями
Отключите все функции с помощью “Offload”
Отключите пакет приоритета и VLAN
Отключите пакеты
Большинство вариантов в этой категории для обеспечения надёжности, но вызывают задержку сетевого трафика, в результате игры по сети передают данные с опозданием, когда они уже должны были быть обработаны, это предполагает, что Вы сделали игру с которой никогда не случится замедление.
Набор буферов приема и передачи буферов до 96
В буфере соединения встречаются разные звери. Один из способов помочь предотвратить потерю данных, если данные не могут быть обработаны вовремя вашей системой, но имея данные в буферах значит будет задержка снова, прежде чем они на самом деле достигнут игрового движка (потому что данные сидят в буфере, ожидая, чтобы пройти через него). Если у вас действительно быстрая система, используя очень низкие значения позволит сократить задержки, потому что сетевой адаптер вынужден будет передавать их быстрее. С маломощной конечной системой это может привести к потере пакетов, так как сетевой адаптер будет просто удалять/отклонять пакеты, которые не вписываются в буферы.
Установить масштабирование на стороне приема (RSS-канал) включено
Установите количество очередей RSS на более высокое значение (2 в моем случае)
Масштабирование на стороне приема (RSS-канал) позволяет использовать несколько ядер процессора для обработки полученных сетевых пакетов быстрее и распространяя ЦП на количество ядер процессора. При включении этого раздела он будет обеспечивать и получать и передавать данные в буфер быстрее и буфер не будет переполнен данными, что позволяет установить очень низкое значение. Это может вызвать небольшие задержки ЦОД, потому что нескольким ядрам нужно синхронизировать сообщения между друг другом, но я думаю, что обработка будет быстрее и в целом помогает больше, чем немного выше будет задержка. Номер очереди RSS-канала определяет, сколько ядер процессора будут использоваться для обработки данных в сети. Значение 2 означает, что 2 из моих 6 ядер (процессор Intel 5820K) будут использованы для создания сети.
Результаты
После того, как я изменил настройки, в среднем я получил потери пакетов и они сократились с 10-12% до 0% (чего и тебе желаю!). Последовательность обработки также снизилась с 480 до 9 или 12 после того, как я поиграл в игру в течение нескольких минут. Это приемлемо, хотя я постараюсь, чтобы играть немного больше, чтобы сделать его ещё меньше, если это возможно.
Я также заметил что чтобы меня убить: коэффициент смертности (кд), значительно улучшился, а также меньше жалоб на то, что убить не получилось. Итак, попробуйте, если у вас ужасные проблемы с сетью как и у меня, вы не можете действительно сделать это хуже, чем есть.
Обратите внимание, что я не специалист в области сетевых технологий, все описанное выше – это то, что я узнал от чтения различных документов и мои прошлые знания о том, как компьютеры и сеть работают. Если у вас есть какие-то корректировки, расскажите, пожалуйста, внизу в комментариях и я буду обновлять информацию. Я также могу обновлять эту статью в будущем, если я смогу найти любую другую игру, в которой можно изменить настройки, которые её улучшат.
| Гигабитовый ведущий или ведомый режим | Определяет настройку адаптера или партнера по подключению в качестве главного устройства. Другое устройство назначается подчиненным.
| ||||
| Крупные кадры (Jumbo) | Включает или выключает возможность передачи крупных кадров. В ситуациях, когда крупные кадры составляют большую часть трафика, они могут помочь снизить загруженность центрального процессора и повысить эффективность кабельной системы. Крупные кадры имеют больший размер, чем стандартные Ethernet-пакеты - 1,5 К. Рекомендации по использованию
| ||||
| Разгрузка операций с отправкой больших пакетов | Эта функция позволяет адаптеру разгружать задачи сегментации сообщений TCP для допустимых кадров Ethernet. Поскольку аппаратные средства адаптера могут выполнять сегментацию данных быстрее, чем программное обеспечение операционной системы, эта функция может повысить производительность передачи. Адаптер также использует меньше ресурсов процессора. Вы можете настроить разгрузку операций с отправкой больших пакетов отдельно для IPv4 и IPv6.
| ||||
| Локально администрируемый адрес |
Виртуальный адрес не заменяет физически записанный адрес на адаптере. Для задания нового сетевого адреса введите в поле Значение 12-значный шестнадцатеричный номер.
Рекомендации по использованию
| ||||
| Журнал событий состояния связи | Позволяет вести системный журнал изменений состояния канала связи. LINK_UP_CHANGE LINK_DOWN_CHANGE LINK_DUPLEX_MISMATCH | ||||
| Параметры производительности — Адаптивное пространство между кадрами | Компенсирует чрезмерные коллизии пакетов Ethernet, управляя фоновой синхронизацией. Если эта функция включена, сетевой адаптер динамически адаптируется к условиям сетевого трафика. Настройка по умолчанию будет работать лучше всего для большинства компьютеров и сетей. В редких случаях вы сможете добиться лучшей производительности, изменив эту настройку. | ||||
| Параметры производительности — Управление потоком | Управление потоком позволяет адаптерам генерировать кадры управления потоком или отвечать на них, что способствует контролю сетевого трафика.
| ||||
| Параметры производительности — Частота модерации прерываний | Устанавливает частоту регулировки прерываний (ITR), а именно скорость, с которой контроллер управляет прерываниями. Настройка по умолчанию оптимизирована для большинства конфигураций. Изменение этой настройки может повысить производительность некоторых сетей и системных конфигураций.
Когда происходит событие, адаптер генерирует прерывание, которое позволяет драйверу обработать пакет. С увеличением скоростей передачи данных генерируется больше прерываний, и повышается загруженность центрального процессора. В результате снижается производительность системы. Если вы используете более высокую частоту ITR, скорость появления прерывания снижается, и в результате повышается производительность системы.
| ||||
| Параметры производительности — Дескрипторы приема | Устанавливает количество буферов, используемых драйвером во время копирования данных в память протокола. Увеличивая это значение, можно повысить производительность передачи, но при этом расходуется больше системной памяти. Дескрипторы приема — это сегменты данных, которые позволяют адаптеру распределять полученные пакеты в памяти. Для каждого полученного пакета требуется один дескриптор приема, и каждый дескриптор использует 2 КБ памяти. | ||||
| Параметры производительности — Дескрипторы передачи | Определяет количество дескрипторов передачи. Дескрипторы передачи являются сегментами данных, которые позволяют адаптеру отслеживать пакеты передачи в системной памяти. В зависимости от размера пакета для него может потребоваться один или несколько дескрипторов передаваемых сегментов данных. Если вы заметите снижение производительности передачи, можно увеличить количество дескрипторов передачи. Увеличение числа дескрипторов передачи может повысить производительность передачи. Однако дескрипторы передачи используют системную память. Если производительность приема не является проблемой, используйте установки по умолчанию. | ||||
| Маркировка пакетов QoS | Включает функцию отправки и получения маркированных кадров IEEE 802.3ac, включающих: Теги 802.1p QoS (управление качеством обслуживания) для пакетов с высокими приоритетами Теги 802.1Q виртуальных локальных сетей Приложение Intel® PROSet автоматически включает маркировку 802.1p во время настройки VLAN. Вы не можете отключить маркировку пакетов QoS в виртуальной сети, так как эта маркировка требуется для VLAN. Когда эта функция включена, маркированные пакеты используют настройки очереди, заданные в определении уровня приоритетов операционной системы. Когда эта функция выключена, адаптер не может помечать исходящие пакеты с помощью тегов 802.1p/802.1Q. | ||||
| Масштабирование на стороне приема | Включает функцию масштабирования на стороне приема (RSS). RSS уравновешивает поступающий трафик между несколькими ядрами центрального или графического процессора. Эта настройка не работает, если в системе имеется только процессор.
Примечания для объединения адаптеров:
| ||||
| Очереди масштабирования на стороне приема | Эта функция используется для настройки количества очередей RSS:
| ||||
| Параметры разгрузки протокола TCP/IP — Разгрузка операций с контрольной суммой IPv4 | Эта функция позволяет адаптеру проверять контрольную сумму стека IP для полученных пакетов и вычислять контрольную сумму для передаваемых пакетов. Включение этой функции может повысить производительность IP-передачи и снизить загруженность центрального процессора.
| ||||
| Параметры разгрузки протокола TCP/IP — Разгрузка операций с контрольной суммой TCP | Эта функция позволяет адаптеру проверять контрольную сумму TCP для полученных пакетов и вычислять контрольную сумму для передаваемых пакетов. Включение этой функции может повысить производительность TCP-передачи и снизить загруженность центрального процессора. Она может конфигурироваться отдельно для IPv4 и IPv6.
| ||||
| Параметры разгрузки протокола TCP/IP — Разгрузка операций с контрольной суммой IP | Эта функция позволяет адаптеру вычислять контрольную сумму IP для передаваемых пакетов. Она может повысить производительность IP-передачи и снизить загрузку центрального процессора. Если разгрузка отключена, проверку контрольной суммы IP выполняет операционная система. | ||||
| Параметры разгрузки протокола TCP/IP — Разгрузка операций с контрольной суммой UDP | Эта функция позволяет адаптеру проверять контрольную сумму UDP для полученных пакетов и вычислять контрольную сумму для передаваемых пакетов. Включение этой функции может повысить производительность UDP-передачи и снизить загрузку центрального процессора. Она может конфигурироваться отдельно для IPv4 и IPv6. | ||||
| Ожидание связи | Эта функция решает, будет ли драйвер ожидать автоматического согласования перед сообщением о состоянии канала.
|
тонкая настройка производительности серверных версий Windows — «Хакер»
Содержание статьи
Win2k3 и Win2k8 по умолчанию оптимизированы под стандартную сетевую среду. Но
если серверную ОС надлежащим образом настроить (например, под требования
компании), то это благоприятно отразится на каждом аспекте работы сети, начиная
от самого оборудования и заканчивая пользователями, подключенными к серверу.
Анализируем причину
Любая внештатная ситуация, в том числе и снижение производительности сервера,
требует тщательного анализа. Не собрав всей информации, можно нагородить дел.
Возьмем такой случай. Контроллер домена (КД) уже не справляется со своими
обязанностями - пользователи подолгу регистрируются в системе или не могут зайти
в сетевую папку. В зависимости от топологии Сети, вариантов решения может быть
несколько.
Например, можно модернизировать железо, перераспределить нагрузку между
серверами (в том случае, когда КД выполняет еще и другую задачу) или же снизить
нагрузку на основной КД за счет установки еще одного КД в отдельном
подразделении компании. При использовании Win2k8 в удаленном офисе есть вариант
установить контроллер домена только для чтения (RODC). Тогда в случае
компрометации сервера или банальной кражи оборудования можно не бояться за
нарушение функционирования всего леса (подробности смотри в статье «В лабиринте
AD»). Так мы разгрузим основной КД и снизим нагрузку на Сеть (в том числе и на
внешний канал, если для соединения между офисами используется интернет).
Узкие места могут возникать по нескольким причинам:
- системные ресурсы сервера или сети исчерпали свои возможности - как
правило, требуется наращивание или модернизация; - отдельные системы или участки сети нагружены неравномерно - требуется
перераспределение ресурсов; - ресурс используется в монопольном режиме - возможно, потребуется замена
программы на аналог, запуск ее только по требованию или в периоды низкой
загрузки; - неправильная настройка - необходимо изменение параметров.
Теперь разберем некоторые моменты подробнее.
Ищем бутылочное горлышко
Производительность систем и сервисов, то есть время, за которое они выполняют
некоторую задачу, зависит от ресурсов процессора и памяти, емкости и
производительности дисковых накопителей и пропускной способности сети. Все они
имеют свой лимит. При превышении запаса прочности одного из ресурсов
производительность начинает резко снижаться, образуя узкое место. Как результат,
общая производительность сервера определяется именно этим ресурсом, хотя
остальное в норме.
В новой Win2k8 и Win2k3, которая еще долго будет верой и правдой служить на
серверах, системы мониторинга несколько отличаются, но не настолько, чтобы не
разобраться при смене системы. Диспетчер задач, вызываемый по <Ctrl+Alt+Del> (в
Win2k8 нужно будет выбрать в меню еще и Start Task Manager) или <Ctrl+Shift+Esc>,
позволяет во вкладке Performance увидеть состояние основных системных ресурсов (CPU,
ОЗУ) и Сети (во вкладке Networking). В обеих системах можно оценить вклад
отдельного процесса в общую потерю производительности. Если информации
недостаточно, добавляем счетчики производительности. Для этого достаточно
перейти во вкладку «Processes» и выбрать в меню View - Select Columns, после
чего установить флажки напротив нужных пунктов. По умолчанию активировано всего
два счетчика: CPU Usage (загрузка ЦП) и Memory - Private Working Set (Memory
Usage в Win2k3, Использование памяти). Названия некоторых счетчиков в системах
отличаются, но разобраться несложно.
В Win2k3 для наблюдения за производительностью системы в штатную поставку
входит «Монитор Производительности» (вызывается через Старт -
Администрирование - Производительность, perfmon.msc), который выводит показания
активных счетчиков в виде графиков, диаграмм или таблиц. Ведется история
событий, помогающая отследить все изменения. При достижении порогового значения
можно, например, отправить сообщение админу - в общем, выполнить действие.
Подробности о «Мониторе Производительности» и основных счетчиках смотри в статье
«Поставь сервер на
счетчик», опубликованной в X_11_2007.
На сайте Microsoft для Win2k3 доступно еще одно эффективное, хотя и
малоизвестное средство анализа производительности - Server Performance Advisor
V2.0 (SPA). С помощью этой утилиты можно собрать информацию о настройках, данные
со счетчиков с одного или нескольких серверов, отслеживать события (Event
Tracing). По результатам работы получим удобные для чтения и анализа отчеты о
производительности, содержащие предупреждения и рекомендации по устранению
неполадок. В SPA имеется более 90 предварительно настроенных групп коллекторов.
Причем самые востребованные уже настроены! Например, коллектор System Overview
содержит основные системные счетчики: CPU usage, Memory usage, занятые файлы и
TCP-клиенты, top-потребители CPU, а также счетчики для основных серверов -
контроллеров домена, файловых служб AD, IIS, DNS, Terminal Services, SQL и др.
В Win2k8 контроль за основными параметрами системы возложен на Reliability
and Performance Monitor (RPM), который вобрал в себя функции отдельных
приложений, доступных в Win2k3. Запустить его можно несколькими способами: из
меню Administrative Tools, нажатием клавиши Resource Monitor во вкладке
Performance в Task Manager, выбрав пункт в меню Diagnostic в Server Manager или
введя в консоли perfmon.exe. В главном окне RPM увидим четыре графика, выводящие
информацию о загрузке CPU, Disk, Memory и Network в реальном времени. Чуть ниже
расположены таблицы с подробной информацией, разбитой по этим же группам. В
каждой показан процесс и связанные с ним данные (PID, объем ОЗУ, загрузка CPU,
Response Time дисковых операций, количество переданных и принятых сетевых
пакетов и прочее).
Зачастую достаточно одного взгляда на графики и таблицу, чтобы оценить
обстановку и принять решение. Но и это еще не все. «Монитор Производительности»
находится в меню Performance Monitor. По умолчанию активирован только один
счетчик Processor Time, но достаточно выбрать в контекстном меню Add
Counter, как откроется одноименное окно, в котором можно выбрать нужный счетчик.
Полный список охватывает все параметры системы и сервисов. Следующее меню, хотя
и не связано с оценкой производительности, - тем не менее, очень полезно при
поиске неисправностей. Речь идет о Reliability Monitor («Монитор Надежности»).
Справа от графика выводится индекс ожидания появления проблемы System Stability
Index («Системный Индекс Устойчивости»). График Stability Index помогает быстро
найти дату, когда было замечено первое появление проблемы (уменьшился System
Stability Index). В поле System Stability Report показаны детали возникшей
проблемы.
Два меню Data Collector Sets и Reports выступают в роли удобного аналога SPA.
Так, в первом из них содержатся шаблоны коллекторов, которые могут быть
использованы с любой программой, предназначенной для сбора данных. Выполнив,
например, LAN Diagnostics или System Performance (то есть любой коллектор или
группу), в соответствующем подменю в Reports получим полный отчет.
Тюнинг системы
Информация собрана, а значит, пора принимать решение. Чтобы добиться
увеличения производительности, можно изменить алгоритм работы буксующей
подсистемы, модифицировав соответствующий системный параметр. Признаю, это
временная мера, которая не всегда улучшает ситуацию. Но при правильном подходе
она позволит серверу продержаться на должном уровне еще несколько месяцев, пока
начальство не раскошелится на новое оборудование.
Перед внесением изменений сформулируем для себя несколько правил:
- одновременно вносим не более одного изменения, даже если узкое место
требует настройки нескольких параметров. Так легче будет сделать откат в
случае неудачи. Следующее изменение производим, только убедившись, что идем
правильным путем. Внесение сразу нескольких настроек делает невозможным
определение результата для каждого конкретного параметра; - после каждого изменения повторяем наблюдение в течение некоторого
времени, достаточного для сбора статистической информации; - так как изменения могут повлиять на другие ресурсы, сохраняем подробную
информацию об изменениях и результатах наблюдений за производительностью.
Среди советов встречаются такие, как отключение «лишних» сервисов и проверка
запланированных заданий, но в Win2k8 изначально запущено только то, что
действительно нужно. Поэтому эти советы больше актуальны для ранних версий
Windows.
Оптимизация сети
Сетевая подсистема в Win2k3/Win2k8 (как, впрочем, и в любой другой ОС)
является многоуровневой. Глубокий тюнинг следует производить на каждом уровне,
начиная от драйвера и NDIS (спецификация интерфейса сетевых драйверов) и
заканчивая уровнем приложений. Начнем «снизу».
Вызываем свойства адаптера и изучаем активные протоколы. Любой протокол
генерирует некоторый трафик, поэтому даже в небольшой сети путешествует гораздо
больше пакетов, чем нужно для ее нормального функционирования. Например,
адаптеру, который смотрит в интернет, часто ни к чему NetBEUI (да и с точки
зрения безопасности, это минус). Поэтому отключаем все лишнее, в том числе и
IPv6 (в нашей стране пока необходимости в нем нет). Параллельно включаем снифер
и отлавливаем «лишние» пакеты, определяя их источник. Если расположить более
быстрый или часто используемый протокол в начале списка, то это позволит
увеличить производительность.
Локальные файлы HOSTS (для TCP/IP) и LMHOSTS (NetBEUI), хранящие адреса и
имена систем, помогают уменьшить количество запросов на разрешение имен. Эти
настройки можно произвести как вручную, так и зайдя в свойства TCP/IP в
настройках сетевой карты, и затем выбрав Advanced. Распространять изменения в
этих файлах можно в небольших сетях вручную, а в AD - при помощи политик.
Присутствие DNS- и WINS-серверов также способно уменьшить количество лишних
задержек.
Кстати, новая концепция ролей в Win2k8 приносит свои плоды: в настройках Сети
после установки системы ничего лишнего не включено, а новые алгоритмы настройки
и оптимизации требуют меньше телодвижений со стороны администратора. Например,
автоматическая настройка TCP Receive Window Auto-Tuning динамически изменяет
размер принимающего буфера TCP, используемого для хранения входящих данных, тем
самым повышая пропускную способность, скажем, при передаче больших файлов на
высокоскоростных каналах (поэтому ключ реестра TcpWindowSize в Win2k8
игнорируется). Средство Compound TCP (CTCP) увеличивает количество одновременно
отправляемых данных - ну, и так далее. Впрочем, кое-что нам оставили и для
ручной настройки.
Нажав кнопку Configure в свойствах адаптера, получаем во вкладке Advanced
доступ к ряду настроек (их количество зависит от конкретного адаптера).
Например, для файлового и FTP сервера рекомендуется задействовать следующие
опции: IPv4, TCP и UDP Checksum offload, Segmentation offload и TCP offload
engine (TOE). Поддержка последнего включается следующим образом:
> netsh int tcp set global chimney = enabled
Для веб-сервера и сервера базы данных желательно активировать еще и
Receive-side scaling (RSS). Но если сетевой адаптер не справляется с нагрузкой,
- наоборот, пробуем по одному отключать все offload настройки. В Link Speed &
Duplex указывается режим работы адаптера (по умолчанию он выбирается
автоматически), а в Transmit/Receive Buffers - буфер приема и передачи. В целях
экономии ресурсов размер буфера по дефолту установлен в минимальное или среднее
значение. При больших нагрузках это чревато потерями пакетов. Если адаптер
позволяет вручную изменить размер буфера, то увеличиваем, не задумываясь.
Параметр Interrupt Moderation по умолчанию установлен в Adaptive.
Проигравшись с настройками, можно попробовать выбрать приемлемый результат между
производительностью Сети и нагрузкой на CPU. Если на сервере несколько CPU и
сетевых карт, то возможна привязка CPU к сетевому адаптеру. Это положительно
скажется на производительности Сети и системы за счет уменьшения количества
«лишних» прерываний. Конечно, это не все, что может сделать админ для разгрузки
Сети. Например, для настройки драйвера http.sys, который используется IIS, есть
целая ветка реестра:
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Http\Parameters
Что-то можно сделать и на прикладном уровне. Например, в ISA Server
реализована функция сжатия данных, передаваемых по протоколу HTTP. Правда, за
меньший трафик придется платить большей нагрузкой на CPU. В медленных сетях
пропускная способность повышается на 30%. Также уменьшается задержка при
передаче информации, хотя нагрузка на процессор не увеличивается более чем на
20%. Для разгрузки сервера терминалов в Computer Configuration - Administrative
Templates - Windows Components - Terminal Services - Terminal Server можно
уменьшить глубину цвета и размер рабочего стола, установить сжатие RDP,
отключить обои и т.д.
Дисковая подсистема
Часто именно дисковая подсистема служит основной причиной потери
производительности. Она ограничена числом физических обращений к диску в секунду
(зависит от скорости вращения диска и от того, насколько случайный характер
имеют операции обращения). Самым простым методом сокращения частоты обращения к
диску будет установка дополнительных дисков или использование RAID.
Кое-что можно сделать и самому. По умолчанию файл подкачки равен 1.5 объема
ОЗУ и расположен на системном диске. Последний обычно сильно загружен, к тому же
подвержен фрагментации. Поэтому, если имеется несколько дисков, создаем файл
подкачки на каждом. Для этого в Control Panel System выбираем Advanced System
Setting и получаем знакомое окно System Properties («Свойства системы»).
Нажимаем во вкладке Advanced в поле Performance кнопку Setting, снова щелкаем
Advanced, а затем кнопку Change. В появившемся окне снимаем флажок «Automatically
manage paging file for all driver» и указываем, на каких дисках и разделах
следует создать файл подкачки. При этом следует помнить, что использование
нескольких разделов одного диска для файла подкачки, мягко говоря,
нецелесообразно. Своп лучше размещать на разделах с меньшей буквой, на которых,
как правило, скорость повыше.
По умолчанию Windows записывает данные блоками по 64 Кб, но жесткие диски и
приложения могут использовать блоки других размеров. Данные в этом случае
придется записывать на несколько секторов, что снижает производительность. В
состав Win2k8 и Win2k3 SP1 входит программа Diskpart, предназначенная для
создания разделов диска. С ее помощью можно задать другое смещение. Пользоваться
программой просто. Для запуска в командной строке набираем diskpart.exe. Далее
командой «List Disk» выводим список дисков, выбираем нужный диск - «Select Disk
1», создаем раздел «Create Partition Primary Align=64» и присваиваем ему букву
(«Assign Letter=D»). Помни, что Diskpart уничтожает данные, поэтому
предварительно создай резервную копию!
Также стоит отключить индексацию файлов для (якобы) быстрого поиска и
компрессию диска (если взведен флажок «Compress this drive to save disk space»).
И, конечно же, не забываем о периодической дефрагментации (Свойства диска -
Tools - Defragment Now). В подменю Shadow Copies находятся настройки теневых
копий. Если резервирование производится другими средствами, то для повышения
производительности их можно отключить или изменить алгоритм работы.
Не помешает знать и о некоторых параметрах реестра (они подходят и для
Win2k3). Так, параметр NumberOfRequests, зависимый от драйвера сетевой карты,
позволяет задать количество запросов, ускоряя работу за счет распараллеливания.
Драйвер сам устанавливает оптимальное значение, но рекомендуется установить его
в диапазоне от 32 до 96.
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\MINIPORT_ADAPTER\Parameters\DeviceN\NumberOfRequests
(REG_DWORD)
Установка в 0 ключа CountOperations позволит отключить некоторые счетчики,
что также повлияет на производительность в лучшую сторону:
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Session Manager\I/O System\CountOperations
Установка в 1 (REG_DWORD) ключа DontVerifyRandomDrivers запрещает
тестирование и проверку некорректно работающих драйверов:
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Session Manager\Memory
Management\DontVerifyRandomDrivers
В Win2k8 используется сложный алгоритм, индивидуально управляющий приоритетом
I/O. Если для экспериментов ты захочешь его отключить, установи в 0:
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control\DeviceClasses\{Device
GUID}\DeviceParameters\Classpnp\IdlePrioritySupported\I/O Priorities
Чтобы запретить обновление даты последнего обращения к файлу, устанавливаем в
1 (REG_DWORD) ключ:
HKLM\System\CurrentControlSet\Control\FileSystem\NtfsDisableLastAccessUpdate
Это только основные параметры. А подробную информацию по настройке дисковой
подсистемы можно найти в документе «Disk Subsystem Performance Analysis for
Windows» на сайте Microsoft.
Точность хирурга
Повышение производительности сервера - это сугубо индивидуальная операция,
которую нужно производить с точностью хирурга, контролируя каждый этап. Но
ничего сложного здесь нет! Потратив некоторое время, ты неизменно получишь
результат. А какой именно, - зависит только от тебя.
Тонкая настройка сетевого стека на Windows-хостах (часть вторая)
Привет.
Это – вторая часть статьи. Поэтому всё, что относится к первой, относится и к этой. В этой, правда, будет больше настроек сетевых адаптеров, но не суть. Не буду повторяться, разве что в плане диспозиции.
Диспозиция
Я предполагаю, что Вы, товарищ читатель, знаете на приемлемом уровне протокол TCP, да и вообще протоколы сетевого и транспортного уровней. Ну и канального тоже. Чем лучше знаете – тем больше КПД будет от прочтения данной статьи.
Речь будет идти про настройку для ядра NT 6.1 (Windows 7 и Windows Server 2008 R2). Всякие исторические ссылки будут, но сами настройки и команды будут применимы к указанным ОС, если явно не указано иное.
В тексте будут упоминаться ключи реестра. Некоторые из упоминаемых ключей будут отсутствовать в официальной документации. Это не страшно, но перед любой серьёзной модификацией рабочей системы лучше фиксировать то, что Вы с ней делаете, и всегда иметь возможность удалённого доступа, не зависящую от состояния сетевого интерфейса (например KVM).
Содержание (то, что зачёркнуто, было в первой части статьи)
- Работаем с управлением RWND (autotuninglevel)
- Работаем с Checksum offload IPv4/IPv6/UDP/TCP
- Работаем с Flow Control
- Работаем с Jumbo Frame
- Работаем с AIFS (Adaptive Inter-frame Spacing)
- Работаем с Header Data Split
- Работаем с Dead Gateway Detection
Работаем с управлением RWND (autotuninglevel)
Данный параметр тесно связан с описаным ранее параметром WSH – Window Scale Heuristic. Говоря проще, включение WSH – это автоматическая установка данного параметра, а если хотите поставить его вручную – выключайте WSH.
Параметр определяет логику управление размером окна приёма – rwnd – для TCP-соединений. Если Вы вспомните, то размер этого окна указывается в поле заголовка TCP, которое называется window size и имеет размер 16 бит, что ограничивает окно 2^16 байтами (65536). Этого может быть мало для текущих высокоскоростных соединений (в сценариях вида “с одного сервера по IPv6 TCPv6-сессии и десятигигабитной сети копируем виртуалку” – совсем тоскливо), поэтому придуман RFC 1323, где описывается обходной способ. Почему мало? Потому что настройка этого окна по умолчанию такова:
- Для сетей со скоростью менее 1 мегабита – 8 КБ (если точнее, 6 раз по стандартному MSS – 1460 байт)
- Для сетей со скоростью 100 Мбит и менее, но более 1 Мбит – 17 КБ (12 раз по стандартному MSS – 1460 байт)
- Для сетей со скоростью выше 100 Мбит – 64 КБ (максимальное значение без поддержки RFC 1323)
Способ обхода, предлагаемый в RFC 1323, прост и красив. Два хоста, ставящих TCP-сессию, согласовывают друг с другом параметр, который является количеством бит, на которые будет сдвинуто значение поля windows size. То есть, если они согласуют этот параметр равный 2, то оба из них будут читать это поле сдвинутым “влево” на 2 бита, что даст увеличение параметра в 2^2=4 раза. И, допустим, значение этого поля в 64К превратится в 256К. Если согласуют 5 – то поле будет сдвинуто “влево” на 5 бит, и 64К превратится в 2МБ. Максимальный поддерживаемый Windows порог этого значения (scaling) – 14, что даёт максимальный размер окна в 1ГБ.
Как настраивается RWND в Windows
Существующие варианты настройки этого параметра таковы:
netsh int tcp set global autotuninglevel=disabled– фиксируем значение по умолчанию (для гигабитного линка это будет 64K), множитель – нуль. Это поможет, если промежуточные узлы (например, старое сетевое оборудование) не понимает, что значение окна TCP – это не поле window size, а оно, модифицированное с учётом множителя scaling.netsh int tcp set global autotuninglevel=normal– оставляем автонастройку, значение множителя – не более 8.netsh int tcp set global autotuninglevel=highlyrestricted– оставляем автонастройку, значение множителя – не более 2.netsh int tcp set global autotuninglevel=restricted– оставляем автонастройку, значение множителя – не более 4.netsh int tcp set global autotuninglevel=experimental– оставляем автонастройку, значение множителя – до 14.
Ещё раз – если Вы включите WSH, он сам будет подбирать “максимальный” множитель, на котором достигается оптимальное качество соединения. Подумайте перед тем, как править этот параметр вручную.
Работаем с Checksum offload IPv4/IPv6/UDP/TCP
Данная пачка технологий крайне проста. Эти настройки снимают с CPU задачи проверки целостности полученых данных, которые (задачи, а не данные) являются крайне затратными. То есть, если Вы получили UDP-датаграмму, Вам, по сути, надо проверить CRC у ethernet-кадра, у IP-пакета, и у UDP-датаграммы. Всё это будет сопровождаться последовательным чтением данных из оперативной памяти. Если скорость интерфейса большая и трафика много – ну, Вы понимаете, что эти, казалось бы, простейшие операции, просто будут занимать ощутимое время у достаточно ценного CPU, плюс гонять данные по шине. Поэтому разгрузки чексумм – самые простые и эффективно влияющие на производительность технологии. Чуть подробнее про каждую из них:
IPv4 checksum offload
Сетевой адаптер самостоятельно считает контрольную сумму у принятого IPv4 пакета, и, в случае, если она не сходится, дропит пакет.
Бывает продвинутая версия этой технологии, когда адаптер умеет сам проставлять чексумму отправляемого пакета. Тогда ОС должна знать про поддержку этой технологии, и ставить в поле контрольной суммы нуль, показывая этим, чтобы адаптер выставлял параметр сам. В случае chimney, это делается автоматически. В других – зависит от сетевого адаптера и драйвера.
IPv6 checksum offload
Учитывая, что в заголовке IPv6 нет поля checksum, под данной технологией обычно имеется в виду “считать чексумму у субпротоколов IPv6, например, у ICMPv6”. У IPv4 это тоже подразумевается, если что, только у IPv4 субпротоколов, подпадающих под это, два – ICMP и IGMP.
UDPv4/v6 checksum offload
Реализуется раздельно для приёма и передачи (Tx и Rx), соответственно, считает чексуммы для UDP-датаграмм.
TCPv4/v6 checksum offload
Реализуется раздельно для приёма и передачи (Tx и Rx), соответственно, считает чексуммы для TCP-сегментов. Есть тонкость – в TCPv6 чексумма считается по иной логике, нежели в UDP.
Общие сведения для всех технологий этого семейства
Помните, что все они, по сути, делятся на 2 части – обработка на адаптере принимаемых данных (легко и не требует взаимодействия с ОС) и обработка адаптером отправляемых данных (труднее и требует уведомления ОС – чтобы ОС сама не считала то, что будет посчитано после). Внимательно изучайте документацию к сетевым адаптерам, возможности их драйверов и возможности ОС.
Ещё есть заблуждение, гласящее примерно следующее “в виртуалках всё это не нужно, ведь это все равно работает на виртуальных сетевухах, значит, считается на CPU!”. Это не так – у хороших сетевых адаптеров с поддержкой VMq этот функционал реализуется раздельно для каждого виртуального комплекта буферов отправки и приёма, и в случае, если виртуальная система “заказывает” этот функционал через драйвер, то он включается на уровне сетевого адаптера.
Как включить IP,UDP,TCP checksum offload в Windows
Включается в свойствах сетевого адаптера. Операционная система с данными технологиями взаимодействует через минипорт, читая настройки и учитывая их в случае формирования пакетов/датаграмм/сегментов для отправки. Так как по уму это всё реализовано в NDIS 6.1, то надо хотя бы Windows Server 2008.
Работаем с Flow Control
Вы наверняка видели в настройках сетевых адаптеров данный параметр. Он есть практически на всех, поскольку технология данная (официально называемая 802.3x) достаточно простая и древняя. Но это никак не отменяет её эффективность.
Суть технологии проста – существует множество ситуаций, когда приём кадра L2 нежелателен (заполнен буфер приёма, перегружена шина данных, загружен порт получателя). В этом случае без управления потоком кадр придётся просто отбросить (обычный tail-drop). Это повлечёт за собой последующее обнаружение потери пакета, который был в кадре, и долгие выяснения на уровне протоколов более высоких уровней (того же TCP), что и как произошло. Иными словами, потеря 1.5КБ кадра превратится в каскад проблем, согласований и выяснений, на которые будет затрачено много времени и куда как больше трафика, чем если бы потери удалось избежать.
А избежать её просто – надо отправить сигнальный кадр с названием PAUSE – попросить партнёра “притормозить на чуток”. Соответственно, надо, чтобы устройство умело и обрабатывать такие кадры, и отправлять их. Кадр устроен просто – это 802.3 с вложением с кодом 0x0001, отправляемое на мультикастовый адрес 01-80-C2-00-00-01, внутри которого – предлагаемое время паузы.
Включайте поддержку этой технологии всегда, когда это возможно – в таком случае в моменты пиковой нагрузки сетевая подсистема будет вести себя более грамотно, сокращая время перегрузки за счёт интеллектуального управления загрузкой канала.
Как включить Flow control в Windows
Включается в свойствах сетевого адаптера. Операционная система с данной технологией не взаимодействует. Не забудьте про full duplex.
Работаем с Jumbo Frame
Исторически размер данных кадра протокола Ethernet – это 1.5КБ, что в сумме со стандартным заголовком составляет 1518 байт, а в случае транкинга 802.1Q – 1522 байт. Соответственно, этот размер оставался, а скорости росли – 10 Мбит, 100 Мбит, 1 Гбит. Скорость в 100 раз выросла – а размер кадра остался. Непорядок. Ведь это обозначает, что процессор в 100 раз чаще “дёргают” по поводу получения нового кадра, что объём служебных данных также остался прежним. Совсем непорядок.
Идея jumbo frame достаточно проста – увеличить максимальный размер кадра. Это повлечёт огромное количество плюсов:
- Улучшится соотношение служебных и “боевых” данных – ведь вместо, допустим, 4х IP-пакетов можно отправить один.
- Уменьшится число переключений контекста – можно будет реже инициировать функцию “пришёл новый кадр”.
- Можно соответствующим образом увеличить размеры PDU верхних уровней – пакета IP, датаграммы UDP, сегмента TCP – и получить соответствующие преимущества.
Данная технология реализуема только на интерфейсах со скоростями 1 гбит и выше. Если Вы включите jumbo frames на уровне сетевого адаптера, а после согласуете скорость в 100 мбит, то данная настройка не будет иметь смысла.
Для увеличения максимального размера кадра есть достаточно технологических возможностей – например, длина кадра хранится в поле размером в 2 байта, поэтому менять формат кадра 802.3 не нужно – место есть. Ограничением является логика подсчёта CRC, которая становится не очень эффективна при размерах >12К, но это тоже решаемо.
Самый простой способ – выставить у адаптера данный параметр в 9014 байт. Это является тем, что сейчас “по умолчанию” называется jumbo frame и шире всего поддерживается.
Есть ли у данной технологии минусы? Есть. Первый – в случае потери кадра из-за обнаружения сбоя в CRC Вы потеряете в 6 раз больше данных. Второй – появляется больше сценариев, когда будет фрагментация сегментов TCP-сессий. Вообще, в реальности эта технология очень эффективна в сценарии “большие потоки не-realtime данных в локальной сети”, учитывайте это. Копирование файла с файл-сервера – это целевой сценарий, разговор по скайпу – нет. Замечу также, что протокол IPv6 более предпочтителен в комбинации с Jumbo frame.
Как включить Jumbo frame в Windows
Включается в свойствах сетевого адаптера (естественно, только гигабитного). Операционная система с данной технологией не взаимодействует, автоматически запрашивая у сетевой подсистемы MTU канального уровня.
Работаем с AIFS (Adaptive Inter-frame Spacing)
Данная технология предназначена для оптимизации работы на half-duplex сетях со скоростями 10/100 мегабит, и, в общем-то, сейчас не особо нужна. Суть её проста – в реальной жизни, при последовательной передаче нескольких ethernet-кадров одним хостом, между ними есть паузы – чтобы и другие хосты могли “влезть” и передать свои данные, и чтобы работал механизм обнаружения коллизий (который CSMA/CD). Иначе, если бы кадры передавались “вплотную”, хост, копирующий по медленной сети большой поток данных, монополизировал бы всю сеть для себя. В случае же full-duplex данная мера уже не сильно интересна, потому что ситуации “из N хостов одновременно может передавать только один” нет. Помните, что включая данную технологию, Вы позволяете адаптеру уменьшать межкадровое расстояние ниже минимума, что приведёт к чуть более эффективному использованию канала, но в случае коллизии Вы получите проблему – “погибнет” не только один кадр, но и соседний (а то и несколько).
Данные паузы называются или interframe gap, или interframe spacing. Минимальное штатное значение этого параметра – 96 бит. AIFS уменьшает это значение до:
- 47 бит в случае канала 10/100 МБит.
- 64 бит в случае канала 1 ГБит.
- 40 бит в случае канала 10 ГБит.
Как понятно, чисто технически уменьшать это значение до чисел менее 32 бит (размер jam) совсем неправильно, поэтому можно считать 32 бита технологическим минимумом IFS.
Процесс, который состоит в приёме потока кадров с одним IFS и отправкой с другим IFS, иногда называется IFG Shrinking.
В общем, говоря проще – негативные эффекты этой технологии есть, но они будут только на 10/100 Мбит сетях в режиме half-duplex, т.к. связаны с более сложным сценарием обработки коллизий. В остальном у технологии есть плюс, Вы получите небольшой выигрыш в части эффективности загрузки канала в сценарии “плотный поток от одного хоста”.
Да, не забудьте, что коммутатор должен “понимать” ситуацию, когда кадры идут плотным (и более плотным, чем обычно) потоком.
Как включить Adaptive Inter-frame Spacing в Windows
Включается в свойствах сетевого адаптера. Операционная система с данной технологией не взаимодействует.
Работаем с Header Data Split
Фича достаточно интересна и анонсирована только в NDIS 6.1. Суть такова – допустим, что у Вас нет Chimney Offload и Вы обрабатываете заголовки программно. К Вам приходят кадры протокола Ethernet, а в них, как обычно – различные вложения протоколов верхних уровней – IP,UDP,TCP,ICMP и так далее. Вы проверяете CRC у кадра, добавляете кадр в буфер, а после – идёт специфичная для протокола обработка (выясняется протокол сетевого уровня, выясняется содержимое заголовка и предпринимаются соответствующие действия). Всё логично.
Но вот есть одна проблема. Смотрите. Если Вы приняли, допустим, сегмент TCP-сессии, обладающий 10К данных, то, по сути, последовательность действий будет такая (вкратце):
- Сетевая карта: Обработать заголовок 802.3; раз там 0x0800 (код протокола IPv4), то скопировать весь пакет и отдать наверх на обработку. Ведь в данные нам лезть незачем – не наша задача, отдадим выше.
- Минипорт: Прочитать заголовок IP, понять, что он нормальный, найти код вложения (раз TCP – то 6) и скопировать дальше. Данные-то не нам не нужны – это не наша задача, отдадим выше.
- NDIS: Ага, это кусок TCP-сессии номер X – сейчас изучим его и посмотрим, как и что там сделано
Заметили проблему? Она проста. Каждый слой читает свой заголовок, который исчисляется в байтах, а тащит ради этого путём копирования весь пакет.
Технология Header-Data Split адресно решает этот вопрос – заголовки пакетов и данные хранятся отдельно. Т.е. когда при приёме кадра в нём обнаруживается “расщепимое в принципе” содержимое, то оно разделяется на части – в нашем примере заголовки IP+TCP будут в одном буфере, а данные – в другом. Это сэкономит трафик копирования, притом очень ощутимо – как минимум на порядки (сравните размеры заголовков IP, который максимум 60 байт, и размер среднего пакета). Технология крайне полезна.
Как включить Header-Data Split в Windows
Включится оно само, как только сетевой драйвер отдаст минипорту флаг о поддержке данной технологии. Можно выключить вручную, отдав NDIS_HD_SPLIT_COMBINE_ALL_HEADERS через WMI на данный сетевой адаптер – тогда минипорт будет “соединять” головы и жо не-головы пакетов перед отправкой их на NDIS. Это может помочь в ситуациях, когда адаптер некорректно “расщепляет” сетевой трафик, что будет хорошо заметно (например, ничего не будет работать, потому что TCP-заголовки не будут обрабатываться корректно). В общем и целом – включайте на уровне сетевого адаптера, и начиная с Windows Server 2008 SP2 всё дальнейшее будет уже не Вашей заботой.
Работаем с Dead Gateway Detection
Данный механизм – один из самых смутных. Я лично слышал вариантов 5 его работы, все из которых были неправильными. Давайте разберёмся.
Первое – для функционирования этого механизма надо иметь хотя бы 2 шлюза по умолчанию. Не маршрутов, вручную добавленых в таблицу маршрутизации через route add например, а два и более шлюза.
Второе – этот механизм работает не на уровне IP, а на уровне TCP. Т.е. по сути, это обнаружение повторяющихся ошибок при попытке передать TCP-данные, и после этого – команда всему IP-стеку сменить шлюз на другой.
Как же будет работать этот механизм? Логика достаточно проста. Стартовые условия – механизм включен и параметр TcpMaxDataRetransmissions настроен по-умолчанию, то есть равен 5. Допустим, что у нас на данный момент есть 10 tcp-подключений.
- На каждое подключение создаётся т.н. RCE – route cache entry – строчка в кэше маршрутов, которая говорит что-то вида такого “все соединения с IP-адреса X на IP-адрес Y ходят через шлюз Z, пересчитывать постоянно это не нужно, потому что полностью обрабатывать таблицу маршрутизации ради 1го пакета – уныло и долго. Ну, этакий Microsoft’овский свичинг L3 типа CEF. :)
- Соединение N1 отправляет очередной сегмент TCP-сессии. В ответ – тишина. Помер.
- Соединение N1 отправляет тот же сегмент TCP-сессии, уже имея запись, что 1 раз это не получилось. В ответ – опять тишина. Нет ACK’а. И этот сегмент стал героем.
- Соединение N1 нервничает и отправляет тот же сегмент TCP-сессии. ACK’а нет. Соединение понимает, что так жить нельзя и делает простой вывод – произошло уже 3 сбоя отправки, что больше, чем половина значения
TcpMaxDataRetransmissions, которое у нас 5. Соединение объявляет шлюз нерабочим и заказывает смену шлюза. - ОС выбирает следующий по приоритету шлюз, обрабатывает маршрут и генерит новую RCE-запись.
- Счётчик ошибок сбрасывается на нуль, и всё заново – злополучный сегмент соединения N1 опять пробуют отправить.
Когда такое происходит для более чем 25% соединений (у нас их 10, значит, когда такое случится с 3 из них), то IP-стек меняет шлюз по-умолчанию. Уже не для конкретного TCP-соединения, а просто – для всей системы. Счётчик количества “сбойных” соединений сбрасывается на нуль и всё готово к продолжению.
Как настроить Dead Gateway Detection в Windows
Для настройки данного параметра нужно управлять тремя значениями в реестре, находящимися в ключе:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\
Все они имеют тип 32bit DWORD и следующую логику настройки:
TcpMaxDataRetransmissions– Количество повторных передач TCP-сегментов. От этого числа берётся критерий “Более половины”.TcpMaxConnectRetransmissions– То же самое, но для повторных попыток подключения, а не передачи сегментов данных.EnableDeadGWDetect– Включён ли вообще алгоритм обнаружения “мёртвого” шлюза. Единица – включён, нуль – отключен.
Вместо заключения
Сетевых настроек – много. Знать их необходимо, чтобы не делать лишнюю работу, не ставить лишний софт, который кричит об “уникальных возможностях”, которые, на самом деле, встроены в операционную систему, не разрабатывать дурацкие архитектурные решения, базирующиеся на незнании матчасти архитектором, и в силу множества других причин. В конце концов, это интересно.
Если как-нибудь дойдут руки – будет новая часть статьи.
Дата последнего редактирования текста: 2013-10-05T07:17:01+08:00
Возможно, вам будет также интересно почитать эти статьи с нашей Knowledge Base
Большие потоки трафика и управление прерываниями в Windows / Habr
Мне очень понравился топик про распределение нагрузки от прерываний сетевого адаптера по процессорам, поэтому я решил описать как это делается в Windows.Disclaimer: судя по некоторым комментариям в предыдущих постах, мне стоит повторить то, с чего я начал первый пост: я не даю (и не могу давать) общеприменимых рецептов. Особенно это касается производительности, где мельчайшая неучтенная деталь может катастрофически повлиять на результат. Вернее рекомендацию то я даю: ТЕСТИРОВАНИЕ И АНАЛИЗ. Смысл моей писанины в том, чтобы дать людям как можно больше информации для анализа, ведь, чем больше понимаешь в том, как что либо работает, тем легче находить пути устранения боттлнеков.
Итак, масштабируемость пропускной способности сети. Потребуется Windows Server 2003 SP2+. Сетевая карта, поддерживающая Receive Side Scaling (можно с достаточной долей уверенности сказать, что подойдет любая серверная сетевая карта, выпущенная в последние 5 лет или любая вообще 1Gb+ NIC, хотя частенько можно увидеть RSS и на 100Mb). Устанавливаем Windows Server и драйвера на карту…
ВСЕ. Настройка завершена. RSS по умолчанию включен во всех версиях Windows, в которых он поддерживается.
Тестирование
Возьмем не особо новый Dell-овый сервер с двумя четырехядерными ксеонами:
На борту две двухпортовые 1Gb сетевые карты и одна 10Gb, но я не нашел 10Gb свитча, так что завести не удалось — ну да ладно:
Что интересно в этих картах, так это то, что несмотря на поддержку RSS в 8 очередей, они не поддерживают ни MSI-X ни даже MSI. Более того, из четырех доступных линий pin-based прерываний на каждый сетевой порт отведена только одна (соответственно никакими способами заставить прерывания приходить на разные процессоры уже нельзя — это аппаратное ограничение данной конфигурации). 10 гигабитка зарегистрировала на себя то ли 32 то ли 64 (на глаз) вектора прерываний, но ее использовать — не судьба. Сможет ли индусская поделка для запуска игр справиться с задачей?
На всякий случай проверяем RSS (хотя если его не будет — будет заметно и так):
Для начала выключим RSS (включал обратно я уже после тестирования, но том же окне)
и запустим нагрузочный тест:
Полностью загружены два ядра, все остальные простаивают
Сеть загружена на треть:
50% одного процессора забито обработакой прерываний, еще 20% того же процессора — обработка DPC. Остальное — tcpip стек и приложение, которое отдает трафик.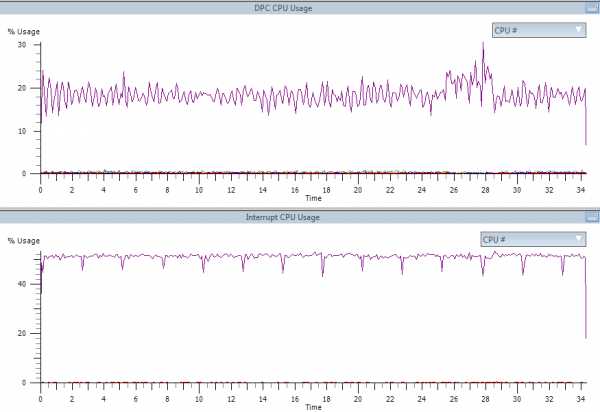
Включаем RSS (скриншот выше). Процессор:
Сеть:
Треть одного процессора забита прерываниями, но DPC отлично распараллелены.
В общем, на данной конфигурации можно было бы отдавать порядка 3 гигабит (с одной сетевой карты) и только тогда мы бы встретили бутылочное горлышко.
На всякий случай, скажу, что у RSS есть менее известный родственник — Send Side Scaling. Если перед посылкой списка буферов выставить значение хеша, то прерывание после завершения посылки будет доставлено в соответствии с установленными indirection table-ами.
Вот здесь можно почитать про RSS, а здесь есть неплохая презентация в картинках поясняющая работу RSS. Если интересно, могу попробовать своими словами описать механизмы работы RSS, но как по мне — лучше читать первоисточники.
TCP Offload Engine
Если нечто подобное RSS в Linux вот-вот появится (не нашел никаких упоминаний о поддержке нормального аппаратного RSS в Linux: кто знает — дайте ссылку — проапдейчу пост). То с TOE в Linux все официально сложно. Патч от Chelsio (один из производителей high-end сетевых карт), реализующий поддержку TOE, был отклонен, а вместо этого начались какие то совершенно идиотские отмазки (при прочтении стоит иметь в виду, что BSD и Windows имеют нормальную поддержку TOE уже много лет).
Итак, что же это такое? TOE — это полная реализация TCPIP на аппаратном уровне: с подтверждением доставки, ретрансмитами при ошибках, контролем окна и пр.: сетевая карта по DMA прямо из памяти берет данные, режет на пакеты, присоединяет хедеры, а рапортует (при помощи прерываний) только в самых крайних случаях.
По умолчанию TOE стоит в automatic режиме. Смотреть Chimney Offload State: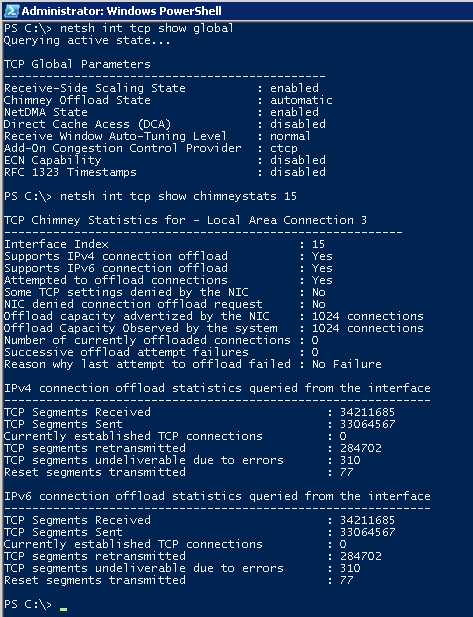
Скриншот снимался во время активного тестирования, но в статистике видно, что ни одного «выгруженного» в сетевую карту соединения нет (о причинах позже). Включем принудительно (и через некоторое время запрашиваем статистику):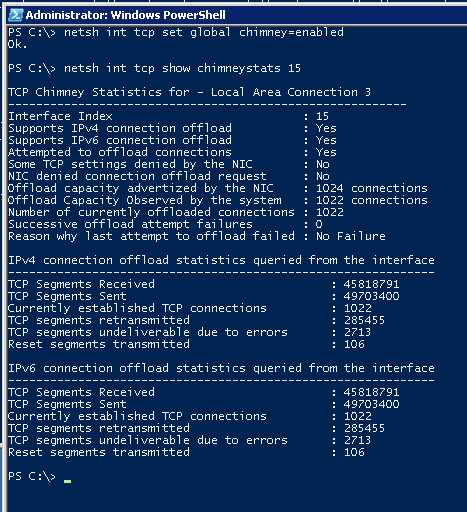
А вот и причина: в данную сетевую карту можно выгрузить только 1024 соединения (но реально система смогла выгрузить 1022). Довольно дорогой ресурс, чтоб можно было выгружать все подряд. Система эвристически пытается обнаруживать соединения (get/put больших файлов по http, пересылка файлового контента на файл-серверах и т.п.), которые проживут долго и выгружает в первую очередь их.
Но все же глянем, что получилось. Процессор разгрузился втрое:
Очень сильно уменьшилось количество (и время проводимое в) как ISR так и DPC: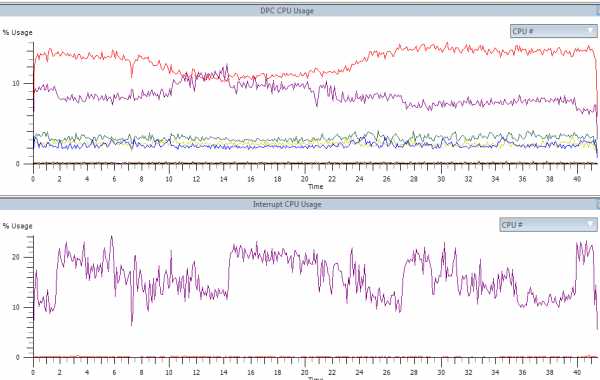
Узкие места сетевой подсистемы Linux. Тюнинг сети в Linux. Настройка производительности сети в модели NAPI и с прерываниями.
Узкие места сетевой подсистемы Linux. Тюнинг сети в Linux. Настройка производительности сети в модели NAPI и с прерываниями.
Кольцевой буфер
Кольцевые буферы, совместно используются драйвером устройства и сетевой картой. TX – есть передача данных, а RX – получение данных в кольцевом буфере. Как следует из названия, переполнение буфера просто перезаписывает существующие данные. Есть два способа переместить данные от сетевой карты до ядра: аппаратные прерывания и программные прерывания, названные SoftIRQs.
Кольцевой буфер RX используется, чтобы сохранить входящие пакеты, пока они не могут быть обработаны драйвером устройства. Драйвер устройства опустошает буфер RX, обычно через SoftIRQs, который помещает входящие пакеты в структуру данных ядра, названную sk_buff или «skb», чтобы начать свой путь через ядро и до приложения, которому принадлежит соответствующий сокет. Кольцевой буфер TX используется для хранения исходящих пакетов, которые предназначенные для отправки по проводам.
Эти кольцевые буферы находятся у основания стека и являются критическим моментом, в который может произойти удаление (drop) пакетов, что негативно влияет на производительность сети.
Прерывания и обработчики прерываний
Прерывания от аппаратных средств известны как прерывания «top-half».
Сетевые карты, как правило, работают с кольцевыми буферами (DMA ring buffer) организованными в памяти, разделяемой с процессором. Каждый входящий пакет размещается в следующем доступном буфере кольца. (DMA - Direct Memory Access (Прямой доступ к памяти) — режим обмена данными между устройствами или же между устройством и основной памятью, в котором центральный процессор (ЦП) не участвует). После этого требуется сообщить системе о появлении нового пакета и передать данные дальше, в специально выделенный буфер (Linux выделяет такие буферы для каждого пакета). Для этой цели в Linux используется механизм прерываний: прерывание генерируется всякий раз, когда новый пакет поступает в систему. Чаще используется отложенные прерывания (см. в статье Linux, принципы работы с сетевой подсистемой ). В ядро Linux начиная с версии ядра 2.6 был добавлен так называемый NAPI (New API), в котором метод прерываний сочетается с методом опроса. Сначала сетевая карта работает в режиме прерываний, но как только пакет поступает на сетевой интерфейс, она регистрирует себя в poll-списке и отключает прерывания. Система периодически проверяет список на наличие новых устройств и забирает пакеты для дальнейшей обработки. Как только пакеты обработаны, карта будет удалена из списка, а прерывания включатся снова.
Жесткие прерывания можно увидеть в /proc/interrupts, где у каждой очереди есть vector прерывания в 1-м столбце. Каждой очереди RX и TX присвоен уникальный vector, который сообщает обработчику прерываний, относительно какого NIC/queue пришло прерывание. Столбцы представляют количество входящих прерываний:
|
#egrep "CPU0|eth2" /proc/interrupts CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 CPU6 CPU7 45: 28324194 0 0 0 0 0 0 0 PCI-MSI-edge eth2 |
SoftIRQs
Иизвестны как прерывания «bottom-half», запросы программного прерывания (SoftIRQs), являются подпрограммами ядра, которые планируется запустить в то время, когда другие задачи не должны быть прерваны. Цель SoftIRQ состоит в извлечении данных из кольцевых буферов. Эти подпрограммы, выполненные в форме процессов ksoftirqd/cpu-number и, вызывают специфичные для драйвера функции кода.
После перемещения данных от драйвера к ядру, трафик двигатется вверх к сокету приложения.
SoftIRQs можно контролировать следующим образом. Каждый столбец есть ЦП:
|
# watch -n1 grep RX /proc/softirqs # watch -n1 grep TX /proc/softirqs |
NAPI Polling
Про метод поллинга читаем статью Linux, принципы работы с сетевой подсистемой
Поиск узкого места
Отбрасывание пакетов и переполнени границ (packet drops и overruns) обычно происходит, когда буфер RX сетевой карты не может достаточно быстро опустошиться ядром. Когда скорость, с которой данные поступают из сети превышает скорость, с которой ядро забирает на обработку пакеты, сетевая карта начинает отбрасывать входящие пакеты, т.к. буфер NIC (сетевой карты) полон, и увеличивает счетчик удаления.Соответствующий счетчик можно увидеть в ethtool статистике. Основные критерии здесь - прерывания и SoftIRQs.
Для примера вывод статистики ethtool:
|
# ethtool -S eth4 rx_errors: 0 tx_errors: 0 rx_dropped: 0 tx_dropped: 0 rx_length_errors: 0 rx_over_errors: 3295 rx_crc_errors: 0 rx_frame_errors: 0 rx_fifo_errors: 3295 rx_missed_errors: 3295 |
Существуют различные инструменты, доступные для поиска проблемной области. Следует исследовать:
• Уровень встроенного ПО адаптера
- Следим за статистикой ethtool -S ethX
• Уровень драйвера адаптера
• Ядро Linux, IRQs или SoftIRQs
- Проверяем /proc/interrupts и /proc/net/softnet_stat
• Уровни протокола IP, TCP, UDP
- Используем netstat -s и смотрим счетчики ошибок
Вот некоторые типичные примеры узких мест:
- Прерывания (IRQs) неправильно сбалансированы. В некоторых случаях служба irqbalance может работать неправильно или не работает вообще. Проверьте /proc/interrupts и удостоверьтесь, что прерывания распределены на разные ядра ЦП. Обратитесь к irqbalance руководству, или вручную сбалансируйте IRQs. В следующем примере прерывания становятся обработанными только одним процессором:
|
# egrep “CPU0|eth3” /proc/interrupts CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 105: 1430000 0 0 0 0 0 IR-PCI-MSI-edge eth3-rx-0 106: 1200000 0 0 0 0 0 IR-PCI-MSI-edge eth3-rx-1 107: 1399999 0 0 0 0 0 IR-PCI-MSI-edge eth3-rx-2 108: 1350000 0 0 0 0 0 IR-PCI-MSI-edge eth3-rx-3 109: 80000 0 0 0 0 0 IR-PCI-MSI-edge eth3-tx |
- Посмотрите, увеличивается ли какая-либо из колонок помимо 1-й колонки в /proc/net/softnet_stat. В следующем примере счетчик большой для CPU0, и budget должен быть увеличен:
|
# cat /proc/net/softnet_stat 0073d76b 00000000 000049ae 00000000 00000000 00000000 00000000 00000000 00000000 00000000 000000d2 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 0000015c 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
|
- SoftIRQs не может получать достаточное количество процессорного времени для опроса адаптера. Используйте инструменты, такие как sar, mpstat или top, чтобы определить, что отнимает много процессорного времени.
- Используйте ethtool -S ethX, чтобы проверить определенный адаптер:
|
# ethtool -S eth4 rx_over_errors: 399 rx_fifo_errors: 399 rx_missed_errors: 399 |
- Увеличение приемного буфера сокета приложения или использование буфера автоподстройки.
- Использование большого/малого TCP или UDP размера пакетов.
Настройка производительности
SoftIRQ
Если выполнение программных прерываний не выполняются достаточно долго, то темп роста входящих данных может превысить возможность ядра опустошить буфер. В результате буферы NIC переполнятся, и трафик будет потерян. Иногда, необходимо увеличить длительность работы SoftIRQs (программных прерываний) с CPU. За это отвечает netdev_budget. Значение по умолчанию 300. Параметр заставит процесс SoftIRQ обработать 300 пакетов от NIC перед тем как отпустить CPU:
|
# sysctl net.core.netdev_budget net.core.netdev_budget = 300 |
Это значение может быть удвоено, если 3-й столбец в /proc/net/softnet_stat увеличивается, что указывает, на то, что SoftIRQ не получил достаточно процессорного времени. Маленькие инкременты нормальны и не требуют настройки.
|
# cat softnet_stat 0073d76b 00000000 000049ae 00000000 00000000 00000000 00000000 00000000 00000000 00000000 000000d2 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 0000015c 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 0000002a 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 |
IRQ Balance
Балансировщик прерываний - это сервис, который может автоматически сбалансировать прерывания между ядрами процессора, основанного на реальном времени состояния системы.
Прерывания также можно раскидать по ядрам вручную.
Чтобы это сделать нужно выполнить команду echo N > /proc/irq/X/smp_affinity, где N - маска процессора (определяет какому процессору достанется прерывание), а X - номер прерывания, виден в первом столбце вывода /proc/interrupts. Чтобы определить маску процессора, нужно возвести 2 в степень cpu_N (номер процессора) и перевести в шестнадцатиричную систему. При помощи bc вычисляется так: echo "obase=16; $[2 ** $cpu_N]" | bc. Например:
|
#CPU0 #CPU1 #CPU2 #CPU3 |
Для того, чтобы при старте системы прерывания сами настраивались, можно сделать скрипт и настроить его запуск /etc/rc.d/rc.local.
Ethernet flow control
Паузы фреймов - управление потоком уровня Ethernet между адаптером и портом коммутатора. Адаптер передаст “кадры паузы”, когда RX или буферы TX станут полными. Коммутатор остановит поток данных в течение определенного промежутка времени в порядке миллисекунд. Этого времени обычно достаточно, чтобы позволить ядру опустошить интерфейсные буферы, таким образом предотвращая переполнение буфера и последующие пакетные отбрасывания или переполнения. В идеале, коммутатор буферизует входящие данные в течение такой паузы.
Однако, важно понимать, что этот уровень контроля потока только между коммутатором и адаптером. Если пакеты отброшены, более высокие уровни, такие как TCP или приложение в случае UDP и/или многоадресно переданы, должен инициировать восстановление.
Важно! Фреймы паузы и flow control (управление потоком) должны быть включены и на NIC и на порте коммутатора.
|
# ethtool -a eth4 Pause parameters for eth4: Autonegotiate: off RX: off TX: off # ethtool -A eth4 rx on # ethtool -A eth4 tx on # ethtool -a eth4 Pause parameters for eth4: Autonegotiate: off RX: on TX: on
|
Interrupt Coalescence (отложенные прерывания)
Отложенные прерывания рассказывают нам о количестве трафика, который будет получать сетевой интерфейс, или времи, которое проходит после приема трафика, перед выдачей жесткого прерывания. Слишком ранние прерывания или слишком частые приводят к снижению производительности системы, так как ядро останавливается (или «перебивает») запущенное задание для обработки запроса прерывания от аппаратного обеспечения. Слишком поздее прерывание может привести к тому, что пакеты достаточно долго не будут обработаны ядром с сетевой карты. Большие объемы трафика могут переписать предыдущие пакеты трафика, т.е. потеря пакетов.
Самые современные NIC и драйверы поддерживают IC, и многие позволяют драйверу автоматически модерировать количество прерываний, сгенерированных аппаратными средствами. Настройки IC обычно включают два основных компонента, время и количество пакетов. Время в мкс - сколько NIC будет ожидать прежде, чем прервать ядро, а число пакетов – сколько пакетов будет ждать в приемном буфере прежде чем сработает прерывание. Отложенные прерывания NIC можно посмотреть, используя команду ethtool -c ethX и настроить через ethtool -C ethX. Адаптивный режим позволяет карте автомодерировать IC. В адаптивном режиме, драйвер инспектирует трафик и ядро настраивает прерывания на лету, предотвращая потерю пакетов.
|
# ethtool -c eth4 Coalesce parameters for eth4: Adaptive RX: on TX: off stats-block-usecs: 0 sample-interval: 0 pkt-rate-low: 400000 pkt-rate-high: 450000 rx-usecs: 16 rx-frames: 44 rx-usecs-irq: 0 rx-frames-irq: 0 |
Следующая команда выключает адаптивный IC, и говорит адаптеру о прерывании ядра
сразу после приема любого трафика:
|
# ethtool -C eth4 adaptive-rx off rx-usecs 0 rx-frames 0 |
Очередь адаптера (The Adapter Queue)
Netdev_max_backlog - очередь в ядре Linux, где трафик хранится после получения от сетевого адаптера, но перед обработкой с помощью стеков протоколов (IP, TCP, и т.д.). Для каждого ядра процессора существует одна очередь. Очередь может расти автоматически до максимального значения, указанного в netdev_max_backlog. Функция ядра netif_receive_skb () находит соответствующий ЦП для пакета и ставит пакеты в очереди того ЦП. Если очередь для этого процессора будет полна и уже в максимальном размере, пакеты будут отброшены. Для того, чтобы тюнить это место необходимо убедиться что оно реально нужно. В /proc/net/softnet_stat в втором столбце есть счетчик, который увеличивается когда очередь переполняется. Каждая строка файла softnet_stat представляет собой ядро процессора, начиная с CPU0.
1-й столбец - количество кадров, полученных с помощью обработчика прерывания.
2-й столбец - количество фреймов, отброшенных из-за превышения netdev_max_backlog..
3-й столбец - число раз ksoftirqd исчерпал netdev_budget или процессорное время, когда нужно было еще поработать.
|
# cat softnet_stat 0073d76b 00000000 000049ae 00000000 00000000 00000000 00000000 00000000 00000000 00000000 000000d2 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 0000015c 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 0000002a 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 |
В текущем выводе netdev_max_backlog не нуждается в тюнинге, т.к. очередь не переполняется и нет потерь соответственно. Если же наблюдаются приащения в второй колонке, тогде увеличиваем значение очереди и снова смотрим в этот файл. Если увеличения этого значения мы видим что скорость приращений в втором столбце уменьшается то можно еще увеличить значение backlog. Повторяем этот процесс пока перестанет расти цифры в столбце 2.
Backlog изменить можно такой командой:
| #sysctl -w net.core.netdev_max_backlog=X |
Adapter RX and TX Buffer
Буфер адаптера по умолчанию обычно установлен в меньшем размере, чем максимальный. Часто, увеличить размер буфера приема RX вполне достаточно, чтобы предотвратить потери пакетов, так как это может приводит к тому, что у ядра будет немного больше времени, чтобы опустошить буфер. В результате, это может предотвратить возможные потери пакетов.
Буферы можно посмотреть так:
|
# ethtool -g eth4 Ring parameters for eth4: Pre-set maximums: RX: 8192 RX Mini: 0 RX Jumbo: 0 TX: 8192 Current hardware settings: RX: 1024 RX Mini: 0 RX Jumbo: 0 TX: 512 |
Тут видим что кольцевой буфер RX входящих пакетов равен 1024 дескрипторам в оперативной памяти, и можно увеличить до 8192.
Очередь передачи (Adapter Transmit Queue Length)
Длина очереди передачи определяет количество пакетов, которые могут быть поставлены в очередь перед передачей. Значение по умолчанию 1000 - обычно достаточно для сегодняшней скорости до 10 Гбит/с или даже 40 Гбит/с сетей. Однако, если число ошибок передачи увеличиваются на адаптере, то значение можно удвоить. Используйте ip -slink, чтобы увидеть, если есть какие-то потери на очереди TX для адаптера.
Увеличить длину очереди можно так:
| # ip link set dev em1 txqueuelen 2000 |
TCP Window Scaling (масштабирование окна TCP)
Размер TCP окна (TCP Window Size) – количество октетов (начиная с номера подтверждения), которое принимающая сторона готова принять в настоящий момент без подтверждения. На стадии установления соединения рабочая станция и сервер обмениваются значениями максимального размера TCP окна (TCP Window Size), которые присутствуют в пакете. Например, если размер окна получателя равен 16384 байта, то отправитель может отправить 16384 байта без остановки. Принимая во внимание, что максимальная длина сегмента (MSS) может быть 1460 байт, то отправитель сможет передать данный объем в 12 фреймах, и затем будет ждать подтверждение доставки от получателя и информации по обновлению размера окна. Если процесс прошел без ошибок, то размер окна может быть увеличен. Таким образом, реализуется размер скользящего окна в стеке протокола TCP. В современных версиях операционных систем можно увеличить размер окна TCP Window Size и включить динамическое изменение окна в зависимости от состояния канала связи. Динамическое увеличение и уменьшение размера окна является непрерывным процессом в TCP и определяет оптимальный размер окна для каждого сеанса. В очень эффективных сетях размеры окна могут стать очень большими, потому что данные не теряются.
Масштабирование Окна TCP включено по умолчанию:
| # sysctl net.ipv4.tcp_window_scaling net.ipv4.tcp_window_scaling = 1 |
TCP буфер
После того, как сетевой трафик обрабатывается от сетевого адаптера, предпринимается попытка приема трафика непосредственно в приложение. Если это не представляется возможным, данные ставятся в очередь на буфер сокета приложения. Есть 3 структуры очереди в сокете:
sk_rmem_alloc = { counter = 121948 },
sk_wmem_alloc = { counter = 553 },
sk_omem_alloc = { counter = 0 },
где:
sk_rmem_alloc – очередь получения
sk_wmem_alloc – очередь передачи
sk_omem_alloc - out-of-order queue
Существует также sk_rcvbuf переменная, которая является пределом, измеренный в байтах, что сокет может получить. В этом случае sk_rcvbuf = 125336.
Из приведенного выше вывода можно вычислить, что очередь получения почти полна. Когда sk_rmem_alloc > sk_rcvbuf то буфер начинает рушится, т.е. наблюдаются потери пакетов. Выполните следующую команду, чтобы определить, происодит это или нет:
|
# netstat -sn | egrep "prune|collap"; sleep 30; netstat -sn | egrep "prune|collap" 17671 packets pruned from receive queue because of socket buffer overrun 18671 packets pruned from receive queue because of socket buffer overrun |
Если счетчик обрезки пакетов растет, то требуется тюнинг.
tcp_rmem: У настраиваемой памяти сокета есть три значения, описывающих минимальное, значение по умолчанию и максимальное значения в байтах. Чтобы просмотреть эти настройки и увеличить:
|
# sysctl net.ipv4.tcp_rmem 4096 87380 4194304 # sysctl -w net.ipv4.tcp_rmem=“16384 349520 16777216” # sysctl net.core.rmem_max 4194304 # sysctl -w net.core.rmem_max=16777216 |
TCP Listen Backlog: отвечает за размер очереди одновременно ожидающих подключений к сокету, то есть инициированных (SYN - SYN, ACK - ACK), но еще не принятых сервером (established).
Параметр ядра net.core.somaxconn - максимальное число открытых сокетов, ждущих соединения. Изменяем:
|
# sysctl net.core.somaxconn net.core.somaxconn = 128 # sysctl -w net.core.somaxconn=2048 net.core.somaxconn = 2048 # sysctl net.core.somaxconn net.core.somaxconn = 2048 |
UDP Buffer Tuning: UDP является гораздо менее сложным, чем протокол TCP. Поскольку UDP не содержит надежности сеанса, он не несет ответственности за повторную передачу потерянных пакетов. Там не существует понятия размера окна и потерянные данные не восстанавливается протоколом. Единственная доступная настройка включает в себя увеличение размера приемного буфера. Если netstat -us показывает “packet receive errors” , попробуйте увеличить число буферов для приема. Буферы UDP могут быть настроены таким образом:
|
124928 # sysctl -w net.core.rmem_max=16777216 |
После изменения максимального размера, требуется перезапуск приложения.