Голосовые данные для синтеза речи женский что это такое
Как настроить синтезатор речи Google на Android
В то время как Google фокусируется на Помощнике, владельцы Android не должны забывать о функции синтеза речи (TTS). Она преобразует текст из Ваших приложений для Android, но Вам может потребоваться изменить его, чтобы речь звучала так, как Вы этого хотите.
Изменение синтеза речи легко сделать из меню настроек специальных возможностей Android. Вы можете изменить скорость и тон выбранного Вами голоса, а также используемый голосовой движок.
Синтезатор речи Google — это голосовой движок по умолчанию, который предварительно установлен на большинстве устройств Android. Если на Вашем Android-устройстве он не установлен, Вы можете загрузить приложение Синтезатор речи Google из Google Play Store.
Цена: БесплатноИзменение скорости речи и высоты тона
Android будет использовать настройки по умолчанию для Синтезатора речи Google, но Вам может потребоваться изменить скорость и высоту голоса, чтобы Вам было легче его понять.
Изменение скорости речи и высоты тона TTS требует, чтобы Вы попали в меню настроек специальных возможностей Google. Шаги для этого могут незначительно отличаться, в зависимости от Вашей версии Android и производителя Вашего устройства. В данной статье используется устройство Honor 8 lite, работающее на Android 8.0.
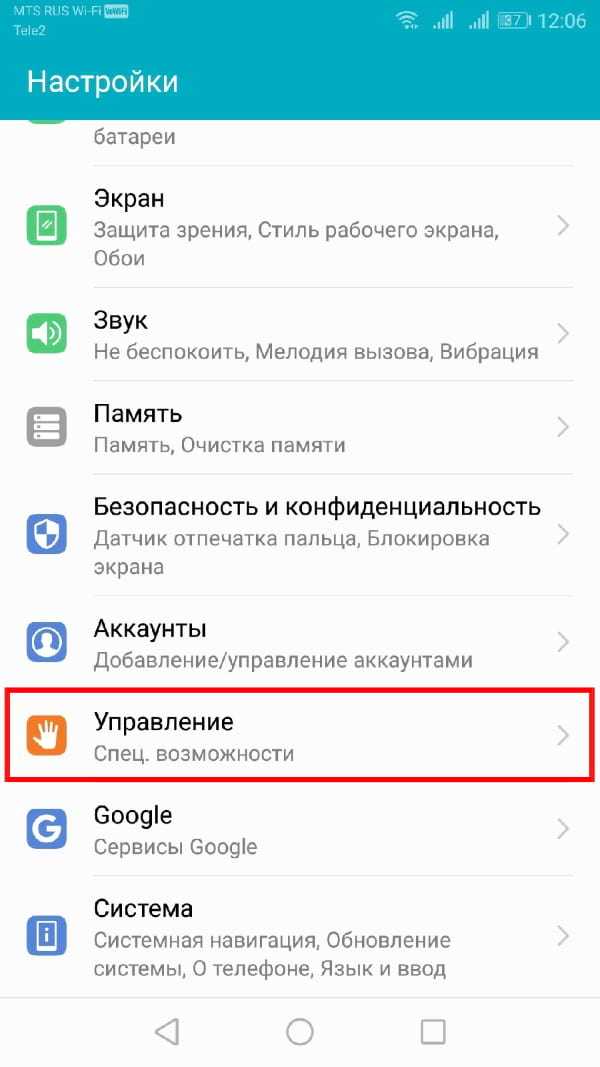
Чтобы открыть меню специальных возможностей Android, перейдите в меню «Настройки» Android. Это можно сделать, проведя пальцем вниз по экрану для доступа к панели уведомлений и нажав значок шестеренки в правом верхнем углу, или запустив приложение «Настройки» в своем списке приложений.
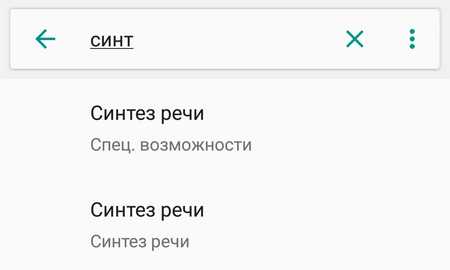
В меню «Настройки» нажмите «Управление», а оттуда «Специальные возможности».
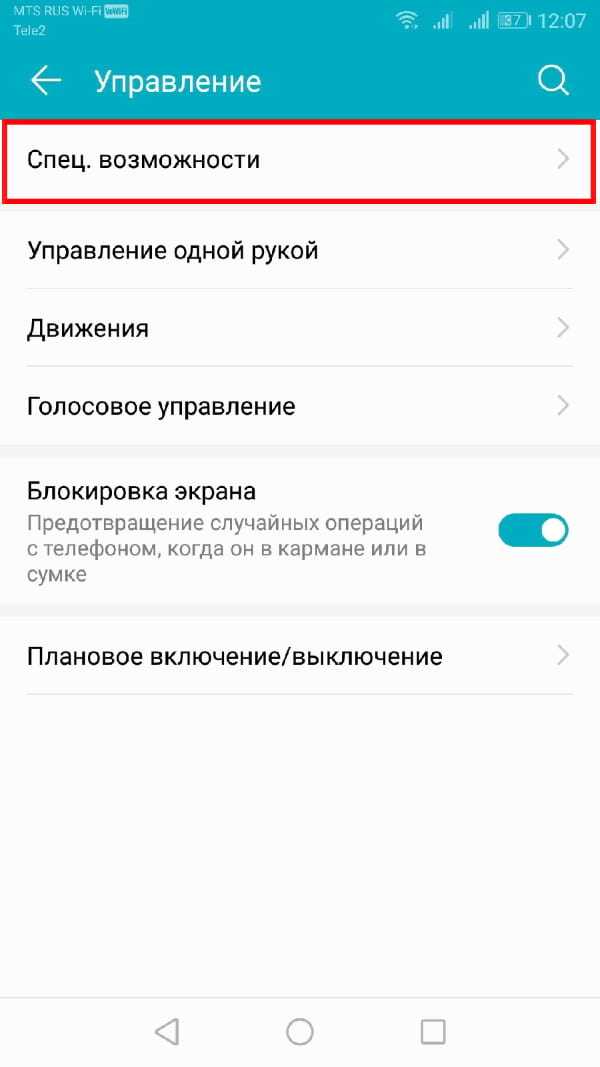
Выберите «Синтез речи».
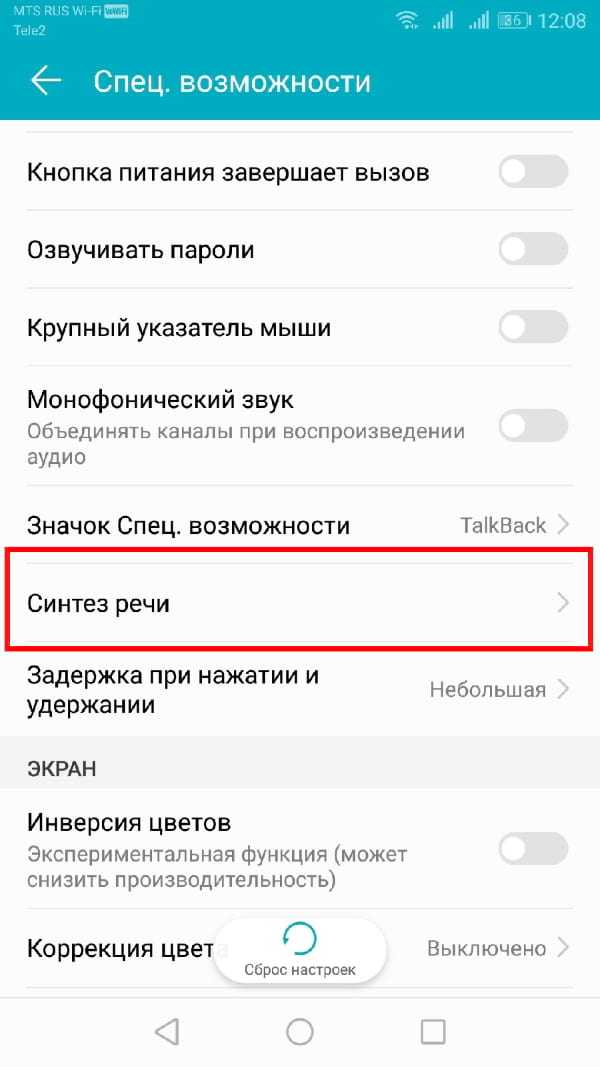
Отсюда Вы сможете изменить настройки преобразования текста в речь.
Изменение скорости речи
Скорость речи — это скорость, с которой будет говорить синтезатор речи. Если Ваш TTS движок слишком быстрый (или слишком медленный), речь может звучать искаженно или плохо для понимания.
Если Вы выполнили вышеуказанные действия, Вы должны увидеть слайдер под заголовком «Скорость речи» в меню «Синтез речи». Проведите пальцем вправо или влево, чтобы повысить или понизить скорость.
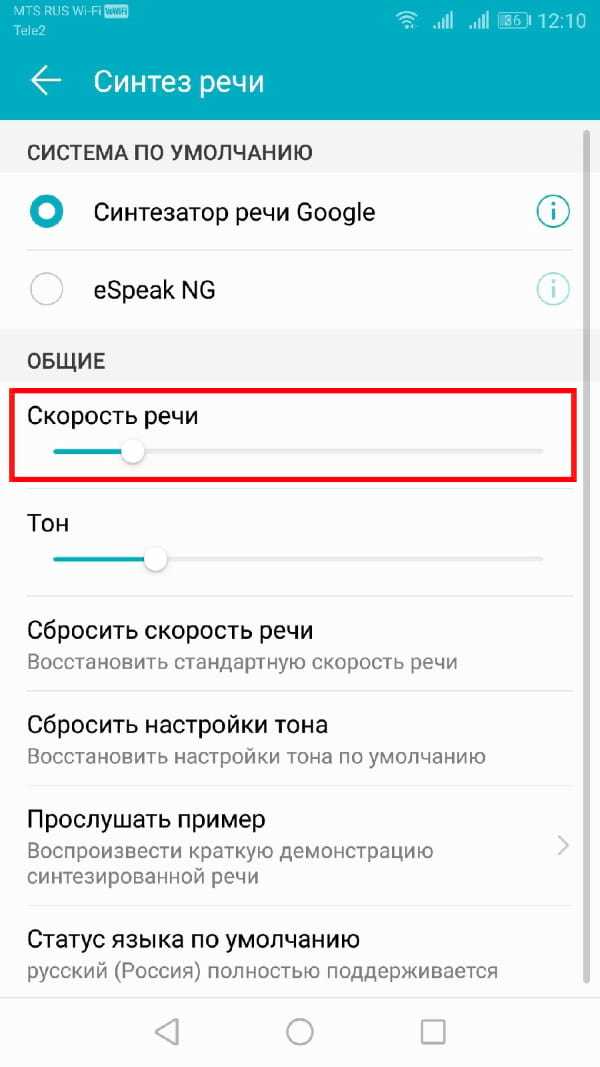
Нажмите кнопку «Прослушать пример», чтобы проверить новый уровень речи.
Изменение высоты тона
Если Вы чувствуете, что тон преобразованного текста в речь слишком высок (или низок), Вы можете изменить это, следуя тому же процессу, что и при изменении скорости речи.
Как и выше, в меню настроек «Синтез речи» отрегулируйте ползунок «Тон» в соответствии с желаемой высотой тона.
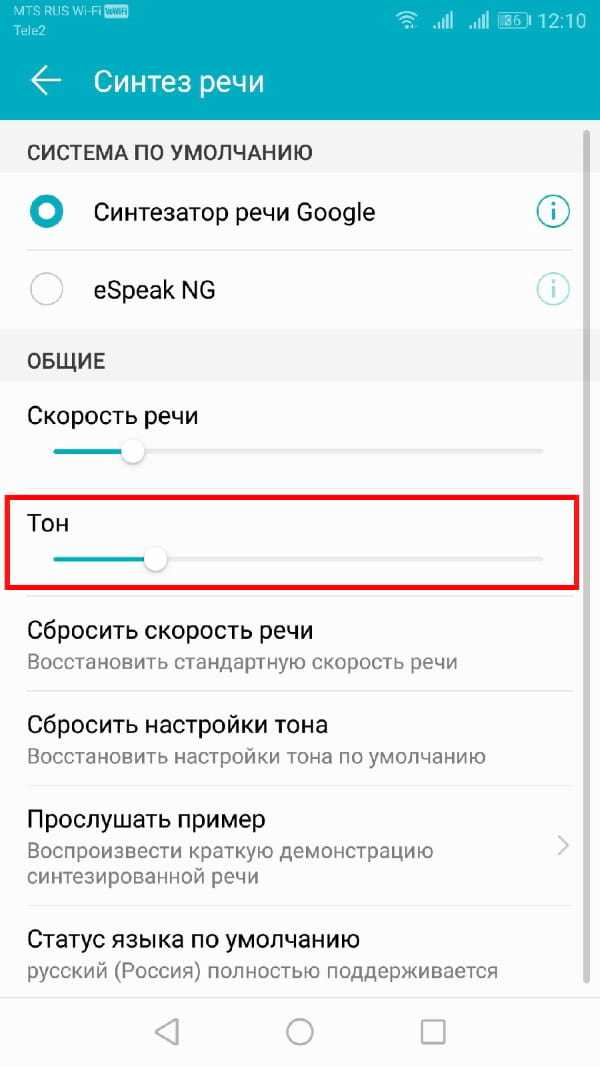
Когда Вы будете готовы, нажмите «Прослушать пример», чтобы попробовать новый вариант.
Продолжайте этот процесс, пока Вы не будете довольны настройками скорости речи и высоты тона, или нажмите «Сбросить скорость речи» и/или «Сбросить настройки тона», чтобы вернуться к настройкам TTS по умолчанию.
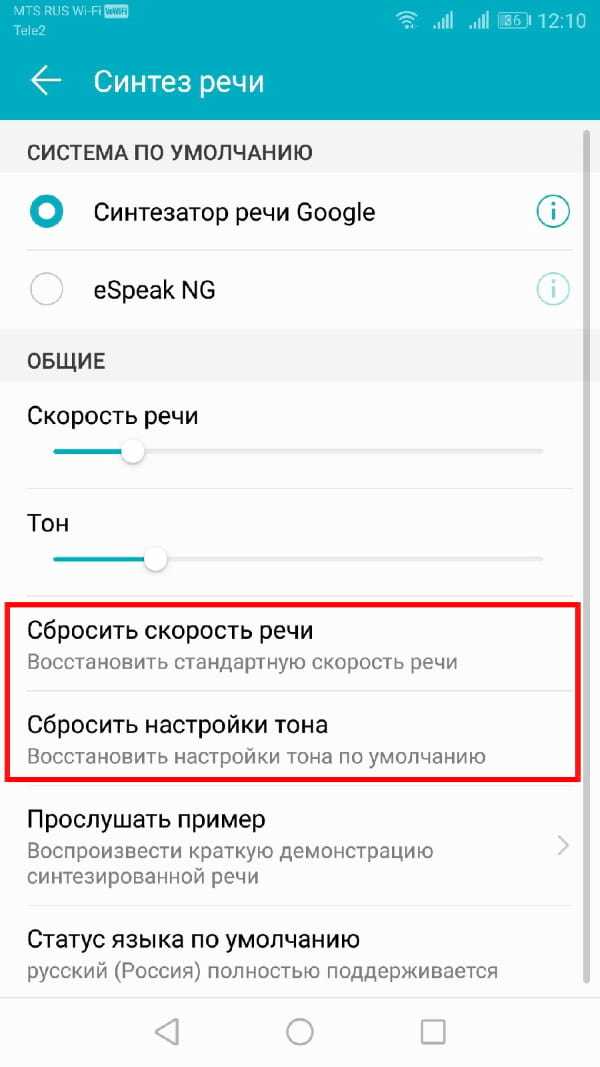
Выбор голоса синтезатора речи
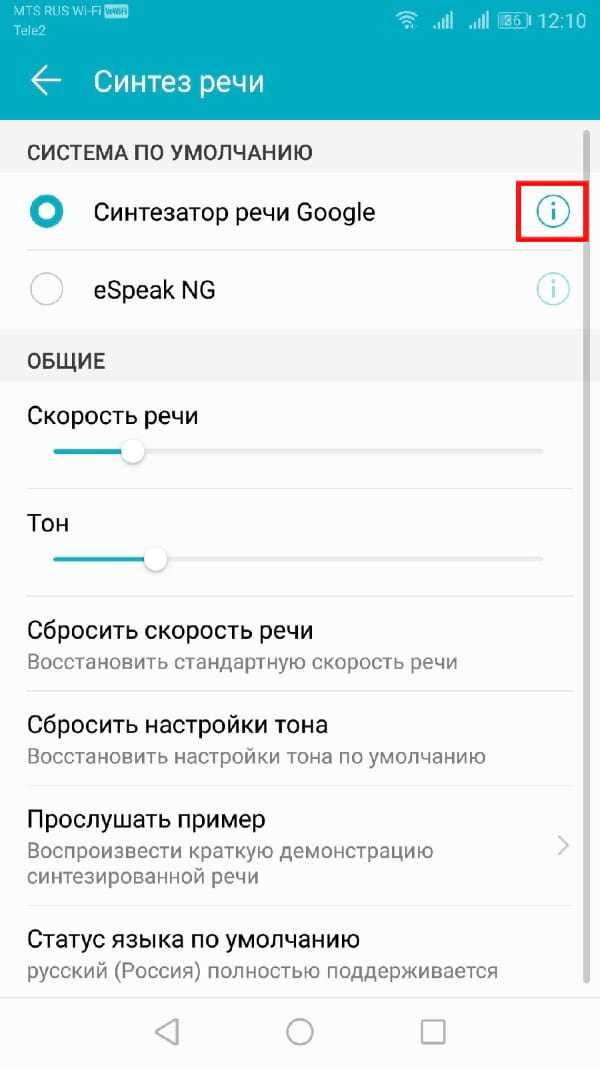
Вы можете не только изменить тон и скорость своего речевого движка TTS, но и изменить голос. Некоторые языковые пакеты, включенные в стандартный движок Синтезатор речи Google, имеют разные голоса, которые звучат как мужской, так и женский.
Если Вы используете Синтезатор речи Google, нажмите кнопку «i» рядом названием.
В меню «Настройки» нажмите «Установка голосовых данных».
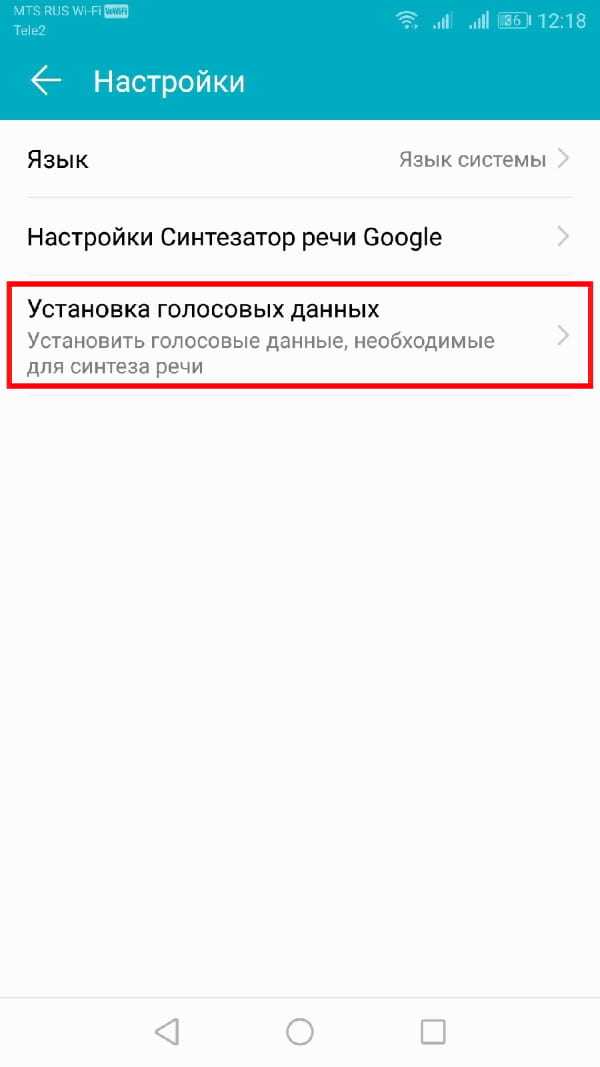
Нажмите на выбранный Вами язык.
Вы увидите различные голоса, перечисленные и пронумерованные, начиная с «Голоса I». Нажмите на каждый, чтобы услышать, как он звучит. Вы должны убедиться, что на Вашем устройстве включен звук.
Выберите голос, который Вас устраивает в качестве Вашего окончательного выбора.
Ваш выбор будет автоматически сохранен, хотя, если Вы выбрали другой язык по умолчанию для Вашего устройства, Вам также придется изменить его.
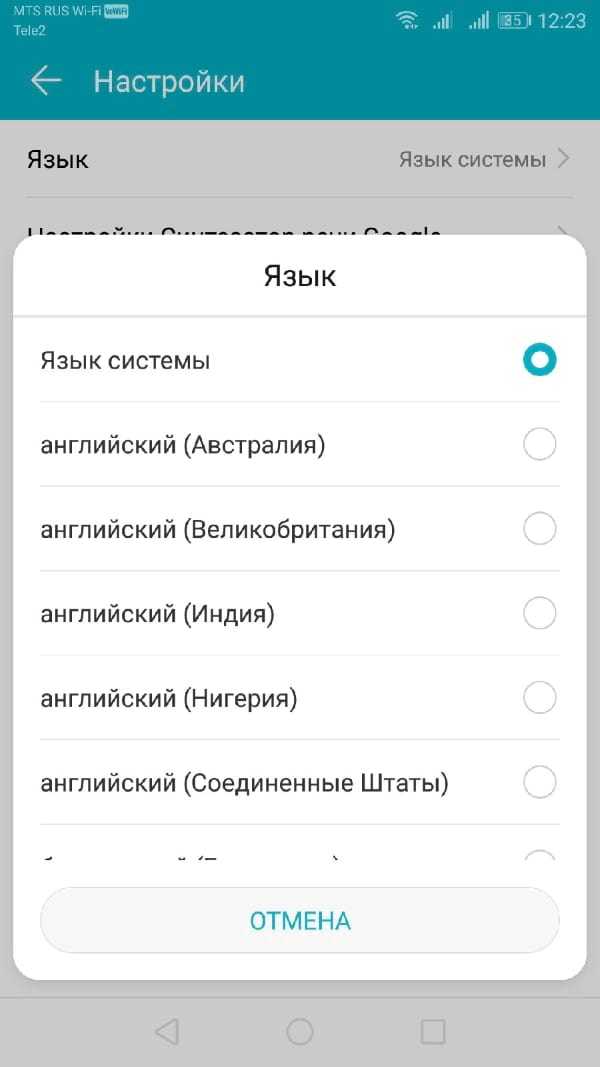
Переключение языков
Если Вам нужно переключить язык, Вы можете легко сделать это из меню настроек Синтеза речи. Возможно, Вы захотите сделать это, если Вы выбрали язык в Вашем движке TTS, отличный от языка Вашей системы по умолчанию.
Вы должны увидеть опцию «Язык». Нажмите, чтобы открыть меню.
Выберите свой язык из списка, нажав на него.
Сторонние движки синтезатора речи
Если Синтезатор речи Google Вам не подходит, Вы можете установить альтернативные варианты.
Их можно установить из Google Play Store или установить вручную. Примеры движков TTS, которые Вы можете установить, включают Acapela и eSpeak TTS, хотя доступны и другие.
Цена: Бесплатно Цена: БесплатноПосле установки из Google Play Store эти сторонние движки TTS появятся в Ваших настройках синтезатора речи.
Изменение движка синтезатора речи
Если Вы установили новый движок преобразования текста в речь и хотите его использовать, перейдите в меню настроек «Синтезатор речи».
Вверху Вы должны увидеть список доступных Вам движков TTS.
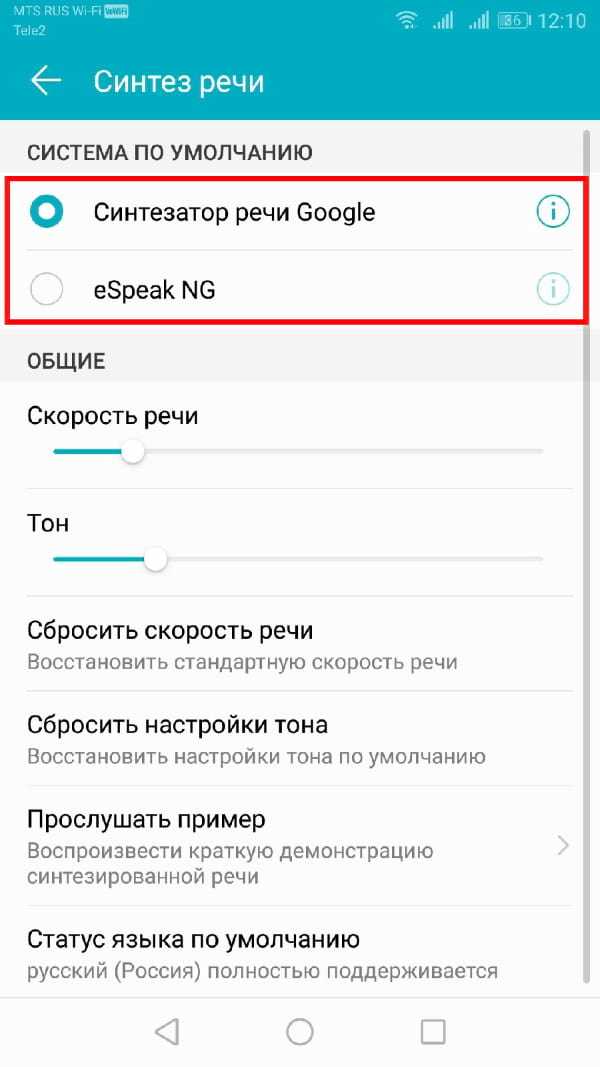
Нажмите на предпочитаемый Вами движок.
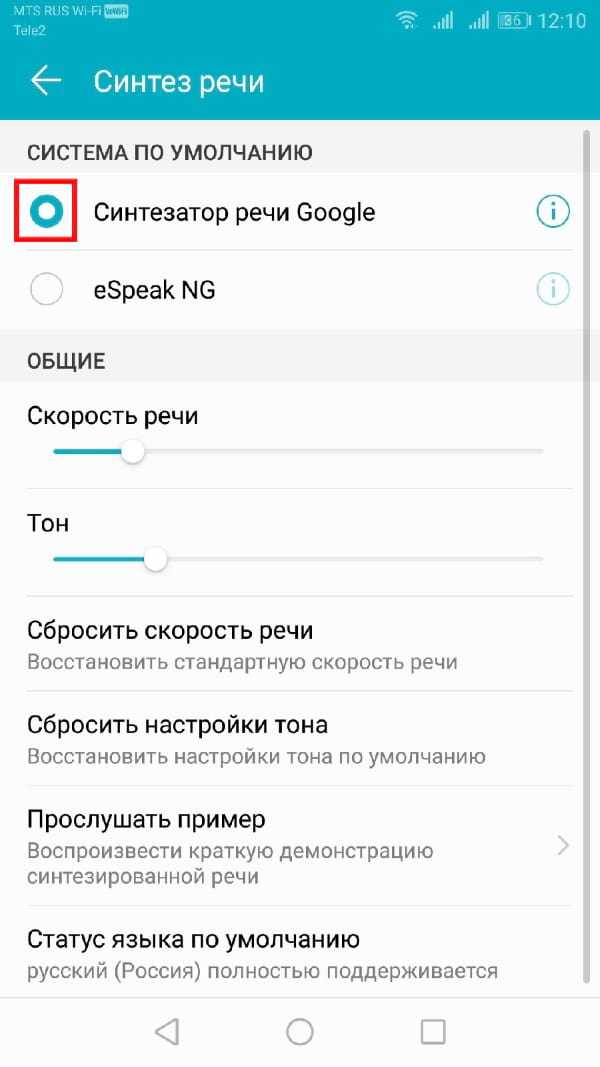
Выбрав новый движок TTS, нажмите «Прослушать пример», чтобы проверить его.
Для большинства пользователей стандартный текстовый движок Google будет предлагать лучшее звучание речи, но сторонние приложения могут лучше работать для других языков, где движок по умолчанию не подходит.
Как только Ваш движок и язык выбраны, Вы можете свободно использовать его с любым приложением для Android, которое его поддерживает.
Голосовой DeepFake, или Как работает технология клонирования голоса
Как научить искусственный интеллект читать текст любым голосом? Рассказываем, что известно о технологии клонирования голоса, на примере открытого репозитория Real-Time Voice Cloning.
Проблема синтеза речи из текста (Text-to-Speech, TTS) представляет собой одну из классических задач для искусственного интеллекта. Цель ИИ – автоматизировать процесс чтения текста, основываясь на наборах данных, содержащих пары «текст – аудиофайл».
Одной из важных проблем синтеза речи является задача создания образа голоса со всеми его характерными особенностями. Соответствующие наборы методик называют технологией клонирования голоса (англ. voice changing, voice cloning).
Решение указанной проблемы имеет множество практических приложений:
- адаптация голосов актёров при локализации фильмов
- озвучивание персонажей игр
- голосовые поздравления
- начитка аудиокниг, в том числе клонирование голосов родителей для сказок, прочитанных профессиональными дикторами
- создание аудио- и видеокурсов
- рекламные видеоролики и аудиореклама
- голоса ботов и умных устройств, персонализированных голосовых помощников
- синтез устной речи естественного звучания для немых людей, в том числе для людей, утративших возможность говорить из примеров их собственной речи
- адаптация устной речи под модель местного акцента
Очевидно, что подобные технологии могут применяться с преступными целями: мошенничество, телефонное хулиганство, компрометирование в результате совмещения с технологией DeepFake. Поэтому кроме методов клонирования голоса важно разрабатывать средства для предотвращения незаконного использования технологии.
Для обучения системы необходимо иметь большое количество сопоставленных аудиозаписей и текстов. В случае голосов знаменитостей можно прибегать к помощи записей публичных выступлений, интервью, результатам творческой деятельности и т. п. В качестве текстовых пар могут применяться стенограммы или тексты, полученные в результате коррекции автоматически распознанной речи.
Отличительной особенностью последних разработок является то, что для создания правдоподобного образа «голосовой мишени» достаточно всё меньших интервалов звучащей устной речи.
Современное состояние
В сфере создания инструментов для клонирования голоса работают множество команд, стремящихся к коммерциализации программных продуктов. По приведённым ниже ссылкам вы можете оценить текущее состояние технологии:
- Resemble.AI (предоставляется демоверсия программы).
- iSpeech (есть демо для 27 языков, включая русский).
- Lyrebird AI (можно загрузить демоверсию на 3 часа речи).
- Vera Voice, созданный компанией Screenlife Technologies Тимура Бекмамбетова и командой проекта «Робот Вера». Недавно команда показала пример адаптации голосов русских знаменитостей:
Другие компании стараются обойти стороной этический вопрос за счёт использования вместо клонирования голоса нейросетевых систем синтеза-смешения множества голосов. Таким коммерческим продуктом является, например, Yandex SpeechKit.
В связи с тем, что данная технология представляет конкурентный интерес для множества IT-компаний, проекты с открытым исходным кодом крайне редки. В этой статье мы остановимся на редком свободном проекте Real-Time Voice Cloning. Этот открытый репозиторий является результатом применения технологии переноса обучения SV2TTS, описанной в научной публикации (сэмплы, полученные в результате применения подхода).
Автор библиотеки с июня 2019 участвует в упомянутом выше коммерческом проекте Resemble.AI и уделяет репозиторию меньше времени, но ничто не мешает вам сделать собственный форк проекта.
Алгоритм клонирования голоса
Чтобы компьютер мог читать вслух текст, ему нужно понимать две вещи: что он читает и как это произнести. Поэтому в проекте Real-Time Voice Cloning система клонирования принимает два входных источника: текст, который необходимо озвучить, и образец голоса, которым этот текст должен быть прочитан.

С технической точки зрения система разбита на три компонента:
- Переданный аудиофайл с образцом речи, записанным в виде звуковой дорожки, преобразуется кодером речи (speaker encoder) в векторное представление фиксированной размерности.
- Переданный текст также кодируется в векторное представлении кодером текста (text encoder). Объединение речевого вектора и вектора текста декодируется в спектрограмму. Кодер текста, конкатенатор векторов и декодер (на схеме объединены синим цветом) представляют собой структуру синтезатора речи.
- Вокодер (vocoder, виртуальное устройство синтеза речи) преобразует спектрограмму в звуковую форму.
Модели трёх выделенных компонентов обучаются независимо друг от друга.
Где взять данные?
Объёмы информации, необходимой для качественного обучения системы клонирования, составляют десятки и сотни Гб. В рассматриваемой библиотеке для хранения датасетов служит одна общая директория. Все сценарии предварительной обработки данных выводят результаты в новый каталог SV2TTS, создаваемый в корневом каталоге датасетов. Внутри этой директории появится каталог для каждой модели: кодера, синтезатора и вокодера.
Для обучения кодера речи можно обратиться к следующим библиотекам:
- LibriSpeech (зеркало): набор данных
train-other-500(извлеките какLibriSpeech/train-other-500). - VoxCeleb1: наборы данных
Dev A–D,в том числе набор метаданных (извлеките какVoxCeleb1/wavиVoxCeleb1/vox1_meta.csv). - VoxCeleb2: наборы данных
Dev A–H(извлеките какVoxCeleb2/dev).
Для обучения синтезатор и вокодера:
- LibriSpeech: наборы данных train-clean-100 (зеркало) и train-clean-360 (зеркало) – извлеките как
LibriSpeech/train-clean-100andLibriSpeech/train-clean-360 - LibriSpeech alignments (только если у вас уже есть LibriSpeech): объедините структуру каталогов с загруженными вами наборами данных LibriSpeech
Официальным хостингом наиболее популярных наборов данных LibriSpeech служит openslr.org, который из-за популярности темы постоянно находится под существенной нагрузкой. Поэтому выше мы приложили ссылки на «зеркала» архивов.
Если вы решили с головой погрузиться в данную тему, обратите внимание на библиотеку Python для работы с аудиодатасетами audiodatasets:
pip install audiodatasets Будьте осторожны: при установке библиотека загружает более 100 Гб данных трех наборов:
Перечислим также другие датасеты, которые не проверялись в рассматриваемой библиотеке, но применимы для обучения, в том числе корпуса русскоязычной устной речи:
- Корпус речи англоговорящих людей CSTR VCTK
- Набор данных M-AILABS: имеются примеры речи на русском, украинском, немецком, английском, испанском, итальянском, французском и польском языках
- Корпуса звучащей русской речи
- Мультимедийный корпус русского языка: преимущественно фрагменты кинофильмов с распознанным текстом
- Подборка различных речевых датасетов
Использование предобученных моделей
Имеется инструкция по переносу проекта с помощью Docker, здесь мы рассмотрим установку на локальной машине. Учтите, что наличие GPU является обязательным. Клонируем репозиторий:
git clone https://github.com/CorentinJ/Real-Time-Voice-Cloning.git В качестве языка программирования используется Python 3, автор рекомендует версию 3.7. В связи с тем, что репозиторий предполагает привлечение вполне конкретных версий библиотек, рекомендуем питонистам пускать в ход виртуальное окружение.
Переходим в папку и устанавливаем необходимые зависимости:
pip3 install -r requirements.txt Также потребуется фреймворк глубокого обучения PyTorch (версия не ниже 1.0.1).
Далее необходимо загрузить предобученные модели (архив на Google drive, зеркало). Согласно с вышеописанной схеме загруженный архив содержит три директории для трех моделей. Их нужно слить вместе с соответствующими директориями корневого каталога библиотеки.
Проверить правильность конфигурации можно ещё до загрузки датасетов:
python3 demo_cli.py Если все тесты пройдены (вы увидите строку All tests passed), можно двигаться дальше. Скрипт предложит указать пути к файлам примеров, но для работы удобнее обратиться кграфическому интерфейсу:
python3 demo_toolbox.py Если у вас уже загружены датасеты, то можно сразу указать путь к директории:
python3 demo_toolbox.py -d <путь_к_директории_датасетов> Чтобы просто поиграть с программой, достаточно наименьшего по объёму датасета LibriSpeech/train-clean-100 (см. выше).
Пример результата вызова интерфейса:

Для первой пробы вы можете нажать под каждым разделом кнопки Random , чтобы выбрать случайный аудиопример, затем Load, чтобы загрузить голосовой ввод в систему. Выпадающий список Dataset служит для выбора набора данных, Speaker – для выбора персоны, Utterance – для произносимой фразы. Чтобы услышать как звучит отрывок, просто нажмите Play. Для запуска алгоритма нажмите Synthesize and vocode. С помощью кнопки Record one можно записать свой собственный сэмпл.
Пример работы с интерфейсом без обучения нейросетей представлен в следующем видеоролике:
Процесс обучения
Вместо предобученных моделей можно также задействовать модели, обученные на других примерах. Процесс обучения происходит посредством последовательного запуска скриптов той же библиотеки. Для того, чтобы узнать дополнительную информацию о каждом из скриптов, при используйте запуске из командной строки добавляйте аргумент -h.
Начинаем с подготовки данных для обучения кодера:
python3 encoder_preprocess.py <datasets_root> Для обучения кодер использует окружение visdom. Инструменты окружения выглядят следующим образом:

При необходимости вы можете отключить окружение с помощью аргумента --no_visdom .
Обучаем кодер:
python3 encoder_train.py my_run <datasets_root> Далее запускаем два скрипта, генерирующих данные для синтезатора. Начинаем с аудиофайлов:
python3 synthesizer_preprocess_audio.py <datasets_root> Затем вложения:
python3 synthesizer_preprocess_embeds.py <datasets_root>/synthesizer Теперь вы можете обучить синтезатор:
python3 synthesizer_train.py my_run <datasets_root>/synthesizer Синтезатор будет выводить сгенерированные аудио и спектрограммы в каталог моделей. Используем синтезатор для генерации обучающих данных вокодера:
python3 vocoder_preprocess.py <datasets_root> Наконец, обучаем вокодер:
python3 vocoder_train.py <datasets_root> Вокодер выводит сгенерированные аудиофайлы в директорию модели.
При возникновении вопросов относительно работы библиотеки мы также рекомендуем ознакомиться с диссертацией автора. Там же приведены ссылки на научные работы, посвящённые теме клонирования и изменения голоса.
Интересны ли вам проекты, связанные с дипфейками лиц и голоса? Будем рады вашим ответам в комментариях.
Как выбрать другой голос в синтезаторе речи Google на Android смартфоне
Синтезатор речи Google поставляется со всеми смартфонами на базе ОС Android. Это обуславливается не только выбором разработчика, но и качеством данного приложения TTS. Но не все догадываются, что в последних обновлениях синтезатор обзавёлся перечнем новых русских голосов наряду с уже известным женским тембром.

Выбор доступных русских голосов от Google
Для того чтобы ознакомиться с новинками голосов, следует перейти в настройки синтеза речи. У меня на смартфоне (Android 5.x) этот пункт доступен в разделе «Язык и ввод». Пользователи же сервиса «Talkback” могут найти его в списке «глобального контекстного меню».
Примечание! Незрячие пользователи «Talkback» также могут установить отличный от стандартного голос. Только все манипуляции по настройке выполняются в соответствии с возможностями программы экранного доступа.
Вместо послесловия
Надеемся,что данная информация поможет разнообразить голосовые ответы вашего смартфона. А любители почитать смогут по достоинству оценить новые голоса в приложении FbReader, которое предоставляет чтение книг вслух.
поделитесь с друзьями:
ВКонтакте
OK
5 лучших синтезаторов речи с русскими голосами
Все чаще в повседневной жизни стали использовать синтезаторы речи. Синтезаторы речи, как становится видно уже по одному названию, осуществляют синтез речи, то есть форматируют письменный текст в устный.
Благодаря этому можно учить новые иностранные слова с правильным произношением, читать книги не отвлекаясь от своих дел или, например, находясь в транспорте. Изначально разработкой таких программ занимались организации, специализирующиеся на технике для людей с проблемами зрения.
Сейчас же, любой пользователь может скачать одну из программ, установить ее на свой компьютер или телефон и синтезировать речь, в том числе и русскую.
Для этого было разработано множество различных программ, приложенный и даже целых систем. К сожалению, не все из них предназначены для русскоязычной аудитории.
Содержание статьи:
Список синтезаторов речи:
1. Acapela
Acapela — один из самых распространенных речевых синтезаторов во всем мире. Программа распознает и озвучивает тексты более, чем на тридцати языках. Русский язык поддерживается двумя голосами: мужской голос — Николай, женский — Алена.
Женский голос появился значительно позднее мужского и является более усовершенствованным.
Прослушать, как звучат голоса, можно на официальном сайте программы. Достаточно лишь выбрать язык и голос, и набрать свой небольшой текст.
Кстати, для мужского голоса был разработан отдельный словарь ударений, что позволяет достичь еще большей четкости произношения.
Установка программы проходит без проблем. Разработаны версии для операционных систем Windows, Linux, Mac, а также для мобильных ОС Android u IOS.
Программа платная, скачать ее можно с официального сайта Acapela.
2. Vokalizer
Вторым в нашем списке, но не по популярности является движок Милена от разработчика программы Vocalizer компании Nuance.
Голос звучит очень естественно, речь чистая. Есть возможность установить различные словари, а также подкорректировать громкость, скорость и ударение, что не маловажно.
Как и в случае с Акапелой, программа имеет различные версии для мобильных, автомобильных и компьютерных приложений. Прекрасно подходит для чтения книг.
Скачать все версии Vokalizer и русскоязычный движок Милена можно на официальном сайте производителя программы.
3. RHVoice
Синтезатор речи RHVoice был разработан Ольгой Яковлевой. Программа озвучивает русские тексты тремя голосами: Елена, Ирина и Александр. Подробнее об установке и применении, а также прослушать голоса Вы сможете в прошлой статье
Код синтезатора открыт для всех, программы же абсолютно бесплатны.
RHVoice выпущена в двух вариантах: как отдельная программа, так и как приложение к NVDA.
Все версии можно скачать с официального сайта разработчика.
4. ESpeak
Первая версия бесплатного синтезатора речи eSpeak была выпущена в 2006 году. С тех пор компания-разработчик постоянно выпускает все более усовершенствованные версии. Последняя версия была представлена в конце весны две тысячи тринадцатого года.
eSpeak можно установить под следующие операционные системы:
- Microsoft Windows,
- Mac OS X,
- Linux,
- RISC OS
Возможна также компиляция кода для Windows Mobile, но делать ее придется самостоятельно.
А вот с мобильной ОС Android программа работает без проблем, хотя русские словари еще не до конца разработаны. Русскоязычных голосов много, можно выбрать на свой вкус.
Для разработчиков будет интересно узнать, что C++ код программы доступен в сети. Скачать программу, а также посмотреть ее код можно на официальном сайте.
5. Festival
Festival — это целая система распознавания и синтеза речи, которая была разработана в эдинбургском университете.
Программы и все модули абсолютно бесплатно и распространяются по системе open source. Скачать их и ознакомиться с демо-версиями можно на официальном сайте университета Эдинбурга.
Русский голос представлен в одном варианте, но звучание довольно хорошее и ясное, без акцента и с правильной расстановкой ударений.
К сожалению, программа пока может быть установлена только в среде API, Linux. Также есть модуль для работы в Mac OS, но русский язык пока поддерживается не очень хорошо.
Вместо послесловия
Стоит отметить, что любой из вышеприведённых синтезаторов отлично исполнен, но выбор программы индивидуален. Всё объясняется различным произношением голосов. Смею посоветовать второй вариант с голосом Милена. ОЧень выразительный голос, насыщенное звучание и приятная во всех смыслах интонация голоса!
поделитесь с друзьями:
ВКонтакте
OK
Синтезаторы речи с русскими голосами как у робота. Лучшие Синтезаторы речи. |

Понадобилось нам сделать ролик с голосом как у робота из шедевра под названием «Месть «кожаным ублюдкам»: пародийное видео о роботах Boston Dynamics, которым надоело угнетение со стороны людей. Среди русскоязычных пользователей соцсетей видео от Boston Dynamics стали мемом из-за традиционных озвучек. В них роботы называют людей кожаными ублюдками и обещают однажды отомстить.
окончательное решение человеческого вопроса pic.twitter.com/W5S0tHCmUr
— игарь (@interiorsha) June 15, 2019
В пародии люди, играющие сотрудников Boston Dynamics избивают «робота», напоминающего модель ATLAS. В итоге машина устраивает бунт и атакует тех, кто его угнетал. Роль ATLAS тоже сыграл человек — подробнее о процессе создания пародии можно посмотреть в отдельном ролике.
Мы немного отошли от темы. Так вот, покопавшись в сети. Вот что мы нашли для себя:
Как записать голос Гугл Мужика / Ivona Maxim
Список синтезаторов речи:
1. Google Переводчик также можно использовать для синтезирования речи
- Для работы с ним выполните вход на данный сервис (вот здесь).
- Выберите в окне слева русский язык, и нажмите на кнопочку с динамиком снизу «Прослушать».
Качество воспроизведения на довольно сносном уровне, но не более.
2. Text-to-speech — синтезатор речи онлайн
Ещё один ресурс, осуществляющий синтез речи нормального качества. Бесплатный функционал ограничен набором текста длиной 1000 символов.
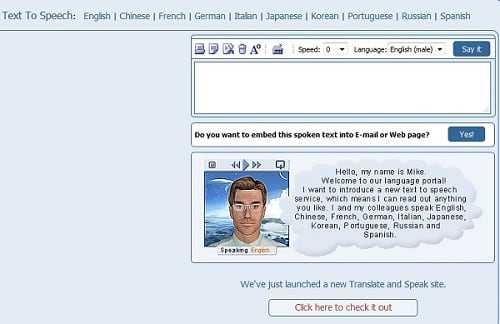
- Для работы с сервисом перейдите на данный сайт, в окне справа рядом с опцией «Language» (язык) выберите Russian.
- В окне наберите (или скопируйте с внешнего источника) требуемый текст, а затем нажмите на кнопку справа «Say It».
- Линк на произношение указанного текста можно также разместить в вашем е-мейле или веб-странице, кликнув на кнопку «Yes» чуть ниже.
Альтернативные программы для ПК для перевода текста в речь
Также существует программы для синтеза речи, такие как TextSpeechPro AudioBookMaker, ESpeak, Voice Reader 15, ГОЛОС и ряд других, способные конвертируют текст в речь. Их необходимо скачать и установить на свой компьютер, а функционал и возможности данных продуктов обычно чуть превышает возможности рассмотренных онлайн-сервисов.
3. Ivona — лучший синтезатор речи
Голосовые движки данного онлайн сервиса отличаются очень высоким качеством, хорошей фонетической основой, звучат достаточно естественно и «металлический» компьютерный голос здесь чувствуется гораздо реже, нежели у сервисов-конкурентов.
Сервис Ivona имеет поддержку множества языков, в русском варианте присутствуют мужской голос (Maxim) и женский (Tatyana). К сожалению у них что-то с сайтом. И доступа нет. https://www.ivona.com/us/
4. Acapela
Acapela — один из самых распространенных речевых синтезаторов во всем мире. Программа распознает и озвучивает тексты более, чем на тридцати языках. Русский язык поддерживается двумя голосами: мужской голос — Николай, женский — Алена.
Женский голос появился значительно позднее мужского и является более усовершенствованным.
- Чтобы воспользоваться функционалом ресурса откройте указанный сервис, слева в окне выберите русский язык (Select a language – Russian).
- Вставьте внизу нужный текст и нажмите на кнопку «Listen» (слушать).
Максимальный размер текста для аудиопрочтения — 300 символов.
Прослушать, как звучат голоса, можно на официальном сайте программы. Достаточно лишь выбрать язык и голос, и набрать свой небольшой текст.
Кстати, для мужского голоса был разработан отдельный словарь ударений, что позволяет достичь еще большей четкости произношения.
Установка программы проходит без проблем. Разработаны версии для операционных систем Windows, Linux, Mac, а также для мобильных ОС Android u IOS.
Программа платная, скачать ее можно с официального сайта Acapela.
5. Vokalizer
Вторым в нашем списке, но не по популярности является движок Милена от разработчика программы Vocalizer компании Nuance.
Голос звучит очень естественно, речь чистая. Есть возможность установить различные словари, а также подкорректировать громкость, скорость и ударение, что не маловажно.
Как и в случае с Акапелой, программа имеет различные версии для мобильных, автомобильных и компьютерных приложений. Прекрасно подходит для чтения книг.
Скачать все версии Vokalizer и русскоязычный движок Милена можно на официальном сайте производителя программы.
6. ESpeak
Первая версия бесплатного синтезатора речи eSpeak была выпущена в 2006 году. С тех пор компания-разработчик постоянно выпускает все более усовершенствованные версии. Последняя версия была представлена в конце весны две тысячи тринадцатого года.
eSpeak можно установить под следующие операционные системы:
- Microsoft Windows,
- Mac OS X,
- Linux,
- RISC OS
Возможна также компиляция кода для Windows Mobile, но делать ее придется самостоятельно.
А вот с мобильной ОС Android программа работает без проблем, хотя русские словари еще не до конца разработаны. Русскоязычных голосов много, можно выбрать на свой вкус.
Для разработчиков будет интересно узнать, что C++ код программы доступен в сети. Скачать программу, а также посмотреть ее код можно на официальном сайте.
7. Festival
Festival — это целая система распознавания и синтеза речи, которая была разработана в эдинбургском университете.
Программы и все модули абсолютно бесплатно и распространяются по системе open source. Скачать их и ознакомиться с демо-версиями можно на официальном сайте университета Эдинбурга.
Русский голос представлен в одном варианте, но звучание довольно хорошее и ясное, без акцента и с правильной расстановкой ударений.
К сожалению, программа пока может быть установлена только в среде API, Linux. Также есть модуль для работы в Mac OS, но русский язык пока поддерживается не очень хорошо.
На компьютере Гугл не предоставляет каких-либо легко доступных средств для озвучки текста за исключением Переводчика, в котором подбор голоса определяется автоматически и может быть изменен только путем смены языка. Однако для Android-устройств существует специальное приложение, которое по необходимости может быть загружено из магазина Google Play.
Перейти к странице Google Text-to-Speech
-
- Рассматриваемое ПО не является полноценным приложением и представляет собой пакет языковых настроек, доступных из соответствующего раздела. Для изменения голоса откройте страницу «Настройки», найдите блок «Личные данные» и выберите «Язык и ввод».
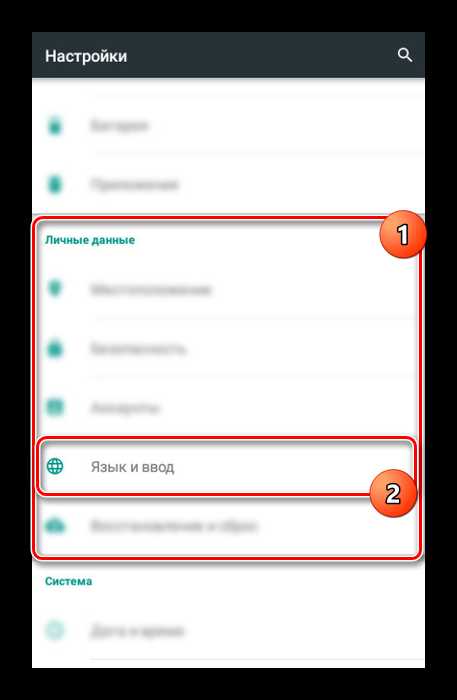 Дальше необходимо найти раздел «Голосовой ввод» и выбрать «Синтез речи».
Дальше необходимо найти раздел «Голосовой ввод» и выбрать «Синтез речи».
- Рассматриваемое ПО не является полноценным приложением и представляет собой пакет языковых настроек, доступных из соответствующего раздела. Для изменения голоса откройте страницу «Настройки», найдите блок «Личные данные» и выберите «Язык и ввод».
-
- Если по умолчанию выставлен какой-либо другой пакет, самостоятельно выберите вариант «Синтезатор речи Google». Процедуру активации потребуется подтвердить с помощью диалогового окна.
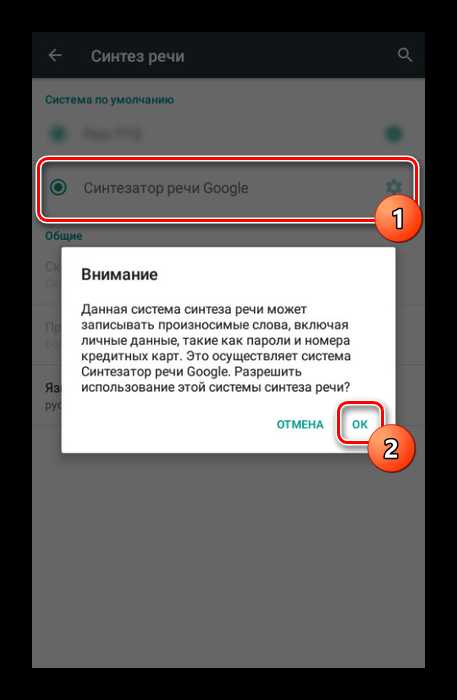 После этого станут доступны дополнительные параметры.
После этого станут доступны дополнительные параметры.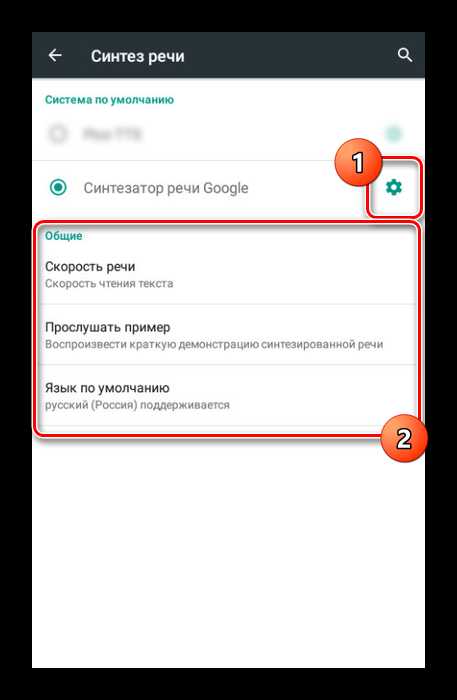 В разделе «Скорость речи» можно выбрать темп голоса и сразу же проверить результат на предыдущей странице.
В разделе «Скорость речи» можно выбрать темп голоса и сразу же проверить результат на предыдущей странице.Примечание: Если приложение было скачано вручную, сначала нужно загрузить языковой пакет.
- Если по умолчанию выставлен какой-либо другой пакет, самостоятельно выберите вариант «Синтезатор речи Google». Процедуру активации потребуется подтвердить с помощью диалогового окна.
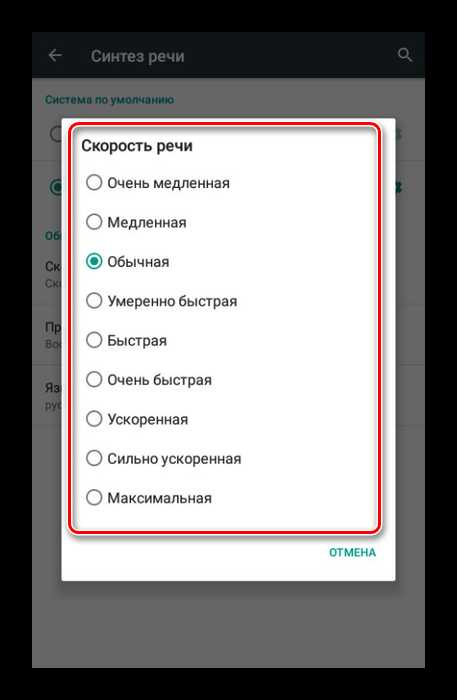
-
- Нажмите по значку шестерни рядом с пунктом «Синтезатор речи Google», чтобы перейти к параметрам языка.
 С помощью первого меню вы можете изменить язык, будь то установленный в системе или любой другой. По умолчанию приложением поддерживаются все распространенные языки, включая русский.
С помощью первого меню вы можете изменить язык, будь то установленный в системе или любой другой. По умолчанию приложением поддерживаются все распространенные языки, включая русский.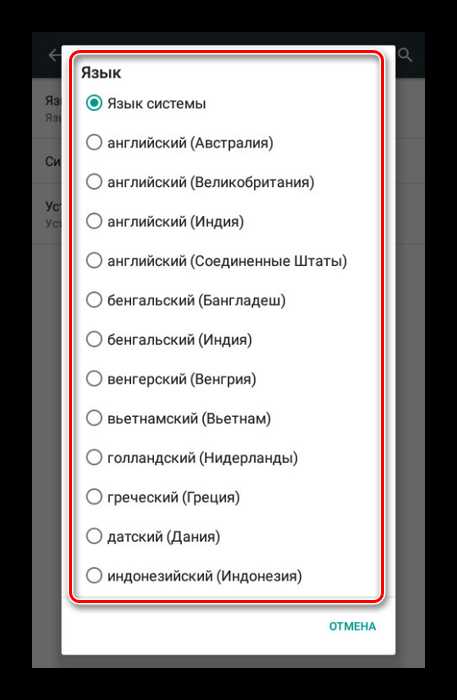 В разделе «Синтезатор речи Google» представлены параметры, путем изменения которых можно контролировать произношение слов. Кроме того, здесь можно перейти к написанию отзыва или указать сеть для скачивания новых пакетов.
В разделе «Синтезатор речи Google» представлены параметры, путем изменения которых можно контролировать произношение слов. Кроме того, здесь можно перейти к написанию отзыва или указать сеть для скачивания новых пакетов.
- Нажмите по значку шестерни рядом с пунктом «Синтезатор речи Google», чтобы перейти к параметрам языка.
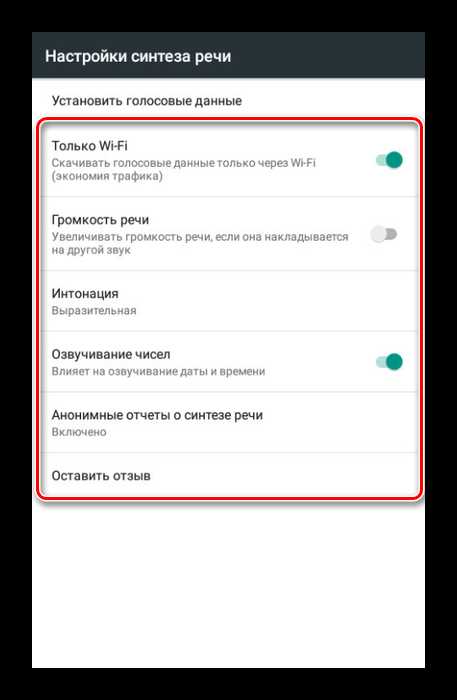
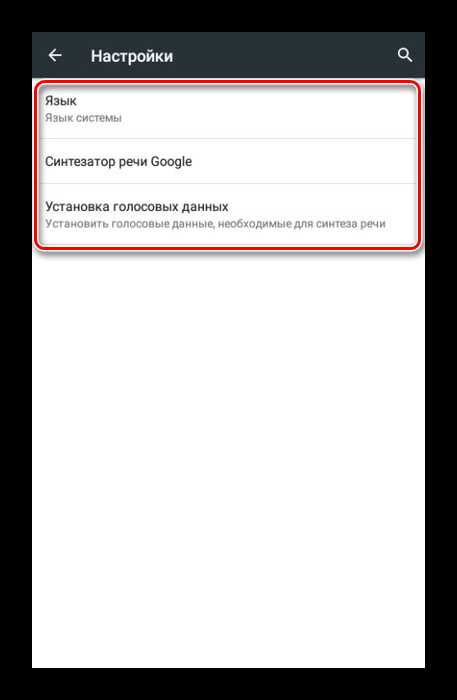
-
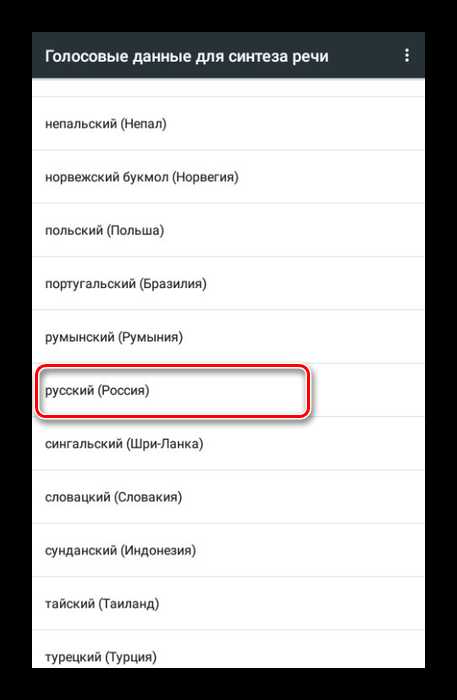
- Выбрав пункт «Установка голосовых данных», вы откроете страницу с доступными языками озвучки. Найдите нужный вариант и установите рядом с ним маркер выделения.
 Дождитесь завершения процедуры скачивания. Иногда для начала загрузки может потребоваться ручное подтверждение.
Дождитесь завершения процедуры скачивания. Иногда для начала загрузки может потребоваться ручное подтверждение.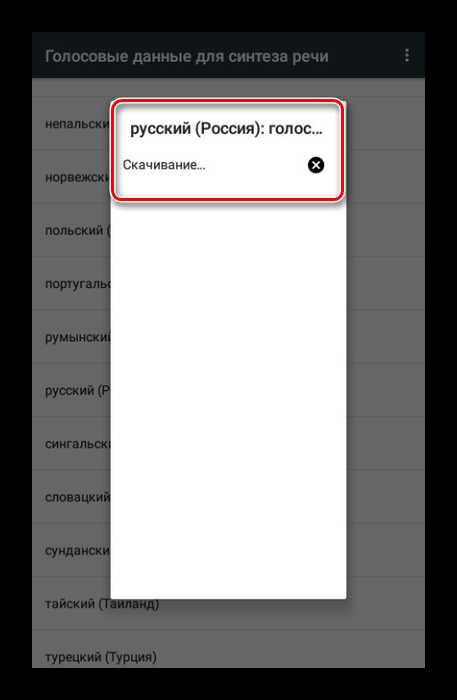 Последним действием нужно выбрать голос озвучки. На момент написания настоящей статьи мужскими являются голоса «II», «III», и «IV».
Последним действием нужно выбрать голос озвучки. На момент написания настоящей статьи мужскими являются голоса «II», «III», и «IV».
- Выбрав пункт «Установка голосовых данных», вы откроете страницу с доступными языками озвучки. Найдите нужный вариант и установите рядом с ним маркер выделения.
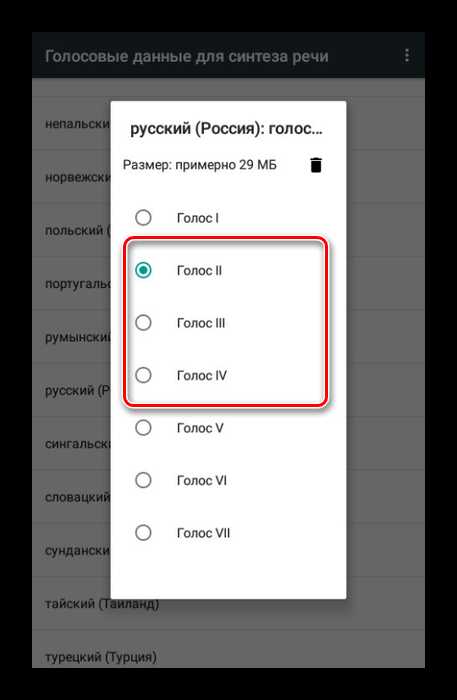
Вне зависимости от выбора тестовое воспроизведение происходит автоматически. Это позволит вам подобрать мужской голос с наиболее оптимальной интонацией и настроить его по желанию с помощью ранее указанных разделов настроек.
Вконтакте
Одноклассники
Что такое синтезаторы речи? Лучшие синтезаторы речи :: SYL.ru
Речевые синтезаторы, установленные на компьютеры или мобильные устройства, уже не кажутся такими необычными программами, как раньше. Благодаря современным технологиям обычный настольный ПК может воспроизводить человеческий голос.
Каким образом работают синтезаторы речи? Где они применяются? Какой самый лучший речевой синтезатор? Ответы на эти и другие вопросы изложены в данной статье.
Общее понятие
Синтезаторы речи являются специальными программами, состоящими из некоторого количества модулей, которые предоставляют возможность перевести набранные тексты в озвученные человеческим голосом предложения. Не стоит думать, что вся база слов и фраз записана реальными людьми в профессиональных студиях. Выполнить подобную задачу физически невозможно. Библиотеку с таким большим количеством фраз нельзя установить ни на один современный компьютер, не говоря уже о мобильных телефонах. Для этого разработчики создали технологию Text-to-Speech.
Сфера применения
Синтезаторы речи используются при изучении иностранных языков, прослушивании текстов на страницах книг, создании вокальных партий, выдаче поисковых запросов в форме озвученных фраз и т. п.
Какие разновидности программ существуют? В зависимости от сферы применения утилиты можно разделить на 2 вида: обычные, преобразующие набранный текст в речь, и специальные вокальные модули, используемые в музыкальных приложениях.
Для лучшего понимания рекомендуется рассмотреть оба класса, однако стоит акцентировать внимание на программах в их непосредственном значении.
Преимущества и недостатки
На данный момент компьютер синтезирует человеческую речь только приблизительно. В простейших программах можно наблюдать проблемы со звуком и правильной постановкой ударений в различных словах. Синтезаторы речи, установленные на мобильные устройства, расходуют много энергии. Нередко можно отметить несанкционированную загрузку дополнительных модулей.
К преимуществам следует отнести удобство восприятия. Многим пользователям гораздо проще усваивать звуковую информацию, нежели какую-либо другую.

Лучшие речевые синтезаторы с русскими голосами
Программа RHVoice была создана Ольгой Яковлевой. Стандартный вариант приложения включает 3 голоса. Настройки очень просты. Программу можно использовать и как самостоятельное приложение, совместимое с SAPI5, и как дополнительный экранный модуль.
Речевой синтезатор Acapela отличается от аналогов идеальным озвучиванием текста. Приложение поддерживает более 30 языков мира. В бесплатной версии доступен лишь 1 женский голос.
Программа Vocalizer часто применяется в call-центрах. Пользователь может настроить постановку ударения, громкость и скорость чтения. При необходимости загружаются дополнительные словари. В приложении есть 1 женский голос. Речевой движок автоматически встраивается в программы для чтения книг в электронном формате.
Утилита eSpeak поддерживает свыше 50 языков. Недостатком программы можно считать сохранение звуковых файлов лишь в формате WAV, который требует много места на жестком диске.
Приложение Festival является мощнейшей утилитой синтеза речи, поддерживающей даже финский язык и хинди.

Установка программы
Как использовать приложения такого типа? Для начала нужно установить программу. В компьютерных ОС применяется стандартный инсталлятор, в котором пользователю остается выбрать лишь поддерживаемый утилитой языковой модуль. Установщик для мобильных устройств можно скачать с официального сайта, Google Play, а также App Store. Инсталляция приложения происходит в автоматическом режиме.
Первый запуск программы
На данном этапе пользователю достаточно установить язык по умолчанию. Иногда требуется отметить качество звучания. Стандартный вариант подразумевает частоту дискретизации 4410 Гц, глубину 16 бит и битрейт 128 кбит/с. В мобильных ОС показатели могут быть ниже. В качестве основы используется определенный голос.
Фильтры и эквалайзеры помогают достичь необходимого звучания. Пользователю доступны три варианта перевода текста. Он может набрать на клавиатуре предложения, включить озвучивание уже имеющегося файла или установить в браузере расширение, которое преобразует содержимое на веб-страницах в речь. Достаточно отметить необходимый вариант действий, тембр голоса и язык, на котором будет произноситься текст. Для включения процесса воспроизведения требуется кликнуть по кнопке «Старт».

Работа со сложными программами
В музыкальных приложениях настройки гораздо сложнее. В речевом модуле программы FL Studio пользователь может выбрать несколько видов голосов, а также указать тональность и скорость воспроизведения. Постановка ударений перед слогами осуществляется с помощью символа «_». С помощью подобного речевого синтезатора можно создать лишь роботизированный голос.
Программа Vocaloid относится к приложениям профессионального типа. Помимо обычных параметров, пользователь может выбирать артикуляцию и глиссандо. В утилите есть база с вокалом профессионалов. При желании можно подгонять под ноты целые предложения. Одна только библиотека с вокалом занимает более 4 Гб в сжатом виде.
"Синтезатор речи Google": что это за программа
В мае 2014 года компания предоставила пользователям возможность опробовать новый бесплатный продукт. Что такое "Синтезатор речи Google" на «Андроиде»? Это программа, озвучивающая текст на экране мобильного устройства или планшета. Теперь нет необходимости устанавливать сторонние утилиты, которые требуют наличия лицензии. "Синтезатор речи Google" используется при чтении электронных книг, прослушивании правильного произношения слов, запуске приложения TalkBack.
Новая версия программы "Синтезатор речи Google 3.1" получила функцию поддержки английского, итальянского, испанского, корейского, немецкого, нидерландского, польского, португальского, русского и французского языков. Где найти голосовые пакеты? Они загружаются из самого приложения.

Преимущества и недостатки продукта от Google
Особенностями русскоговорящего женского голоса является четкое, громкое звучание и плавная интонация. Скорость воспроизведения можно регулировать в настройках программы. Пользователи, использующие TalkBack и русскую языковую локализацию ОС Android, должны проявлять осторожность при переключении на речевой синтезатор, если ранее в приложении по умолчанию был установлен другой голос. Могут возникнуть проблемы, связанные с сохранением контроля над мобильным устройством на слух. Практически все голоса, кроме русского, неспособны обрабатывать предложения на кириллице.
Среди минусов можно отметить задержку реакции на чтение текстов, состоящих из фраз на разных языках. Русский голос отличается металлическими нотками тембра. Можно услышать дребезжащий звук на низких частотах. К преимуществам можно отнести стабильность работы приложения и приемлемое качество чтения англоязычных слов.
"Синтезатор речи Google": как пользоваться программой
Для того чтобы утилита заработала как надо, требуется обновить ее до последней версии. Чтобы активировать процесс озвучивания текста, нужно открыть настройки. В разделе «язык и ввод» необходимо поставить флажок на пункте «синтез речи». Тут же следует отметить строку «система по умолчанию». Не стоит забывать о том, что голосовые пакеты в самой программе также нуждаются в обновлении.

Проблемы при работе с утилитой
При необходимости пользователь может отключить приложение. В самых простых утилитах кнопка остановки находится в самой программе. Деактивация расширения, установленного в браузере, производится путем отключения дополнения или полного удаления плагина. При работе с программой на мобильном телефоне также могут возникнуть проблемы. Дело в том, что синтезатор речи автоматически включает загрузку ненужных пользователю языковых модулей.
Данный процесс занимает много времени и существенно расходует трафик. Как отключить "Синтезатор речи Google" на мобильном устройстве и избавиться от этой проблемы? Для начала нужно открыть настройки приложения. Потом необходимо выбрать раздел «язык и голосовой ввод». Далее нужно отметить последнюю строку.
Выбрав голосовой поиск, следует кликнуть по крестику у пункта «распознавание речи офлайн». Затем рекомендуется удалить кэш приложений. Далее требуется перезагрузить мобильный телефон. Чтобы полностью отключить утилиту, необходимо открыть в настройках раздел «приложения», выбрать в списке синтезатор речи и кликнуть по кнопке «остановить».
Удаление программы
Бывает так, что пользователь вообще не использует "Синтезатор речи Google". Можно ли удалить утилиту с мобильного устройства? Для этого нужно открыть Google Play. Затем следует выбрать в перечне установленных программ синтезатор речи и кликнуть по кнопке «удалить».

Итоги
Обычным пользователям и людям с ограниченными возможностями подойдут приложения с простым интерфейсом. Это может быть как RHVoice, так и "Синтезатор речи Google". Русский голос озвучит отображаемый на экране текст. Большего рядовому пользователю не требуется.
Музыкантам рекомендуется отдавать предпочтение профессиональной программе Vocaloid. В приложении есть дополнительные голосовые библиотеки и множество различных опций. Программа позволит получить естественное звучание голоса. Ведь музыкантам так важно, чтобы компьютерный синтез не ощущался на слух.
Синтезатор речи Google на смартфоне — что это и как работает?
Как включить синтезатор речи Google на телефоне для озвучивания текстов?
Разработчики операционной системы Android предусмотрели возможность преобразования практически любого текста в речь. Такая опция позволит читать сообщения или статьи на разнообразных сайтах — для этого нужно запустить воспроизведение, отрегулировать громкость и положить телефон на стол, чтобы освободить руки. В результате можно сэкономить массу времени, раньше затрачиваемого на самостоятельное чтение. Также озвучивание текстов пригодится слабовидящим людям, которым проблематично разглядеть мелкий шрифт на экране смартфона.
Рассматриваемая функция неизвестна многим пользователям телефонов, поскольку «спрятана» глубоко в настройках. Давайте рассмотрим последовательность действий, необходимых для включения опции.
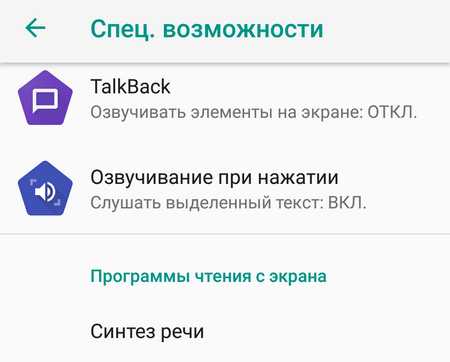
Откройте «Настройки» смартфона и найдите раздел «Специальные возможности». Он часто находится в «Расширенных настройках», но лучше всего воспользоваться поиском.
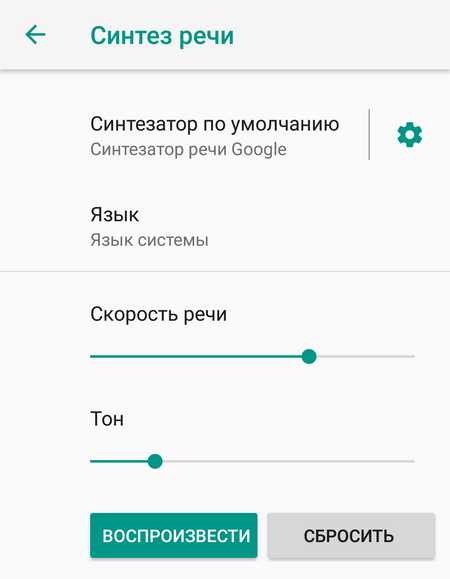
Далее нужно выбрать пункт «Синтез речи». По умолчанию здесь включен «Синтезатор речи Google». Перед использованием преобразователя рекомендуется подобрать оптимальные параметры, например, отрегулировать скорость речи. При желании можно прослушать пример, нажав соответствующую кнопку.
После изменения параметров вернитесь в раздел «Специальные возможности» и включите «Озвучивание при нажатии».
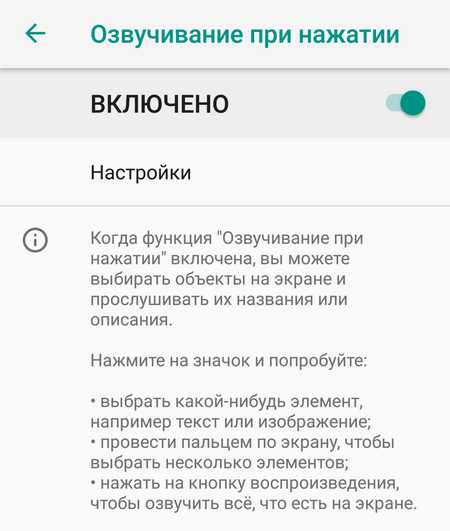
Если соответствующего пункта нет, установите утилиту Android Accessibility Suite из каталога Google Play.
После выполненных действий поверх всех приложений появится небольшой круглый значок с изображением диалогового окна. Если нажать на кнопку, программа предложит выделить область экрана, с которой нужно прочитать текст экране. Внизу появится небольшая панель с несколькими управляющими кнопками, благодаря которым можно быстро переходить на озвучивание предыдущих/следующих текстов или ставить воспроизведение на паузу.
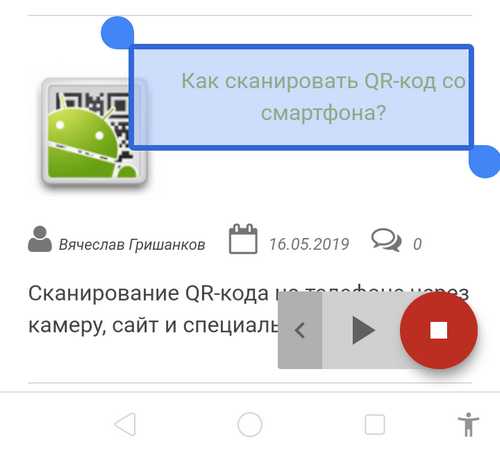
К сожалению, по каким-то причинам синтезатор речи Google не работает на некоторых смартфонах — иконка для воспроизведения текста просто не появляется. Во многих случаях эта кнопка отображается в нижнем меню с навигационными кнопками (как на скриншоте выше).
За счет простого управления и минимума настроек с синтезатором речи Google разберется любой владелец телефона. Дополнительное достоинство — высокое качество преобразования текста в речь и абсолютная бесплатность технологии.
Загрузка...Нейросетевой синтез речи своими руками
Синтез речи на сегодняшний день применяется в самых разных областях. Это и голосовые ассистенты, и IVR-системы, и умные дома, и еще много чего. Сама по себе задача, на мой вкус, очень наглядная и понятная: написанный текст должен произноситься так, как это бы сделал человек.Некоторое время назад в область синтеза речи, как и во многие другие области, пришло машинное обучение. Выяснилось, что целый ряд компонентов всей системы можно заменить на нейронные сети, что позволит не просто приблизиться по качеству к существующим алгоритмам, а даже значительно их превзойти.
Я решил попробовать сделать полностью нейросетевой синтез своими руками, а заодно и поделиться с сообществом своим опытом. Что из этого получилось, можно узнать, заглянув под кат.
Синтез речи
Чтобы построить систему синтеза речи, нужна целая команда специалистов из разных областей. По каждой из них существует целая масса алгоритмов и подходов. Написаны докторские диссертации и толстые книжки с описанием фундаментальных подходов. Давайте для начала поверхностно разберемся с каждой их них.
Лингвистика
- Нормализация текста. Для начала нам нужно развернуть все сокращения, числа и даты в текст. 50е годы XX века должно превратиться в пятидесятые годы двадцатого века, а г. Санкт-Петербург, Большой пр. П.С. в город Санкт-Петербург, Большой проспект Петроградской Стороны. Это должно происходить так естественно, как если бы человека попросили прочитать написанное.
- Подготовка словаря ударений. Расстановка ударений может производиться по правилам языка. В английском ударение часто ставится на первый слог, а в испанском — на предпоследний. При этом из этих правил существует целая масса исключений, не поддающихся какому-то общему правилу. Их обязательно нужно учитывать. Для русского языка в общем смысле правил расстановки ударения вообще не существует, так что без словаря с расставленными ударениями совсем никуда не деться.
- Снятие омографии. Омографы — это слова, которые совпадают в написании, но различаются в произношении. Носитель языка легко расставит ударения: дверной замок и замок на горе. А вот ключ от замка — задача посложнее. Полностью снять омографию без учета контекста невозможно.
Просодика
- Выделение синтагм и расстановка пауз. Синтагма представляет относительно законченный по смыслу отрезок речи. Когда человек говорит, он обычно вставляет паузы между фразами. Нам нужно научиться разделять текст на такие синтагмы.
- Определение типа интонации. Выражение завершенности, вопроса и восклицания — самые простые интонации. А вот выразить иронию, сомнение или воодушевление задача куда сложнее.
Фонетика
- Получение транскрипции. Так как в конечном итоге мы работаем с произнесением, а не с написанием, то очевидно вместо букв (графем), логично использовать звуки (фонемы). Преобразование графемной записи в фонемную — отдельная задача, состоящая из множества правил и исключений.
- Вычисление параметров интонации. В этот момент нужно решить как будет меняться высота основного тона и скорость произнесения в зависимости от расставленных пауз, подобранной последовательности фонем и типа выражаемой интонации. Помимо основного тона и скорости есть и другие параметры, с которыми можно долго экспериментировать.
Акустика
- Подбор звуковых элементов. Системы синтеза оперируют так называемыми аллофонами — реализациями фонемы, зависящими от окружения. Записи из обучающих данных нарезаются на кусочки по фонемной разметке, которые образуют аллофонную базу. Каждый аллофон характеризуется набором параметров, таких как контекст (фонемы соседи), высота основного тона, длительность и прочие. Сам процесс синтеза представляет собой подбор правильной последовательности аллофонов, наиболее подходящих в текущих условиях.
- Модификация и звуковые эффекты. Для получившихся записей иногда нужна постобработка, какие-то специальные фильтры, делающие синтезируемую речь чуть ближе к человеческой или исправляющие какие-то дефекты.
Если вдруг вам показалось, что все это можно упростить, прикинуть в голове или быстро подобрать какие-то эвристики для отдельных модулей, то просто представьте, что вам нужно сделать синтез на хинди. Если вы не владеете языком, то вам даже не удастся оценить качество вашего синтеза, не привлекая кого-то, кто владел бы языком на нужном уровне. Мой родной язык русский, и я слышу, когда синтез ошибается в ударениях или говорит не с той интонацией. Но в тоже время, весь синтезированный английский для меня звучит примерно одинаково, не говоря уже о более экзотических языках.
Реализации
Мы попытаемся найти End-2-End (E2E) реализацию синтеза, которая бы взяла на себя все сложности, связанные с тонкостями языка. Другими словами, мы хотим построить систему, основанную на нейронных сетях, которая бы на вход принимала текст, а на выходе давала бы синтезированную речь. Можно ли обучить такую сеть, которая позволила бы заменить целую команду специалистов из узких областей на команду (возможно даже из одного человека), специализирующуюся на машинном обучении?
На запрос end2end tts Google выдает целую массу результатов. Во главе — реализация Tacotron от самого Google. Самым простым мне показалось идти от конкретных людей на Github, которые занимаются исследованиям в этой области и выкладывают свои реализации различных архитектур.
Я бы выделил троих:
- Kyubyong Park
- Keith Ito
- Ryuichi Yamamoto
Загляните к ним в репозитории, там целый кладезь информации. Архитектур и подходов к задаче E2E-синтеза довольно много. Среди основных:
- Tacotron (версии 1, 2).
- DeepVoice (версии 1, 2, 3).
- Char2Wav.
- DCTTS.
- WaveNet.
Нам нужно выбрать одну. Я выбрал Deep Convolutional Text-To-Speech (DCTTS) от Kyubyong Park в качестве основы для будущих экспериментов. Оригинальную статью можно посмотреть по ссылке. Давайте поподробнее рассмотрим реализацию.
Автор выложил результаты работы синтеза по трем различным базам и на разных стадиях обучения. На мой вкус, как не носителя языка, они звучат весьма прилично. Последняя из баз на английском языке (Kate Winslet's Audiobook) содержит всего 5 часов речи, что для меня тоже является большим преимуществом, так как моя база содержит примерно сопоставимое количество данных.
Через некоторое время после того, как я обучил свою систему, в репозитории появилась информация о том, что автор успешно обучил модель для корейского языка. Это тоже довольно важно, так как языки могут сильно разниться и робастность по отношению к языку — это приятное дополнение. Можно ожидать, что в процессе обучения не потребуется особого подхода к каждому набору обучающих данных: языку, голосу или еще каким-то характеристикам.
Еще один важный момент для такого рода систем — это время обучения. Tacotron на том железе, которое у меня есть, по моим оценкам учился бы порядка 2 недель. Для прототипирования на начальном уровне мне показалось это слишком ресурсоемким. Педали, конечно, крутить не пришлось бы, но на создание какого-то базового прототипа потребовалось бы очень много календарного времени. DCTTS в финальном варианте учится за пару дней.
У каждого исследователя есть набор инструментов, которыми он пользуется в своей работе. Каждый подбирает их себе по вкусу. Я очень люблю PyTorch. К сожалению, на нем реализации DCTTS я не нашел, и пришлось использовать TensorFlow. Возможно в какой-то момент выложу свою реализацию на PyTorch.
Данные для обучения
Хорошая база для реализации синтеза — это основной залог успеха. К подготовке нового голоса подходят очень основательно. Профессиональный диктор произносит заранее подготовленные фразы в течение многих часов. Для каждого произнесения нужно выдержать все паузы, говорить без рывков и замедлений, воспроизвести правильный контур основного тона и все это в купе с правильной интонацией. Кроме всего прочего, не все голоса одинаково приятно звучат.
У меня на руках была база порядка 8 часов, записанная профессиональным диктором. Сейчас мы с коллегами обсуждаем возможность выложить этот голос в свободный доступ для некоммерческого использования. Если все получится, то дистрибутив с голосом помимо самих записей будет включать в себя точные текстовки для каждой из них.
Начнем
Мы хотим создать сеть, которая на вход принимала бы текст, а на выходе давала бы синтезированный звук. Обилие реализаций показывает, что это возможно, но есть конечно и ряд оговорок.
Основные параметры системы обычно называют гиперпараметрами и выносят в отдельный файл, который называется соответствующим образом: hparams.py или hyperparams.py, как в нашем случае. В гиперпараметры выносится все, что можно покрутить, не трогая основной код. Начиная от директорий для логов, заканчивая размерами скрытых слоев. После этого гиперпараметры в коде используются примерно вот так:
from hyperparams import Hyperparams as hp batch_size = hp.B # размер батча берем из гиперпараметровДалее по тексту все переменные имеющие префикс hp. берутся именно из файла гиперпараметров. Подразумевается, что эти параметры не меняются в процессе обучения, поэтому будьте осторожны перезапуская что-то с новыми параметрами.
Текст
Для обработки текста обычно используются так называемый embedding-слой, который ставится самым первым. Суть его простая — это просто табличка, которая каждому символу из алфавита ставит в соответствие некий вектор признаков. В процессе обучения мы подбираем оптимальные значения для этих векторов, а когда синтезируем по готовой модели, просто берем значения из этой самой таблички. Такой подход применяется в уже довольно широко известных Word2Vec, где строится векторное представление для слов.
Для примера возьмем простой алфавит:
['a', 'b', 'c']В процессе обучения мы выяснили, что оптимальные значения каждого их символов вот такие:
{ 'a': [0, 1], 'b': [2, 3], 'c': [4, 5] }Тогда для строчки aabbcc после прохождения embedding-слоя мы получим следующую матрицу:
[[0, 1], [0, 1], [2, 3], [2, 3], [4, 5], [4, 5]]Эта матрица дальше подается на другие слои, которые уже не оперируют понятием символ.
В этот момент мы видим первое ограничение, которое у нас появляется: набор символов, который мы можем отправлять на синтез, ограничен. Для каждого символа должно быть какое-то ненулевое количество примеров в обучающих данных, лучше с разным контекстом. Это значит, что нам нужно быть осторожными в выборе алфавита.
В своих экспериментах я остановился на варианте:
# Алфавит задается в файле с гиперпараметрами vocab = "E абвгдеёжзийклмнопрстуфхцчшщъыьэюя-" Это алфавит русского языка, дефис, пробел и обозначение конца строки. Тут есть несколько важных моментов и допущений:
- Я не добавлял в алфавит знаки препинания. С одной стороны, мы действительно их не произносим. С другой, по знакам препинания мы делим фразу на части (синтагмы), разделяя их паузами. Как система произнесет казнить нельзя помиловать?
- В алфавите нет цифр. Мы ожидаем, что они будут развернуты в числительные перед подачей на синтез, то есть нормализованы. Вообще все E2E-архитектуры, которые я видел, требуют именно нормализованный текст.
- В алфавите нет латинских символов. Английский система уметь произносить не будет. Можно попробовать транслитерацию и получить сильный русский акцент — пресловутый лет ми спик фром май харт.
- В алфавите есть буква ё. В данных, на который я обучал систему, она стояла там, где нужно, и я решил этот расклад не менять. Однако, в тот момент, когда я оценивал получившиеся результаты, выяснилось, что теперь перед подачей на синтез эту букву тоже нужно ставить правильно, иначе система произносит именно е, а не ё.
В будущих версиях можно уделить каждому из пунктов более пристальное внимание, а пока оставим в таком немного упрощенном виде.
Звук
Почти все системы оперируют не самим сигналом, а разного рода спектрами полученными на окнах с определенным шагом. Я не буду вдаваться в подробности, по этой теме довольно много разного рода литературы. Сосредоточимся на реализации и использованию. В реализации DCTTS используются два вида спектров: амплитудный спектр и мел-спектр.
Считаются они следующим образом (код из этого листинга и всех последующих взят из реализации DCTTS, но видоизменен для наглядности):
# Получаем сигнал фиксированной частоты дискретизации y, sr = librosa.load(wavename, sr=hp.sr) # Обрезаем тишину по краям y, _ = librosa.effects.trim(y) # Pre-emphasis фильтр y = np.append(y[0], y[1:] - hp.preemphasis * y[:-1]) # Оконное преобразование Фурье linear = librosa.stft(y=y, n_fft=hp.n_fft, hop_length=hp.hop_length, win_length=hp.win_length) # Амплитудный спектр mag = np.abs(linear) # Мел-спектр mel_basis = librosa.filters.mel(hp.sr, hp.n_fft, hp.n_mels) mel = np.dot(mel_basis, mag) # Переводим в децибелы mel = 20 * np.log10(np.maximum(1e-5, mel)) mag = 20 * np.log10(np.maximum(1e-5, mag)) # Нормализуем mel = np.clip((mel - hp.ref_db + hp.max_db) / hp.max_db, 1e-8, 1) mag = np.clip((mag - hp.ref_db + hp.max_db) / hp.max_db, 1e-8, 1) # Транспонируем и приводим к нужным типам mel = mel.T.astype(np.float32) mag = mag.T.astype(np.float32) # Добиваем нулями до правильных размерностей t = mel.shape[0] num_paddings = hp.r - (t % hp.r) if t % hp.r != 0 else 0 mel = np.pad(mel, [[0, num_paddings], [0, 0]], mode="constant") mag = np.pad(mag, [[0, num_paddings], [0, 0]], mode="constant") # Понижаем частоту дискретизации для мел-спектра mel = mel[::hp.r, :] Для вычислений почти во всех проектах E2E-синтеза используется библиотека LibROSA (https://librosa.github.io/librosa/). Она содержит много полезного, рекомендую заглянуть в документацию и посмотреть, что в ней есть.
Теперь давайте посмотрим как амплитудный спектр (magnitude spectrum) выглядит на одном из файлов из базы, которую я использовал:
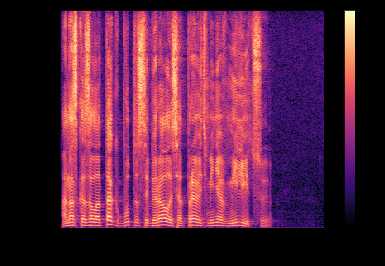
Такой вариант представления оконных спекторов называется спектрограммой. На оси абсцисс располагается время в секундах, на оси ординат — частота в герцах. Цветом выделяется амплитуда спектра. Чем точка ярче, тем значение амплитуды больше.
Мел-спектр — это амплитудный спектр, но взятый на мел-шкале с определенным шагом и окном. Количество шагов мы задаем заранее, в большинстве реализаций для синтеза используется значение 80 (задается параметром hp.n_mels). Переход к мел-спектру позволяет сильно сократить количество данных, но этом сохранить важные для речевого сигнала характеристики. Мел-спектрограмма для того же файла выглядит следующим образом:
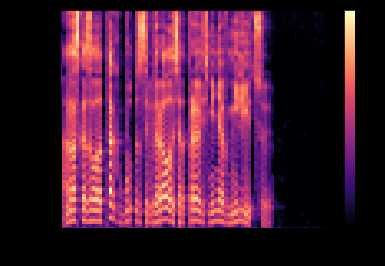
Обратите внимание на прореживание мел-спектров во времени на последней строке листинга. Мы берем только каждый 4 вектор (hp.r == 4), соответственно уменьшая тем самым частоту дискретизации. Синтез речи сводится к предсказанию мел-спектров по последовательности символов. Идея простая: чем меньше сети приходится предсказывать, тем лучше она будет справляться.
Хорошо, мы можем получить спектрограмму по звуку, но послушать мы ее не можем. Соответственно нам нужно уметь восстанавливать сигнал обратно. Для этих целей в системах часто используется алгоритм Гриффина-Лима и его более современные интерпретации (к примеру, RTISILA, ссылка). Алгоритм позволяет восстановить сигнал по его амплитудным спектрам. Реализация, которую использовал я:
def griffin_lim(spectrogram, n_iter=hp.n_iter): x_best = copy.deepcopy(spectrogram) for i in range(n_iter): x_t = librosa.istft(x_best, hp.hop_length, win_length=hp.win_length, window="hann") est = librosa.stft(x_t, hp.n_fft, hp.hop_length, win_length=hp.win_length) phase = est / np.maximum(1e-8, np.abs(est)) x_best = spectrogram * phase x_t = librosa.istft(x_best, hp.hop_length, win_length=hp.win_length, window="hann") y = np.real(x_t) return yА сигнал по амплитудной спектрограмме можно восстановить вот так (шаги, обратные получению спектра):
# Транспонируем mag = mag.T # Денормализуем mag = (np.clip(mag, 0, 1) * hp.max_db) - hp.max_db + hp.ref_db # Возвращаемся от децибел к аплитудам mag = np.power(10.0, mag * 0.05) # Восстанавливаем сигнал wav = griffin_lim(mag**hp.power) # De-pre-emphasis фильтр wav = signal.lfilter([1], [1, -hp.preemphasis], wav)Давайте попробуем получить амплитудный спектр, восстановить его обратно, а затем послушать.
Оригинал:
Восстановленный сигнал:
На мой вкус, результат стал хуже. Авторы Tacotron (первая версия также использует этот алгоритм) отмечали, что использовали алгоритм Гриффина-Лима как временное решение для демонстрации возможностей архитектуры. WaveNet и ему подобные архитектуры позволяют синтезировать речь лучшего качества. Но они более тяжеловесные и требуют определенных усилий для обучения.
Обучение
DCTTS, который мы выбрали, состоит из двух практически независимых нейронных сетей: Text2Mel и Spectrogram Super-resolution Network (SSRN).
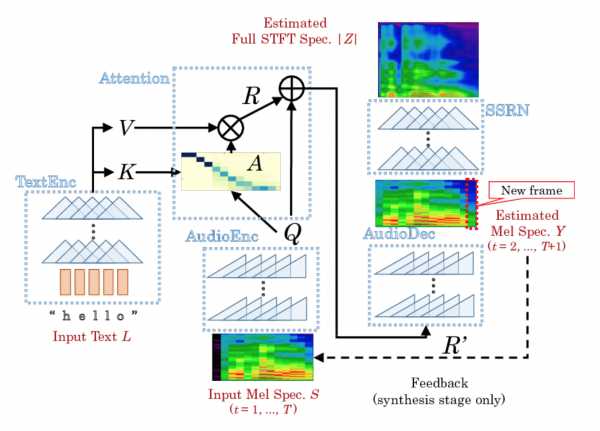
Text2Mel предсказывает мел-спектр по тексту, используя механизм внимания (Attention), который увязывает два энкодера (TextEnc, AudioEnc) и один декодер (AudioDec). Обратите внимание, что Text2Mel восстанавливает именно разреженный мел-спектр.
SSRN восстанавливает из мел-спектра полноценный амплитудный спектр, учитывая пропуски кадров и восстанавливая частоту дискретизации.
Последовательность вычислений довольно подробно описана в оригинальной статье. К тому же есть исходный код реализации, так что всегда можно отладиться и вникнуть в тонкости. Обратите внимание, что автор реализации отошел в некоторых местах от статьи. Я бы выделил два момента:
- Появились дополнительные слои для нормализации (normalization layers), без которых, по словам автора, ничего не работало.
- В реализации используется механизм исключения (dropout) для лучшей регуляризации. В статье этого нет.
Я взял голос, включающий в себя 8 часов записей (несколько тысяч файлов). Оставил только записи, которые:
- В текстовках содержат только буквы, пробелы и дефисы.
- Длина текстовок не превышает hp.max_N.
- Длина мел-спектров после разреживания не превышает hp.max_T.
У меня получилось чуть больше 5 часов. Посчитал для всех записей нужные спекты и поочередно запустил обучение Text2Mel и SSRN. Все это делается довольно безхитростно:
$ python prepro.py $ python train.py 1 $ python train.py 2Обратите внимание, что в оригинальном репозитории prepro.py именуется как prepo.py. Мой внутренний перфекционист не смог этого терпеть, так что я его переименовал.
DCTTS содержит только сверточные слои, и в отличие от RNN реализаций, вроде Tacotron, учится значительно быстрее.
На моей машине с Intel Core i5-4670, 16 Gb RAM и GeForce 1080 на борту 50 тыс. шагов для Text2Mel учится за 15 часов, а 75 тыс. шагов для SSRN — за 5 часов. Время требуемое на тысячу шагов в процессе обучения у меня почти не менялось, так что можно легко прикинуть, сколько потребуется времени на обучение с большим количеством шагов.
Размер батча можно регулировать параметром hp.B. Периодически процесс обучения у меня валился с out-of-memory, так что я просто делил на 2 размер батча и перезапускал обучение с нуля. Полагаю, что проблема кроется где-то в недрах TensorFlow (я использовал не самый свежий) и тонкостях реализации батчинга. Я с этим разбираться не стал, так как на значении 8 все падать перестало.
Результат
После того, как модели обучились, можно наконец запустить и синтез. Для этого заполняем файлик с фразами и запускаем:
$ python synthesize.pyЯ немного поправил реализацию, чтобы генерировать фразы из нужного файла.
Результаты в виде WAV-файлов будут сохранены в директорию samples. Вот примеры синтеза системой, которая получилась у меня:
Выводы и ремарки
Результат превзошел мои личные ожидания по качеству. Система расставляет ударения, речь получается разборчивой, а голос узнаваем. В целом получилось неплохо для первой версии, особенно с учетом того, что для обучения использовалось всего 5 часов обучающих данных.
Остаются вопросы по управляемости таким синтезом. Пока невозможно даже исправить ударение в слове, если оно неверное. Мы жестко завязаны на максимальную длину фразы и размер мел-спектрограммы. Нет возможности управлять интонацией и скоростью воспроизведения.
Я не выкладывал мои изменения в коде оригинальной реализации. Они коснулись только загрузки обучающих данных и фраз для синтеза уже по готовой системе, а также значений гиперпараметров: алфавит (hp.vocab) и размер батча (hp.B). В остальном реализация осталась оригинальная.
В рамках рассказа я совсем не коснулся темы продакшн реализации таких систем, до этого полностью E2E-системам синтеза речи пока очень далеко. Я использовал GPU c CUDA, но даже в этом случае все работает медленнее реального времени. На CPU все работает просто неприлично медленно.
Все эти вопросы будут решаться в ближайшие годы крупными компаниями и научными сообществами. Уверен, что это будет очень интересно.
Amazon представила сервис создания персональной системы синтеза речи

giphy.com
Компания Amazon запустила сервис создания системы синтеза речи с голосом конкретного человека на основе образцов его речи. Amazon предлагает использовать сервис брендам, связанным с конкретным человеком или образом. Например, она создала для KFC алгоритм синтеза речи Полковника Сандерса.
Развитие алгоритмов синтеза звука, таких как WaveNet, привлекло к этой области внимание исследователей и компаний, в результате чего за последние годы появилось много голосовых помощников и систем синтеза речи, которые разработчики могут использовать в своих приложениях. Однако почти всегда система синтеза речи от одной компании может говорить одним или максимум несколькими голосами, причем они, как правило, не принадлежат известным людям. Есть исключения, например, голос Джона Ледженда в Google Assistant, однако в целом пока крупные разработчики голосовых помощников и систем синтеза речи до недавнего времени не позволяли создавать алгоритм, говорящий голосом конкретного человека.
Amazon, которая уже предоставляет разработчикам приложений сервис Polly для синтеза речи на разных языках и разными голосами, запустила в рамках этого сервиса функцию создания пользовательского голоса. Сервис доступен как в виде голоса для навыков голосового помощника Alexa, так и в виде отдельного API, получающего текст и выдающего файл с аудиозаписью, который можно использовать любым образом.
В первую очередь она нацелена на компании, которые хотят использовать в своих сервисах голос известного представителя бренда. В качестве примера Amazon показала результат работы с KFC, которая для своего канадского отделения создала голосовую модель символа компании — Полковника Сандерса:
Здесь должно было быть аудио, но что-то пошло не так.
Компания не раскрывает стоимость и подробности работы сервиса, однако, вероятно, он основан на алгоритме, описанном в статье сотрудников Amazon в 2019 году. Алгоритм берет данные конкретного человека и добавляет их к генерализованной нейросетевой модели, обученной на других данных. В результате на обучение модели требуется гораздо меньше образцов речи, чем при использовании других подходов, но качество синтеза получается высоким.
Пока одной из самых реалистичных и масштабно применяемых систем синтеза речи остается Google Duplex. Эта функция работает в США и Новой Зеландии, и позволяет забронировать столик в ресторане или совершить другое действие, попросив Google Assistant. После этого алгоритм сам найдет нужную информацию, в том числе телефон заведения, позвонит и сообщит пользователю итог. Система оказалась настолько реалистичной. что после запуска Google пришлось научить ее в начале звонка уточнять, что говориталгоритм, а не человек.
Григорий Копиев
Скачиваются голосовые данные для синтеза речи. Остановка загрузки на Android. "Синтезатор речи Google": что это за программа
В некоторых случаях на Android-смартфонах появляется уведомление «Скачивание пакета “Русский”». Сегодня мы хотим рассказать вам, что это такое и как убрать это сообщение.
«Пакет “Русский”» — компонент голосового управления телефоном от Google. Данный файл представляет собой словарь, который используется приложением «корпорации добра» для распознавания запросов пользователя. Зависшее уведомление о скачивании этого пакета сообщает о сбое либо в самом приложении Гугл, либо в менеджере загрузок Андроид. Справится с с этой проблемой можно двумя путями – дозагрузить проблемный файл и отключить автообновления языковых пакетов или очистить данные приложения.
Способ 1: Отключение автообновления языковых пакетов
На некоторых прошивках, особенно сильно модифицированных, возможна нестабильная работа программы-поисковика Google. Из-за внесенных в систему модификаций или сбоя неясной природы приложение не может обновить голосовой модуль для выбранного языка. Следовательно, стоит сделать это вручную.
- Откройте «Настройки» . Сделать это можно, например, из шторки.
- Ищем блоки «Управление» или «Дополнительно» , в нем – пункт «Язык и ввод» .
- В меню «Язык и ввод» ищем «Голосовой ввод Google» .
- Внутри этого меню найдите «Основные функции Google» .
Нажмите на иконку с изображением шестерни. - Тапните по «Распознавание речи офлайн» .
- Откроются настройки голосового ввода. Перейдите на вкладку «Все» .
Пролистайте список вниз. Найдите «Русский (Россия)» и скачайте его. - Теперь перейдите на вкладку «Автообновления» .
Отметьте пункт «Не обновлять языки» .
Проблема будет решена – уведомление должно пропасть и больше вас не беспокоить. Однако на некоторых вариантах прошивок этих действий может быть недостаточно. Столкнувшись с таким, переходите к следующему методу.
Способ 2: Очистка данных приложений Google и «Диспетчера загрузки»
Из-за несоответствия компонентов прошивки и сервисов Гугл возможно зависание обновления языкового пакета. Перезагрузка аппарата в этом случае бесполезна – нужно очищать данные как самого поискового приложения, так и «Диспетчера загрузок» .
- Заходите в «Настройки» и ищите пункт «Приложения» (иначе «Диспетчер приложений» ).
- В «Приложениях» найдите «Google» .
Будьте внимательны! Не перепутайте его с Google Play Services !
- Тапните по приложению. Откроется меню свойств и управления данными. Нажмите «Управление памятью» .
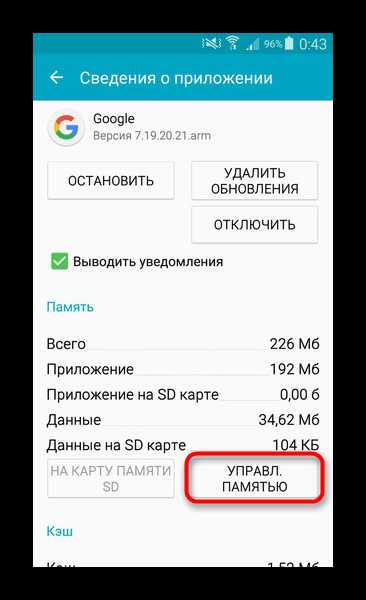
В открывшемся окне тапните «Удалить все данные» .
Подтвердите удаление. - Переходите обратно в «Приложения» . На этот раз найдите «Диспетчер загрузок» .
Если вы не можете его обнаружить, нажмите на три точки справа вверху и выберите «Показать системные приложения» . - Нажмите последовательно «Очистить кэш» , «Очистить данные» и «Остановить» .
- Перезагружайте ваш девайс.
Комплекс описанных действий поможет решить проблему раз и навсегда.
Подводя итог, отметим, что наиболее часто подобная ошибка встречается на аппаратах Xiaomi с русифицированной китайской прошивкой.
- речи - синтезатор речи речи ) - русский (Россия) или какой там загружается - крестик справа ">Как отключить загрузку голосовых данных для синтеза речи ?
Язык и ввод - синтез речи - синтезатор речи Гугл с шестеренкой справа - тыц по шестеренке - Установка голосовых данных (установить голосовые данные, необходимые для синтеза речи ) - русский (Россия) или какой там загружается - крестик справа "Х". -
...синтезатора речи синтезатор речи googleЗагрузка голосовых данных, как убрать ?Как убрать загрузку голосовыхВакансии по запросу Fly убрать синтезатор речи . - Как убрать загрузку голосовых данных синтезатора речи ?
Что касается загрузки голосовых дан
Выбираем голосовой синтезатор речи с русским голосом

Недавно передо мной встала проблема выбора голосового синтезатора речи. Основные требования — это поддержка русского языка и более-менее нормальное произношение.
Для тех, кто не в курсе того, что такое синтезатор речи, расскажу — это специальная программа, смысл работы которой заключается в преобразовании письменного текста в устную речь. Это и есть так называемый синтез.
Зачем это надо? Ну, например, когда надо записать голосовое сообщение чужим голосом. Иностранцам оно может быть полезно для того, чтобы услышать произношение того или иного слова. Синтезатор речи удобен для чтения, когда надо включить ребенку сказку, которой нет в аудиокнигах. Да и вообще, ситуации всякие бывают.
Так вот, в процессе выбора я нашел несколько очень полезных инструментов, среди которых работающих в режиме онлайн с поддержкой русского языка и сейчас я Вам о них и расскажу.
Переводчик Google
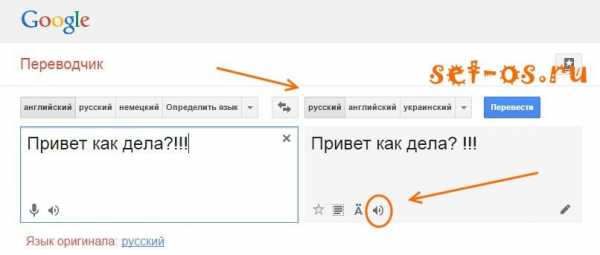
Вот поистине многоцелевой продукт, которых можно использовать совершенно по-разному. Главные преимущества:
— это совершенно бесплатный сервис;
— работа в режиме Онлайн без установки. Нужен только доступ в Интернет;
— на мой взгляд этот синтезатор речи имеет лучший голосовой модуль, самое близкое к натуральному;
— наверное самая лучшая команда разработчиков и техподдержка в мире;
— самое большое количество поддерживаемых языков.
К сожалению, вариант голоса только один — женский. Выбора я не нашел.
RHVoice

Отличный многоязычный синтезатор речи от российского разработчика — Ольги Яковлевой. Есть версии, как для операционных систем семейства Windows, так и для Linux. Разработчик синтезатора — Ольга Яковлева. Программа распространяется совершенно бесплатно и доступна на официальном сайте в двух вариантах: как SAPI5-совместимая самостоятельная версия и как модуль для бесплатной программы экранного доступа NVDA. Этот синтезатор голосовой речи умеет озвучивать русские тексты тремя голосами — Елена, Ирина и Александр.
Acapela

Acapela — это, пожалуй, один из самых популярных и распространенных голосовых синтезаторов в мире. Главная особенность — это озвучка текстов более чем на тридцати языках мира. Если рассматривать русский язык, то тут доступны два голоса — Николай и Алена. Причем последний более совершенен и естественен в плане произношения. В демонстрационном режиме на сайте доступен только голос Алена.
Программа доступна для скачивания на официальном сайте и поддерживает все популярные современные операционные системы — Windows, Linux, Mac. Есть даже версии для Android u iOS.
Vokalizer

Женских голос Milena — это ещё один очень популярный движок голосового синтезатора речи от компании Nuance — он очень высококачественный и естественно звучащий. Его Вы можете услышать в call-центрах и в различных сетевых речевых системах, а также в различных приложениях приложениях — таких как Moon+ Reader Pro, Full Screen Caller ID , Cool Reader, в навигационной программах TomTom, iGo Primo.
Среди плюсов можно отметить возможность установки различных словарей, регулировки громкости, ударения и скорости чтения.
Код программы открытый, скачать его бесплатно можно на официальном сайте, собственно как и инсталлятор самой программы.
Festival
Festival — это не просто очередной голосовой речевой синтезатор, а уже целая система распознавания и синтеза речи с различными API. Разработчик — Исследовательский Центр Речевых Технологий университета Эдинбурга.
Festival предназначен для поддержки нескольких языков. По умолчанию поддерживает английский, валлийский и испанский языки. Но есть возможность подключить голосовые пакеты других языков: чешский, финский, хинди, итальянский, маратхи, польский, русский и телугу.
Код программы открытый, сам голосовой синтезатор распространяется по лицензии open source и доступна только для операционных систем Linux. Правда есть портированная версия по Макинтош.
ESpeak

Последняя в моём обзоре система синтеза речи — программа ESpeak — разрабатывается уже около 8 лет. Последняя версия — 1.48.04 от 6 апреля 2014. Данный голосовой синтезатор речи кроссплатформенный — есть версии под Windows, Linux, Mac OS X, и даже под RISC OS, хотя последние две уже давно не поддерживаются.
Отдельно отмечу, что eSpeak используется в мобильных операционных системах Android, правда имеет при этом ряд существенных ошибок.
Программа поддерживает пятидесяти различных языков, поддержка которых указывается при установке программы.
Один из главных минусов это голосового синтезатора — генерирование голоса только в файл формата WAV. Скачать программу бесплатно можно на официальном сайте.
От себя добавлю лишь, что мне понравились RHVoice и Vokalizer, хотя тут во много дело индивидуальное и во многом зависит от того, что Вы хотите получить. Так что пробуйте, ставьте и смотрите. Я думаю, что один из представленных вариантов Вам обязательно должен подойти.