Инкрементальная загрузка что это такое
Что такое инкрементальная загрузка в App Store?
 Многим пользователям продуктов компании Apple, которые хотят скачать весомое приложение, приходится узнать, что такое инкрементальная загрузка в App Store. Дело в том, что не всегда у пользователей есть возможность пользоваться Wi-Fi сетями при скачивании приложений.
Многим пользователям продуктов компании Apple, которые хотят скачать весомое приложение, приходится узнать, что такое инкрементальная загрузка в App Store. Дело в том, что не всегда у пользователей есть возможность пользоваться Wi-Fi сетями при скачивании приложений.C развитием мобильны технологий и снижающейся стоимостью мобильного интернета, необходимость в Wi-Fi для скачки файлов постепенно отпадает.
Тем не менее, у Apple существует ограничение на скачивание файлов из App Store до 150 мегабайт (на более ранних версиях ограничение стоит на 100 мб). Если приложение или игра требует больше места, то программа не даст скачать файл. Естественно, что данное ограничение нравится далеко не всем. Те, кто экономят мобильный трафик, конечно, рады такой функции, однако другим это приносит определенный дискомфорт. К счастью, существует несколько простых способов обойти данное ограничение
Перезагрузка
Судя по отзывам в интернете, данный способ подходит далеко не всем. На многих версиях Ios он не работает. Однако это первый способ, который стоит попробовать, так как он самый простой.

При скачивании файла более 150 мегабайт, система выведет сообщение о том, что файл невозможно загрузить, пока устройство не будет подключено к Wi-Fi. Сообщения разнятся, в зависимости от версии операционной системы, но их смысл всегда одинаковый. Кнопки на сообщении дают два варианта: «Отменить» и «ОК»^
- Для того, чтобы продолжить загрузку, следует нажать «ОК» и выполнить перезагрузку устройства. Как только устройство включится, загрузка должна автоматически начаться.
- Если этот способ не сработал, то можно попробовать другой вариант. Перед перезагрузкой нужно включить режим самолета и Wi-Fi и тогда после перезагрузки, устройство продолжит закачку.
Джейлбрейк
Хотя джейлбрейк имеет много минусов, он может помочь обойти ограничения на загрузку. Для «сломанных» устройств доступны различные приложения, которые нейтрализуют ошибку App Store.
Wi-fi с другого устройства.
Если ни один из способов не помог, то можно воспользоваться традиционным методом обмана телефона. Нужно просто переставить сим карту в другой телефон и с него раздать Wi-fi на устройство, которое скачивает «весомое» приложение. Тогда это уже станет скачиванием по Wi-fi и App Store не будет иметь ничего против такой загрузки.
Стоит отметить, что каждая iOS имеет свои особенности в решении проблемы инкрементальной загрузки, поэтому вполне возможно, что некоторые способы не будут работать на конкретном устройстве.
Как включить инкрементальную загрузку iPhone

Основная часть контента, распространяемого в App Store, весит более 100 Мб. Размер игры или приложения имеет значение в том случае, если вы планируете выполнить скачивание через мобильный интернет, поскольку максимальный размер загружаемых данных без подключения к Wi-Fi не может превышать 150 Мб. Сегодня мы рассмотрим, каким образом данное ограничение можно обойти.
В старых версиях iOS размер скачиваемых игр или приложений не мог превышать 100 Мб. Если контент весил больше, на экране iPhone отображалось сообщение об ошибке скачивания (ограничение действовало в том случае, если для игры или приложения не действовала инкрементальная загрузка). Позднее Apple увеличила размер загружаемого файла до 150 Мб, однако, зачастую даже самые простые приложения весят больше.
Обходим ограничение загрузки приложений через сотовые данные
Ниже мы рассмотрим два простых способа скачать игру или программу, размер которой превышает установленный предел в 150 Мб.
Способ 1: Перезагрузка устройства
- Откройте App Store, найдите интересующий контент, не проходящий по размеру, и попытайтесь его загрузить. Когда на экране появится сообщение об ошибке скачивания, тапните по кнопке «ОК».
- Перезагрузите телефон.
Подробнее: Как перезагрузить iPhone
- Как только Айфон будет включен, спустя минуту он должен запустить загрузку приложения — если этого не произошло автоматически, тапните по иконке приложения. При необходимости, повторите перезагрузку, поскольку данный способ может не сработать с первого раза.
Способ 2: Смена даты
Небольшая уязвимость в прошивке позволяет обойти ограничение при загрузке тяжелых игр и приложений через сотовую сеть.
- Запустите App Store, найдите интересующую программу (игру), а затем попытайтесь ее загрузить — на экране появится сообщение об ошибке. Не трогайте в данном окне никакие кнопки, а вернитесь на рабочий стол iPhone нажатием кнопки «Домой».
- Откройте настройки смартфона и перейдите в раздел «Основные».
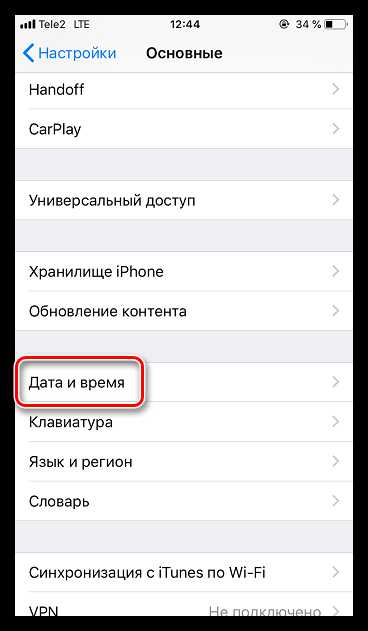
- В отобразившемся окне выберите пункт «Дата и время».
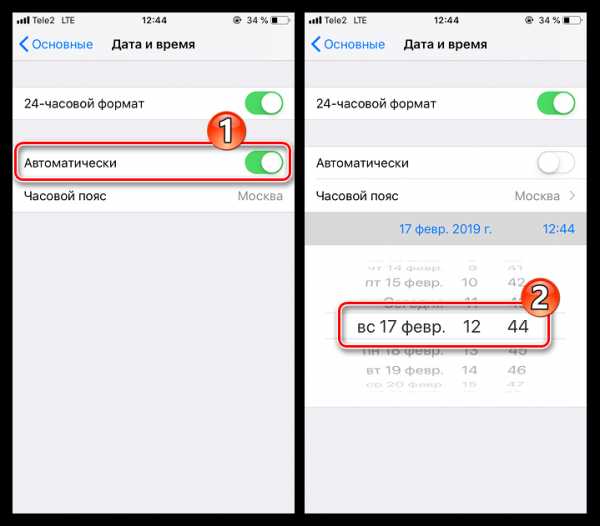
- Деактивируйте пункт «Автоматически», а затем измените дату на смартфоне, сдвинув ее на один день вперед.
- Дважды нажмите кнопку «Домой», а затем снова перейдите в App Store. Повторите попытку загрузки приложения.
- Начнется скачивание. Как только оно будет завершено, вновь активируйте на Айфоне автоматическое определение даты и времени.
Любой из двух приведенных в статье способов позволит обойти ограничение iOS и загрузить большое приложение на свое устройство без подключения к сети Wi-Fi.
Мы рады, что смогли помочь Вам в решении проблемы.Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
ДА НЕТХранилище данных — Википедия
Материал из Википедии — свободной энциклопедии
Храни́лище да́нных (англ. Data Warehouse) — предметно-ориентированная информационная база данных, специально разработанная и предназначенная для подготовки отчётов и бизнес-анализа с целью поддержки принятия решений в организации. Строится на базе систем управления базами данных и систем поддержки принятия решений. Данные, поступающие в хранилище данных, как правило, доступны только для чтения.
Данные из OLTP-системы копируются в хранилище данных таким образом, чтобы при построении отчётов и OLAP-анализе не использовались ресурсы транзакционной системы и не нарушалась её стабильность. Есть два варианта обновления данных в хранилище:
- полное обновление данных в хранилище. Сначала старые данные удаляются, потом происходит загрузка новых данных. Процесс происходит с определённой периодичностью, при этом актуальность данных может несколько отставать от OLTP-системы;
- инкрементальное обновление — обновляются только те данные, которые изменились в OLTP-системе.
- Проблемно-предметная ориентация. Данные объединяются в категории и хранятся в соответствии с областями, которые они описывают, а не с приложениями, которые они используют.
- Интегрированность. Данные объединены так, чтобы они удовлетворяли всем требованиям предприятия в целом, а не единственной функции бизнеса.
- Некорректируемость. Данные в хранилище данных не создаются: то есть поступают из внешних источников, не корректируются и не удаляются.
- Зависимость от времени. Данные в хранилище точны и корректны только в том случае, когда они привязаны к некоторому промежутку или моменту времени.
Существуют два основных архитектурных направления — нормализованные хранилища данных и хранилища с измерениями.
В нормализованных хранилищах, данные находятся в предметно ориентированных таблицах третьей нормальной формы. Нормализованные хранилища характеризуются как простые в создании и управлении, недостатки нормализованных хранилищ — большое количество таблиц как следствие нормализации, из-за чего для получения какой-либо информации нужно делать выборку из многих таблиц одновременно, что приводит к ухудшению производительности системы. Для решения этой проблемы используются денормализованные таблицы — витрины данных, на основе которых уже выводятся отчетные формы. При громадных объемах данных могут использовать несколько уровней «витрин»/«хранилищ».
Хранилища с измерениями используют схему «звезда» или схему «снежинка». При этом в центре «звезды» находятся данные (таблица фактов), а измерения образуют лучи звезды. Различные таблицы фактов совместно используют таблицы измерений, что значительно облегчает операции объединения данных из нескольких предметных таблиц фактов (пример — факты продаж и поставок товара). Таблицы данных и соответствующие измерения образуют архитектуру «шина». Измерения часто создаются в третьей нормальной форме, в том числе, для протоколирования изменения в измерениях. Основным достоинством хранилищ с измерениями является простота и понятность для разработчиков и пользователей, также, благодаря более эффективному хранению данных и формализованным измерениям, облегчается и ускоряется доступ к данным, особенно при сложных анализах. Основным недостатком является более сложные процедуры подготовки и загрузки данных, а также управление и изменение измерений данных.
При достаточно большом объеме данных схемы «звезда» и «снежинка» также дают снижение производительности при соединениях с измерениями.
Источниками данных могут быть:
- Традиционные системы регистрации операций
- Отдельные документы
- Наборы данных
Операции с данными:
- Извлечение — перемещение информации от источников данных в отдельную БД, приведение их к единому формату.
- Преобразование — подготовка информации к хранению в оптимальной форме для реализации запроса, необходимого для принятия решений.
- Загрузка — помещение данных в хранилище, производится атомарно, путём добавления новых фактов или корректировкой существующих.
- Анализ — OLAP, Data Mining, сводные отчёты.
- Представление результатов анализа.
Вся эта информация используется в словаре метаданных. В словарь метаданных автоматически включаются словари источников данных. Здесь же описаны форматы данных для их последующего согласования, периодичность пополнения данных, согласованность во времени.Задача словаря метаданных состоит в том, чтобы освободить разработчика от необходимости стандартизировать источники данных.Создание хранилищ данных не должно противоречить действующим системам сбора и обработки информации.Специальные компоненты словарей должны обеспечивать своевременное извлечение данных из них и обеспечить преобразование данных к единому формату на основе словаря метаданных.
Логическая структура данных хранилища данных существенно отличается от структуры данных источников данных. Для разработки эффективного процесса преобразования необходима хорошо проработанная модель корпоративных данных и модель технологии принятия решений.Данные для пользователя удобно представлять в многоразмерных БД, где в качестве измерений могут выступать время, цена или географический регион.
Кроме извлечения данных из БД, для принятия решений важен процесс извлечения знаний, в соответствии с информационными потребностями пользователя. С точки зрения пользователя в процессе извлечения знаний из БД должны решаться следующие преобразования: данные → информация → знания → полученные решения.
Как обойти ограничение на загрузку приложений больше 200 (150) мегабайт из App Store
Побороть самое глупое ограничение iPhone очень просто!
На iPhone и iPad есть одно неприятное ограничение. При помощи мобильного интернета из App Store нельзя загрузить приложение, размер которого превышает 200 Мб (ранее 150 Мб). Но что делать, если доступа к Wi-Fi нет, а скачать нужное приложение нужно здесь и сейчас? В этой инструкции поделились верным способом обхода ограничения.
Как обойти ограничение на загрузку приложений больше 200 (150) мегабайт
Для того чтобы загрузить большое приложение или игру из App Store по сотовой сети необходимо проделать следующую операцию:
Шаг 1. Начните скачивать приложение из App Store. Система выдаст оповещение «Размер этого объекта превышает 200 МБ», ожидая, что устройство будет подключено к Wi-Fi. На главном экране при этом появится иконка загружаемого вами приложения.
Шаг 2. Перейдите в меню «Настройки» → «Основные» → «Дата и время».
Шаг 3. Отключите переключатель «Автоматически» и смените дату (не время, это важно), указав любой следующий день. Например, если сегодня 13 ноября, то выберите в качестве даты 13 декабря. Чтобы изменения сохранились достаточно выйти на главный экран.
Шаг 4. Тапните по иконке приложения, которое вы загружаете для того, чтобы загрузка по сотовой сети началась.
Важно! Не меняйте дату на устройстве до завершения загрузки приложения.
После такой несложной операции загрузка нужного приложения или игры большого размера без Wi-Fi начнется!
Знай и используй:
Поделиться ссылкой
Поставьте 5 звезд внизу статьи, если нравится эта тема. Подписывайтесь на нас Telegram, ВКонтакте, Instagram, Facebook, Twitter, Viber, Дзен, YouTube.
Загрузка...
Инкремент — Википедия
Материал из Википедии — свободной энциклопедии
Текущая версия страницы пока не проверялась опытными участниками и может значительно отличаться от версии, проверенной 18 октября 2018; проверки требуют 2 правки. Текущая версия страницы пока не проверялась опытными участниками и может значительно отличаться от версии, проверенной 18 октября 2018; проверки требуют 2 правки.Инкремент, инкрементирование (от англ. increment «увеличение») — операция во многих языках программирования, увеличивающая переменную. Обратную операцию называют декремент (уменьшение). Чаще всего унарная операция приводит переменную к следующему элементу базового типа (то есть для целых чисел — увеличивает на 1, для символьного типа даёт следующий символ в некоторой таблице символов и т. п.)
Использование в языках программирования[править | править код]
Инкремент часто используется в языках программирования (равно как и в машинном языке большинства микропроцессоров), например, при организации цикла, где какая-то величина в каждом новом шаге цикла становится больше на единицу.
Для примера возьмём язык программирования JavaScript:
Соответствующий ему декремент выглядит так:
Оператор инкрементирования можно записывать с обеих сторон («префиксный инкремент» ++x и «постфиксный инкремент» x++). От этого зависит результат операции, но не его побочного действия. Так:
можно записать, как
В то время, как
эквивалентно
«префиксный декремент» --x и «постфиксный декремент» x-- действуют аналогично на переменную x, уменьшая её.
Обозначение оператора унарного постфиксного инкремента используется в названии языка программирования C++, как указание на его усовершенствование относительно своего предшественника (язык С)
Аналогичным образом назван текстовый редактор Notepad++, отсылающий к не связанной с ним программе Notepad.
В Agile используется технология PI-планирования (Program Increment Planing, планирование инкремента программы) которое распределяет значимость и порядок выполнения поставленных задач между командами. Основная цель скоординировать команды друг с другом и упорядочить выполнение задач[1].
Поскольку операция инкремента (как и декремента) используется очень часто, арифметическое устройство процессора может выполнять её на аппаратном уровне, для чего имеется отдельная низкоуровневая команда. Поэтому инкремент выполняется быстрее, чем если бы производилось прибавление единицы к числу обычным способом. Поэтому для компиляторов языка Си, которые плохо оптимизируют исходный код программы, запись ++x предпочтительнее, чем x = x + 1 или x += 1 , хотя большинство современных компиляторов языка Си уже без проблем сами заменяют арифметические выражения x = x + 1 или x += 1 на низкоуровневый инкремент на этапе оптимизации и компиляции.
традиционная и облачная / Habr
Привет, Хабр! На тему архитектуры хранилищ данных написано немало, но так лаконично и емко как в статье, на которую я случайно натолкнулся, еще не встречал.Предлагаю и вам познакомиться с данной статьей в моем переводе. Комментарии и дополнения только приветствуются!
(Источник картинки)
Введение
Итак, архитектура хранилищ данных меняется. В этой статье рассмотрим сравнение традиционных корпоративных хранилищ данных и облачных решений с более низкой первоначальной стоимостью, улучшенной масштабируемостью и производительностью.
Хранилище данных – это система, в которой собраны данные из различных источников внутри компании и эти данные используются для поддержки принятия управленческих решений.
Компании все чаще переходят на облачные хранилища данных вместо традиционных локальных систем. Облачные хранилища данных имеют ряд отличий от традиционных хранилищ:
- Нет необходимости покупать физическое оборудование;
- Облачные хранилища данных быстрее и дешевле настроить и масштабировать;
- Облачные хранилища данных обычно могут выполнять сложные аналитические запросы гораздо быстрее, потому что они используют массовую параллельную обработку.
Традиционная архитектура хранилища данных
Следующие концепции освещают некоторые из устоявшихся идей и принципов проектирования, используемых для создания традиционных хранилищ данных.
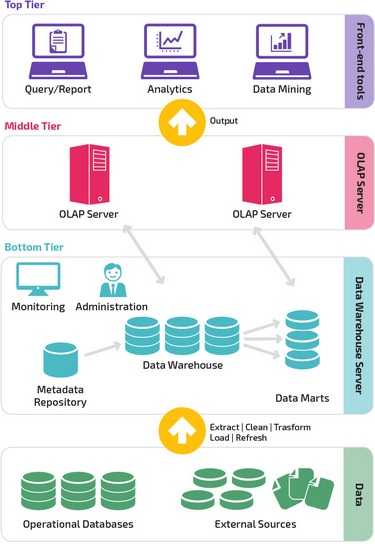
Трехуровневая архитектура
Довольно часто традиционная архитектура хранилища данных имеет трехуровневую структуру, состоящую из следующих уровней:
- Нижний уровень: этот уровень содержит сервер базы данных, используемый для извлечения данных из множества различных источников, например, из транзакционных баз данных, используемых для интерфейсных приложений.
- Средний уровень: средний уровень содержит сервер OLAP, который преобразует данные в структуру, лучше подходящую для анализа и сложных запросов. Сервер OLAP может работать двумя способами: либо в качестве расширенной системы управления реляционными базами данных, которая отображает операции над многомерными данными в стандартные реляционные операции (Relational OLAP), либо с использованием многомерной модели OLAP, которая непосредственно реализует многомерные данные и операции.
- Верхний уровень: верхний уровень — это уровень клиента. Этот уровень содержит инструменты, используемые для высокоуровневого анализа данных, создания отчетов и анализа данных.
Kimball vs. Inmon
Два пионера хранилищ данных: Билл Инмон и Ральф Кимбалл предлагают разные подходы к проектированию.
Подход Ральфа Кимбалла основывается на важности витрин данных, которые являются хранилищами данных, принадлежащих конкретным направлениям бизнеса. Хранилище данных — это просто сочетание различных витрин данных, которые облегчают отчетность и анализ. Проект хранилища данных по принципу Кимбалла использует подход «снизу вверх».
Подход Билла Инмона основывается на том, что хранилище данных является централизованным хранилищем всех корпоративных данных. При таком подходе организация сначала создает нормализованную модель хранилища данных. Затем создаются витрины размерных данных на основе модели хранилища. Это известно как нисходящий подход к хранилищу данных.
Модели хранилищ данных
В традиционной архитектуре существует три общих модели хранилищ данных: виртуальное хранилище, витрина данных и корпоративное хранилище данных:
- Виртуальное хранилище данных — это набор отдельных баз данных, которые можно использовать совместно, чтобы пользователь мог эффективно получать доступ ко всем данным, как если бы они хранились в одном хранилище данных;
- Модель витрины данных используется для отчетности и анализа конкретных бизнес-линий. В этой модели хранилища – агрегированные данные из ряда исходных систем, относящихся к конкретной бизнес-сфере, такой как продажи или финансы;
- Модель корпоративного хранилища данных предполагает хранение агрегированных данных, охватывающих всю организацию. Эта модель рассматривает хранилище данных как сердце информационной системы предприятия с интегрированными данными всех бизнес-единиц
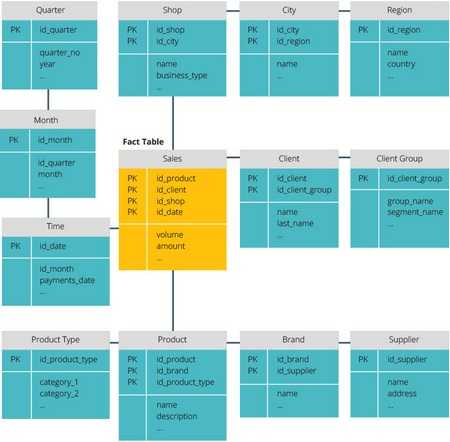
Звезда vs. Снежинка
Схемы «звезда» и «снежинка» — это два способа структурировать хранилище данных.
Схема типа «звезда» имеет централизованное хранилище данных, которое хранится в таблице фактов. Схема разбивает таблицу фактов на ряд денормализованных таблиц измерений. Таблица фактов содержит агрегированные данные, которые будут использоваться для составления отчетов, а таблица измерений описывает хранимые данные.
Денормализованные проекты менее сложны, потому что данные сгруппированы. Таблица фактов использует только одну ссылку для присоединения к каждой таблице измерений. Более простая конструкция звездообразной схемы значительно упрощает написание сложных запросов.
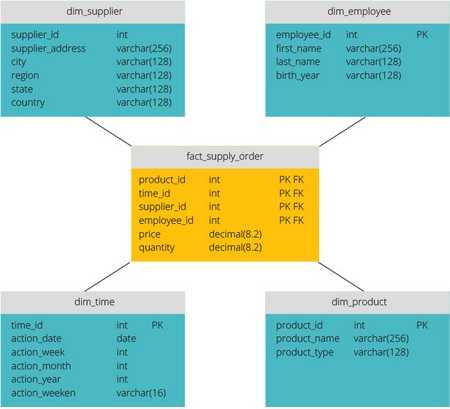
Схема типа «снежинка» отличается тем, что использует нормализованные данные. Нормализация означает эффективную организацию данных так, чтобы все зависимости данных были определены, и каждая таблица содержала минимум избыточности. Таким образом, отдельные таблицы измерений разветвляются на отдельные таблицы измерений.
Схема «снежинки» использует меньше дискового пространства и лучше сохраняет целостность данных. Основным недостатком является сложность запросов, необходимых для доступа к данным — каждый запрос должен пройти несколько соединений таблиц, чтобы получить соответствующие данные.
ETL vs. ELT
ETL и ELT — два разных способа загрузки данных в хранилище.
ETL (Extract, Transform, Load) сначала извлекают данные из пула источников данных. Данные хранятся во временной промежуточной базе данных. Затем выполняются операции преобразования, чтобы структурировать и преобразовать данные в подходящую форму для целевой системы хранилища данных. Затем структурированные данные загружаются в хранилище и готовы к анализу.
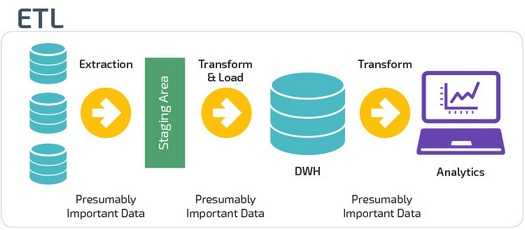
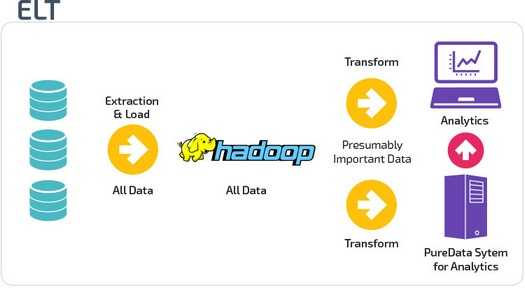
В случае ELT (Extract, Load, Transform) данные сразу же загружаются после извлечения из исходных пулов данных. Промежуточная база данных отсутствует, что означает, что данные немедленно загружаются в единый централизованный репозиторий.
Данные преобразуются в системе хранилища данных для использования с инструментами бизнес-аналитики и аналитики.
Организационная зрелость
Структура хранилища данных организации также зависит от его текущей ситуации и потребностей.
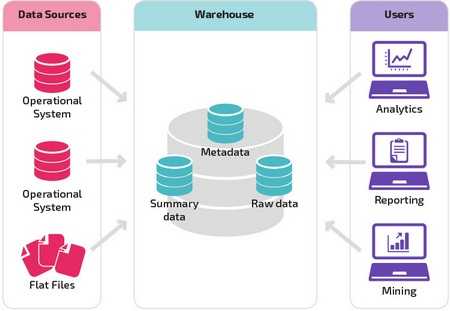
Базовая структура позволяет конечным пользователям хранилища напрямую получать доступ к сводным данным, полученным из исходных систем, создавать отчеты и анализировать эти данные. Эта структура полезна для случаев, когда источники данных происходят из одних и тех же типов систем баз данных.
Хранилище с промежуточной областью является следующим логическим шагом в организации с разнородными источниками данных с множеством различных типов и форматов данных. Промежуточная область преобразует данные в обобщенный структурированный формат, который проще запрашивать с помощью инструментов анализа и отчетности.
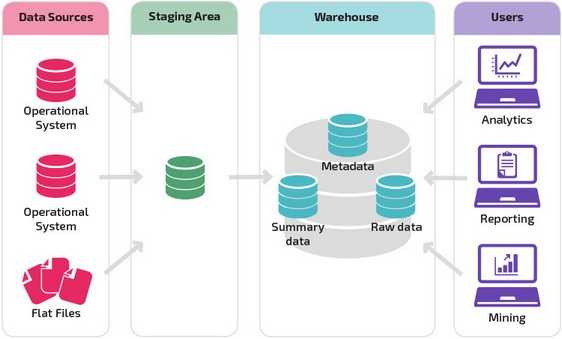
Одной из разновидностей промежуточной структуры является добавление витрин данных в хранилище данных. В витринах данных хранятся сводные данные по конкретной сфере деятельности, что делает эти данные легко доступными для конкретных форм анализа.
Например, добавление витрин данных может позволить финансовому аналитику легче выполнять подробные запросы к данным о продажах, прогнозировать поведение клиентов. Витрины данных облегчают анализ, адаптируя данные специально для удовлетворения потребностей конечного пользователя.
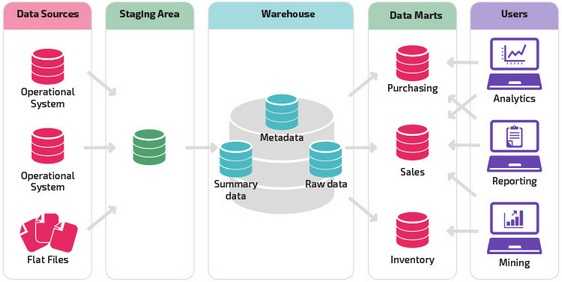
Новые архитектуры хранилищ данных
В последние годы хранилища данных переходят в облако. Новые облачные хранилища данных не придерживаются традиционной архитектуры и каждое из них предлагает свою уникальную архитектуру.
В этом разделе кратко описываются архитектуры, используемые двумя наиболее популярными облачными хранилищами: Amazon Redshift и Google BigQuery.
Amazon Redshift
Amazon Redshift — это облачное представление традиционного хранилища данных.
Redshift требует, чтобы вычислительные ресурсы были подготовлены и настроены в виде кластеров, которые содержат набор из одного или нескольких узлов. Каждый узел имеет свой собственный процессор, память и оперативную память. Leader Node компилирует запросы и передает их вычислительным узлам, которые выполняют запросы.
На каждом узле данные хранятся в блоках, называемых срезами. Redshift использует колоночное хранение, то есть каждый блок данных содержит значения из одного столбца в нескольких строках, а не из одной строки со значениями из нескольких столбцов.
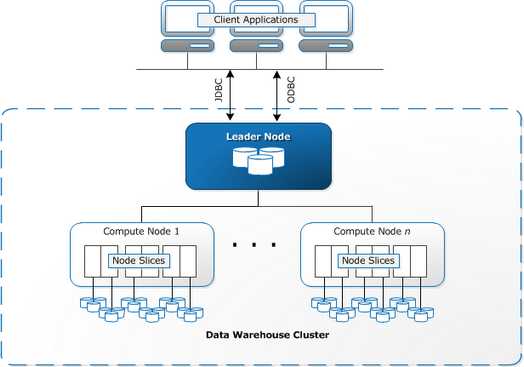
Redshift использует архитектуру MPP (Massively Parallel Processing), разбивая большие наборы данных на куски, которые назначаются слайсам в каждом узле. Запросы выполняются быстрее, потому что вычислительные узлы обрабатывают запросы в каждом слайсе одновременно. Узел Leader Node объединяет результаты и возвращает их клиентскому приложению.
Клиентские приложения, такие как BI и аналитические инструменты, могут напрямую подключаться к Redshift с использованием драйверов PostgreSQL JDBC и ODBC с открытым исходным кодом. Таким образом, аналитики могут выполнять свои задачи непосредственно на данных Redshift.
Redshift может загружать только структурированные данные. Можно загружать данные в Redshift с использованием предварительно интегрированных систем, включая Amazon S3 и DynamoDB, путем передачи данных с любого локального хоста с подключением SSH или путем интеграции других источников данных с помощью API Redshift.
Google BigQuery
Архитектура BigQuery не требует сервера, а это означает, что Google динамически управляет распределением ресурсов компьютера. Поэтому все решения по управлению ресурсами скрыты от пользователя.
BigQuery позволяет клиентам загружать данные из Google Cloud Storage и других читаемых источников данных. Альтернативным вариантом является потоковая передача данных, что позволяет разработчикам добавлять данные в хранилище данных в режиме реального времени, строка за строкой, когда они становятся доступными.
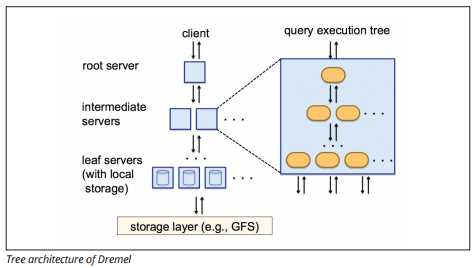
BigQuery использует механизм выполнения запросов под названием Dremel, который может сканировать миллиарды строк данных всего за несколько секунд. Dremel использует массивно параллельные запросы для сканирования данных в базовой системе управления файлами Colossus. Colossus распределяет файлы на куски по 64 мегабайта среди множества вычислительных ресурсов, называемых узлами, которые сгруппированы в кластеры.
Dremel использует колоночную структуру данных, аналогичную Redshift. Древовидная архитектура отправляет запросы тысячам машин за считанные секунды.
Для выполнения запросов к данным используются простые команды SQL.
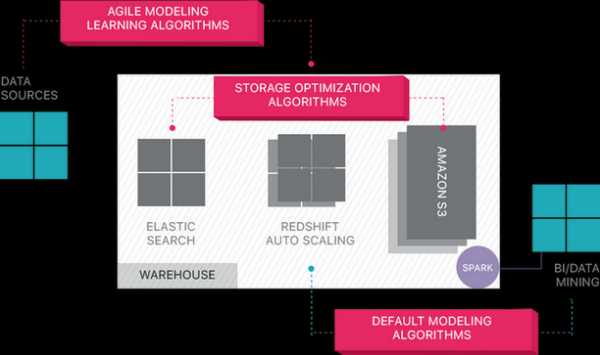
Panoply
Panoply обеспечивает комплексное управление данными как услуга. Его уникальная самооптимизирующаяся архитектура использует машинное обучение и обработку естественного языка (NLP) для моделирования и рационализации передачи данных от источника к анализу, сокращая время от данных до значения как можно ближе к нулю.
Интеллектуальная инфраструктура данных Panoply включает в себя следующие функции:
- Анализ запросов и данных — определение наилучшей конфигурации для каждого варианта использования, корректировка ее с течением времени и создание индексов, сортировочных ключей, дисковых ключей, типов данных, вакуумирование и разбиение.
- Идентификация запросов, которые не следуют передовым методам — например, те, которые включают вложенные циклы или неявное приведение — и переписывает их в эквивалентный запрос, требующий доли времени выполнения или ресурсов.
- Оптимизация конфигурации сервера с течением времени на основе шаблонов запросов и изучения того, какая настройка сервера работает лучше всего. Платформа плавно переключает типы серверов и измеряет итоговую производительность.
По ту сторону облачных хранилищ данных
Облачные хранилища данных — это большой шаг вперед по сравнению с традиционными подходами к архитектуре. Однако пользователи по-прежнему сталкиваются с рядом проблем при их настройке:
- Загрузка данных в облачные хранилища данных нетривиальна, а для крупномасштабных конвейеров данных требуется настройка, тестирование и поддержка процесса ETL. Эта часть процесса обычно выполняется сторонними инструментами;
- Обновления, вставки и удаления могут быть сложными и должны выполняться осторожно, чтобы не допустить снижения производительности запросов;
- С полуструктурированными данными трудно иметь дело — их необходимо нормализовать в формате реляционной базы данных, что требует автоматизации больших потоков данных;
- Вложенные структуры обычно не поддерживаются в облачных хранилищах данных. Вам необходимо преобразовать вложенные таблицы в форматы, понятные хранилищу данных;
- Оптимизация кластера. Существуют различные варианты настройки кластера Redshift для запуска ваших рабочих нагрузок. Различные рабочие нагрузки, наборы данных или даже различные типы запросов могут потребовать иной настройки. Для достижения оптимальной работы, необходимо постоянно пересматривать и при необходимости дополнительно настраивать конфигурацию;
- Оптимизация запросов — пользовательские запросы могут не соответствовать передовым методам и, следовательно, будут выполняться намного дольше. Вы можете работать с пользователями или автоматизированными клиентскими приложениями для оптимизации запросов, чтобы хранилище данных могло работать так, как ожидалось
- Резервное копирование и восстановление — несмотря на то, что поставщики хранилищ данных предоставляют множество возможностей для резервного копирования ваших данных, их нетривиально настроить и они требуют мониторинга и пристального внимания
Ссылка на оригинальный текст: panoply.io/data-warehouse-guide/data-warehouse-architecture-traditional-vs-cloud
Как сделать маркетинг гибким, или Зачем нужны инкременты и итерации
Лиана Хазиахметова
Цифровая среда диктует новые правила. Сегодня проект может устареть раньше, чем увидит свет, поэтому важно держать руку на пульсе и вовремя вносить изменения в создание продукта. В IT сфере применяют гибкие методологии, чтобы быстро реагировать на перемены в жизни, бизнесе, технологиях. Применить такой же подход Скотт Бринкер советует и в маркетинге. Он более 20 лет работает на стыке маркетинга и программного обеспечения, и своим опытом Бринкер поделился в книге «Agile-маркетинг». Сегодня расскажем о двух подходах, которые сделают работу вашей компании гибкой.
Инкремент = приращение или этап
При инкрементальном подходе масштабная идея, программа или проект реализуются посредством небольших последовательных шагов.
Agile-маркетинг
Например, при запуске сайта вы можете создать первоначальный вариант (первый шаг) с небольшим объемом контента в незначительном числе разделов, а затем в ходе последующих шагов увеличить количество контента, разделов, добавить дополнительные функции и прочее. На протяжении ряда шагов сайт будет расти и может стать довольно большим и сложным. Но начинается все с малого и разрастается на одно легко поддающееся управлению действие за один раз.
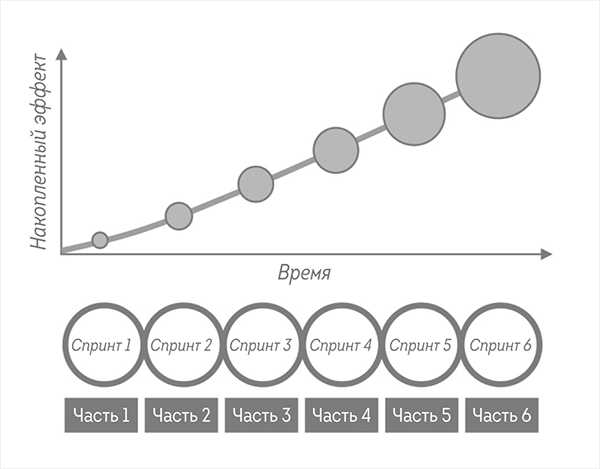
Инкрементальный маркетинг приводит к накопительному результату
Согласно философии agile-разработки, каждый шаг должен давать жизнеспособный сайт. Хотя вначале сайт выглядит небольшим, простым и содержит не все, что посетители захотят увидеть, его все-таки можно запустить в виде «как есть», предложив пользователям целостный опыт. Функциональность сайта не должна быть нарушена. В худшем случае он просто будет весьма скромным.
Тем не менее каждый инкремент, или приращение, не должен запускаться только потому, что может быть запущен. При более консервативном подходе к маркетингу большинство инкрементов в таком проекте останутся внутри организации. Разные заинтересованные стороны смогут предоставить обратную связь на каждом этапе пути. И только тогда, когда сайт можно считать вполне завершенным, его демонстрируют всем желающим.
Ценность в применении такого поэтапного процесса есть даже в имеющейся среде. Сайт проходит через разные этапы создания и должен быть пригоден к использованию на каждом шаге, чтобы заинтересованные лица действительно могли его опробовать. Это отражают две ценности Agile-манифеста: работающий продукт важнее исчерпывающей документации, а сотрудничество с заказчиком важнее согласования условий контракта.
Заинтересованные стороны могут дать более детальную обратную связь в отношении того, что можно «потрогать руками», в противовес необходимости вникать в нечеткие описания или низкокачественные эскизы того, что должно получиться. Естественные переломные моменты каждого инкремента позволяют часто корректировать курс на основе новой информации. Когда при планировании спринта мы определяем, что будет создано в ближайшие инкременты, мы можем учитывать новые приоритеты и свежие инсайты рынка.

Работайте инкрементами, и вы всегда будете знать, куда вы идете. Источник
Чаще всего каждый завершенный инкремент дает нам возможность решить: «Пора запускать!», поэтому мы можем выпустить на рынок то, что получилось в конце любого из спринтов, если, на наш взгляд, ситуация благоприятная. И это консервативный подход. Более прогрессивный подход, использующий преимущества цифровой динамики, состоит в более агрессивном запуске итогов завершенных инкрементных задач. Лучше сделать запуск раньше, чем позже. В нашем примере с сайтом каждый завершенный инкремент будет по умолчанию незамедлительно опубликован для потребителей.
Более частый выпуск инкрементов дает еще два преимущества.
Во-первых, это позволяет получить обратную связь от реальной аудитории. Потенциальные и существующие клиенты могут сразу сообщить свое мнение или сделать это косвенно — посредством своего поведения. Сколько времени они проводят на сайте? Сколько страниц просматривают? Делятся ли информацией в социальных сетях? Следуют ли нашим призывам к действию, например, подписаться на рассылку новой информации по электронной почте или запросить разговор с работником отдела продаж?
Такая обратная связь бесценна, поскольку выводит нас за пределы теоретических рассуждений, которые, как правило, доминируют во внутренних дискуссиях, о том, какая кампания предположительно должна найти отклик у аудитории. Вместо этого мы получаем точные данные о том, какой отклик находят наши идеи. Мы можем использовать их, чтобы скорректировать направление работ в последующих инкрементах. Не стоит позволять внутренним гипотезам слишком долго вариться в собственном соку, лучше вытащить их на свет, который проливают эмпирические данные.
Во-вторых, более частый выпуск инкрементов быстрее выталкивает последние маркетинговые идеи в мир — и они быстрее достигают целевой аудитории. Мы ускоряем изучение полученных результатов и используем открывающиеся возможности раньше конкурентов, получая солидную выгоду.
В современном маркетинге скорость имеет значение, и частый выпуск инкрементальных результатов помогает обуздать быстроту цифрового мира, обратив ее себе на пользу.
Итерация = версия
Итерации похожи на инкременты в том смысле, что обычно начинаются с малого. «Какой именно маркетинговый результат мы можем получить и развернуть в рамках одного спринта?» В отличие от инкрементов итерации не всегда рассматриваются как части крупного проекта. Они либо дают небольшие автономные результаты, либо вносят незначительные изменения в существующие программы или функциональные средства. Их размер не обязательно должен увеличиваться. Стимул для выполнения нескольких итераций — не рост масштабов того, что создается, а повышение производительности, как показано на рисунке.
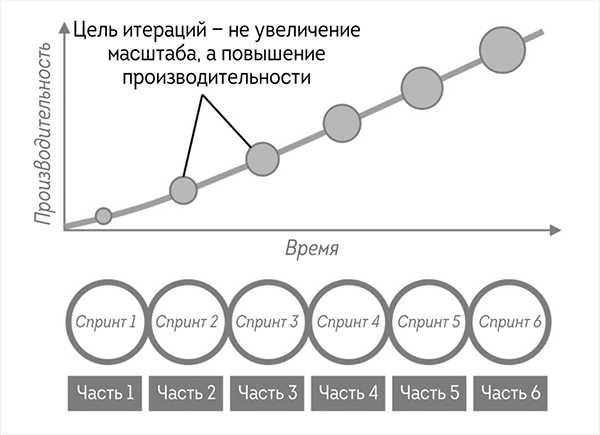
Итерационный маркетинг направлен на достижение общего роста производительности
Типичный пример итерации в маркетинге — жизненный цикл посадочной страницы. Это страница сайта, посвященная конкретной маркетинговой кампании, на которую будут попадать посетители, щелкнув по рекламе либо перейдя по ссылке, указанной в имейл-рассылке или социальных сетях. Она, как правило, содержит призыв к действию и стремится убедить пользователей совершить его, например: заполнить форму, скачать отчет, зарегистрироваться на вебинар или сделать онлайн-покупку.
В маркетинге мы редко знаем заранее, что именно сработает. Существуют лишь наши предположения, основанные на опыте, интуиции и знании рынка, полученных при наблюдении за действиями других компаний. А еще есть вдохновение, которое иногда неожиданно нас посещает.
Но прогнозировать, какие идеи сработают в непроверенных ситуациях, практически невозможно. Люди и рынки слишком сложны, да и мир меняется чересчур быстро. В лучшем случае мы можем использовать всю имеющуюся информацию, чтобы сделать реалистичное предположение. Но мы не узнаем точно, пока не попробуем.
В доцифровом мире было мало маркетинговых идей, которые можно было проверить, поэтому мы делали ставки на кампании с наибольшим потенциалом (по нашему мнению) и смотрели, что из этого выйдет. Иногда такие действия окупались, иногда нет. В те времена точных цифровых метрик не существовало, и мы не всегда знали, хорошо ли выполняется маркетинговая программа, даже если она была настоящим подарком для нас. Это была игра по-крупному — с завязанными глазами.
Вместо того чтобы пытаться угадать, какая из десятка идей сразу же заработает, мы можем, рискуя по-крупному, попробовать все предложения с низкими рисками, а потом уверенно выбрать победителя. Это что-то вроде мошенничества, но в хорошем смысле.
Так выглядит более надежный способ — путь хакера — оказаться гением маркетинга.

Agile поможет стать гением маркетинга. Источник
Чем больше вариантов мы протестируем, тем выше вероятность обнаружить среди них выигрышный. Именно поэтому agile-маркетинг подразумевает многочисленные небольшие эксперименты вместо нескольких масштабных активностей. Это не значит, что мы не можем или не хотим делать большие запуски, мы просто стремимся как можно чаще использовать опыт проверки мелких активностей, чтобы определить, какие из них в крупном формате будут наиболее успешными.
Цифровая среда делает такое поведение технически осуществимым, а спринты Agile — организационно реалистичным. Ограниченность времени спринта заставляет делать итерации небольшими, поэтому их можно быстро реализовать и протестировать. Обзор спринта дает возможность анализировать результативность последних итераций, оценить результаты по сравнению с ожиданиями и в следующем планировании спринта учесть относительный приоритет дальнейшего развития конкретной инициативы или перейти к какой-либо другой. Это объясняет, почему agile-маркетинг считает тестирование и данные важнее мнений и условностей. Мы можем запустить небольшие тесты с низким риском, поэтому нет необходимости полагаться на «чутье», чтобы решить, какой подход выбрать для определенной маркетинговой тактики. Вместо того чтобы спорить, лучше сказать: «Давай проверим!» — и полученные данные покажут, что нравится аудитории.
Такой подход также обеспечивает безопасный способ отказа от части устаревших правил организации. Столкнувшись с непрошибаемой стеной установок «мы всегда делали именно так» или «мы никогда так не делали», agile-маркетологи скромно посоветуют «просто проверить этот способ». Результаты выявят наиболее эффективный вариант.
Попробуйте, и вы увидите, как итеративные и инкрементные изменения в работе улучшат и повысят эффективность компании.
По материалам книги «Agile-маркетинг»
Обложка поста: unsplash.com
Проектирование хранилищ данных DWH в Microsoft Excel
Смотрите видео к статье:
Excel как инструмент проектирования баз данных (для разработчиков BI / программистов SQL)
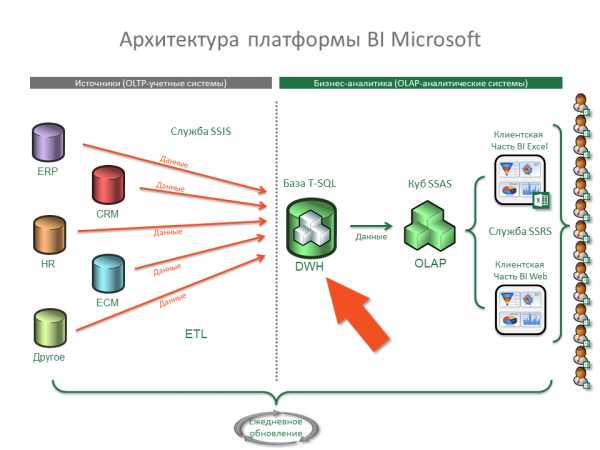
Data Warehouse = DWH = Хранилище данных (rus) – это специальная аналитическая база данных, предназначенная для подготовки аналитических отчетов или построения дальнейшей бизнес-аналитики в OLAP-кубах (OLAP-системах). Данные в DWH-хранилище, как правило, поступают путем прямого импорта из корпоративных учетных систем различного назначения (OLTP-систем), например:
- ERP – основная корпоративная учетная система (как правило: 1С, NAV, SAP)
- CRM – система управления взаимоотношениями с клиентами
- HR – система управления персоналом
- ECM (СЭД) – система электронного документооборота
- и т.п.
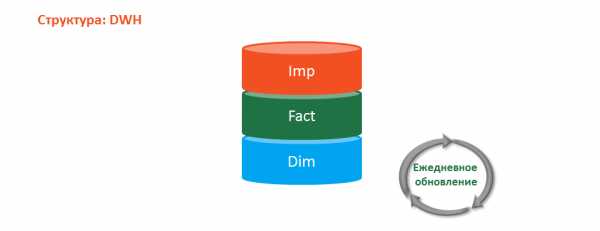
Структура базы данных DWH чаще всего состоит из трех типов таблиц:
- Таблицы «Импорта» (Imp) — используются для импорта данных из OLTP-систем и последующего обновления таблиц «Фактов» и «Измерений»
- Таблицы «Фактов» (Fact) — содержат все аналитические показатели и ключи связи с таблицами «Измерений»
- Таблицы «Измерений» (Dim) — содержат все аналитические атрибуты измерений, по которым можно анализировать показатели из таблиц «Фактов»
Примечание: таблицы «Фактов» еще часто называют «Меры», а таблицы «Измерений» — «Справочники».
Импорт данных из OLTP-систем и обновление DWH зависит от выбранного подхода:
- «Полное» обновление данных в хранилище – обновляются все данные в хранилище при каждом запуске обновления
- «Инкрементальное» обновление данных в хранилище — обновляются не все данные в хранилище, а только те, которые изменились в OLTP за промежуток времени между запуском обновлений
Универсального и готового решения для выполнения обновления DWH на рынке я не встречал. Каждый программист/разработчик использует что-то свое…
Я, например, в готовых решениях Бизнес – аналитики (BI) использую свои уникальные скрипты, которые позволяют автоматически обновлять хранилище DWH за любой выбранный период.
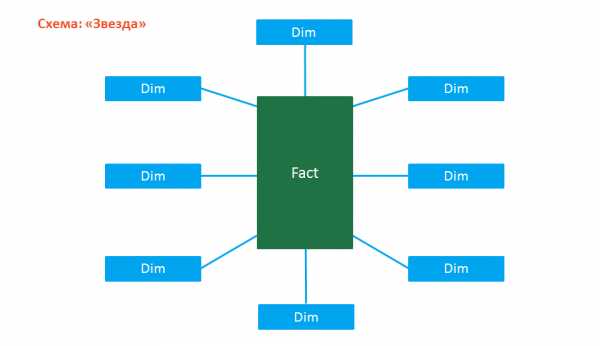
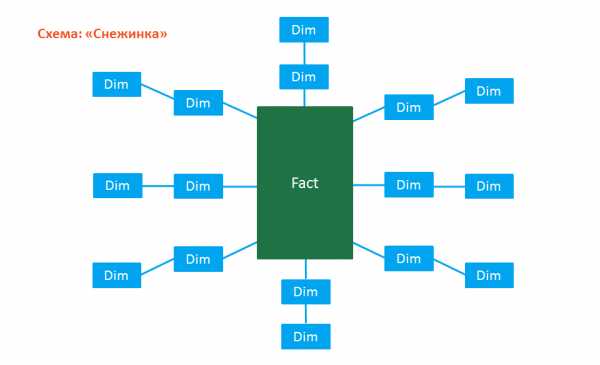
Связь таблиц «Фактов» и «Измерений» зависит от выбранной схемы:
- Схема «Звезда»
- Схема «Снежинка»
Проектирование Data Warehouse (DWH):
Не буду здесь говорить про специализированный SOFT. Конечно, он существует и может быть функциональным и полезным.
При этом хочу порекомендовать для моделирования хранилища данных (DWH) программу Microsoft Excel, которая всегда под рукой и обладает необходимым функционалом:
- Удобно оперировать табличными данными
- Можно показывать образцы данных
- Можно автоматически составлять SQL скрипты
- Можно легко обмениваться файлами (т.к. Excel есть у всех)
Для создания модели DWH достаточно освоить следующие функции Excel:
- ТРАНСП() — Транспонирование диапазонов ячеек — т.е. изменение направления, в котором располагаются ячейки
- СЦЕПИТЬ() или ее аналог «&»
Примеры формул для генерации SQL скрипта:
(где h3 – название поля, G2 – тип поля, F2 – описание поля)
- SQL to Create – пример: [DataTypeKey] nvarchar (32), —Тип данных Key
Формула:
="["&h3&"] "&G2&", --"&F2
- SQL to Select AS – пример: DataTypeKey AS DataTypeKey, —Тип данных Key
Формула:
=h3&" AS "&h3&", --"&F2
- SQL to Select – пример: DataTypeKey,
Формула:
=h3&","
- SQL to Update – пример: DataTypeKey = source.DataTypeKey,
Формула:
=h3&" = source."&h3&","
- SQL to Insert – пример: source.DataTypeKey,
Формула:
="source."&h3&","
Подробно, как все работает, смотрите видеоинструкцию.
Предложение:
- Мы предлагаем разработать для Вас необходимое хранилище данных (DWH).
- Вы получите лучшие отраслевое DWH — хранилище и сэкономите до 90% от рыночной стоимости!
Что такое DWH и как они повышают ценность данных для бизнеса
Тем, кто работает в крупном бизнесе, периодически приходится слышать три магические буквы — DWH. Узнав расшифровку этой аббревиатуры — data warehouse, можно догадаться, что это имеет отношение к данным. А вот чем DWH отличается от простых баз данных, почему вокруг них снуют рои бизнес-аналитиков и зачем вашей компании иметь такую штуку — это всё еще непонятно. Разбираемся в статье.
DWH — что это и в чем отличие от баз данных
Data warehouse — склад всех нужных и важных для принятия решений данных компании.
Но есть же всякие базы данных внутри фирмы, разве они не DWH? Например, СУБД с клиентами, складскими запасами или покупками. Где разница между обычной базой данных и DWH?
Разница вот в чем:
- Типы хранимых данных. Обычные СУБД хранят данные строго для определенных подсистем. База данных склада хранит складские запасы и ничего более. База данных кадровиков хранит данные по персоналу, но не товары или сделки. DWH, как правило, хранит информацию разных подразделений — там найдутся данные и по товарам, и по персоналу, и по сделкам.
- Объемы данных. Обычная БД, которая ведется в рамках стандартной деятельности компании, содержит только актуальную информацию, нужную в данный момент для функционирования определенной системы. В DWH пишутся не столько копии актуальных состояний, сколько исторические данные и агрегированные значения. Например, состояние запасов разных категорий товаров на конец смены за последние пять лет. Иногда в DWH пишутся и более крупные пачки данных, если они имеют критическое значение для бизнеса — допустим, полные данные по продажам и сделкам. То есть, по сути, это копия СУБД отдела продаж.
- Место в рабочих процессах. Информация обычно сразу попадает в рабочие базы данных, а уже оттуда некоторые записи переползают в DWH. Склад данных, по сути, отражает состояние других БД и процессов в компании уже после того, как вносятся изменения в рабочих базах.
Короче говоря, DWH — это система данных, отдельная от оперативной системы обработки данных. В корпоративных хранилищах в удобном для анализа виде хранятся архивные данные из разных, иногда очень разнородных источников. Эти данные предварительно обрабатываются и загружаются в хранилище в ходе процессов извлечения, преобразования и загрузки, называемых ETL. Решения ETL и DWH — это (упрощенно) одна система для работы с корпоративной информацией и ее хранения.
Что дают DWH-решения для BI и принятия решений в компании
Понятное дело, что просто так тратить деньги и время на консервирование кучи разных записей, которые и так можно накопать в других базах данных, никто не станет. Ответ заключается в том, что DWH необходима для того, чтобы делать BI — business intelligence.
Что такое BI с DWH? Бизнес-аналитика (BI) — это процесс анализа данных и получения информации, помогающей компаниям принимать решения.
Допустим, у вас в онлайн-магазине упала выручка. Менеджеры зовут на помощь бизнес-аналитика и просят его разобраться. Тот идет в DWH, вынимает оттуда данные по продажам, выручке, количеству пользователей, расходам — и собирает отчет, который в подробностях и с цифрами говорит о причинах падения финансовых показателей. Менеджеры внимательно смотрят на эту информацию и принимают решения по реорганизации ассортимента товаров и маркетинговых политик.Если бы такого аналитического отчета не было — управленцам пришлось бы искать проблему наугад.
Логичный вопрос: казалось бы, зачем держать для этого всего DWH? Аналитики вполне могут ходить в базы данных разных систем и просто выдергивать оттуда то, что им надо.
Ответ: так, конечно, тоже можно делать. Но — не нужно. И вот почему:
- Доступ к нужным данным. Если компания большая, на получение данных из разных источников нужно собирать разрешения и доступы. У каждого подразделения в такой ситуации, как правило, свои базы данных со своими паролями, которые надо будет запрашивать отдельно. В DWH все нужное уже будет под рукой в готовом виде. Можно просто пойти и дернуть там необходимую статистику.
- Сохранность нужных данных. Данные в DWH не теряются и хранятся в виде, удобном для принятия решений: есть исторические записи, есть агрегированные значения. В операционной базе данных такой информации может и не быть. Например, админы уж точно не будут хранить на складском сервере архив запасов за 10 лет — БД склада в таком случае была бы слишком тяжелой. А вот хранить агрегированные запасы со склада в DWH — это нормально.
- Устойчивость работы бизнес-систем. DWH оптимизируется для работы аналитиков, а эти ребята могут запрашивать очень большие объемы информации. Если они будут делать это с помощью DWH — ничего страшного, даже если их запрос будет обрабатываться очень долго. А если запросить слишком много записей с боевой базы данных сервера — он может уйти в отказ до конца выполнения запроса от аналитики и создать проблемы для других систем. DWH исключает риск того, что аналитики что-то повесят или сломают.
Для работы с большими данными используют различные решения, обрабатывающие информацию из DWH. SAS, Mail.ru Cloud Solutions и другие компании предлагают различные варианты коробочных и облачных решений под такие задачи.
Резервное копирование — Википедия
Картридж для стримера формата LTO — пример носителя резервной копии, используемого в современных центрах обработки данных.Резервное копирование (англ. backup copy) — процесс создания копии данных на носителе (жёстком диске, дискете и т. д.), предназначенном для восстановления данных в оригинальном или новом месте их расположения в случае их повреждения или разрушения.
- Резервное копирование данных (резервное дублирование данных) — процесс создания копии данных.
- Восстановление данных — процесс восстановления в оригинальном месте.
Резервное копирование необходимо для возможности быстрого и недорогого восстановления информации (документов, программ, настроек и т. д.) в случае утери рабочей копии информации по какой-либо причине.
Кроме этого, решается проблема передачи данных и работы с общими документами.
Требования к системе резервного копирования[править | править код]
- Надёжность хранения информации — обеспечивается применением отказоустойчивого оборудования систем хранения, дублированием информации и заменой утерянной копии другой в случае уничтожения одной из копий (в том числе как часть отказоустойчивости).
- Многоплатформенность - полноценное функционирование системы резервного копирования в гетерогенной сети предполагает, что её серверная часть будет работать в различных операционных средах и поддерживать клиенты на самых разных аппаратно-программных платформах.
- Простота в эксплуатации — автоматизация (по возможности минимизировать участие человека: как пользователя, так и администратора).
- Быстрое внедрение — простая установка и настройка программ, быстрое обучение пользователей.
Ключевыми параметрами резервного копирования являются:
- RPO — Recovery Point Objective;
- RTO — Recovery Time Objective.
RPO определяет точку отката — момент времени в прошлом, на который будут восстановлены данные, а RTO определяет время, необходимое для восстановления из резервной копии.
Существует несколько видов резервного копирования[1][2]:
Полное резервное копирование (Full backup)[править | править код]
- Полное копирование обычно затрагивает всю систему и все файлы. Еженедельное, ежемесячное и ежеквартальное резервное копирование подразумевает создание полной копии всех данных. Обычно оно выполняется тогда, когда копирование большого объёма данных не влияет на работу организации. Для предотвращения большого объёма использованных ресурсов используют алгоритмы сжатия, а также сочетание этого вида с другими: дифференциальным или инкрементным. Полное резервное копирование незаменимо в случае, когда нужно подготовить резервную копию для быстрого восстановления системы с нуля.
Дифференциальное резервное копирование (Differential backup)[править | править код]
- При дифференциальном («разностном») резервном копировании каждый файл, который был изменён с момента последнего полного резервного копирования, копируется каждый раз заново. Дифференциальное копирование ускоряет процесс восстановления. Все копии файлов делаются в определённые моменты времени, что, например, важно при заражении вирусами.
Инкрементное резервное копирование (Incremental backup)[править | править код]
- При добавочном («инкрементном») резервном копировании происходит копирование только тех файлов, которые были изменены с тех пор, как в последний раз выполнялось полное или добавочное резервное копирование. Последующее инкрементное резервное копирование добавляет только файлы, которые были изменены с момента предыдущего. Инкрементное резервное копирование занимает меньше времени, так как копируется меньшее количество файлов. Однако процесс восстановления данных занимает больше времени, так как должны быть восстановлены данные последнего полного резервного копирования, а также данные всех последующих инкрементных резервных копирований. В отличие от дифференциального копирования, изменившиеся или новые файлы не замещают старые, а добавляются на носитель независимо.
Клонирование[править | править код]
- Клонирование позволяет скопировать целый раздел или носитель (устройство) со всеми файлами и каталогами в другой раздел или на другой носитель. Если раздел является загрузочным, то клонированный раздел тоже будет загрузочным[3].
Резервное копирование в виде образа[править | править код]
- Образ — точная копия всего раздела или носителя (устройства), хранящаяся в одном файле[4].
Резервное копирование в режиме реального времени[править | править код]
- Резервное копирование в режиме реального времени позволяет создавать копии файлов, каталогов и томов, не прерывая работу, без перезагрузки компьютера.[5]
Холодное резервирование[править | править код]
- При холодном резервировании база данных выключена или закрыта для потребителей. Файлы данных не изменяются и копия базы данных находится в согласованном состоянии при последующем включении.[6]
Горячее резервирование[править | править код]
- При горячем резервировании база данных включена и открыта для потребителей. Копия базы данных приводится в согласованное состояние путём автоматического приложения к ней журналов резервирования по окончании копирования файлов данных.[6]
Смена рабочего набора носителей в процессе копирования называется их ротацией. Для резервного копирования очень важным вопросом является выбор подходящей схемы ротации носителей (например, магнитных лент).
Одноразовое копирование[править | править код]
Простейшая схема, не предусматривающая ротации носителей. Все операции проводятся вручную. Перед копированием администратор задаёт время начала резервного копирования, перечисляет файловые системы или каталоги, которые нужно копировать. Эту информацию можно сохранить в базе данных, чтобы её можно было использовать снова. При одноразовом копировании чаще всего применяется полное копирование.
Простая ротация[править | править код]
Простая ротация подразумевает, что некий набор лент используется циклически. Например, цикл ротации может составлять неделю, тогда отдельный носитель выделяется для определённого рабочего дня недели. Недостаток данной схемы — она не очень подходит для ведения архива, поскольку количество носителей в архиве быстро увеличивается. Кроме того, инкрементальная/дифференциальная запись проводится на одни и те же носители, что ведёт к их значительному износу и, как следствие, увеличивает вероятность отказа.
«Дед, отец, сын»[править | править код]
Данная схема имеет иерархическую структуру и предполагает использование комплекта из трёх наборов носителей. Раз в неделю делается полная копия дисков компьютера («отец»), ежедневно же проводится инкрементальное (или дифференциальное) копирование («сын»). Дополнительно раз в месяц проводится ещё одно полное копирование («дед»). Состав ежедневного и еженедельного набора постоянен. Таким образом, по сравнению с простой ротацией в архиве содержатся только ежемесячные копии плюс последние еженедельные и ежедневные копии. Недостаток данной схемы состоит в том, что в архив попадают только данные, имевшиеся на конец месяца, а также в износе носителей.
«Ханойская башня»[править | править код]
Схема призвана устранить некоторые из недостатков схемы простой ротации и ротации «Дед, отец, сын». Схема построена на применении нескольких наборов носителей. Каждый набор предназначен для недельного копирования, как в схеме простой ротации, но без изъятия полных копий. Иными словами, отдельный набор включает носитель с полной недельной копией и носители с ежедневными инкрементальными (дифференциальными) копиями. Специфическая проблема схемы «ханойская башня» — её более высокая сложность, чем у других схем.
«10 наборов»[править | править код]
Данная схема рассчитана на десять наборов носителей. Период из сорока недель делится на десять циклов. В течение цикла за каждым набором закреплён один день недели. По прошествии четырёхнедельного цикла номер набора сдвигается на один день. Иными словами, если в первом цикле за понедельник отвечал набор номер 1, а за вторник — номер 2, то во втором цикле за понедельник отвечает набор номер 2, а за вторник — номер 3. Такая схема позволяет равномерно распределить нагрузку, а следовательно, и износ между всеми носителями.
Схемы «Ханойская башня»[источник не указан 3037 дней] и «10 наборов» используются нечасто, так как многие системы резервного копирования их не поддерживают.
Эксплуатационные поломки носителей информации[править | править код]
Описание: случайные поломки в пределах статистики отказов, связанные с неосторожностью или выработкой ресурса. Если важная информация уже потеряна, то можно обратиться в специализированную службу, но надёжность не стопроцентная.
Решение: хранить всю информацию (каждый файл) минимум в двух экземплярах (причём каждый экземпляр на своём носителе данных). Для этого применяются:
- RAID 1, обеспечивающий восстановление самой свежей информации. Файлы, расположенные на сервере с RAID, более защищены от поломок, чем хранящиеся на локальной машине;
- Ручное или автоматическое копирование на другой носитель. Для этого может использоваться система контроля версий, специализированная программа резервного копирования или подручные средства наподобие периодически запускаемого cmd-файла.
Стихийные и техногенные бедствия[править | править код]
Описание: шторм, землетрясение, кража, пожар, прорыв водопровода — всё это может привести к потере всех носителей данных, расположенных на определённой территории.
Борьба: единственный способ защиты от стихийных бедствий — держать часть резервных копий в другом помещении. В частности, помогает резервное копирование через сеть на компьютер, расположенный достаточно далеко (или в облачное хранилище данных).
Вредоносные программы[править | править код]
Описание: в эту категорию входит случайно занесённое ПО, которое намеренно портит информацию — вирусы, черви, «троянские кони». Иногда факт заражения обнаруживается, когда немалая часть информации искажена или уничтожена.
Борьба:
- Установка антивирусных программ на рабочие станции. Простейшие антивирусные меры — отключение автозагрузки, изоляция локальной сети от Интернета, и т. д.
- Обеспечение централизованного обновления: первая копия антивируса получает обновления прямо из Интернета, а другие копии настроены на папку, куда первая загружает обновления; также можно настроить прокси-сервер таким образом, чтобы обновления кэшировались (это всё меры для уменьшения трафика).
- Иметь копии в таком месте, до которого вирус не доберётся — выделенный сервер или съёмные носители.
- Если копирование идёт на сервер: обеспечить защиту сервера от вирусов (либо установить антивирус, либо использовать ОС, для которой вероятность заражения мала). Хранить версии достаточной давности, чтобы существовала копия, не контактировавшая с заражённым компьютером.
- Если копирование идёт на съёмные носители: часть носителей хранить (без дописывания на них) достаточно долго, чтобы существовала копия, не контактировавшая с заражённым компьютером.
- Использование носителей с однократной записью: CD-R, DVD-R, BD-R. Их объём недостаточен для серьёзных применений.
Человеческий фактор[править | править код]
Описание: намеренное или ненамеренное уничтожение важной информации — человеком, специально написанной вредоносной программой или сбойным ПО.
Борьба:
- Тщательно расставить права на все ресурсы, чтобы другие пользователи не могли модифицировать чужие файлы. Исключение делается для системного администратора, который должен обладать всеми правами на всё, чтобы быть способным исправить ошибки пользователей, программ и т. д.
- Построить работающую систему резервного копирования — систему, которой люди реально пользуются и которая достаточно устойчива к ошибкам оператора. Если пользователь не пользуется системой резервного копирования, вся ответственность за сохранность ложится на него.
- Хранить версии достаточной давности, чтобы при обнаружении испорченных данных файл можно было восстановить.
- Перед переустановкой ОС следует обязательно копировать всё содержимое раздела, на которой будет установлена ОС, на сервер, на другой раздел или на CD/DVD.
- Оперативно обновлять ПО, которое заподозрено в потере данных.
Затруднения при резервном копировании[править | править код]
Законы об авторском праве и других исключительных правах могут запрещать или ограничивать копирование. Иногда для резервного копирования предусматриваются исключения (см. Свободное использование произведений, ограничения и исключения в области авторского права).
Условия использования проприетарного программного обеспечения и других несвободных произведений также могут ограничивать или запрещать резервное копирование.
Технические меры защиты от копирования затрудняют резервное копирование независимо от законов и условий.
- ↑ А. Н. Чекмарев, Д. Б. Вишнякова. Глава 8. Восстановление системы. Процедуры резервного копирования и восстановления // Microsoft Windows 2000: Server и Professional. Русские версии. — Санкт-Петербург: БХВ — Санкт-Петербург, 2000. — С. 294—298. — 1056 с. — 5 000 экз. — ISBN 5-8206-0107-6.
- ↑ Шапиро Дж., Бойс Дж. Глава 17. Архивация и восстановление данных // Windows 2000 Server. Библия пользователя = Windows 2000 Server. Bible. — Москва: «Диалектика», 2001. — С. 615-617. — 912 с. — ISBN 5-8459-0161-8 (рус.) 0-7645-4667-8 (англ.).
- ↑ Словарь терминов Acronis
- ↑ Словарь терминов Acronis (неопр.) (недоступная ссылка). Дата обращения 22 декабря 2011. Архивировано 28 декабря 2010 года.
- ↑ Словарь терминов Acronis
- ↑ 1 2 What is cold backup (offline backup)?
Полное, инкрементное, дифференциальное – о методах резервного копирования
Друзья, привет. На сайте так много практического материала по резервному копированию, но вот как-то я упустил из виду теоретическую часть. В комментариях вы меня периодически спрашиваете по поводу методов резервного копирования - полного, инкрементного и дифференциального. В чём их разница, что лучше выбрать и т.п. В этой статье, собственно, и будем детально разбираться во всех этих вопросах.Полное, инкрементное, дифференциальное – о методах резервного копирования
А разбираться в методах резервного копирования предлагаю на примере программы AOMEI Backupper. Итак, друзья, когда мы в программе AOMEI Backupper создаём резервную копию Windows, целого диска, отдельных разделов или отдельных папок с данными, в дальнейшем после создания резервной копии сможем использовать для неё некоторые программные возможности. В их числе – создание на базе заданных условий бэкапа новых копий с выбором механизма резервного копирования:- Полная копия;
- Инкрементная копия;
- Дифференциальная копия.
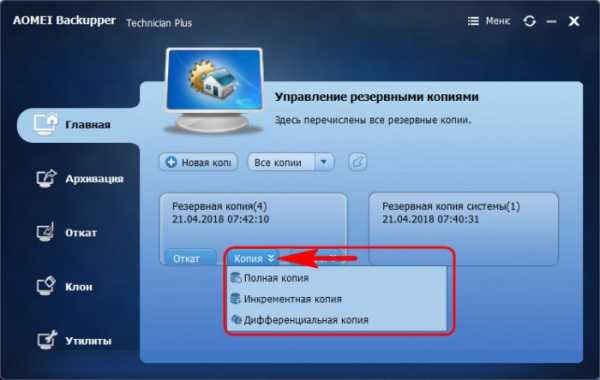
Что же это за механизмы?
Полное резервное копирование
Полное – это резервное копирование, при котором снимок операционной системы, диска, раздела или отдельных папок содержит все резервируемые данные. Такие снимки, создаваемые в рамках одной и той же задачи по бэкапу, независимы друг от друга, повреждение одного из них никак не повлияет на другие снимки. Это самый надёжный метод резервного копирования, но, вместе с тем, самый затратный по ресурсам дискового пространства. Например, образ рабочей Windows без особых каких-то громоздких программ и игр будет весить примерно 20 Гб. Если по мере создания новых бэкапов не избавляться от старых, диск-хранилище просто забьётся ими под завязку. Решить эту проблему призваны два других механизма резервного копирования.
Инкрементное резервное копирование
Инкрементное – это такое резервное копирование, при котором полная копия создаётся единожды в начале, а все последующие копии, создаваемые в рамках одной и той же задачи, содержат не все данные, а лишь произошедшие изменения - какие файлы удалены, а какие добавлены. Первая инкрементная копия содержит разницу в данных между ней самой и полной копией. А вторая инкрементная копия содержит разницу между ней самой и первой инкрементной копией. Третья – между ней самой и второй. И так далее. Каждая новая инкрементная копия зависит от своей предшественницы и не может быть задействована для процесса восстановления без такой предшественницы. Ну и, конечно же, без полной первичной копии. Каждая из резервных копий задачи – хоть полная, хоть инкрементная - являет собой точку восстановления. И мы всегда сможем выбрать дату или время, на которое хотим откатить систему или данные.
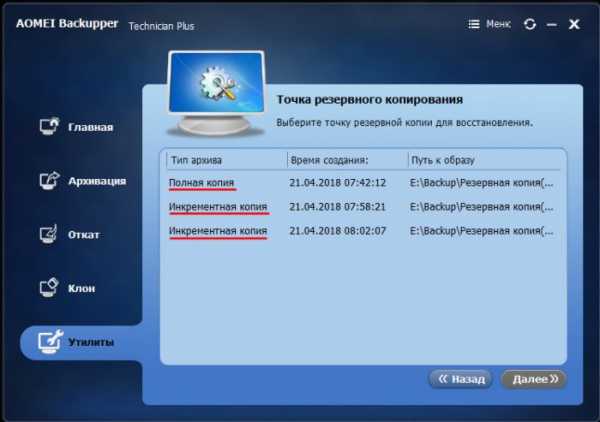
Удаление инкрементной копии (или повреждение её вирусами) не будет иметь следствием неработоспособность предыдущих инкрементных копий и первичной полной. А вот последующих – будет. К точкам после удалённой инкрементной копии откатиться мы уже не сможем. В этом плане, конечно, метод инкрементного копирования уязвим, но его сильной стороной является обеспечение отката к разным точкам состояния при минимально занятом дисковом пространстве. Ведь при незначительных изменениях каждая новая копия будет весить пару Мб разницы между ней и предшественницей. Вот как, например, бэкап раздела на скриншоте ниже. Вес в 3,57 Гб, отмеченный сиреневым маркером – это вес полной первичной копии, а отмеченные жёлтым маркером 9,12 Мб и 20,01 Мб – это вес инкрементных копий.
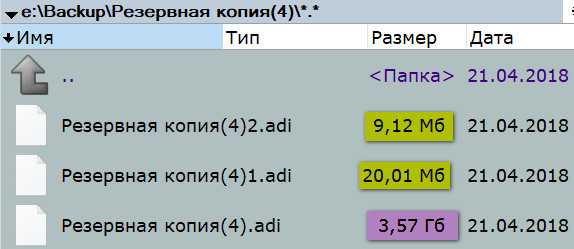
Ещё один недостаток инкрементных копий – более долгий по времени процесс восстановления, чем из полных и дифференциальных бэкапов.
Дифференциальное резервное копирование
Дифференциальное – это такое резервное копирование, при котором полная копия создаётся единожды в начале, а все последующие копии, создаваемые в рамках одной и той же задачи, содержат не все данные, а лишь произошедшие изменения с момента создания первичной полной копии. Ключевой момент здесь – с момента создания полной копии. Тогда как при инкрементом копировании вторая инкрементная копия цепочки являет собой разницу между ней и первой копией, при дифференциальном и первая, и вторая, и третья, и четвёртая, и все следующие дифференциальные копии будут зависимыми только от полной копии. Но никак не зависимыми друг от друга. Удаление или повреждение любой из дифференциальных копий не повлияет на другие копии – ни на те, что создавались до удалённой (повреждённой), ни на те, что после неё.
Дифференциальные резервные копии – это тоже точки восстановления.
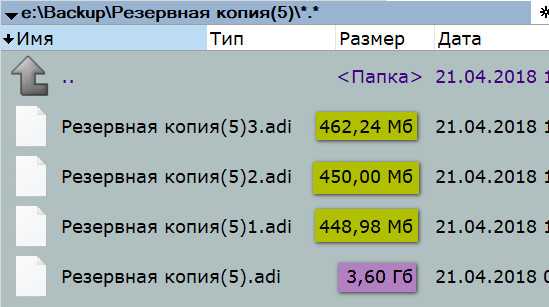
Необходимость дифференциальной копии каждый раз сравнивать себя с полной первичной копией, соответственно, влечёт за собой использование большего дискового пространства. На скриншоте ниже сиреневым маркером отмечен размер полной копии и жёлтым размеры дифференциальных бэкапов. Размер последних в районе 450 Мб свидетельствует о том, что между ними произошло немного изменений, тем не менее каждое такое изменение с момента создания полной копии зафиксировано в отдельном порядке. И в отдельном порядке поглощает место на диске.
Какой метод лучше выбрать
Какой из методов резервного копирования – полное, инкрементное или дифференциальное – выбрать для обычных домашних нужд? Полное – самое надёжное, но каждый раз создавать полную копию не всегда целесообразно. В стеснённых условиях дискового пространства ветвистой системы точек отката особо не настроишь. Инкрементное будет экономить место на диске, но если вирус повредит промежуточную копию или её, например, кто-то из близких случайно удалит, мы не сможем откатиться к свежим бэкапам. Оптимальный вариант – дифференциальное резервное копирование. Его можно как периодически выполнять вручную, так и настроить для автоматического запуска в планировщике программы-бэкапера.
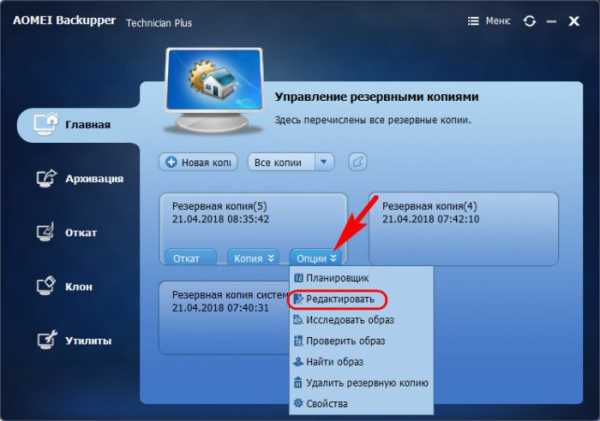
Но есть же ещё нюанс, друзья. Некоторые продвинутые программы-бэкаперы могут предложить не только тот или иной метод создания бэкапа, но и его применение в тех или иных условиях. Например, у AOMEI Backupper есть 5 схем резервного копирования. Схемы можно включить сразу при создании первичного бэкапа.
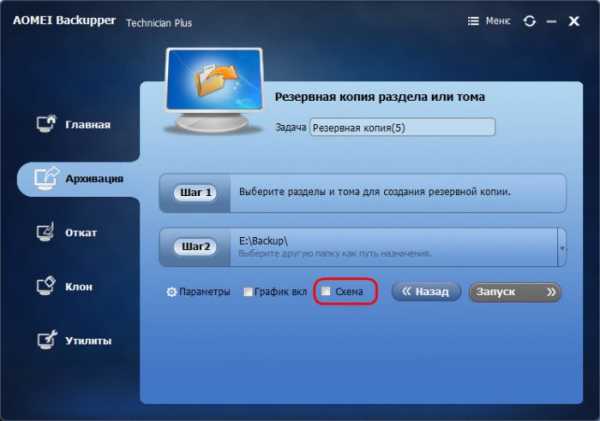
А можно подключить позднее.
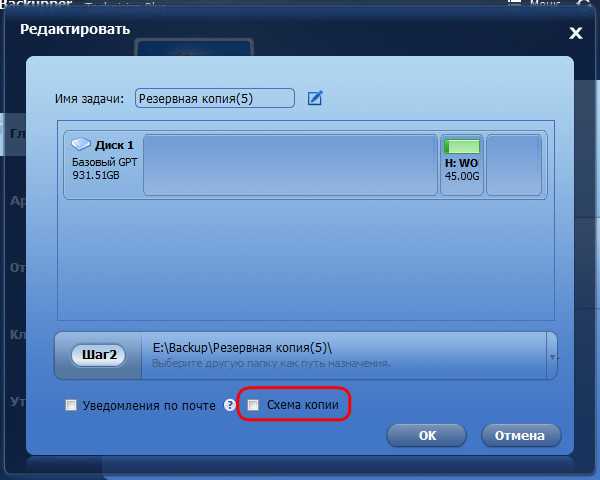
При настройке схем нужно поставить галочку «Включить управление дисками». И в выпадающем списке ниже увидим пятёрку гибких решений от AOMEI Backupper.
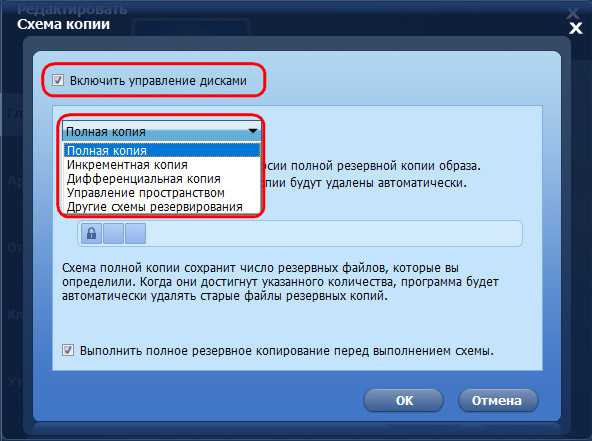
Что это за гибкие решения? Это:
• «Полная копия» - схема с применением метода полного резервного копирования, при котором по достижении назначенного количества копий старые будут автоматически удаляться;
• «Инкрементная копия» - схема с инкрементным бэкапом. По достижении назначенного числа копий цепь предыдущих копий – полной и зависимых инкрементных – удаляется, уступая место новым цепям;
• «Дифференциальная копия» - схема с созданием полных и дифференциальных копий. По достижении их граничного числа старые удаляются, и происходит всё это с учётом привязки дифференциальных копий к их полным;
• «Управление пространством» - схема с созданием полных и дифференциальных копий, заточенная под удаление старых копий при обнаружении недостатка места на диске;
• «Другие схемы резервирования» - схема с полным резервным копированием и возможностью выбора условий автоматического удаления старых копий.
В других программах-бэкаперах, соответственно, могут быть другие идеи от разработчиков. Здесь нужно уже разбираться с каждой такой программой в отдельности и подбирать условия создания бэкапа под свои нужды.
Метки к статье: Бэкап Acronis True Image AOMEI Backupper