Нейросети что это такое
Нейронные сети для начинающих. Часть 1 / Habr

Привет всем читателям Habrahabr, в этой статье я хочу поделиться с Вами моим опытом в изучении нейронных сетей и, как следствие, их реализации, с помощью языка программирования Java, на платформе Android. Мое знакомство с нейронными сетями произошло, когда вышло приложение Prisma. Оно обрабатывает любую фотографию, с помощью нейронных сетей, и воспроизводит ее с нуля, используя выбранный стиль. Заинтересовавшись этим, я бросился искать статьи и «туториалы», в первую очередь, на Хабре. И к моему великому удивлению, я не нашел ни одну статью, которая четко и поэтапно расписывала алгоритм работы нейронных сетей. Информация была разрознена и в ней отсутствовали ключевые моменты. Также, большинство авторов бросается показывать код на том или ином языке программирования, не прибегая к детальным объяснениям.
Поэтому сейчас, когда я достаточно хорошо освоил нейронные сети и нашел огромное количество информации с разных иностранных порталов, я хотел бы поделиться этим с людьми в серии публикаций, где я соберу всю информацию, которая потребуется вам, если вы только начинаете знакомство с нейронными сетями. В этой статье, я не буду делать сильный акцент на Java и буду объяснять все на примерах, чтобы вы сами смогли перенести это на любой, нужный вам язык программирования. В последующих статьях, я расскажу о своем приложении, написанном под андроид, которое предсказывает движение акций или валюты. Иными словами, всех желающих окунуться в мир нейронных сетей и жаждущих простого и доступного изложения информации или просто тех, кто что-то не понял и хочет подтянуть, добро пожаловать под кат.
Первым и самым важным моим открытием был плейлист американского программиста Джеффа Хитона, в котором он подробно и наглядно разбирает принципы работы нейронных сетей и их классификации. После просмотра этого плейлиста, я решил создать свою нейронную сеть, начав с самого простого примера. Вам наверняка известно, что когда ты только начинаешь учить новый язык, первой твоей программой будет Hello World. Это своего рода традиция. В мире машинного обучения тоже есть свой Hello world и это нейросеть решающая проблему исключающего или(XOR). Таблица исключающего или выглядит следующим образом:
| a | b | c |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Что такое нейронная сеть?
Нейронная сеть — это последовательность нейронов, соединенных между собой синапсами. Структура нейронной сети пришла в мир программирования прямиком из биологии. Благодаря такой структуре, машина обретает способность анализировать и даже запоминать различную информацию. Нейронные сети также способны не только анализировать входящую информацию, но и воспроизводить ее из своей памяти. Заинтересовавшимся обязательно к просмотру 2 видео из TED Talks: Видео 1, Видео 2). Другими словами, нейросеть это машинная интерпретация мозга человека, в котором находятся миллионы нейронов передающих информацию в виде электрических импульсов.
Какие бывают нейронные сети?
Пока что мы будем рассматривать примеры на самом базовом типе нейронных сетей — это сеть прямого распространения (далее СПР). Также в последующих статьях я введу больше понятий и расскажу вам о рекуррентных нейронных сетях. СПР как вытекает из названия это сеть с последовательным соединением нейронных слоев, в ней информация всегда идет только в одном направлении.
Для чего нужны нейронные сети?
Нейронные сети используются для решения сложных задач, которые требуют аналитических вычислений подобных тем, что делает человеческий мозг. Самыми распространенными применениями нейронных сетей является:
Классификация — распределение данных по параметрам. Например, на вход дается набор людей и нужно решить, кому из них давать кредит, а кому нет. Эту работу может сделать нейронная сеть, анализируя такую информацию как: возраст, платежеспособность, кредитная история и тд.
Предсказание — возможность предсказывать следующий шаг. Например, рост или падение акций, основываясь на ситуации на фондовом рынке.
Распознавание — в настоящее время, самое широкое применение нейронных сетей. Используется в Google, когда вы ищете фото или в камерах телефонов, когда оно определяет положение вашего лица и выделяет его и многое другое.
Теперь, чтобы понять, как же работают нейронные сети, давайте взглянем на ее составляющие и их параметры.
Что такое нейрон?
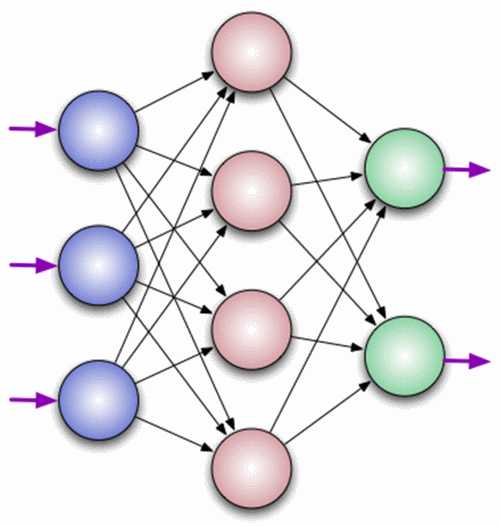
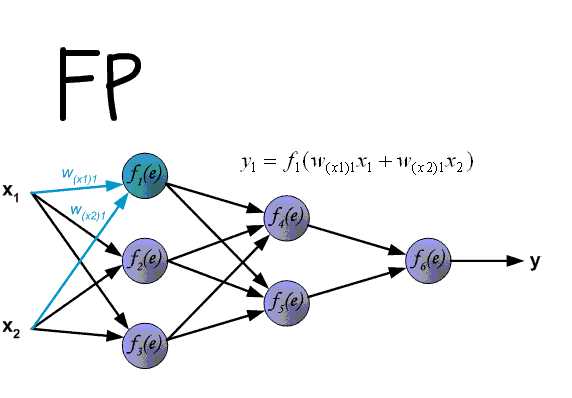
Нейрон — это вычислительная единица, которая получает информацию, производит над ней простые вычисления и передает ее дальше. Они делятся на три основных типа: входной (синий), скрытый (красный) и выходной (зеленый). Также есть нейрон смещения и контекстный нейрон о которых мы поговорим в следующей статье. В том случае, когда нейросеть состоит из большого количества нейронов, вводят термин слоя. Соответственно, есть входной слой, который получает информацию, n скрытых слоев (обычно их не больше 3), которые ее обрабатывают и выходной слой, который выводит результат. У каждого из нейронов есть 2 основных параметра: входные данные (input data) и выходные данные (output data). В случае входного нейрона: input=output. В остальных, в поле input попадает суммарная информация всех нейронов с предыдущего слоя, после чего, она нормализуется, с помощью функции активации (пока что просто представим ее f(x)) и попадает в поле output.
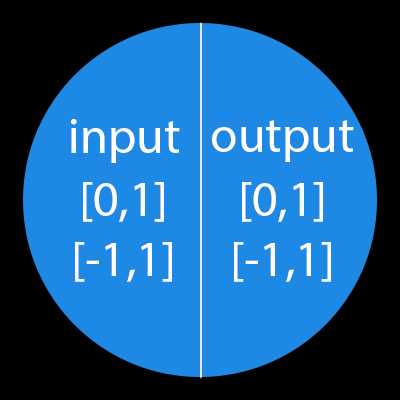
Важно помнить, что нейроны оперируют числами в диапазоне [0,1] или [-1,1]. А как же, вы спросите, тогда обрабатывать числа, которые выходят из данного диапазона? На данном этапе, самый простой ответ — это разделить 1 на это число. Этот процесс называется нормализацией, и он очень часто используется в нейронных сетях. Подробнее об этом чуть позже.
Что такое синапс?
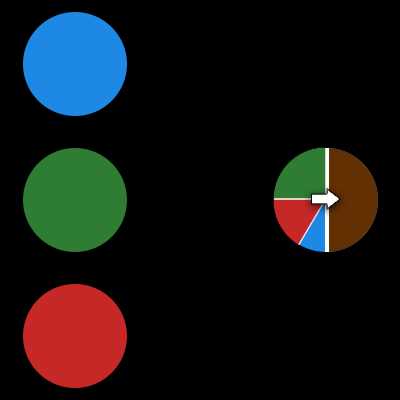
Синапс это связь между двумя нейронами. У синапсов есть 1 параметр — вес. Благодаря ему, входная информация изменяется, когда передается от одного нейрона к другому. Допустим, есть 3 нейрона, которые передают информацию следующему. Тогда у нас есть 3 веса, соответствующие каждому из этих нейронов. У того нейрона, у которого вес будет больше, та информация и будет доминирующей в следующем нейроне (пример — смешение цветов). На самом деле, совокупность весов нейронной сети или матрица весов — это своеобразный мозг всей системы. Именно благодаря этим весам, входная информация обрабатывается и превращается в результат.
Важно помнить, что во время инициализации нейронной сети, веса расставляются в случайном порядке.
Как работает нейронная сеть?
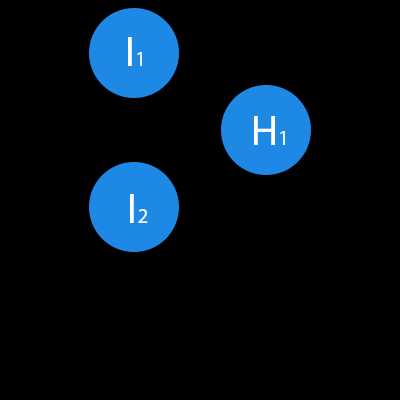
В данном примере изображена часть нейронной сети, где буквами I обозначены входные нейроны, буквой H — скрытый нейрон, а буквой w — веса. Из формулы видно, что входная информация — это сумма всех входных данных, умноженных на соответствующие им веса. Тогда дадим на вход 1 и 0. Пусть w1=0.4 и w2 = 0.7 Входные данные нейрона Н1 будут следующими: 1*0.4+0*0.7=0.4. Теперь когда у нас есть входные данные, мы можем получить выходные данные, подставив входное значение в функцию активации (подробнее о ней далее). Теперь, когда у нас есть выходные данные, мы передаем их дальше. И так, мы повторяем для всех слоев, пока не дойдем до выходного нейрона. Запустив такую сеть в первый раз мы увидим, что ответ далек от правильно, потому что сеть не натренирована. Чтобы улучшить результаты мы будем ее тренировать. Но прежде чем узнать как это делать, давайте введем несколько терминов и свойств нейронной сети.
Функция активации
Функция активации — это способ нормализации входных данных (мы уже говорили об этом ранее). То есть, если на входе у вас будет большое число, пропустив его через функцию активации, вы получите выход в нужном вам диапазоне. Функций активации достаточно много поэтому мы рассмотрим самые основные: Линейная, Сигмоид (Логистическая) и Гиперболический тангенс. Главные их отличия — это диапазон значений.
Линейная функция
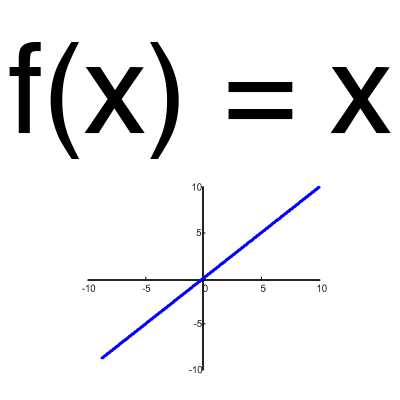
Эта функция почти никогда не используется, за исключением случаев, когда нужно протестировать нейронную сеть или передать значение без преобразований.
Сигмоид
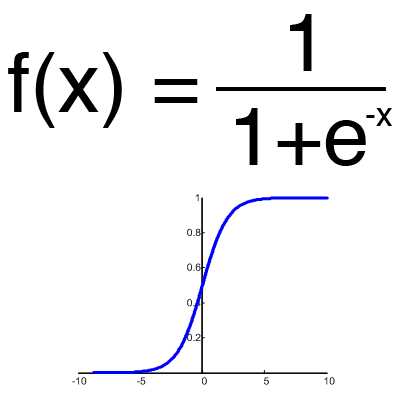
Это самая распространенная функция активации, ее диапазон значений [0,1]. Именно на ней показано большинство примеров в сети, также ее иногда называют логистической функцией. Соответственно, если в вашем случае присутствуют отрицательные значения (например, акции могут идти не только вверх, но и вниз), то вам понадобиться функция которая захватывает и отрицательные значения.
Гиперболический тангенс
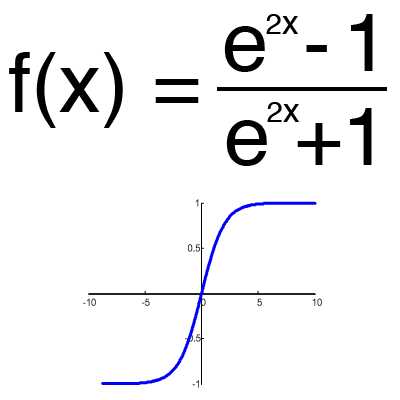
Имеет смысл использовать гиперболический тангенс, только тогда, когда ваши значения могут быть и отрицательными, и положительными, так как диапазон функции [-1,1]. Использовать эту функцию только с положительными значениями нецелесообразно так как это значительно ухудшит результаты вашей нейросети.
Тренировочный сет
Тренировочный сет — это последовательность данных, которыми оперирует нейронная сеть. В нашем случае исключающего или (xor) у нас всего 4 разных исхода то есть у нас будет 4 тренировочных сета: 0xor0=0, 0xor1=1, 1xor0=1,1xor1=0.
Итерация
Это своеобразный счетчик, который увеличивается каждый раз, когда нейронная сеть проходит один тренировочный сет. Другими словами, это общее количество тренировочных сетов пройденных нейронной сетью.
Эпоха
При инициализации нейронной сети эта величина устанавливается в 0 и имеет потолок, задаваемый вручную. Чем больше эпоха, тем лучше натренирована сеть и соответственно, ее результат. Эпоха увеличивается каждый раз, когда мы проходим весь набор тренировочных сетов, в нашем случае, 4 сетов или 4 итераций.
Важно не путать итерацию с эпохой и понимать последовательность их инкремента. Сначала n
раз увеличивается итерация, а потом уже эпоха и никак не наоборот. Другими словами, нельзя сначала тренировать нейросеть только на одном сете, потом на другом и тд. Нужно тренировать каждый сет один раз за эпоху. Так, вы сможете избежать ошибок в вычислениях.
Ошибка
Ошибка — это процентная величина, отражающая расхождение между ожидаемым и полученным ответами. Ошибка формируется каждую эпоху и должна идти на спад. Если этого не происходит, значит, вы что-то делаете не так. Ошибку можно вычислить разными путями, но мы рассмотрим лишь три основных способа: Mean Squared Error (далее MSE), Root MSE и Arctan. Здесь нет какого-либо ограничения на использование, как в функции активации, и вы вольны выбрать любой метод, который будет приносить вам наилучший результат. Стоит лишь учитывать, что каждый метод считает ошибки по разному. У Arctan, ошибка, почти всегда, будет больше, так как он работает по принципу: чем больше разница, тем больше ошибка. У Root MSE будет наименьшая ошибка, поэтому, чаще всего, используют MSE, которая сохраняет баланс в вычислении ошибки.
MSE
Root MSE
Arctan
Принцип подсчета ошибки во всех случаях одинаков. За каждый сет, мы считаем ошибку, отняв от идеального ответа, полученный. Далее, либо возводим в квадрат, либо вычисляем квадратный тангенс из этой разности, после чего полученное число делим на количество сетов.
Задача
Теперь, чтобы проверить себя, подсчитайте результат, данной нейронной сети, используя сигмоид, и ее ошибку, используя MSE.
Данные: I1=1, I2=0, w1=0.45, w2=0.78 ,w3=-0.12 ,w4=0.13 ,w5=1.5 ,w6=-2.3.
Решениеh2input = 1*0.45+0*-0.12=0.45
h2output = sigmoid(0.45)=0.61
h3input = 1*0.78+0*0.13=0.78
h3output = sigmoid(0.78)=0.69
O1input = 0.61*1.5+0.69*-2.3=-0.672
O1output = sigmoid(-0.672)=0.33
O1ideal = 1 (0xor1=1)
Error = ((1-0.33)^2)/1=0.45
Результат — 0.33, ошибка — 45%.
Большое спасибо за внимание! Надеюсь, что данная статья смогла помочь вам в изучении нейронных сетей. В следующей статье, я расскажу о нейронах смещения и о том, как тренировать нейронную сеть, используя метод обратного распространения и градиентного спуска.
Использованные ресурсы:
— Раз
— Два
— Три
Искусственные нейронные сети простыми словами / Habr
Когда, за бутылкой пива, я заводил разговор о нейронных сетях — люди обычно начинали боязливо на меня смотреть, грустнели, иногда у них начинал дёргаться глаз, а в крайних случаях они залезали под стол. Но, на самом деле, эти сети просты и интуитивны. Да-да, именно так! И, позвольте, я вам это докажу!
Допустим, я знаю о девушке две вещи — симпатична она мне или нет, а также, есть ли о чём мне с ней поговорить. Если есть, то будем считать это единицей, если нет, то — нулём. Аналогичный принцип возьмем и для внешности. Вопрос: “В какую девушку я влюблюсь и почему?”
Можно подумать просто и бескомпромиссно: “Если симпатична и есть о чём поговорить, то влюблюсь. Если ни то и ни другое, то — увольте.”
Но что если дама мне симпатична, но с ней не о чем разговаривать? Или наоборот?
Понятно, что для каждого из нас что-то одно будет важнее. Точнее, у каждого параметра есть его уровень важности, или вернее сказать — вес. Если помножить параметр на его вес, то получится соответственно “влияние внешности” и “влияние болтливости разговора”.
И вот теперь я с чистой совестью могу ответить на свой вопрос:
“Если влияние харизмы и влияние болтливости в сумме больше значения “влюбчивость” то влюблюсь…”
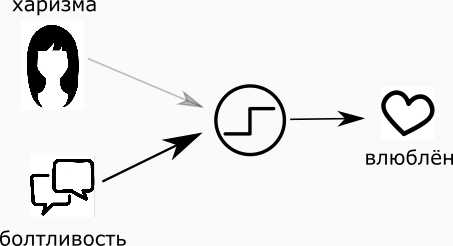
То есть, если я поставлю большой вес “болтологичности” дамы и маленький вес внешности, то в спорной ситуации я влюблюсь в особу, с которой приятно поболтать. И наоборот.
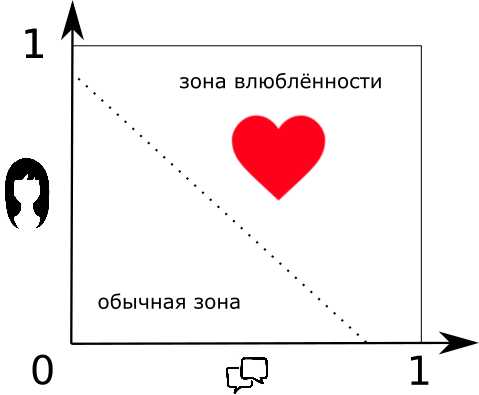
Собственно, это правило и есть нейрон.
Искусственный нейрон — это такая функция, которая преобразует несколько входных фактов в один выходной. Настройкой весов этих фактов, а также порога возбуждения — мы настраиваем адекватность нейрона. В принципе, для многих наука жизни заканчивается на этом уровне, но ведь эта история не про нас, верно?
Сделаем ещё несколько выводов:
- Если оба веса будут малыми, то мне будет сложно влюбиться в кого бы-то ни было.
- Если же оба веса будут чересчур большими, то я влюблюсь хоть в столб.
- Заставить меня влюбиться в столб можно также, понизив порог влюбчивости, но прошу — не делайте со мной этого! Лучше давайте пока забудем про него, ок?
Кстати о пороге
Смешно, но параметр “влюбчивости” называется “порогом возбуждения”. Но, дабы эта статья не получила рейтинг “18+”, давайте договоримся говорить просто “порог”, ок?
Нейронная сеть
Не бывает однозначно симпатичных и однозначно общительных дам. Да и влюблённость влюблённости рознь, кто бы что ни говорил. Потому давайте вместо брутальных и бескомпромиссных “0” и “1”, будем использовать проценты. Тогда можно сказать — “я сильно влюблён (80%), или “эта дама не особо разговорчива (20%)”.
Наш примитивный “нейрон-максималист” из первой части уже нам не подходит. Ему на смену приходит “нейрон-мудрец”, результатом работы которого будет число от 0 до 1, в зависимости от входных данных.
“Нейрон-мудрец” может нам сказать: “эта дама достаточно красива, но я не знаю о чём с ней говорить, поэтому я не очень-то ей и восхищён”
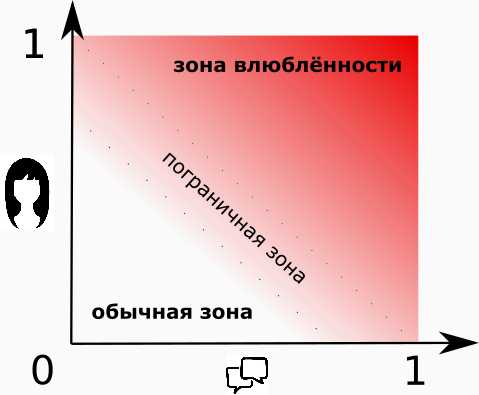
Немного терминологии
К слову говоря, входные факты нейрона называются синапсами, а выходное суждение — аксоном. Связи с положительным весом называются возбуждающими, а с отрицательным — тормозящими. Если же вес равен нулю, то считается, что связи нет (мёртвая связь).
Поехали дальше. Сделаем по этим двум фактам другую оценку: насколько хорошо с такой девушкой работать (сотрудничать)? Будем действовать абсолютно аналогичным образом — добавим мудрый нейрон и настроим веса комфортным для нас образом.
Но, судить девушку по двум характеристикам — это очень грубо. Давайте судить её по трём! Добавим ещё один факт – деньги. Который будет варьироваться от нуля (абсолютно бедная) до единицы (дочь Рокфеллера). Посмотрим, как с приходом денег изменятся наши суждения….
Для себя я решил, что, в плане очарования, деньги не очень важны, но шикарный вид всё же может на меня повлиять, потому вес денег я сделаю маленьким, но положительным.
В работе мне абсолютно всё равно, сколько денег у девушки, поэтому вес сделаю равным нулю.
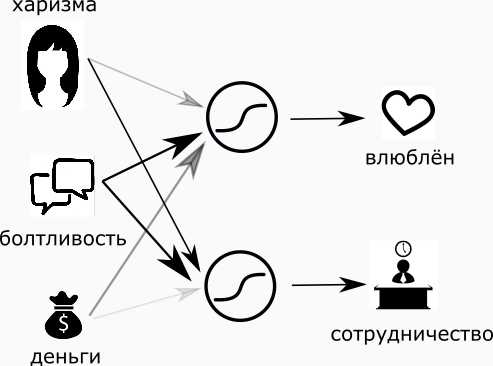
Оценивать девушку только для работы и влюблённости — очень глупо. Давайте добавим, насколько с ней будет приятно путешествовать:
- Харизма в этой задаче нейтральна (нулевой или малый вес).
- Разговорчивость нам поможет (положительный вес).
- Когда в настоящих путешествиях заканчиваются деньги, начинается самый драйв, поэтому вес денег я сделаю слегка отрицательным.
Соединим все эти три схемы в одну и обнаружим, что мы перешли на более глубокий уровень суждений, а именно: от харизмы, денег и разговорчивости — к восхищению, сотрудничеству и комфортности совместного путешествия. И заметьте — это тоже сигналы от нуля до единицы. А значит, теперь я могу добавить финальный “нейрон-максималист”, и пускай он однозначно ответит на вопрос — “жениться или нет”?
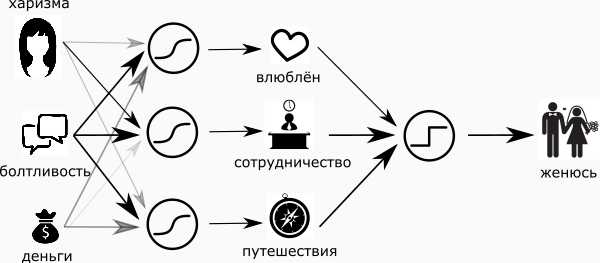
Ладно, конечно же, не всё так просто (в плане женщин). Привнесём немного драматизма и реальности в наш простой и радужный мир. Во-первых, сделаем нейрон "женюсь — не женюсь" — мудрым. Сомнения же присущи всем, так или иначе. И ещё — добавим нейрон "хочу от неё детей" и, чтобы совсем по правде, нейрон “держись от неё подальше".
Я ничего не понимаю в женщинах, и поэтому моя примитивная сеть теперь выглядит как картинка в начале статьи.
Входные суждения называются “входной слой”, итоговые — “выходной слой”, а тот, что скрывается посередине, называется "скрытым". Скрытый слой — это мои суждения, полуфабрикаты, мысли, о которых никто не знает. Скрытых слоёв может быть несколько, а может быть и ни одного.
Долой максимализм.
Помните, я говорил об отрицательном влияние денег на моё желание путешествовать с человеком? Так вот — я слукавил. Для путешествий лучше всего подходит персона, у которой денег не мало, и не много. Мне так интереснее и не буду объяснять почему.
Но тут я сталкиваюсь с проблемой:
Если я ставлю вес денег отрицательным, то чем меньше денег — тем лучше для путешествий.
Если положительным, то чем богаче — тем лучше,
Если ноль — тогда деньги “побоку”.
Не получается мне вот так, одним весом, заставить нейрон распознать ситуацию “ни много -ни мало”!
Чтобы это обойти, я сделаю два нейрона — “денег много” и “денег мало”, и подам им на вход денежный поток от нашей дамы.
Теперь у меня есть два суждения: “много” и “мало”. Если оба вывода незначительны, то буквально получится “ни много — ни мало”. То есть, добавим на выход ещё один нейрон, с отрицательными весами:
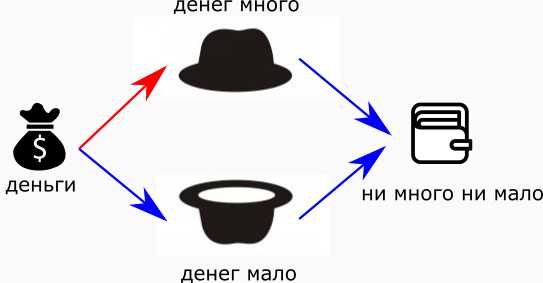
“Нимногонимало”. Красные стрелки — положительные связи, синие — отрицательные
Вообще, это значит, что нейроны подобны элементам конструктора. Подобно тому, как процессор делают из транзисторов, мы можем собрать из нейронов мозг. Например, суждение “Или богата, или умна” можно сделать так:
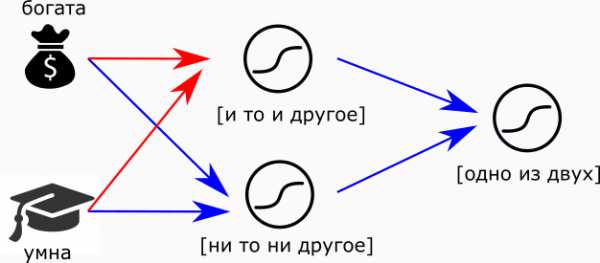
Или-или. Красные стрелки — положительные связи, синие – отрицательные
Или так:
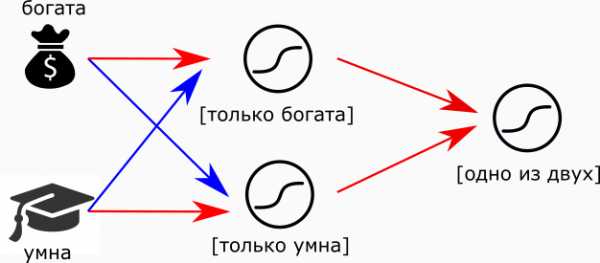
можно заменить “мудрые” нейроны на “максималистов” и тогда получим логический оператор XOR. Главное — не забыть настроить пороги возбуждения.
В отличие от транзисторов и бескомпромиссной логики типичного программиста “если — то”, нейронная сеть умеет принимать взвешенные решения. Их результаты будут плавно меняться, при плавном изменение входных параметров. Вот она мудрость!
Обращу ваше внимание, что добавление слоя из двух нейронов, позволило нейрону “ни много — ни мало” делать более сложное и взвешенное суждение, перейти на новый уровень логики. От “много” или “мало” — к компромиссному решению, к более глубокому, с философской точки зрения, суждению. А что если добавить скрытых слоёв ещё? Мы способны охватить разумом ту простую сеть, но как насчёт сети, у которой есть 7 слоёв? Способны ли мы осознать глубину её суждений? А если в каждом из них, включая входной, около тысячи нейронов? Как вы думаете, на что она способна?
Представьте, что я и дальше усложнял свой пример с женитьбой и влюблённостью, и пришёл к такой сети. Где-то там в ней скрыты все наши девять нейрончиков, и это уже больше похоже на правду. При всём желании, понять все зависимости и глубину суждений такой сети — попросту невозможно. Для меня переход от сети 3х3 к 7х1000 — сравним с осознанием масштабов, если не вселенной, то галактики — относительно моего роста. Попросту говоря, у меня это не получится. Решение такой сети, загоревшийся выход одного из её нейронов — будет необъясним логикой. Это то, что в быту мы можем назвать “интуицией” (по крайней мере – “одно из..”). Непонятное желание системы или её подсказка.
Но, в отличие от нашего синтетического примера 3х3, где каждый нейрон скрытого слоя достаточно чётко формализован, в настоящей сети это не обязательно так. В хорошо настроенной сети, чей размер не избыточен для решения поставленной задачи — каждый нейрон будет детектировать какой-то признак, но это абсолютно не значит, что в нашем языке найдётся слово или предложение, которое сможет его описать. Если проецировать на человека, то это — какая-то его характеристика, которую ты чувствуешь, но словами объяснить не можешь.
Обучение.
Несколькими строчками ранее я обмолвился о хорошо настроенной сети, чем вероятно спровоцировал немой вопрос: “А как мы можем настроить сеть, состоящую из нескольких тысяч нейронов? Сколько “человеколет” и погубленных жизней нужно на это?.. Боюсь предположить ответ на последний вопрос. Куда лучше автоматизировать такой процесс настройки — заставить сеть саму настраивать себя. Такой процесс автоматизации называется обучением. И чтобы дать поверхностное о нём представление, я вернусь к изначальной метафоре об “очень важном вопросе”:
Мы появляемся в этом мире с чистым, невинным мозгом и нейронной сетью, абсолютно не настроенной относительно дам. Её необходимо как-то грамотно настроить, дабы счастье и радость пришли в наш дом. Для этого нам нужен некоторый опыт, и тут есть несколько путей по его добыче:
1) Обучение с учителем (для романтиков). Насмотреться на голливудские мелодрамы и начитаться слезливых романов. Или же насмотреться на своих родителей и/или друзей. После этого, в зависимости от выборки, отправиться проверять полученные знания. После неудачной попытки — повторить всё заново, начиная с романов.
2) Обучение без учителя (для отчаянных экспериментаторов). Попробовать методом “тыка” жениться на десятке-другом женщин. После каждой женитьбы, в недоумение чесать репу. Повторять, пока не поймёшь, что надоело, и ты “уже знаешь, как это бывает”.
3) Обучение без учителя, вариант 2 (путь отчаянных оптимистов). Забить на всё, что-то делать по жизни, и однажды обнаружить себя женатым. После этого, перенастроить свою сеть в соответствие с текущей реальностью, дабы всё устраивало.
Далее, по логике я должен расписать всё это подробно, но без математики это будет слишком философично. Потому считаю, что мне стоит на этом остановиться. Быть может в другой раз?
Всё вышесказанное справедливо для искусственной нейронной сети типа “персептрон”. Остальные сети похожи на нее по основным принципам, но имеют свою нюансы.
Хороших вам весов и отличных обучающих выборок! Ну а если это уже и не нужно, то расскажите об этом кому-нибудь ещё.
ENG version
Нейронные сети: практическое применение / Habr

Наталия Ефремова погружает публику в специфику практического использования нейросетей. Это — расшифровка доклада Highload++.
Добрый день, меня зовут Наталия Ефремова, и я research scientist в компании NtechLab. Сегодня я буду рассказывать про виды нейронных сетей и их применение.
Сначала скажу пару слов о нашей компании. Компания новая, может быть многие из вас еще не знают, чем мы занимаемся. В прошлом году мы выиграли состязание MegaFace. Это международное состязание по распознаванию лиц. В этом же году была открыта наша компания, то есть мы на рынке уже около года, даже чуть больше. Соответственно, мы одна из лидирующих компаний в распознавании лиц и обработке биометрических изображений.
Первая часть моего доклада будет направлена тем, кто незнаком с нейронными сетями. Я занимаюсь непосредственно deep learning. В этой области я работаю более 10 лет. Хотя она появилась чуть меньше, чем десятилетие назад, раньше были некие зачатки нейронных сетей, которые были похожи на систему deep learning.
В последние 10 лет deep learning и компьютерное зрение развивались неимоверными темпами. Все, что сделано значимого в этой области, произошло в последние лет 6.
Я расскажу о практических аспектах: где, когда, что применять в плане deep learning для обработки изображений и видео, для распознавания образов и лиц, поскольку я работаю в компании, которая этим занимается. Немножко расскажу про распознавание эмоций, какие подходы используются в играх и робототехнике. Также я расскажу про нестандартное применение deep learning, то, что только выходит из научных институтов и пока что еще мало применяется на практике, как это может применяться, и почему это сложно применить.
Доклад будет состоять из двух частей. Так как большинство знакомы с нейронными сетями, сначала я быстро расскажу, как работают нейронные сети, что такое биологические нейронные сети, почему нам важно знать, как это работает, что такое искусственные нейронные сети, и какие архитектуры в каких областях применяются.
Сразу извиняюсь, я буду немного перескакивать на английскую терминологию, потому что большую часть того, как называется это на русском языке, я даже не знаю. Возможно вы тоже.
Итак, первая часть доклада будет посвящена сверточным нейронным сетям. Я расскажу, как работают convolutional neural network (CNN), распознавание изображений на примере из распознавания лиц. Немного расскажу про рекуррентные нейронные сети recurrent neural network (RNN) и обучение с подкреплением на примере систем deep learning.
В качестве нестандартного применения нейронных сетей я расскажу о том, как CNN работает в медицине для распознавания воксельных изображений, как используются нейронные сети для распознавания бедности в Африке.
Прототипом для создания нейронных сетей послужили, как это ни странно, биологические нейронные сети. Возможно, многие из вас знают, как программировать нейронную сеть, но откуда она взялась, я думаю, некоторые не знают. Две трети всей сенсорной информации, которая к нам попадает, приходит с зрительных органов восприятия. Более одной трети поверхности нашего мозга заняты двумя самыми главными зрительными зонами — дорсальный зрительный путь и вентральный зрительный путь.
Дорсальный зрительный путь начинается в первичной зрительной зоне, в нашем темечке и продолжается наверх, в то время как вентральный путь начинается на нашем затылке и заканчивается примерно за ушами. Все важное распознавание образов, которое у нас происходит, все смыслонесущее, то что мы осознаём, проходит именно там же, за ушами.
Почему это важно? Потому что часто нужно для понимания нейронных сетей. Во-первых, все об этом рассказывают, и я уже привыкла что так происходит, а во-вторых, дело в том, что все области, которые используются в нейронных сетях для распознавания образов, пришли к нам именно из вентрального зрительного пути, где каждая маленькая зона отвечает за свою строго определенную функцию.
Изображение попадает к нам из сетчатки глаза, проходит череду зрительных зон и заканчивается в височной зоне.
В далекие 60-е годы прошлого века, когда только начиналось изучение зрительных зон мозга, первые эксперименты проводились на животных, потому что не было fMRI. Исследовали мозг с помощью электродов, вживлённых в различные зрительные зоны.
Первая зрительная зона была исследована Дэвидом Хьюбелем и Торстеном Визелем в 1962 году. Они проводили эксперименты на кошках. Кошкам показывались различные движущиеся объекты. На что реагировали клетки мозга, то и было тем стимулом, которое распознавало животное. Даже сейчас многие эксперименты проводятся этими драконовскими способами. Но тем не менее это самый эффективный способ узнать, что делает каждая мельчайшая клеточка в нашем мозгу.
Таким же способом были открыты еще многие важные свойства зрительных зон, которые мы используем в deep learning сейчас. Одно из важнейших свойств — это увеличение рецептивных полей наших клеток по мере продвижения от первичных зрительных зон к височным долям, то есть более поздним зрительным зонам. Рецептивное поле — это та часть изображения, которую обрабатывает каждая клеточка нашего мозга. У каждой клетки своё рецептивное поле. Это же свойство сохраняется и в нейронных сетях, как вы, наверное, все знаете.
Также с возрастанием рецептивных полей увеличиваются сложные стимулы, которые обычно распознают нейронные сети.
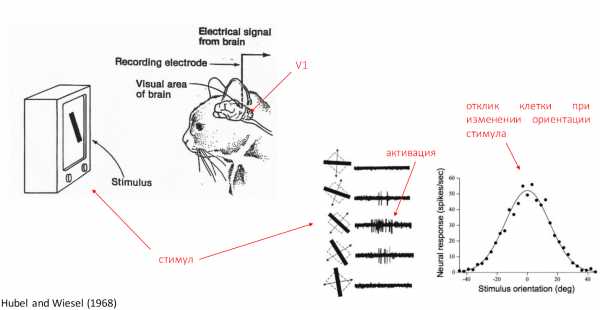
Здесь вы видите примеры сложности стимулов, различных двухмерных форм, которые распознаются в зонах V2, V4 и различных частях височных полей у макак. Также проводятся некоторое количество экспериментов на МРТ.
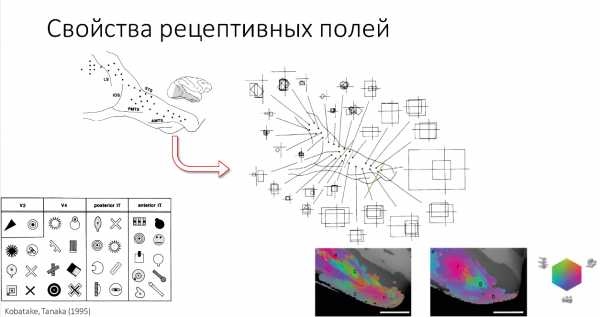
Здесь вы видите, как проводятся такие эксперименты. Это 1 нанометровая часть зон IT cortex'a мартышки при распознавании различных объектов. Подсвечено то, где распознается.
Просуммируем. Важное свойство, которое мы хотим перенять у зрительных зон — это то, что возрастают размеры рецептивных полей, и увеличивается сложность объектов, которые мы распознаем.
До того, как мы научились это применять к компьютерному зрению — в общем, как такового его не было. Во всяком случае, оно работало не так хорошо, как работает сейчас.
Все эти свойства мы переносим в нейронную сеть, и вот оно заработало, если не включать небольшое отступление к датасетам, о котором расскажу попозже.
Но сначала немного о простейшем перцептроне. Он также образован по образу и подобию нашего мозга. Простейший элемент напоминающий клетку мозга — нейрон. Имеет входные элементы, которые по умолчанию располагаются слева направо, изредка снизу вверх. Слева это входные части нейрона, справа выходные части нейрона.
Простейший перцептрон способен выполнять только самые простые операции. Для того, чтобы выполнять более сложные вычисления, нам нужна структура с большим количеством скрытых слоёв.
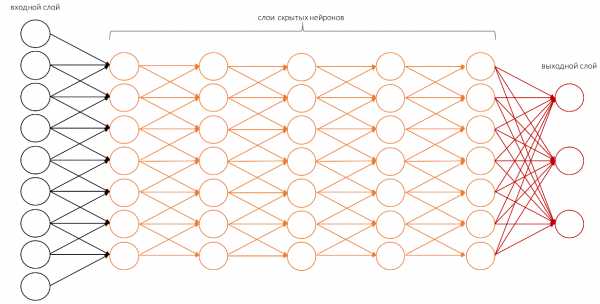
В случае компьютерного зрения нам нужно еще больше скрытых слоёв. И только тогда система будет осмысленно распознавать то, что она видит.
Итак, что происходит при распознавании изображения, я расскажу на примере лиц.
Для нас посмотреть на эту картинку и сказать, что на ней изображено именно лицо статуи, достаточно просто. Однако до 2010 года для компьютерного зрения это было невероятно сложной задачей. Те, кто занимался этим вопросом до этого времени, наверное, знают насколько тяжело было описать объект, который мы хотим найти на картинке без слов.
Нам нужно это было сделать каким-то геометрическим способом, описать объект, описать взаимосвязи объекта, как могут эти части относиться к друг другу, потом найти это изображение на объекте, сравнить их и получить, что мы распознали плохо. Обычно это было чуть лучше, чем подбрасывание монетки. Чуть лучше, чем chance level.
Сейчас это происходит не так. Мы разбиваем наше изображение либо на пиксели, либо на некие патчи: 2х2, 3х3, 5х5, 11х11 пикселей — как удобно создателям системы, в которой они служат входным слоем в нейронную сеть.
Сигналы с этих входных слоёв передаются от слоя к слою с помощью синапсов, каждый из слоёв имеет свои определенные коэффициенты. Итак, мы передаём от слоя к слою, от слоя к слою, пока мы не получим, что мы распознали лицо.
Условно все эти части можно разделить на три класса, мы их обозначим X, W и Y, где Х — это наше входное изображение, Y — это набор лейблов, и нам нужно получить наши веса. Как мы вычислим W?
При наличии нашего Х и Y это, кажется, просто. Однако то, что обозначено звездочкой, очень сложная нелинейная операция, которая, к сожалению, не имеет обратной. Даже имея 2 заданных компоненты уравнения, очень сложно ее вычислить. Поэтому нам нужно постепенно, методом проб и ошибок, подбором веса W сделать так, чтобы ошибка максимально уменьшилась, желательно, чтобы стала равной нулю.
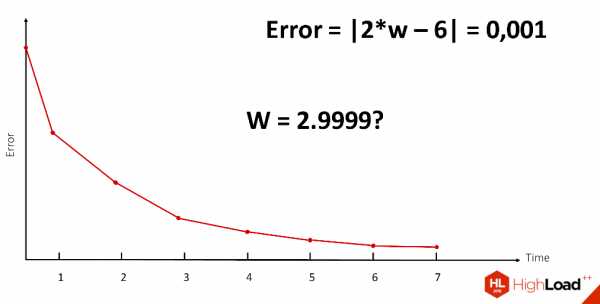
Этот процесс происходит итеративно, мы постоянно уменьшаем, пока не находим то значение веса W, которое нас достаточно устроит.
К слову, ни одна нейронная сеть, с которой я работала, не достигала ошибки, равной нулю, но работала при этом достаточно хорошо.
Перед вами первая сеть, которая победила на международном соревновании ImageNet в 2012 году. Это так называемый AlexNet. Это сеть, которая впервые заявила о себе, о том, что существует convolutional neural networks и с тех самых пор на всех международных состязаниях уже convolutional neural nets не сдавали своих позиций никогда.
Несмотря на то, что эта сеть достаточно мелкая (в ней всего 7 скрытых слоёв), она содержит 650 тысяч нейронов с 60 миллионами параметров. Для того, чтобы итеративно научиться находить нужные веса, нам нужно очень много примеров.
Нейронная сеть учится на примере картинки и лейбла. Как нас в детстве учат «это кошка, а это собака», так же нейронные сети обучаются на большом количестве картинок. Но дело в том, что до 2010 не существовало достаточно большого data set’a, который способен был бы научить такое количество параметров распознавать изображения.
Самые большие базы данных, которые существовали до этого времени: PASCAL VOC, в который было всего 20 категорий объектов, и Caltech 101, который был разработан в California Institute of Technology. В последнем была 101 категория, и это было много. Тем же, кто не сумел найти свои объекты ни в одной из этих баз данных, приходилось стоить свои базы данных, что, я скажу, страшно мучительно.
Однако, в 2010 году появилась база ImageNet, в которой было 15 миллионов изображений, разделённые на 22 тысячи категорий. Это решило нашу проблему обучения нейронных сетей. Сейчас все желающие, у кого есть какой-либо академический адрес, могут спокойно зайти на сайт базы, запросить доступ и получить эту базу для тренировки своих нейронных сетей. Они отвечают достаточно быстро, по-моему, на следующий день.
По сравнению с предыдущими data set’ами, это очень большая база данных.

На примере видно, насколько было незначительно все то, что было до неё. Одновременно с базой ImageNet появилось соревнование ImageNet, международный challenge, в котором все команды, желающие посоревноваться, могут принять участие.
В этом году победила сеть, созданная в Китае, в ней было 269 слоёв. Не знаю, сколько параметров, подозреваю, тоже много.
Условно ее можно разделить на 2 части: те, которые учатся, и те, которые не учатся.
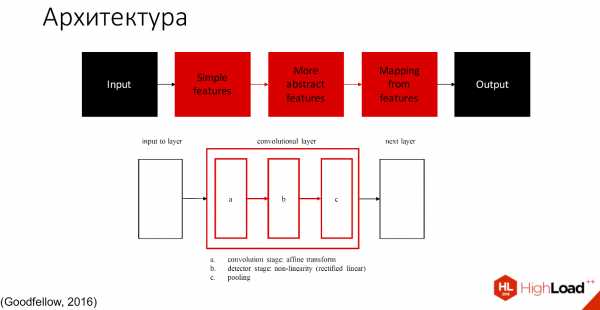
Чёрным обозначены те части, которые не учатся, все остальные слои способны обучаться. Существует множество определений того, что находится внутри каждого сверточного слоя. Одно из принятых обозначений — один слой с тремя компонентами разделяют на convolution stage, detector stage и pooling stage.
Не буду вдаваться в детали, еще будет много докладов, в которых подробно рассмотрено, как это работает. Расскажу на примере.
Поскольку организаторы просили меня не упоминать много формул, я их выкинула совсем.
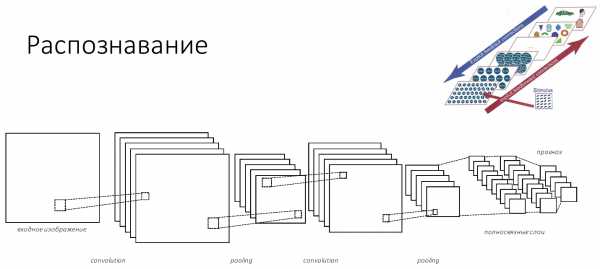
Итак, входное изображение попадает в сеть слоёв, которые можно назвать фильтрами разного размера и разной сложности элементов, которые они распознают. Эти фильтры составляют некий свой индекс или набор признаков, который потом попадает в классификатор. Обычно это либо SVM, либо MLP — многослойный перцептрон, кому что удобно.
По образу и подобию с биологической нейронной сетью объекты распознаются разной сложности. По мере увеличения количества слоёв это все потеряло связь с cortex’ом, поскольку там ограничено количество зон в нейронной сети. 269 или много-много зон абстракции, поэтому сохраняется только увеличение сложности, количества элементов и рецептивных полей.
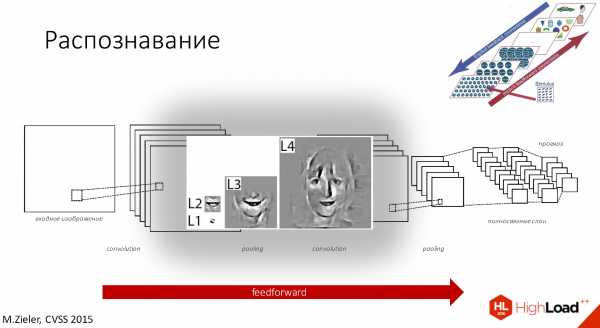
Если рассмотреть на примере распознавания лиц, то у нас рецептивное поле первого слоя будет маленьким, потом чуть побольше, побольше, и так до тех пор, пока наконец мы не сможем распознавать уже лицо целиком.
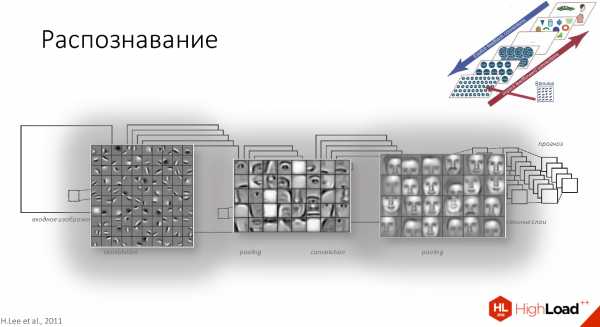
С точки зрения того, что находится у нас внутри фильтров, сначала будут наклонные палочки плюс немного цвета, затем части лиц, а потом уже целиком лица будут распознаваться каждой клеточкой слоя.
Есть люди, которые утверждают, что человек всегда распознаёт лучше, чем сеть. Так ли это?
В 2014 году ученые решили проверить, насколько мы хорошо распознаем в сравнении с нейронными сетями. Они взяли 2 самые лучшие на данный момент сети — это AlexNet и сеть Мэттью Зиллера и Фергюса, и сравнили с откликом разных зон мозга макаки, которая тоже была научена распознавать какие-то объекты. Объекты были из животного мира, чтобы обезьяна не запуталась, и были проведены эксперименты, кто же распознаёт лучше.
Так как получить отклик от мартышки внятно невозможно, ей вживили электроды и мерили непосредственно отклик каждого нейрона.
Оказалось, что в нормальных условиях клетки мозга реагировали так же хорошо, как и state of the art model на тот момент, то есть сеть Мэттью Зиллера.
Однако при увеличении скорости показа объектов, увеличении количества шумов и объектов на изображении скорость распознавания и его качество нашего мозга и мозга приматов сильно падают. Даже самая простая сверточная нейронная сеть распознаёт объекты лучше. То есть официально нейронные сети работают лучше, чем наш мозг.
Их на самом деле не так много, они относятся к трём классам. Среди них — такие задачи, как идентификация объекта, семантическая сегментация, распознавание лиц, распознавание частей тела человека, семантическое определение границ, выделение объектов внимания на изображении и выделение нормалей к поверхности. Их условно можно разделить на 3 уровня: от самых низкоуровневых задач до самых высокоуровневых задач.
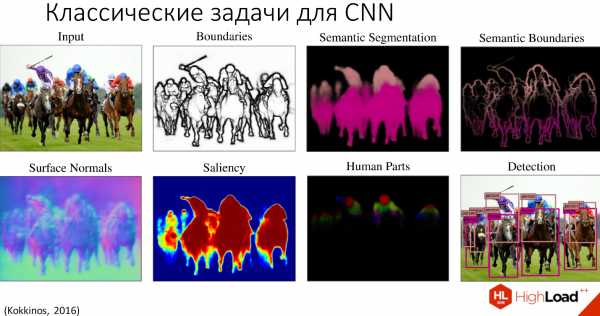
На примере этого изображения рассмотрим, что делает каждая из задач.
- Определение границ — это самая низкоуровневая задача, для которой уже классически применяются сверточные нейронные сети.
- Определение вектора к нормали позволяет нам реконструировать трёхмерное изображение из двухмерного.
- Saliency, определение объектов внимания — это то, на что обратил бы внимание человек при рассмотрении этой картинки.
- Семантическая сегментация позволяет разделить объекты на классы по их структуре, ничего не зная об этих объектах, то есть еще до их распознавания.
- Семантическое выделение границ — это выделение границ, разбитых на классы.
- Выделение частей тела человека.
- И самая высокоуровневая задача — распознавание самих объектов, которое мы сейчас рассмотрим на примере распознавания лиц.
Первое, что мы делаем — пробегаем face detector'ом по изображению для того, чтобы найти лицо. Далее мы нормализуем, центрируем лицо и запускаем его на обработку в нейронную сеть. После чего получаем набор или вектор признаков однозначно описывающий фичи этого лица.
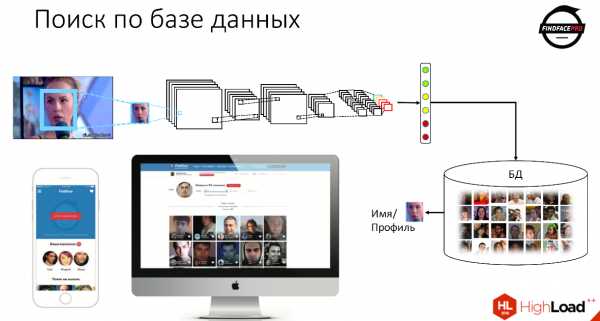
Затем мы можем этот вектор признаков сравнить со всеми векторами признаков, которые хранятся у нас в базе данных, и получить отсылку на конкретного человека, на его имя, на его профиль — всё, что у нас может храниться в базе данных.
Именно таким образом работает наш продукт FindFace — это бесплатный сервис, который помогает искать профили людей в базе «ВКонтакте».
Кроме того, у нас есть API для компаний, которые хотят попробовать наши продукты. Мы предоставляем сервис по детектированию лиц, по верификации и по идентификации пользователей.
Сейчас у нас разработаны 2 сценария. Первый — это идентификация, поиск лица по базе данных. Второе — это верификация, это сравнение двух изображений с некой вероятностью, что это один и тот же человек. Кроме того, у нас сейчас в разработке распознавание эмоций, распознавание изображений на видео и liveness detection — это понимание, живой ли человек перед камерой или фотография.
Немного статистики. При идентификации, при поиске по 10 тысячам фото у нас точность около 95% в зависимости от качества базы, 99% точность верификации. И помимо этого данный алгоритм очень устойчив к изменениям — нам необязательно смотреть в камеру, у нас могут быть некие загораживающие предметы: очки, солнечные очки, борода, медицинская маска. В некоторых случаях мы можем победить даже такие невероятные сложности для компьютерного зрения, как и очки, и маска.
Очень быстрый поиск, затрачивается 0,5 секунд на обработку 1 миллиарда фотографий. Нами разработан уникальный индекс быстрого поиска. Также мы можем работать с изображениями низкого качества, полученных с CCTV-камер. Мы можем обрабатывать это все в режиме реального времени. Можно загружать фото через веб-интерфейс, через Android, iOS и производить поиск по 100 миллионам пользователей и их 250 миллионам фотографий.
Как я уже говорила мы заняли первое место на MegaFace competition — аналог для ImageNet, но для распознавания лиц. Он проводится уже несколько лет, в прошлом году мы были лучшими среди 100 команд со всего мира, включая Google.
Recurrent neural networks мы используем тогда, когда нам недостаточно распознавать только изображение. В тех случаях, когда нам важно соблюдать последовательность, нам нужен порядок того, что у нас происходит, мы используем обычные рекуррентные нейронные сети.
Это применяется для распознавания естественного языка, для обработки видео, даже используется для распознавания изображений.
Про распознавание естественного языка я рассказывать не буду — после моего доклада еще будут два, которые будут направлены на распознавание естественного языка. Поэтому я расскажу про работу рекуррентных сетей на примере распознавания эмоций.
Что такое рекуррентные нейронные сети? Это примерно то же самое, что и обычные нейронные сети, но с обратной связью. Обратная связь нам нужна, чтобы передавать на вход нейронной сети или на какой-то из ее слоев предыдущее состояние системы.
Предположим, мы обрабатываем эмоции. Даже в улыбке — одной из самых простых эмоций — есть несколько моментов: от нейтрального выражения лица до того момента, когда у нас будет полная улыбка. Они идут друг за другом последовательно. Чтоб это хорошо понимать, нам нужно уметь наблюдать за тем, как это происходит, передавать то, что было на предыдущем кадре в следующий шаг работы системы.
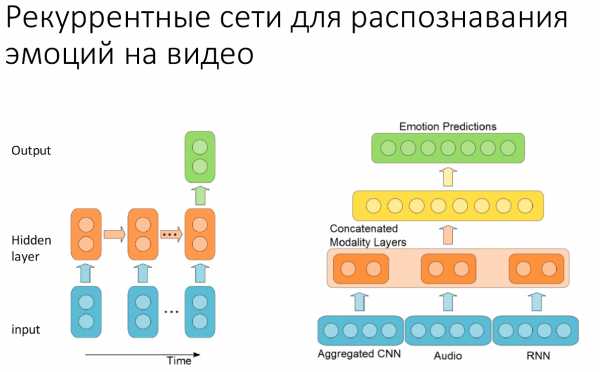
В 2005 году на состязании Emotion Recognition in the Wild специально для распознавания эмоций команда из Монреаля представила рекуррентную систему, которая выглядела очень просто. У нее было всего несколько свёрточных слоев, и она работала исключительно с видео. В этом году они добавили также распознавание аудио и cагрегировали покадровые данные, которые получаются из convolutional neural networks, данные аудиосигнала с работой рекуррентной нейронной сети (с возвратом состояния) и получили первое место на состязании.
Следующий тип нейронных сетей, который очень часто используется в последнее время, но не получил такой широкой огласки, как предыдущие 2 типа — это deep reinforcement learning, обучение с подкреплением.
Дело в том, что в предыдущих двух случаях мы используем базы данных. У нас есть либо данные с лиц, либо данные с картинок, либо данные с эмоциями с видеороликов. Если у нас этого нет, если мы не можем это отснять, как научить робота брать объекты? Это мы делаем автоматически — мы не знаем, как это работает. Другой пример: составлять большие базы данных в компьютерных играх сложно, да и не нужно, можно сделать гораздо проще.
Все, наверное, слышали про успехи deep reinforcement learning в Atari и в го.
Кто слышал про Atari? Ну кто-то слышал, хорошо. Про AlphaGo думаю слышали все, поэтому я даже не буду рассказывать, что конкретно там происходит.

Что происходит в Atari? Слева как раз изображена архитектура этой нейронной сети. Она обучается, играя сама с собой для того, чтобы получить максимальное вознаграждение. Максимальное вознаграждение — это максимально быстрый исход игры с максимально большим счетом.
Справа вверху — последний слой нейронной сети, который изображает всё количество состояний системы, которая играла сама против себя всего лишь в течение двух часов. Красным изображены желательные исходы игры с максимальным вознаграждением, а голубым — нежелательные. Сеть строит некое поле и движется по своим обученным слоям в то состояние, которого ей хочется достичь.
В робототехнике ситуация состоит немного по-другому. Почему? Здесь у нас есть несколько сложностей. Во-первых, у нас не так много баз данных. Во-вторых, нам нужно координировать сразу три системы: восприятие робота, его действия с помощью манипуляторов и его память — то, что было сделано в предыдущем шаге и как это было сделано. В общем это все очень сложно.
Дело в том, что ни одна нейронная сеть, даже deep learning на данный момент, не может справится с этой задачей достаточно эффективно, поэтому deep learning только исключительно кусочки того, что нужно сделать роботам. Например, недавно Сергей Левин предоставил систему, которая учит робота хватать объекты.
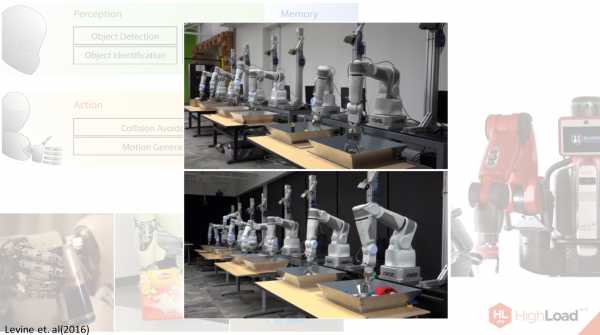
Вот здесь показаны опыты, которые он проводил на своих 14 роботах-манипуляторах.
Что здесь происходит? В этих тазиках, которые вы перед собой видите, различные объекты: ручки, ластики, кружки поменьше и побольше, тряпочки, разные текстуры, разной жесткости. Неясно, как научить робота захватывать их. В течение многих часов, а даже, вроде, недель, роботы тренировались, чтобы уметь захватывать эти предметы, составлялись по этому поводу базы данных.
Базы данных — это некий отклик среды, который нам нужно накопить для того, чтобы иметь возможность обучить робота что-то делать в дальнейшем. В дальнейшем роботы будут обучаться на этом множестве состояний системы.
Это к сожалению, конец, у меня не много времени. Я расскажу про те нестандартные решения, которые сейчас есть и которые, по многим прогнозам, будут иметь некое приложение в будущем.
Итак, ученые Стэнфорда недавно придумали очень необычное применение нейронной сети CNN для предсказания бедности. Что они сделали?
На самом деле концепция очень проста. Дело в том, что в Африке уровень бедности зашкаливает за все мыслимые и немыслимые пределы. У них нет даже возможности собирать социальные демографические данные. Поэтому с 2005 года у нас вообще нет никаких данных о том, что там происходит.
Учёные собирали дневные и ночные карты со спутников и скармливали их нейронной сети в течение некоторого времени.
Нейронная сеть была преднастроена на ImageNet'е. То есть первые слои фильтров были настроены так, чтобы она умела распознавать уже какие-то совсем простые вещи, например, крыши домов, для поиска поселения на дневных картах. Затем дневные карты были сопоставлены с картами ночной освещенности того же участка поверхности для того, чтобы сказать, насколько есть деньги у населения, чтобы хотя бы освещать свои дома в течение ночного времени.

Здесь вы видите результаты прогноза, построенного нейронной сетью. Прогноз был сделан с различным разрешением. И вы видите — самый последний кадр — реальные данные, собранные правительством Уганды в 2005 году.
Можно заметить, что нейронная сеть составила достаточно точный прогноз, даже с небольшим сдвигом с 2005 года.
Были конечно и побочные эффекты. Ученые, которые занимаются deep learning, всегда с удивлением обнаруживают разные побочные эффекты. Например, как те, что сеть научилась распознавать воду, леса, крупные строительные объекты, дороги — все это без учителей, без заранее построенных баз данных. Вообще полностью самостоятельно. Были некие слои, которые реагировали, например, на дороги.
И последнее применение о котором я хотела бы поговорить — семантическая сегментация 3D изображений в медицине. Вообще medical imaging — это сложная область, с которой очень сложно работать.
Для этого есть несколько причин.
- У нас очень мало баз данных. Не так легко найти картинку мозга, к тому же повреждённого, и взять ее тоже ниоткуда нельзя.
- Даже если у нас есть такая картинка, нужно взять медика и заставить его вручную размещать все многослойные изображения, что очень долго и крайне неэффективно. Не все медики имеют ресурсы для того, чтобы этим заниматься.
- Нужна очень высокая точность. Медицинская система не может ошибаться. При распознавании, например, котиков, не распознали — ничего страшного. А если мы не распознали опухоль, то это уже не очень хорошо. Здесь особо свирепые требования к надежности системы.
- Изображения в трехмерных элементах — вокселях, не в пикселях, что доставляет дополнительные сложности разработчикам систем.
Но как обошли этот вопрос в данном случае? CNN была двупотоковая. Одна часть обрабатывала более нормальное разрешение, другая — чуть более ухудшенное разрешение для того, чтобы уменьшить количество слоёв, которые нам нужно обучать. За счёт этого немного сократилось время на тренировку сети.
Где это применяется: определение повреждений после удара, для поиска опухоли в мозгу, в кардиологии для определения того, как работает сердце.
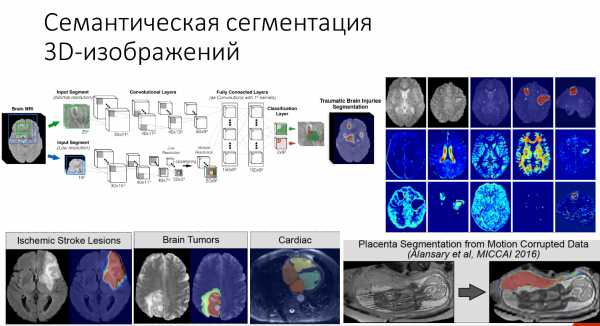
Вот пример для определения объема плаценты.
Автоматически это работает хорошо, но не настолько, чтобы это было выпущено в производство, поэтому пока только начинается. Есть несколько стартапов для создания таких систем медицинского зрения. Вообще в deep learning очень много стартапов в ближайшее время. Говорят, что venture capitalists в последние полгода выделили больше бюджета на стартапы обрасти deep learning, чем за прошедшие 5 лет.
Эта область активно развивается, много интересных направлений. Мы с вами живем в интересное время. Если вы занимаетесь deep learning, то вам, наверное, пора открывать свой стартап.
Ну на этом я, наверное, закруглюсь. Спасибо вам большое.
Доклад: Нейронные сети — практическое применение.
Нейронные сети для начинающих. Часть 2 / Habr

Добро пожаловать во вторую часть руководства по нейронным сетям. Сразу хочу принести извинения всем кто ждал вторую часть намного раньше. По определенным причинам мне пришлось отложить ее написание. На самом деле я не ожидал, что у первой статьи будет такой спрос и что так много людей заинтересует данная тема. Взяв во внимание ваши комментарии, я постараюсь предоставить вам как можно больше информации и в то же время сохранить максимально понятный способ ее изложения. В данной статье, я буду рассказывать о способах обучения/тренировки нейросетей (в частности метод обратного распространения) и если вы, по каким-либо причинам, еще не прочитали первую часть, настоятельно рекомендую начать с нее. В процессе написания этой статьи, я хотел также рассказать о других видах нейросетей и методах тренировки, однако, начав писать про них, я понял что это пойдет вразрез с моим методом изложения. Я понимаю, что вам не терпится получить как можно больше информации, однако эти темы очень обширны и требуют детального анализа, а моей основной задачей является не написать очередную статью с поверхностным объяснением, а донести до вас каждый аспект затронутой темы и сделать статью максимально легкой в освоении. Спешу расстроить любителей “покодить”, так как я все еще не буду прибегать к использованию языка программирования и буду объяснять все “на пальцах”. Достаточно вступления, давайте теперь продолжим изучение нейросетей.
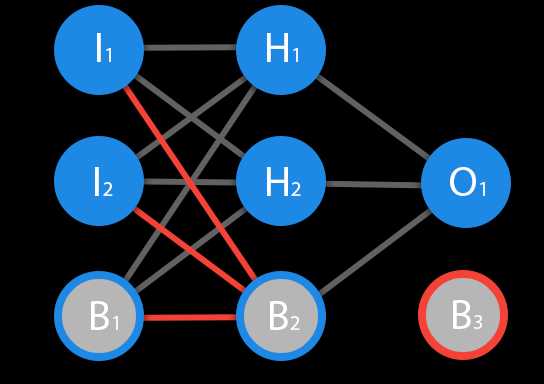
Перед тем как начать нашу основную тему, мы должны ввести понятие еще одного вида нейронов — нейрон смещения. Нейрон смещения или bias нейрон — это третий вид нейронов, используемый в большинстве нейросетей. Особенность этого типа нейронов заключается в том, что его вход и выход всегда равняются 1 и они никогда не имеют входных синапсов. Нейроны смещения могут, либо присутствовать в нейронной сети по одному на слое, либо полностью отсутствовать, 50/50 быть не может (красным на схеме обозначены веса и нейроны которые размещать нельзя). Соединения у нейронов смещения такие же, как у обычных нейронов — со всеми нейронами следующего уровня, за исключением того, что синапсов между двумя bias нейронами быть не может. Следовательно, их можно размещать на входном слое и всех скрытых слоях, но никак не на выходном слое, так как им попросту не с чем будет формировать связь.
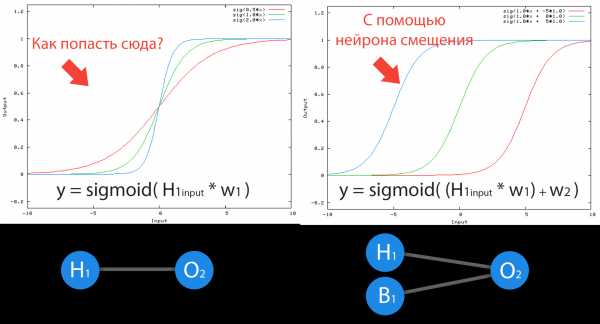
Нейрон смещения нужен для того, чтобы иметь возможность получать выходной результат, путем сдвига графика функции активации вправо или влево. Если это звучит запутанно, давайте рассмотрим простой пример, где есть один входной нейрон и один выходной нейрон. Тогда можно установить, что выход O2 будет равен входу h2, умноженному на его вес, и пропущенному через функцию активации (формула на фото слева). В нашем конкретном случае, будем использовать сигмоид.
Из школьного курса математики, мы знаем, что если взять функцию y = ax+b и менять у нее значения “а”, то будет изменяться наклон функции (цвета линий на графике слева), а если менять “b”, то мы будем смещать функцию вправо или влево (цвета линий на графике справа). Так вот “а” — это вес h2, а “b” — это вес нейрона смещения B1. Это грубый пример, но примерно так все и работает (если вы посмотрите на функцию активации справа на изображении, то заметите очень сильное сходство между формулами). То есть, когда в ходе обучения, мы регулируем веса скрытых и выходных нейронов, мы меняем наклон функции активации. Однако, регулирование веса нейронов смещения может дать нам возможность сдвинуть функцию активации по оси X и захватить новые участки. Иными словами, если точка, отвечающая за ваше решение, будет находиться, как показано на графике слева, то ваша НС никогда не сможет решить задачу без использования нейронов смещения. Поэтому, вы редко встретите нейронные сети без нейронов смещения.
Также нейроны смещения помогают в том случае, когда все входные нейроны получают на вход 0 и независимо от того какие у них веса, они все передадут на следующий слой 0, но не в случае присутствия нейрона смещения. Наличие или отсутствие нейронов смещения — это гиперпараметр (об этом чуть позже). Одним словом, вы сами должны решить, нужно ли вам использовать нейроны смещения или нет, прогнав НС с нейронами смешения и без них и сравнив результаты.
ВАЖНО знать, что иногда на схемах не обозначают нейроны смещения, а просто учитывают их веса при вычислении входного значения например:
input = h2*w1+h3*w2+b3
b3 = bias*w3
Так как его выход всегда равен 1, то можно просто представить что у нас есть дополнительный синапс с весом и прибавить к сумме этот вес без упоминания самого нейрона.
Ответ прост — нужно ее обучать. Однако, насколько бы прост не был ответ, его реализация в плане простоты, оставляет желать лучшего. Существует несколько методов обучения НС и я выделю 3, на мой взгляд, самых интересных:
- Метод обратного распространения (Backpropagation)
- Метод упругого распространения (Resilient propagation или Rprop)
- Генетический Алгоритм (Genetic Algorithm)
Об Rprop и ГА речь пойдет в других статьях, а сейчас мы с вами посмотрим на основу основ — метод обратного распространения, который использует алгоритм градиентного спуска.
Это способ нахождения локального минимума или максимума функции с помощью движения вдоль градиента. Если вы поймете суть градиентного спуска, то у вас не должно возникнуть никаких вопросов во время использования метода обратного распространения. Для начала, давайте разберемся, что такое градиент и где он присутствует в нашей НС. Давайте построим график, где по оси х будут значения веса нейрона(w) а по оси у — ошибка соответствующая этому весу(e).
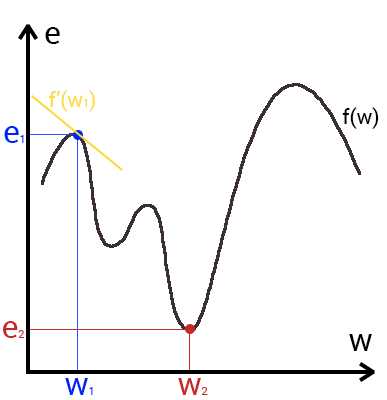
Посмотрев на этот график, мы поймем, что график функция f(w) является зависимостью ошибки от выбранного веса. На этом графике нас интересует глобальный минимум — точка (w2,e2) или, иными словами, то место где график подходит ближе всего к оси х. Эта точка будет означать, что выбрав вес w2 мы получим самую маленькую ошибку — e2 и как следствие, самый лучший результат из всех возможных. Найти же эту точку нам поможет метод градиентного спуска (желтым на графике обозначен градиент). Соответственно у каждого веса в нейросети будет свой график и градиент и у каждого надо найти глобальный минимум.
Так что же такое, этот градиент? Градиент — это вектор который определяет крутизну склона и указывает его направление относительно какой либо из точек на поверхности или графике. Чтобы найти градиент нужно взять производную от графика по данной точке (как это и показано на графике). Двигаясь по направлению этого градиента мы будем плавно скатываться в низину. Теперь представим что ошибка — это лыжник, а график функции — гора. Соответственно, если ошибка равна 100%, то лыжник находиться на самой вершине горы и если ошибка 0% то в низине. Как все лыжники, ошибка стремится как можно быстрее спуститься вниз и уменьшить свое значение. В конечном случае у нас должен получиться следующий результат:
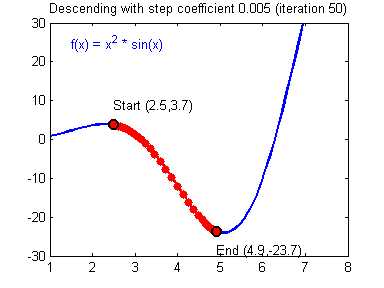
Представьте что лыжника забрасывают, с помощью вертолета, на гору. На сколько высоко или низко зависит от случая (аналогично тому, как в нейронной сети при инициализации веса расставляются в случайном порядке). Допустим ошибка равна 90% и это наша точка отсчета. Теперь лыжнику нужно спуститься вниз, с помощью градиента. На пути вниз, в каждой точке мы будем вычислять градиент, что будет показывать нам направление спуска и при изменении наклона, корректировать его. Если склон будет прямым, то после n-ого количества таких действий мы доберемся до низины. Но в большинстве случаев склон (график функции) будет волнистый и наш лыжник столкнется с очень серьезной проблемой — локальный минимум. Я думаю все знают, что такое локальный и глобальный минимум функции, для освежения памяти вот пример. Попадание в локальный минимум чревато тем, что наш лыжник навсегда останется в этой низине и никогда не скатиться с горы, следовательно мы никогда не сможем получить правильный ответ. Но мы можем избежать этого, снарядив нашего лыжника реактивным ранцем под названием момент (momentum). Вот краткая иллюстрация момента:
Как вы уже наверное догадались, этот ранец придаст лыжнику необходимое ускорение чтобы преодолеть холм, удерживающий нас в локальном минимуме, однако здесь есть одно НО. Представим что мы установили определенное значение параметру момент и без труда смогли преодолеть все локальные минимумы, и добраться до глобального минимума. Так как мы не можем просто отключить реактивный ранец, то мы можем проскочить глобальный минимум, если рядом с ним есть еще низины. В конечном случае это не так важно, так как рано или поздно мы все равно вернемся обратно в глобальный минимум, но стоит помнить, что чем больше момент, тем больше будет размах с которым лыжник будет кататься по низинам. Вместе с моментом в методе обратного распространения также используется такой параметр как скорость обучения (learning rate). Как наверняка многие подумают, чем больше скорость обучения, тем быстрее мы обучим нейросеть. Нет. Скорость обучения, также как и момент, является гиперпараметром — величина которая подбирается путем проб и ошибок. Скорость обучения можно напрямую связать со скоростью лыжника и можно с уверенностью сказать — тише едешь дальше будешь. Однако здесь тоже есть определенные аспекты, так как если мы совсем не дадим лыжнику скорости то он вообще никуда не поедет, а если дадим маленькую скорость то время пути может растянуться на очень и очень большой период времени. Что же тогда произойдет если мы дадим слишком большую скорость?
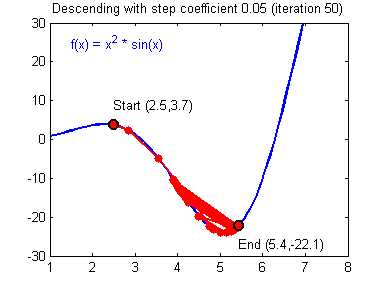
Как видите, ничего хорошего. Лыжник начнет скатываться по неправильному пути и возможно даже в другом направлении, что как вы понимаете только отдалит нас от нахождения правильного ответа. Поэтому во всех этих параметрах нужно находить золотую середину чтобы избежать не сходимости НС (об этом чуть позже).
Вот мы и дошли до того момента, когда мы можем обсудить, как же все таки сделать так, чтобы ваша НС могла правильно обучаться и давать верные решения. Очень хорошо МОР визуализирован на этой гифке:
А теперь давайте подробно разберем каждый этап. Если вы помните то в предыдущей статье мы считали выход НС. По другому это называется передача вперед (Forward pass), то есть мы последовательно передаем информацию от входных нейронов к выходным. После чего мы вычисляем ошибку и основываясь на ней делаем обратную передачу, которая заключается в том, чтобы последовательно менять веса нейронной сети, начиная с весов выходного нейрона. Значение весов будут меняться в ту сторону, которая даст нам наилучший результат. В моих вычисления я буду пользоваться методом нахождения дельты, так как это наиболее простой и понятный способ. Также я буду использовать стохастический метод обновления весов (об этом чуть позже).
Теперь давайте продолжим с того места, где мы закончили вычисления в предыдущей статье.
Данные задачи из предыдущей статьиДанные: I1=1, I2=0, w1=0.45, w2=0.78 ,w3=-0.12 ,w4=0.13 ,w5=1.5 ,w6=-2.3.
h2input = 1*0.45+0*-0.12=0.45
h2output = sigmoid(0.45)=0.61
h3input = 1*0.78+0*0.13=0.78
h3output = sigmoid(0.78)=0.69
O1input = 0.61*1.5+0.69*-2.3=-0.672
O1output = sigmoid(-0.672)=0.33
O1ideal = 1 (0xor1=1)
Error = ((1-0.33)^2)/1=0.45
Результат — 0.33, ошибка — 45%.
Так как мы уже подсчитали результат НС и ее ошибку, то мы можем сразу приступить к МОРу. Как я уже упоминал ранее, алгоритм всегда начинается с выходного нейрона. В таком случае давайте посчитаем для него значение δ (дельта) по формуле 1.
Так как у выходного нейрона нет исходящих синапсов, то мы будем пользоваться первой формулой (δ output), следственно для скрытых нейронов мы уже будем брать вторую формулу (δ hidden). Тут все достаточно просто: считаем разницу между желаемым и полученным результатом и умножаем на производную функции активации от входного значения данного нейрона. Прежде чем приступить к вычислениям я хочу обратить ваше внимание на производную. Во первых как это уже наверное стало понятно, с МОР нужно использовать только те функции активации, которые могут быть дифференцированы. Во вторых чтобы не делать лишних вычислений, формулу производной можно заменить на более дружелюбную и простую формула вида:
Таким образом наши вычисления для точки O1 будут выглядеть следующим образом.РешениеO1output = 0.33
O1ideal = 1
Error = 0.45
δO1 = (1 — 0.33) * ( (1 — 0.33) * 0.33 ) = 0.148
На этом вычисления для нейрона O1 закончены. Запомните, что после подсчета дельты нейрона мы обязаны сразу обновить веса всех исходящих синапсов этого нейрона. Так как в случае с O1 их нет, мы переходим к нейронам скрытого уровня и делаем тоже самое за исключение того, что формула подсчета дельты у нас теперь вторая и ее суть заключается в том, чтобы умножить производную функции активации от входного значения на сумму произведений всех исходящих весов и дельты нейрона с которой этот синапс связан. Но почему формулы разные? Дело в том что вся суть МОР заключается в том чтобы распространить ошибку выходных нейронов на все веса НС. Ошибку можно вычислить только на выходном уровне, как мы это уже сделали, также мы вычислили дельту в которой уже есть эта ошибка. Следственно теперь мы будем вместо ошибки использовать дельту которая будет передаваться от нейрона к нейрону. В таком случае давайте найдем дельту для h2:Решениеh2output = 0.61
w5 = 1.5
δO1 = 0.148
δh2 = ( (1 — 0.61) * 0.61 ) * ( 1.5 * 0.148 ) = 0.053
Теперь нам нужно найти градиент для каждого исходящего синапса. Здесь обычно вставляют 3 этажную дробь с кучей производных и прочим математическим адом, но в этом и вся прелесть использования метода подсчета дельт, потому что в конечном счете ваша формула нахождения градиента будет выглядеть вот так:
Здесь точка A это точка в начале синапса, а точка B на конце синапса. Таким образом мы можем подсчитать градиент w5 следующим образом:Решениеh2output = 0.61
δO1 = 0.148
GRADw5 = 0.61 * 0.148 = 0.09
Сейчас у нас есть все необходимые данные чтобы обновить вес w5 и мы сделаем это благодаря функции МОР которая рассчитывает величину на которую нужно изменить тот или иной вес и выглядит она следующим образом:
Настоятельно рекомендую вам не игнорировать вторую часть выражения и использовать момент так как это вам позволит избежать проблем с локальным минимумом.
Здесь мы видим 2 константы о которых мы уже говорили, когда рассматривали алгоритм градиентного спуска: E (эпсилон) — скорость обучения, α (альфа) — момент. Переводя формулу в слова получим: изменение веса синапса равно коэффициенту скорости обучения, умноженному на градиент этого веса, прибавить момент умноженный на предыдущее изменение этого веса (на 1-ой итерации равно 0). В таком случае давайте посчитаем изменение веса w5 и обновим его значение прибавив к нему Δw5.
РешениеE = 0.7Α = 0.3
w5 = 1.5
GRADw5 = 0.09
Δw5(i-1) = 0
Δw5 = 0.7 * 0.09 + 0 * 0.3 = 0.063
w5 = w5 + Δw5 = 1.563
Таким образом после применения алгоритма наш вес увеличился на 0.063. Теперь предлагаю сделать вам тоже самое для h3.Решениеh3output = 0.69
w6 = -2.3
δO1 = 0.148
E = 0.7
Α = 0.3
Δw6(i-1) = 0
δh3 = ( (1 — 0.69) * 0.69 ) * ( -2.3 * 0.148 ) = -0.07
GRADw6 = 0.69 * 0.148 = 0.1
Δw6 = 0.7 * 0.1 + 0 * 0.3 = 0.07
w6 = w6 + Δw6 = -2.2
И конечно не забываем про I1 и I2, ведь у них тоже есть синапсы веса которых нам тоже нужно обновить. Однако помним, что нам не нужно находить дельты для входных нейронов так как у них нет входных синапсов.Решениеw1 = 0.45, Δw1(i-1) = 0
w2 = 0.78, Δw2(i-1) = 0
w3 = -0.12, Δw3(i-1) = 0
w4 = 0.13, Δw4(i-1) = 0
δh2 = 0.053
δh3 = -0.07
E = 0.7
Α = 0.3
GRADw1 = 1 * 0.053 = 0.053
GRADw2 = 1 * -0.07 = -0.07
GRADw3 = 0 * 0.053 = 0
GRADw4 = 0 * -0.07 = 0
Δw1 = 0.7 * 0.053 + 0 * 0.3 = 0.04
Δw2 = 0.7 * -0.07 + 0 * 0.3 = -0.05
Δw3 = 0.7 * 0 + 0 * 0.3 = 0
Δw4 = 0.7 * 0 + 0 * 0.3 = 0
w1 = w1 + Δw1 = 0.5
w2 = w2 + Δw2 = 0.73
w3 = w3 + Δw3 = -0.12
w4 = w4 + Δw4 = 0.13
Теперь давайте убедимся в том, что мы все сделали правильно и снова посчитаем выход НС только уже с обновленными весами.РешениеI1 = 1
I2 = 0
w1 = 0.5
w2 = 0.73
w3 = -0.12
w4 = 0.13
w5 = 1.563
w6 = -2.2
h2input = 1 * 0.5 + 0 * -0.12 = 0.5
h2output = sigmoid(0.5) = 0.62
h3input = 1 * 0.73 + 0 * 0.124 = 0.73
h3output = sigmoid(0.73) = 0.675
O1input = 0.62* 1.563 + 0.675 * -2.2 = -0.51
O1output = sigmoid(-0.51) = 0.37
O1ideal = 1 (0xor1=1)
Error = ((1-0.37)^2)/1=0.39
Результат — 0.37, ошибка — 39%.
Как мы видим после одной итерации МОР, нам удалось уменьшить ошибку на 0.04 (6%). Теперь нужно повторять это снова и снова, пока ваша ошибка не станет достаточно мала.
Нейросеть можно обучать с учителем и без (supervised, unsupervised learning).
Обучение с учителем — это тип тренировок присущий таким проблемам как регрессия и классификация (им мы и воспользовались в примере приведенном выше). Иными словами здесь вы выступаете в роли учителя а НС в роли ученика. Вы предоставляете входные данные и желаемый результат, то есть ученик посмотрев на входные данные поймет, что нужно стремиться к тому результату который вы ему предоставили.
Обучение без учителя — этот тип обучения встречается не так часто. Здесь нет учителя, поэтому сеть не получает желаемый результат или же их количество очень мало. В основном такой вид тренировок присущ НС у которых задача состоит в группировке данных по определенным параметрам. Допустим вы подаете на вход 10000 статей на хабре и после анализа всех этих статей НС сможет распределить их по категориям основываясь, например, на часто встречающихся словах. Статьи в которых упоминаются языки программирования, к программированию, а где такие слова как Photoshop, к дизайну.
Существует еще такой интересный метод, как обучение с подкреплением (reinforcement learning). Этот метод заслуживает отдельной статьи, но я попытаюсь вкратце описать его суть. Такой способ применим тогда, когда мы можем основываясь на результатах полученных от НС, дать ей оценку. Например мы хотим научить НС играть в PAC-MAN, тогда каждый раз когда НС будет набирать много очков мы будем ее поощрять. Иными словами мы предоставляем НС право найти любой способ достижения цели, до тех пор пока он будет давать хороший результат. Таким способом, сеть начнет понимать чего от нее хотят добиться и пытается найти наилучший способ достижения этой цели без постоянного предоставления данных “учителем”.
Также обучение можно производить тремя методами: стохастический метод (stochastic), пакетный метод (batch) и мини-пакетный метод (mini-batch). Существует очень много статей и исследований на тему того, какой из методов лучше и никто не может прийти к общему ответу. Я же сторонник стохастического метода, однако я не отрицаю тот факт, что каждый метод имеет свои плюсы и минусы.
Вкратце о каждом методе:
Стохастический (его еще иногда называют онлайн) метод работает по следующему принципу — нашел Δw, сразу обнови соответствующий вес.
Пакетный метод же работает по другому. Мы суммируем Δw всех весов на текущей итерации и только потом обновляем все веса используя эту сумму. Один из самых важных плюсов такого подхода — это значительная экономия времени на вычисление, точность же в таком случае может сильно пострадать.
Мини-пакетный метод является золотой серединой и пытается совместить в себе плюсы обоих методов. Здесь принцип таков: мы в свободном порядке распределяем веса по группам и меняем их веса на сумму Δw всех весов в той или иной группе.
Гиперпараметры — это значения, которые нужно подбирать вручную и зачастую методом проб и ошибок. Среди таких значений можно выделить:
- Момент и скорость обучения
- Количество скрытых слоев
- Количество нейронов в каждом слое
- Наличие или отсутствие нейронов смещения
В других типах НС присутствуют дополнительные гиперпараметры, но о них мы говорить не будем. Подбор верных гиперпараметров очень важен и будет напрямую влиять на сходимость вашей НС. Понять стоит ли использовать нейроны смещения или нет достаточно просто. Количество скрытых слоев и нейронов в них можно вычислить перебором основываясь на одном простом правиле — чем больше нейронов, тем точнее результат и тем экспоненциально больше время, которое вы потратите на ее обучение. Однако стоит помнить, что не стоит делать НС с 1000 нейронов для решения простых задач. А вот с выбором момента и скорости обучения все чуточку сложнее. Эти гиперпараметры будут варьироваться, в зависимости от поставленной задачи и архитектуры НС. Например, для решения XOR скорость обучения может быть в пределах 0.3 — 0.7, но в НС которая анализирует и предсказывает цену акций, скорость обучения выше 0.00001 приводит к плохой сходимости НС. Не стоит сейчас заострять свое внимание на гиперпараметрах и пытаться досконально понять, как же их выбирать. Это придет с опытом, а пока что советую просто экспериментировать и искать примеры решения той или иной задачи в сети.

Сходимость говорит о том, правильная ли архитектура НС и правильно ли были подобраны гиперпараметры в соответствии с поставленной задачей. Допустим наша программа выводит ошибку НС на каждой итерации в лог. Если с каждой итерацией ошибка будет уменьшаться, то мы на верном пути и наша НС сходится. Если же ошибка будет прыгать вверх — вниз или застынет на определенном уровне, то НС не сходится. В 99% случаев это решается изменением гиперпараметров. Оставшийся 1% будет означать, что у вас ошибка в архитектуре НС. Также бывает, что на сходимость влияет переобучение НС.
Переобучение, как следует из названия, это состояние нейросети, когда она перенасыщена данными. Это проблема возникает, если слишком долго обучать сеть на одних и тех же данных. Иными словами, сеть начнет не учиться на данных, а запоминать и “зубрить” их. Соответственно, когда вы уже будете подавать на вход этой НС новые данные, то в полученных данных может появиться шум, который будет влиять на точность результата. Например, если мы будем показывать НС разные фотографии яблок (только красные) и говорить что это яблоко. Тогда, когда НС увидит желтое или зеленое яблоко, оно не сможет определить, что это яблоко, так как она запомнила, что все яблоки должны быть красными. И наоборот, когда НС увидит что-то красное и по форме совпадающее с яблоком, например персик, она скажет, что это яблоко. Это и есть шум. На графике шум будет выглядеть следующим образом.
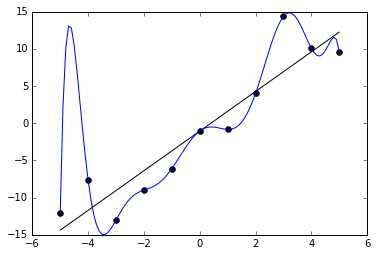
Видно, что график функции сильно колеблется от точки к точке, которые являются выходными данными (результатом) нашей НС. В идеале, этот график должен быть менее волнистый и прямой. Чтобы избежать переобучения, не стоит долго тренировать НС на одних и тех же или очень похожих данных. Также, переобучение может быть вызвано большим количеством параметров, которые вы подаете на вход НС или слишком сложной архитектурой. Таким образом, когда вы замечаете ошибки (шум) в выходных данных после этапа обучения, то вам стоит использовать один из методов регуляризации, но в большинстве случаев это не понадобиться.
Надеюсь эта статья смогла прояснить ключевые моменты такого нелегко предмета, как Нейронные сети. Однако я считаю, что сколько бы ты статей не прочел, без практики такую сложную тему освоить невозможно. Поэтому, если вы только в начале пути и хотите изучить эту перспективную и развивающуюся отрасль, то советую начать практиковаться с написания своей НС, а уже после прибегать к помощи различных фреймворков и библиотек. Также, если вам интересен мой метод изложения информации и вы хотите, чтобы я написал статьи на другие темы связанные с Машинным обучением, то проголосуйте в опросе ниже за ту тему которую вам интересна. До встречи в будущих статьях :)
Нейронные сети - простыми словами: история, типология, будущее нейронных систем
Нейронные сети – это современный тренд, применяемый в науке и технике. С их помощью улучшаются программы и создаются целые системы, способные автоматизировать, ускорять и помогать в работе человеку. Основная урбанистическая цель – научить систему самостоятельно принимать решения в сложных ситуациях так, как это делает человек.
Биологические нейронные сети
Многое из того, что человечество желает достичь искусственно, уже сделано природой. Человеческий мозг наделен великолепной нейронной сетью, изучение которой ведется и по сей день. Генетически, биологические нейронные сети устроены довольно сложно и человеку без соответствующей технической подготовки будет сложно понять процесс работы естественной нейросети.
В упрощённой трактовке можно сказать так: биологическая нейронная сеть это та часть нервной системы, что находится в мозге человека. Совокупность нейронов и сети позволяет нам думать, принимать решения и воспринимать окружающий мир. Биологический нейрон – клетка, основные составляющие которой: ядро, отростки, тела и иные компоненты для тесной связи с тысячами нейронов. По этой связи передаются электрохимические импульсы, приводящие нейронную сеть в состояние спокойствия или возбуждения. Например, перед сдачей экзаменов или другим важным событием, порождается импульс и распространяется по всей нейронной сети в головном мозге, проводя сеть в состояние возбуждения. Затем, по нервной системе передается это состояние другим органам, что приводит к учащению сердцебиения, частому морганию ресниц и прочим проявлениям волнения.
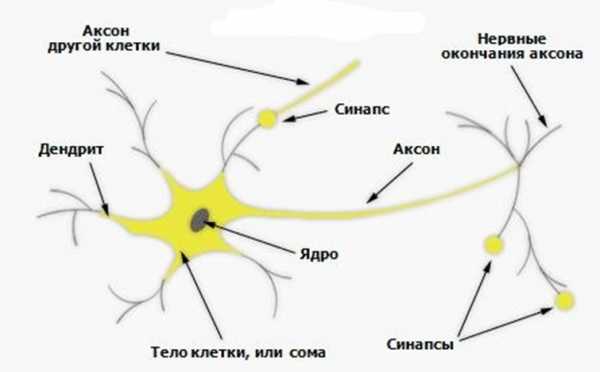
По упрощенной теории естественной нейросети рассмотрим составляющие нейрона. Состоит он из тела клетки и ядра. К телу относится множество ответвлений, называемых дендритами. Длинные дендриты называться Аксонами. С их помощью проходит связь между нейронами с помощью синапсов (места контакта двух нейронов, по которым проходит импульс). В этом случае можно уловить закономерность. На дендрит приходит сигнал (значит это вход), по аксону (выход) передается на другую нейронную клетку. В точке синаптической передачи импульса, его частота и амплитуда может изменяться (переменные составляющие сложного уравнения, влияющие на состояние сигнала). Примерно так работает естественная нейросеть в голове каждого человека. В таком случае, почему бы не создать искусственную нейросеть наподобие естественной, откинув биологическую составляющую. Дендрит будет выступать в роли входа, аксон – выход, тело нейрона в виде сумматора, а кодом, состоящим из 0 и 1 можно регулировать частоту, импульс сигнала, перед подачей на сумматор в разделе «Веса». Это основная составляющая нейрона. В целом, математическую и графическую модель нейрона можно записать так.
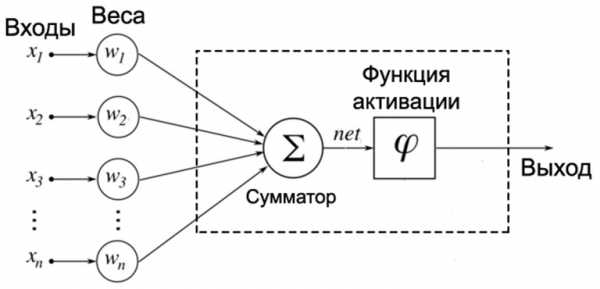
Нарисовать и представить алгоритм работы можно с помощью абстрактной схемы. Есть несколько методов представления схем нейронных сетей, но для наглядности проще будет использовать кружки со стрелками.
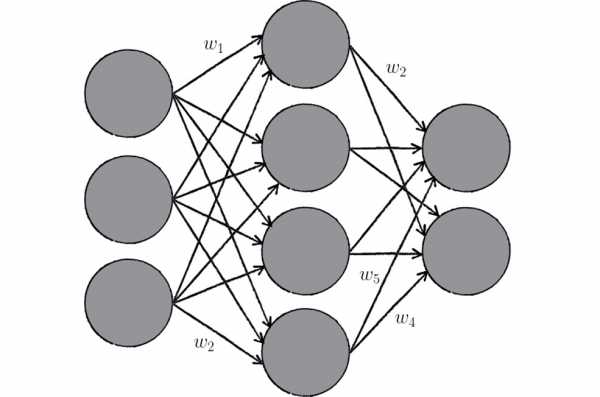
Изучив основные аспекты, можно дать определение искусственной нейронной сети – это построенная по математическим правилам модель естественной нейросети, которая воплощена в жизнь с помощью программных и аппаратных составляющих.
История нейронных сетей
Развитие искусственной нейросети началось с появлением электронно-вычислительных машин (ЭВМ) в конце 1940 года. В это время, канадский физиолог и нейропсихолог Дональд Хебб создал алгоритм нейронной сети, и заложил принципы его работы в ЭВМ. Затем, важными точками в развитии искусственных нейросетей были такие даты: 1. 1954 год – на рабочей ЭВМ впервые на практике применили нейросеть. 2. 1958 год – американским ученым по нейрофизиологии и искусственного интеллекта, Фрэнком Розенблаттом был разработан алгоритм распознавания образов и предоставлено его краткое изложение для общественности. 3. 1960 год – ЭВМ не могла должным образом из-за слабых мощностей выполнять сложные задачи, возложенные на нее, поэтому интерес к технологии немного угас. 4. За двадцатилетний период полным ходом шла «компьютеризация», и мощности тогдашних компьютеров хватило, чтобы вновь разжечь интерес к нейросетям. В 1980 году появилась система с механизмом обратной связи и начались разработки алгоритмов по самообучению. 5. Спустя следующие 20 лет, мощности компьютеров выросли настолько, что в 2000 году ученые-исследователи смогли применять нейросети во многих сферах. Появились программы распознавания речи, имитация зрения, когнитивного восприятия информации. Нейросеть, машинное обучение, робототехника, компьютеризация стали частью нечто большего, под названием «искусственный интеллект».
Типы нейронных сетей
За период развития, нейронные сети поделились на множество типов, которые переплетаются между собой в различных задачах. На данный момент сложно классифицировать какую-либо сеть только по одному признаку. Это можно сделать по принципу применения, типу входной информации, характеру обучения, характеру связей, сфере применения.
| Нейронная сеть | Принцип применения | Обучение с учителем (+) или без(-) или смешанное (с) | Сфера применения |
| Перцептрон Розенблатта | Распознание образов, принятие решений, прогнозирование, аппроксимация, анализ данных | + | Практически любая сфера применения, кроме оптимизации информации |
| Хопфилда | Сжатие данных и ассоциативная память | — | Строение компьютерных систем |
| Кохонена | Кластеризация, сжатие данных, анализ данных, оптимизация | — | Финансы, базы данных |
| Радиально-базисных функций (RBF-сеть) | Принятие решений и управление, аппроксимация, прогнозирование | с | Управленческие структуры, нейроуправление |
| Свёрточная | Распознание образов | + | Обработка графических данных |
| Импульсная | Принятие решение, распознавание образов, анализ данных | с | Протезирование, робототехника, телекоммуникации, компьютерное зрение |
Про то, что такое обучение с учителем, написано в следующем разделе. Каждая сеть имеет свои характеристики, которые можно применять в том или ином случае. Рассмотрим более подробно два типа сетей, которые для множества производных типов нейросетей являются практически первоисточниками.
Сверточные
Один из популярнейших типов сети, часто используемый для распознавания той или иной информации в фотографиях и видео, обработке языка, системах для рекомендаций. Основные характеристики:
- Отличная масштабируемость – проводят распознания образов любого разрешения (какое бы не было оно большое).
- Использование объемных трехмерных нейронов – внутри слоя, нейроны связаны малым полем, именуемы рецептивным слоем.
- Механизм пространственной локализации – соседние слои нейронов связаны таким механизмом, за счет чего обеспечивается работа нелинейных фильтров и охват все большего числа пикселей графического изображения.
Идея сложной системы этого типа нейросети возникла при тщательном изучении зрительной коры, которая в больших полушариях мозга отвечает за обработку визуальной составляющей. Основной критерий выбора в пользу сверточного типа – она в составе технологий глубокого обучения. Схожий тип с перцептроном, но разница в том, что здесь используется ограниченная матрица весов, сдвигаемая по обрабатываемому слою, вместо полносвязной нейронной сети.
Рекуррентные
Этот тип нейросети, в котором связи между элементами могут обрабатывать серии различных событий во времени или работать с последовательными цепочками в пространстве. Такой тип часто применяют там, где что-то целое разбито на куски. Например, распознавание речи или рукописного текста. От нее пошло множество видов сетей, в том числе Хопфилда, Элмана и Джордана.
Обучение нейронной сети
Один из главных и самый важный критерий – возможность обучения нейросети. В целом, нейросеть – это совокупность нейронов, через которые проходит сигнал. Если подать его на вход, то пройдя через тысячи нейронов, на выходе получится неизвестно что. Для преобразования нужно менять параметры сети, чтобы на выходе получились нужные результаты.

Входной сигнал изменить нельзя, сумматор выполняет функцию суммирования и изменить что-то в нем или вывести из системы не выйдет, так как это перестанет быть нейросетью. Остается одно – использовать коэффициенты или коррелирующие функции и применять их на веса связей. В этом случае можно дать определение обучения нейронной сети – это поиск набора весовых коэффициентов, которые при прохождении через сумматор позволят получить на выходе нужный сигнал.
Такую концепцию применяет и наш мозг. Вместо весов в нем используются синопсы, позволяющие усиливать или делать затухание входного сигнала. Человек обучается, благодаря изменению синапсов при прохождении электрохимического импульса в нейросети головного мозга.
Но есть один нюанс. Если же задать вручную коэффициенты весов, то нейросеть запомнит правильный выходной сигнал. При этом вывод информации будет мгновенным и может показаться, что нейросеть смогла быстро обучиться. И стоит немного изменить входной сигнал, как на выходе появятся неправильные, не логические ответы.
Поэтому, вместо указания конкретных коэффициентов для одного входного сигнала, можно создать обобщающие параметры с помощью выборки.
С помощью такой выборки можно обучать сеть, чтобы она выдавала корректные результаты. В этом моменте, можно поделить обучение нейросети на обучение с учителем и без учителя.
Обучение с учителем
Обучение таким способом подразумевает концепцию: даете выборку входных сигналов нейросети, получаете выходные и сравниваете с готовым решением.
Как готовить такие выборки:
- Для опознавания лиц создать выборку из 5000-10000 фотографий (вход) и самостоятельно указать, какие содержат лица людей (выход, правильный сигнал).
- Для прогнозирования роста или падения акций, выборка делается с помощью анализа данных прошлых десятилетий. Входными сигналами могут быть как состояние рынка в целом, так и конкретные дни.
Учителем не обязательно выступает человек. Сеть нужно тренировать сотнями и тысячами часов, поэтому в 99% случаев тренировкой занимается компьютерная программа.
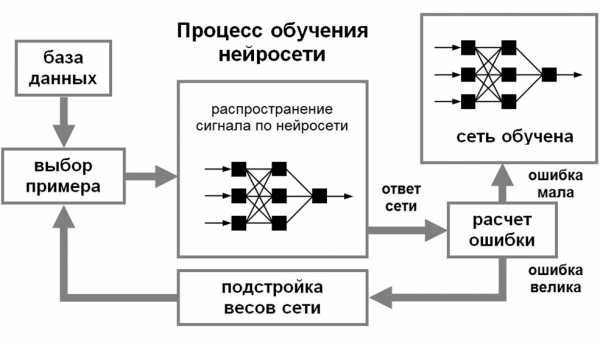
Обучение без учителя
Концепция состоит в том, что делается выборка входных сигналов, но правильных ответов на выходе вы знать не можете.
Как происходит обучение? В теории и на практике, нейросеть начинает кластеризацию, то есть определяет классы подаваемых входных сигналов. Затем, она выдает сигналы различных типов, отвечающие за входные объекты.
Сколько нейронным сетям еще до человеческого мозга?
В некоторых аспектах, нейронная сеть уже превосходит человеческий мозг – это запоминание информации и быстродействие, ее обработка. Однажды запомнив данные, нейросеть навсегда отложит их в своей памяти.
Что касается качества обработки информации, то нейросеть еще не дотягивает до уровней человеческого мозга. С каждым годом, этот показатель улучшается, но достичь или превзойти человека – вопрос на десятилетия продуктивного труда. Несовершенство нейронной сети тоже играет немаловажную роль. Типов сети сделано достаточно много и каждый отвечает за тот или иной аспект деятельности. Естественная нейросеть – одна и она взаимодействует как единый механизм, чего на практике достичь искусственно очень и очень тяжело.
Почему нейронные сети стали так популярны именно сейчас

Все дело в мощностях вычислительной техники. Сегодня, из сотен или тысяч компьютеров можно создать сеть с огромной вычислительной мощностью, которая позволяет решать задачи, ранее не доступные ученым. Например, моделировать вселенную или использовать распознавание речи, получить быстрый ответ на любой заданный вопрос.
Применение нейронных сетей
Исследовательские университеты, корпоративные гиганты, обучающие центры – применение нейросетей затронуло практически каждый аспект жизни человека.
Поисковые системы

Яндекс и Google не первый год используют нейронные сети для обучения собственный поисковых систем, делая их «умнее». Они адаптируются под конкретного пользователя, узнают о его предпочтениях и выдают максимально релевантные результаты. Тот же принцип применяется и в контекстной и таргетированной рекламе.
Голосовые ассистенты

Системы распознавания речи достигли такого уровня, что позволяют распознать вопрос и предоставить информацию по нему, или выполнить ту или иную функцию. Эти голосовые ассистенты внедряются в технику, поэтому мы можем голосом попросить включить медленную музыкальную композицию, притушить свет в комнате, открыть окно на проветривание и поставить таймер на приготовление еды в мультиварке.
Автономное управление автомобилем

Управление без участия водителя – это уже реальность сегодняшнего дня. Благодаря нейронной сети, что входит в комплекс систем автономного управления, автомобиль может передвигаться в автоматическом режиме, соблюдая все правила дорожного движения.
Фотофильтры
Работа с графикой – самое популярное направление нейросети. С ее помощью можно накладывать множество фильтров на фото и видео, используя дополнительную реальность. Еще, множество фотографий можно прогонять через специальные приложения, чтобы получить на выходе эффекты молодости, старения, смены пола и прочие прелести вполне качественного автоматического фотошопа.
Заключение
Искусственные нейронные сети – технология, что уже позволяет приниматься человечеству за задачи, на решение которых ушли бы тысячелетия. Это перспективная и востребованная ветвь развития науки и техники, которая будет популярна на протяжении многих лет.
как искусственный интеллект помогает в бизнесе и жизни / Habr
Читайте оригинал статьи в Блоге DTI.В работе Oxford Martin School 2013 года говорилось о том, что 47% всех рабочих мест может быть автоматизировано в течение следующих 20 лет. Основным драйвером этого процесса является применение искусственного интеллекта, работающего с большими данными, как более эффективной замены человеку.

Машины теперь способны решать все больше процессов, за которые раньше отвечали люди. Кроме того, делают это качественнее и во многих случаях дешевле. О том, что это значит для рынка труда, в июле этого года говорил Герман Греф, выступая перед студентами Балтийского федерального университета им. Канта:
“Мы перестаём брать на работу юристов, которые не знают, что делать с нейронной сетью. <...> Вы — студенты вчерашнего дня. Товарищи юристы, забудьте свою профессию. В прошлом году 450 юристов, которые у нас готовят иски, ушли в прошлое, были сокращены. У нас нейронная сетка готовит исковые заявления лучше, чем юристы, подготовленные Балтийским федеральным университетом. Их мы на работу точно не возьмем.”
Продолжая освещать #технобудущее, команда DTI подготовила все, что необходимо знать для первого погружения в нейронные сети: как они устроены, почему все больше компаний предпочитают нейросети живым сотрудникам и какой потенциал по оптимизации различных процессов несет эта технология.
Искусственный интеллект, машинное обучение и нейросети: в чем разница
Нейронная сеть – один из способов реализации искусственного интеллекта (ИИ).
В разработке ИИ существует обширная область — машинное обучение. Она изучает методы построения алгоритмов, способных самостоятельно обучаться. Это необходимо, если не существует четкого решения какой-либо задачи. В этом случае проще не искать правильное решение, а создать механизм, который сам придумает метод для его поиска.
#справка Во многих статьях можно встретить термин «глубокое» — или «глубинное» — обучение. Под ним понимают алгоритмы машинного обучения, использующие много вычислительных ресурсов. В большинстве случаев под ним можно понимать просто “нейронные сети”.
Чтобы не запутаться в понятиях «искусственный интеллект», «машинное обучение» и «глубокое обучение», предлагаем посмотреть на визуализацию их развития:

#интересное Существует два типа искусственного интеллекта (ИИ): слабый (узконаправленный) и сильный (общий). Слабый ИИ предназначен для выполнения узкого списка задач. Такими являются голосовые помощники Siri и Google Assistant и все остальные примеры, которые мы приводим в этой статье. Сильный ИИ, в свою очередь, способен выполнить любую человеческую задачу. На данный момент реализация сильного ИИ невозможна, он является утопической идеей.
Как устроена нейросеть
Нейросеть моделирует работу человеческой нервной системы, особенностью которой является способность к самообучению с учетом предыдущего опыта. Таким образом, с каждым разом система совершает все меньше ошибок.
Как и наша нервная система, нейросеть состоит из отдельных вычислительных элементов – нейронов, расположенных на нескольких слоях. Данные, поступающие на вход нейросети, проходят последовательную обработку на каждом слое сети. При этом каждый нейрон имеет определенные параметры, которые могут изменяться в зависимости от полученных результатов – в этом и заключается обучение сети.
Предположим, что задача нейросети – отличать кошек от собак. Для настройки нейронной сети подается большой массив подписанных изображений кошек и собак. Нейросеть анализирует признаки (в том числе линии, формы, их размер и цвет) на этих картинках и строит такую распознавательную модель, которая минимизирует процент ошибок относительно эталонных результатов.
На рисунке ниже представлен процесс работы нейросети, задача которой — распознать цифру почтового индекса, написанную от руки.
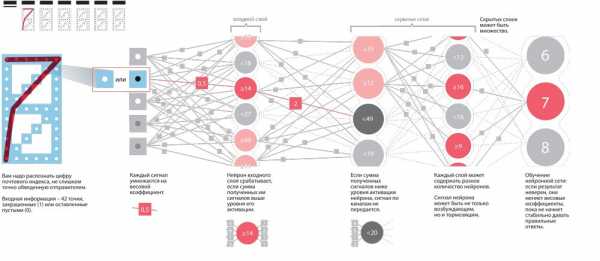
История нейросетей
Несмотря на то, что нейросети попали в центр всеобщего внимания совсем недавно, это один из старейших алгоритмов машинного обучения. Первая версия формального нейрона, ячейки нейронной сети, была предложена Уорреном Маккалоком и Уолтером Питтсом в 1943 году.
А уже в 1958 году Фрэнк Розенблатт разработал первую нейронную сеть. Несмотря на свою простоту, она уже могла различать, например, объекты в двухмерном пространстве.

Mark I Perceptron — машина Розенблатта
Первые успехи привлекли повышенное внимание к технологии, однако затем другие алгоритмы машинного обучения стали показывать лучшие результаты, и нейросети отошли на второй план. Следующая волна интереса пришлась на 1990-е годы, после чего о нейросетях почти не было слышно до 2010 года.
Почему нейросети вновь популярны
До 2010 года попросту не существовало базы данных, достаточно большой для того, чтобы качественно обучить нейросети решать определенные задачи, в основном связанные с распознаванием и классификацией изображений. Поэтому нейросети довольно часто ошибались: путали кошку с собакой, или, что еще хуже, снимок здорового органа со снимком органа, пораженного опухолью.
Но в 2010 году появилась база ImageNet, содержащая 15 миллионов изображений в 22 тысячах категорий. ImageNet многократно превышала объем существовавших баз данных изображений и была доступна для любого исследователя. С такими объемами данных нейросети можно было учить принимать практически безошибочные решения.

Размер ImageNet в сравнении с другими существовавшими в 2010 году базами изображений
До этого на пути развития нейросетей стояла другая, не менее существенная, проблема: традиционный метод обучения был неэффективен. Несмотря на то что важную роль играет число слоев в нейронной сети, важен также и метод обучения сети. Использовавшийся ранее метод обратного шифрования мог эффективно обучать только последние слои сети. Процесс обучения оказывался слишком длительным для практического применения, а скрытые слои глубинных нейросетей не функционировали должным образом.
Результатов в решении этой проблемы в 2006 году добились три независимых группы ученых. Во-первых, Джеффри Хинтон реализовал предобучение сети при помощи машины Больцмана, обучая каждый слой отдельно. Во-вторых, Ян ЛеКан предложил использование сверточной нейронной сети для решения проблем распознавания изображений. Наконец, Иошуа Бенджио разработал каскадный автокодировщик, позволивший задействовать все слои в глубокой нейронной сети.
Примеры успешного применения нейросетей в бизнесе
Медицина
Команда исследователей из Ноттингемского университета разработала четыре алгоритма машинного обучения для оценки степени риска сердечно-сосудистых заболеваний пациентов. Для обучения использовались данные 378 тыс. британских пациентов. Обученный искусственный интеллект определял риск кардиологических заболеваний эффективнее реальных врачей. Точность алгоритма — между 74 и 76,4 процентами (стандартная система из восьми факторов, разработанная Американской коллегией кардиологии, обеспечивает точность лишь в 72,8%).
Финансы
Японская страховая компания Fukoku Mutual Life Insurance заключила контракт с IBM. Согласно нему, 34 сотрудников японской компании заменит система IBM Watson Explorer AI. Нейросеть будет просматривать десятки тысяч медицинских сертификатов и учитывать число посещений госпиталей, перенесенные операции и другие факторы для определения условий страхования клиентов. В Fukoku Mutual Life Insurance уверены, что использование IBM Watson повысит продуктивность на 30% и окупится за два года.
Машинное обучение помогает распознавать потенциальные случаи мошенничества в различных сферах жизни. Подобный инструмент использует, например, PayPal – в рамках борьбы с отмыванием денег компания сравнивает миллионы транзакций и обнаруживает среди них подозрительные. В результате, мошеннические транзакции в PayPal составляют рекордно низкие 0,32%, тогда как стандарт в финансовом секторе — 1,32%.
Коммерция
Искусственный интеллект существенно улучшил механизмы рекомендаций в онлайн-магазинах и сервисах. Алгоритмы, основанные на машинном обучении, анализируют ваше поведение на сайте и сравнивают его с миллионами других пользователей. Все для того, чтобы определить, какой продукт вы купите с наибольшей вероятностью.
Механизм рекомендаций обеспечивает Amazon 35% продаж. Алгоритм Brain, используемый YouTube для рекомендации контента, позволил добиться того, что практически 70% видео, просматриваемых на сайте, люди нашли благодаря рекомендациям (а не по ссылкам или подпискам). WSJ сообщало о том, что использование искусственного интеллекта для рекомендаций является одним из факторов, повлиявших на 10-кратный рост аудитории за последние пять лет.
Алгоритм Yandex Data Factory способен предсказывать влияние промоакций на объем продаж товаров. Анализируя историю продаж, а также тип и ассортимент магазина, алгоритм дал 87% точных (с точностью до коробки) и 61% ультраточных (с точностью до упаковки) прогнозов.
Нейросети, анализирующие естественный язык, могут использоваться для создания чат-ботов, позволяющих клиентам получить необходимую информацию о продуктах компании. Это позволит сократить издержки на команды колл-центров. Подобный робот уже работает в приемной Правительства Москвы и обрабатывает около 5% запросов. Бот способен подсказать, в том числе, расположение ближайшего МФЦ и график отключения горячей воды.
На технологии нейронных сетей также основана Albert – маркетинговая платформа полного цикла, самостоятельно осуществляющая практически все операции. Использующая ее компания-производитель нижнего белья Cosabella в итоге расформировала собственный отдел маркетинга и полностью доверилась платформе.
Транспорт
Беспилотные автомобили – концепт, над которым работает большинство крупных концернов, а также технологические компании (Google, Uber, Яндекс и другие) и стартапы, в своей работе опирается на нейросети. Искусственный интеллект отвечает за распознавание окружающих объектов – будь то другой автомобиль, пешеход или иное препятствие.

Так видит наш мир нейросеть
Потенциал искусственного интеллекта в этой сфере не ограничивается автопилотом. Недавний опрос IBM показал: 74% топ-менеджеров автомобильной индустрии ожидают, что умные автомобили появятся на дорогах уже к 2025 году. Такие автомобили, интегрированные в Интернет вещей (см. наш предыдущий лонгрид), будут собирать информацию о предпочтениях пассажиров и автоматически регулировать температуру в салоне, громкость радио, положение сидений и другие параметры. Помимо пилотирования, система также будет информировать о возникающих проблемах (и даже попытается решить их сама) и ситуации на дороге.
Промышленность
Нейросеть, разработанная Марком Уоллером из Шанхайского Университета, специализируется на разработке синтетических молекул. Алгоритм составил шестистадийный синтез производного бензопирана сульфонамида (необходим при лечении Альцгеймера) всего за 5,4 секунды.
Инструменты Yandex Data Factory помогают при выплавке стали: использующийся для производства стали металлический лом зачастую неоднороден по составу. Чтобы сталь соответствовала стандартам, при ее выплавке всегда нужно учитывать специфику лома и вводить специальные добавки. Этим обычно занимаются специально обученные технологи. Но, поскольку на таких производствах собирается много информации о поступающем сырье, применяемых добавках и результате, эту информацию с большей эффективностью способна обработать нейросеть. По данным Яндекса, внедрение нейросетей позволяет на 5% сократить расходы дорогих ферросплавов.
Аналогичным образом нейросеть способна помочь в переработке стекла. Сейчас это нерентабельный, хотя и полезный, бизнес, нуждающийся в государственных субсидиях. Использование технологий машинного обучения позволит значительно сократить издержки.
Сельское хозяйство
Инженеры Microsoft совместно с учеными из ICRISAT применяют искусственный интеллект, чтобы определить оптимальное время посева в Индии. Приложение, использующее Microsoft Cortana Intelligence Suite, также следит за состоянием почвы и подбирает необходимые удобрения. Изначально в программе участвовало всего лишь 175 фермеров из 7 деревень. Они начали посев только после соответствующего SMS уведомления. В результате, они собрали урожая на 30-40% больше, чем обычно.
Развлечения и искусство
В прошлом году вышли и мгновенно стали популярными приложения, использующие нейросети для обработки фото и видео: MSQRD от белорусских разработчиков (в дальнейшем сервис выкупила Facebook), и российские Prisma и Mlvch. Другой сервис, Algorithmia, раскрашивает черно-белые фотографии.
Яндекс успешно экспериментирует с музыкой: нейронные сети компании уже записали два альбома: в стиле Nirvana и “Гражданской обороны”. А музыка, написанная нейросетью под композитора-классика Александра Скрябина, была исполнена камерным оркестром, что заставляет вновь задуматься над вопросом о том, сможет ли робот сочинить симфонию. Нейросеть, созданная сотрудниками Sony, вдохновлялась Бахом.
Японский алгоритм написал книгу “День, когда Компьютер написал роман”. Несмотря на то что с характерами героев и сюжетными линиями неопытному писателю помогали люди, компьютер проделал огромную работу – в итоге одна из его работ прошла отборочный этап престижной литературной премии. Нейросети также написали продолжения к Гарри Поттеру и Игре Престолов.
В 2015 году нейросеть AlphaGo, разработанная командой Google DeepMind, стала первой программой, победившей профессионального игрока в го. А в мае этого года программа обыграла сильнейшего игрока в го в мире, Кэ Цзэ. Это стало прорывом, поскольку долгое время считалось, что компьютеры не обладают интуицией, необходимой для игры в го.
Безопасность
Команда разработчиков из Технологического университета Сиднея представила дронов для патрулирования пляжей. Основной задачей дронов станет поиск акул в прибрежных водах и предупреждение людей на пляжах. Анализ видеоданных производят нейросети, что существенно отразилось на результатах: разработчики утверждают о вероятности обнаружения и идентификации акул до 90%, тогда как оператор, просматривающий видео с беспилотников, успешно распознает акул лишь в 20-30% случаев.
Австралия занимает второе место в мире после США по количеству случаев нападения акул на людей. В 2016 году в этой стране были зафиксированы 26 случаев нападения акул, два из которых закончились смертью людей.
В 2014 году Лаборатория Касперского сообщала, что их антивирус регистрирует 325 тыс. новых зараженных файлов ежедневно. В то же время, исследование компании Deep Instinct показало, что новые версии вирусов практически не отличаются от предыдущих – изменение составляет от 2% до 10%. Самообучающаяся модель, разработанная Deep Instinct, на основании этой информации способна с высокой точностью определять зараженные файлы.
Нейросети также способны искать определенные закономерности в том, как хранится информация в облачных сервисах, и сообщать об обнаруженных аномалиях, способных привести к бреши в безопасности.
Бонус: нейросети на страже нашего газона
В 2016 году 65-летний инженер NVIDIA Роберт Бонд столкнулся с проблемой: соседские кошки регулярно посещали его участок и оставляли следы своего присутствия, что раздражало его жену, работающую в саду. Бонд сразу отсек слишком недружелюбную идею соорудить ловушки для незваных гостей. Вместо этого он решил написать алгоритм, который бы автоматически включал садовые разбрызгиватели воды при приближении кошек.
Перед Робертом стояла задача идентификации кошек в поступающем с внешней камеры видеопотоке. Для этого он использовал систему, основанную на популярной нейросети Caffe. Каждый раз, когда камера наблюдала изменение в обстановке на участке, она делала семь снимков и передавала их нейросети. После этого нейросеть должна была определить, присутствует ли в кадре кошка, и, в случае утвердительного ответа, включить разбрызгиватели.

Изображение с камеры во дворе Бонда
До начала работы нейросеть прошла обучение: Бонд “скормил” ей 300 разных фотографий кошек. Анализируя эти фотографии, нейросеть училась распознавать животных. Но этого оказалось недостаточно: она корректно определяла кошек лишь в 30% случаев и приняла за кошку тень Бонда, в результате чего он сам оказался мокрым.
Нейросеть заработала лучше после дополнительного обучения на большем количестве фотографий. Однако Бонд предупреждает, что нейросеть можно натренировать слишком сильно, в случае чего у нее сложится нереалистичный стереотип – например, если все снимки, использующиеся для обучения, сняты с одного ракурса, то искусственный интеллект может не распознать ту же самую кошку с другого угла. Поэтому чрезвычайно важным является грамотный подбор обучающего ряда данных.
Через некоторое время кошки, обучившиеся не на фотографиях, но на собственной шкуре, перестали посещать участок Бонда.
Заключение
Нейронные сети, технология середины прошлого века, сейчас меняет работу целых отраслей. Реакция общества неоднозначна: одних возможности нейросетей приводят в восторг, а других – заставляют усомниться в их пользе как специалистов.
Однако не везде, куда приходит машинное обучение, оно вытесняет людей. Если нейросеть ставит диагнозы лучше живого врача, это не значит, что в будущем нас будут лечить исключительно роботы. Вероятнее, врач будет работать вместе с нейросетью. Аналогично, суперкомпьютер IBM Deep Blue выиграл в шахматы у Гарри Каспарова еще в 1997 году, однако люди из шахмат никуда не делись, а именитые гроссмейстеры до сих пор попадают на обложки глянцевых журналов.
Кооперация с машинами принесет гораздо больше пользы, чем конфронтация. Поэтому мы собрали список материалов в открытом доступе, которые помогут вам продолжить знакомство с нейросетями:
пятиминутный гид для новичков / Neurodata Lab corporate blog / Habr
С момента описания первого искусственного нейрона Уорреном Мак-Каллоком и Уолтером Питтсом прошло более пятидесяти лет. С тех пор многое изменилось, и сегодня нейросетевые алгоритмы применяются повсеместно. И хотя нейронные сети способны на многое, исследователи при работе с ними сталкиваются с рядом трудностей: от переобучения до проблемы «черного ящика».Если термины «катастрофическая забывчивость» и «регуляризация весов» вам пока ни о чем не говорят, читайте дальше: попробуем разобраться во всем по порядку.
 / Фотография Jun / CC-SA
/ Фотография Jun / CC-SA
За что мы любим нейросети
Основное преимущество нейронных сетей перед другими методами машинного обучения состоит в том, что они могут распознавать более глубокие, иногда неожиданные закономерности в данных. В процессе обучения нейроны способны реагировать на полученную информацию в соответствии с принципами генерализации, тем самым решая поставленную перед ними задачу.
К областям, где сети находят практическое применение уже сейчас, можно отнести медицину (например, очистка показаний приборов от шумов, анализ эффективности проведённого лечения), интернет (ассоциативный поиск информации), экономику (прогнозирование курсов валют, автоматический трейдинг), игры (например, го) и другие. Нейросети могут использоваться практически для чего угодно в силу своей универсальности. Однако волшебной таблеткой они не являются, и чтобы они начали функционировать должным образом, требуется проделать много предварительной работы.
Обучение нейросетей 101
Одним из ключевых элементов нейронной сети является способность обучаться. Нейронная сеть — это адаптивная система, умеющая изменять свою внутреннюю структуру на базе поступающей информации. Обычно такой эффект достигается с помощью корректировки значений весов.
Связи между нейронами на соседних слоях нейросети — это числа, описывающие значимость сигнала между двумя нейронами. Если обученная нейронная сеть верно реагирует на входную информацию, то настраивать веса нет необходимости, а в противном случае с помощью какого-либо алгоритма обучения нужно изменить веса, улучшив результат.
Как правило, это делают с помощью метода обратного распространения ошибки: для каждого из обучающих примеров веса корректируются так, чтобы уменьшить ошибку. Считается, что при правильно подобранной архитектуре и достаточном наборе обучающих данных сеть рано или поздно обучится.
Существует несколько принципиально отличающихся подходов к обучению, в привязке к поставленной задаче. Первый — обучение с учителем. В этом случае входные данные представляют собой пары: объект и его характеристику. Такой подход применяется, например, в распознавании изображений: обучение проводится по размеченной базе из картинок и расставленных вручную меток того, что на них нарисовано.
Самой известной из таких баз является ImageNet. При такой постановке задачи обучение мало чем отличается от, например, распознавания эмоций, которым занимается Neurodata Lab. Сети демонстрируются примеры, она делает предположение, и, в зависимости от его правильности, корректируются веса. Процесс повторяется до тех пор, пока точность не увеличивается до искомых величин.
Второй вариант — обучение без учителя. Типичными задачами для него считаются кластеризация и некоторые постановки задачи поиска аномалий. При таком раскладе истинные метки обучающих данных нам недоступны, но есть необходимость в поиске закономерностей. Иногда схожий подход применяют для предобучения сети в задаче обучения с учителем. Идея состоит в том, чтобы начальным приближением для весов было не случайное решение, а уже умеющее находить закономерности в данных.
Ну и третий вариант — обучение с подкреплением — стратегия, построенная на наблюдениях. Представьте себе мышь, бегущую по лабиринту. Если она повернет налево, то получит кусочек сыра, а если направо — удар током. Со временем мышь учится поворачивать только налево. Нейронная сеть действует точно так же, подстраивая веса, если итоговый результат — «болезненный». Обучение с подкреплением активно применяется в робототехнике: «ударился ли робот в стену или остался невредим?». Все задачи, имеющие отношение к играм, в том числе самая известная из них — AlphaGo, основаны именно на обучении с подкреплением.
Переобучение: в чем проблема и как ее решить
Главная проблема нейросетей — переобучение. Оно заключается в том, что сеть «запоминает» ответы вместо того, чтобы улавливать закономерности в данных. Наука поспособствовала появлению на свет нескольких методов борьбы с переобучением: сюда относятся, например, регуляризация, нормализация батчей, наращивание данных и другие. Иногда переобученная модель характеризуется большими абсолютными значениями весов.
Механизм этого явления примерно такой: исходные данные нередко сильно многомерны (одна точка из обучающей выборки изображается большим набором чисел), и вероятность того, что наугад взятая точка окажется неотличимой от выброса, будет тем больше, чем больше размерность. Вместо того, чтобы «вписывать» новую точку в имеющуюся модель, корректируя веса, нейросеть как будто придумывает сама себе исключение: эту точку мы классифицируем по одним правилам, а другие — по другим. И таких точек обычно много.
Очевидный способ борьбы с такого рода переобучением – регуляризация весов. Она состоит либо в искусственном ограничении на значения весов, либо в добавлении штрафа в меру ошибки на этапе обучения. Такой подход не решает проблему полностью, но чаще всего улучшает результат.
Второй способ основан на ограничении выходного сигнала, а не значений весов, — речь о нормализации батчей. На этапе обучения данные подаются нейросети пачками — батчами. Выходные значения для них могут быть какими угодно, и тем их абсолютные значения больше, чем выше значения весов. Если из каждого из них мы вычтем какое-то одно значение и поделим результат на другое, одинаково для всего батча, то мы сохраним качественные соотношения (максимальное, например, все равно останется максимальным), но выход будет более удобным для обработки его следующим слоем.
Третий подход работает не всегда. Как уже говорилось, переобученная нейросеть воспринимает многие точки как аномальные, которые хочется обрабатывать отдельно. Идея состоит в наращивании обучающей выборки, чтобы точки были как будто той же природы, что и исходная выборка, но сгенерированы искусственно. Однако тут сразу рождается большое число сопутствующих проблем: подбор параметров для наращивания выборки, критическое увеличение времени обучения и прочие.
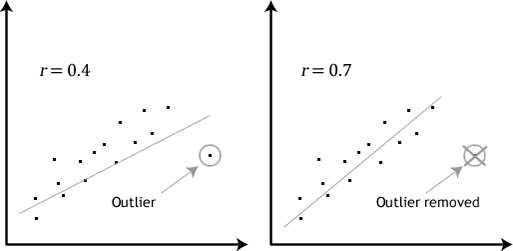
Эффект от удаления аномального значения из тренировочного свода данных (источник)
В обособленную проблему выделяется поиск настоящих аномалий в обучающей выборке. Иногда это даже рассматривают как отдельную задачу. Изображение выше демонстрирует эффект исключения аномального значения из набора. В случае нейронных сетей ситуация будет аналогичной. Правда, поиск и исключение таких значений — нетривиальная задача. Для этого применяются специальные техники — подробнее о них вы можете прочитать по ссылкам (здесь и здесь).
Одна сеть – одна задача или «проблема катастрофической забывчивости»
Работа в динамически изменяющихся средах (например, в финансовых) сложна для нейронных сетей. Даже если вам удалось успешно натренировать сеть, нет гарантий, что она не перестанет работать в будущем. Финансовые рынки постоянно трансформируются, поэтому то, что работало вчера, может с тем же успехом «сломаться» сегодня.
Здесь исследователям или приходится тестировать разнообразные архитектуры сетей и выбирать из них лучшую, или использовать динамические нейронные сети. Последние «следят» за изменениями среды и подстраивают свою архитектуру в соответствии с ними. Одним из используемых в этом случае алгоритмов является метод MSO (multi-swarm optimization).
Более того, нейросети обладают определенной особенностью, которую называют катастрофической забывчивостью (catastrophic forgetting). Она сводится к тому, что нейросеть нельзя последовательно обучить нескольким задачам — на каждой новой обучающей выборке все веса нейронов будут переписаны, и прошлый опыт будет «забыт».
Безусловно, ученые трудятся над решением и этой проблемы. Разработчики из DeepMind недавно предложили способ борьбы с катастрофической забывчивостью, который заключается в том, что наиболее важные веса в нейронной сети при выполнении некой задачи А искусственно делаются более устойчивыми к изменению в процессе обучения на задаче Б.
Новый подход получил название Elastic Weight Consolidation (упругое закрепление весов) из-за аналогии с упругой пружинкой. Технически он реализуется следующим образом: каждому весу в нейронной сети присваивается параметр F, который определяет его значимость только в рамках определенной задачи. Чем больше F для конкретного нейрона, тем сложнее будет изменить его вес при обучении новой задаче. Это позволяет сети «запоминать» ключевые навыки. Технология уступила «узкоспециализированным» сетям в отдельных задачах, но показала себя с лучшей стороны по сумме всех этапов.
Армированный черный ящик
Еще одна сложность работы с нейронными сетями состоит в том, что ИНС фактически являются черными ящиками. Строго говоря, кроме результата, из нейросети не вытащишь ничего, даже статистические данные. При этом сложно понять, как сеть принимает решения. Единственный пример, где это не так — сверточные нейронные сети в задачах распознавания. В этом случае некоторые промежуточные слои имеют смысл карт признаков (одна связь показывает то, встретился ли какой-то простой шаблон в исходной картинке), поэтому возбуждение различных нейронов можно отследить.
Разумеется, указанный нюанс делает достаточно сложным использование нейронных сетей в приложениях, когда ошибки критичны. Например, менеджеры фондов не могут понять, как нейронная сеть принимает решения. Это приводит к тому, что невозможно корректно оценить риски торговых стратегий. Аналогично банки, прибегающие к нейронным сетям для моделирования кредитных рисков, не смогут сказать, почему этот самый клиент имеет сейчас именно такой кредитный рейтинг.
Поэтому разработчики нейросетей ищут способы обойти это ограничение. Например, работа ведется над так называемыми алгоритмами изъятия правил (rule-extraction algorithms), чтобы повысить прозрачность архитектур. Эти алгоритмы извлекают информацию из нейросетей либо в виде математических выражений и символьной логики, либо в виде деревьев решений.
Нейронные сети — это лишь инструмент
Само собой, искусственные нейронные сети активно помогают осваивать новые технологии и развивать существующие. Сегодня на пике популярности находится программирование беспилотных автомобилей, в которых нейросети в режиме реального времени анализируют окружающую обстановку. IBM Watson из года в год открывает для себя всё новые прикладные области, включая медицину. В Google существует целое подразделение, которое занимается непосредственно искусственным интеллектом.
Вместе с тем порой нейронная есть — не лучший способ решить задачу. Например, сети «отстают» по таким направлениям, как создание изображений высокого разрешения, генерация человеческой речи и глубокий анализ видеопотоков. Работа с символами и рекурсивными структурами также даётся нейросистемам нелегко. Верно это и для вопросно-ответных систем.
Изначально идея нейронных сетей заключалась в копировании и даже воссоздании механизмов функционирования мозга. Однако человечеству по-прежнему нужно разрешить проблему скорости работы нейронных сетей, разработать новые алгоритмы логического вывода. Существующие алгоритмы по меньшей мере в 10 раз уступают возможностям мозга, что неудовлетворительно во многих ситуациях.
При этом ученые до сих пор не до конца определились, в каком направлении следует развивать нейросети. Индустрия старается как максимально приблизить нейросети к модели человеческого мозга, так и генерировать технологии и концептуальные схемы, абстрагируясь ото всех «аспектов человеческой природы». На сегодняшний день — это что-то вроде «открытого произведения» (если воспользоваться термином Умберто Эко), где практически любые опыты допустимы, а фантазии – приемлемы.
Деятельность ученых и разработчиков, занимающихся нейросетями, требует глубокой подготовки, обширных знаний, использования нестандартных методик, поскольку нейросеть сама по себе — это не «серебряная пуля», способная решить любые проблемы и задачи без участия человека. Это комплексный инструмент, который в умелых руках может делать удивительные вещи. И у него еще всё впереди.
Нейронные сети с нуля. Обзор курсов и статей на русском языке, бесплатно и без регистрации
На Хабре периодически появляются обзоры курсов по машинному обучению. Но такие статьи чаще добавляют в закладки, чем проходят сами курсы. Причины для этого разные: курсы на английском языке, требуют уверенного знания матана или специфичных фреймворков (либо наоборот не описаны начальные знания, необходимые для прохождения курса), находятся на других сайтах и требуют регистрации, имеют расписание, домашнюю работу и тяжело сочетаются с трудовыми буднями. Всё это мешает уже сейчас с нуля начать погружаться в мир машинного обучения со своей собственной скоростью, ровно до того уровня, который интересен и пропускать при этом неинтересные разделы.В этом обзоре в основном присутствуют только ссылки на статьи на хабре, а ссылки на другие ресурсы в качестве дополнения (информация на них на русском языке и не нужно регистрироваться). Все рекомендованные мною статьи и материалы я прочитал лично. Я попробовал каждый видеокурс, чтобы выбрать что понравится мне и помочь с выбором остальным. Большинство статей мною были прочитаны ранее, но есть и те на которые я наткнулся во время написания этого обзора.
Обзор состоит из нескольких разделов, чтобы каждый мог выбрать уровень с которого можно начать.
Для крупных разделов и видео-курсов указаны приблизительные временные затраты, необходимые знания, ожидаемые результаты и задания для самопроверки.
Большинство статей не было написано в рамках единого курса, поэтому информация может дублироваться. Если вы видите, что знаете какую-то часть статьи, то можете её смело пропустить, если вы не разорались с этой информацией в предыдущей статье, то у вас есть шанс прочитать тоже самое, но другими словами, что должно помочь усвоению материала.
Вводные статьи
Требуемый уровень: школьное образование, знание русского языка.
Требуемое время: несколько часов.
Казалось бы, что стоит начать изучение со статьи Искусственная нейронная сеть на википедии, но я не рекомендую. Наискучнейшее описание отбивает всё желание изучать нейронные сети.
Нейронки за 5 минут (слишком упрощённое описание, для гуманитариев, зато потребуется всего 5 минут)
Искусственные нейронные сети простыми словами (лучше потратить 15 минут на эту статью)
Основы ИНС (одна из четырёх статей из Учебник — Нейронные сети)
Нейронные сети для начинающих. Часть 1 и Часть 2
Нейронные сети, фундаментальные принципы работы, многообразие и топология
Искусственные нейронные сети и миниколонки реальной коры (девятая часть из курса Логика сознания)
Расширяем горизонты
Требуемый уровень: базовое понимание работы нейронных сетей.
Требуемое время: несколько часов.
Краткий курс машинного обучения или как создать нейронную сеть для решения скоринг задачи
Самое главное о нейронных сетях. Лекция в Яндексе (рекомендую посмотреть только видео на 1 час, читать статью показалось тяжеловато)
Введение в архитектуры нейронных сетей
Что такое свёрточная нейронная сеть
Свёрточная нейронная сеть, часть 1: структура, топология, функции активации и обучающее множество
Зоопарк архитектур нейронных сетей. Часть 1 и Часть 2 (Особо вчитываться не надо, достаточно посмотреть красивые картинки и прочитать описание по диагонали)
- типы задач, которые решают нейронные сети
- типы архитектур нейронных сетей
- функции активации
- типы нейронов / слоёв
Углубляем знания
Требуемый уровень: понимание работы нейронных сетей, знание базовых архитектур.
Требуемое время: несколько десятков часов.
Курс о Deep Learning на пальцах от АФТИ НГУ (14 видеороликов, 15 часов, будет познавательно)
Материалы открытого курса OpenDataScience и Mail.Ru Group по машинному обучению (10 видеороликов, 20 часов, будет сложно)
Лекции Техносферы. Нейронные сети в машинном обучении (14 видеороликов, 25 часов, будет скучно)
Чтобы определиться самому и помочь с выбором остальным хабровчанам, я построил график падения интереса к курсу на основе падения количества просмотров каждого следующего ролика. Выводы неутешительные — мало кто доходит до конца. Самый большой процент дошедших до конца — у курса от АФТИ НГУ.
(График падения количества просмотров составлялся пару месяцев назад и текущая картина может немного отличаться).
Примеры применения на практике
Сюда вошли в основном только те статьи, после которых прочитавшие их люди смогут сами воспроизвести описанные результаты (есть ссылки на исходники или онлайн сервисы)
ТОП30 самых впечатляющих проектов по машинному обучению за прошедший год (v.2018)
Улучшение качества изображения с помощью нейронной сети
Детектирование частей тела с помощью глубоких нейронных сетей
Классификация объектов в режиме реального времени
Раскрашиваем чёрно-белую фотографию с помощью нейросети
Смена пола и расы на селфи с помощью нейросетей
Как различать британскую и американскую литературу с помощью машинного обучения
Разделение текста на предложения с помощью Томита-парсера
WaveNet: новая модель для генерации человеческой речи и музыки
Анализ Корана при помощи AI
Сколько нужно нейронов, чтобы узнать, разведён ли мост Александра Невского?
Сколько котов на хабре?
Торговля знает, когда вы ждете ребенка
Стэнфордская нейросеть определяет тональность текста с точностью 85%
Топливо для ИИ: подборка открытых датасетов для машинного обучения
Другие материалы
Статьи и курсы, которые не вошли в мой обзор, но возможно вам понравятся.
Нейронные сети в картинках: от одного нейрона до глубоких архитектур (python, numpy)
Базовые принципы машинного обучения на примере линейной регрессии (python, numpy, матан)
Сверточная нейронная сеть, часть 2: обучение алгоритмом обратного распространения ошибки (матан)
Нейронные сети на stepik.org (в обзоре двухлетней давности его уже тогда называли устаревшим)
Курс по машинному обучению на Coursera от Яндекса и ВШЭ (курс доступен только после регистрации, NumPy, Pandas, Scikit-Learn)
Deep Learning For Coders (7 видеороликов, 15 часов, английский язык)
Курс Deep Learning от Google на udacity (английский язык)
Курс Структурирование проектов по машинному обучению на Coursera (платный, английский язык)
Другие статьи-обзоры на хабре по изучению машинного обучения
Где и как изучать машинное обучение? (английский язык)
Что читать о нейросетях 10 книг (английский язык)
Обучаемся самостоятельно: подборка видеокурсов по Computer Science (английский язык)
Обзор курсов по Deep Learning (английский язык)
10 курсов по машинному обучению на лето (английский/русский язык, платно/бесплатно)
Прочтение этих статей и подтолкнуло меня написать свою собственную, в которой были бы материалы только на русском языке, без регистрации и требования 5 лет матана.
Надеюсь, что у моей статьи будет меньше комментариев вида:
«Закинул в закладки. Смотреть я их, конечно, не буду.»
Прошу всех заинтересованных лиц ответить на опросы после статьи, ну и подписывайтесь, чтобы не пропустить мои следующие статьи, ставьте лайки, чтобы мотивировать меня на их написание и пишите в комментариях вопросы (опечатки лучше в личку).
Традиционное предупреждение: я не отвечаю на сообщения в личку/соцсетях/телеграмме и т.д. Если у вас есть вопрос, то задавайте его в комментариях.
Нейросети. Куда это все движется / Habr
Статья состоит из двух частей:
- Краткое описание некоторых архитектур сетей по обнаружению объектов на изображении и сегментации изображений с самыми понятными для меня ссылками на ресурсы. Старался выбирать видео пояснения и желательно на русском языке.
- Вторая часть состоит в попытке осознать направление развития архитектур нейронных сетей. И технологий на их основе.

Рисунок 1 – Понимать архитектуры нейросетей непросто
Все началось с того, что сделал два демонстрационных приложения по классификации и обнаружению объектов на телефоне Android:
- Back-end demo, когда данные обрабатываются на сервере и передаются на телефон. Классификация изображений (image classification) трех типов медведей: бурого, черного и плюшевого.
- Front-end demo, когда данные обрабатываются на самом телефоне. Обнаружение объектов (object detection) трех типов: фундук, инжир и финик.
Есть разница между задачами по классификации изображений, обнаружению объектов на изображении и сегментацией изображений. Поэтому появилась необходимость узнать, какие архитектуры нейросетей обнаруживают объекты на изображениях и какие могут сегментировать. Нашел следующие примеры архитектур с самыми понятными для меня ссылками на ресурсы:
- Серия архитектур на основе R-CNN (Regions with Convolution Neural Networks features): R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN. Для обнаружения объекта на изображении с помощью механизма Region Proposal Network (RPN) выделяются ограниченные регионы (bounding boxes). Первоначально вместо RPN применялся более медленный механизм Selective Search. Затем выделенные ограниченные регионы подаются на вход обычной нейросети для классификации. В архитектуре R-CNN есть явные циклы «for» перебора по ограниченным регионам, всего до 2000 прогонов через внутреннюю сеть AlexNet. Из-за явных циклов «for» замедляется скорость обработки изображений. Количество явных циклов, прогонов через внутреннюю нейросеть, уменьшается с каждой новой версией архитектуры, а также проводятся десятки других изменений для увеличения скорости и для замены задачи обнаружения объектов на сегментацию объектов в Mask R-CNN.
- YOLO (You Only Look Once) – первая нейронная сеть, которая распознавала объекты в реальном времени на мобильных устройствах. Отличительная особенность: различение объектов за один прогон (достаточно один раз посмотреть). То есть в архитектуре YOLO нет явных циклов «for», из-за чего сеть работает быстро. Например, такая аналогия: в NumPy при операциях с матрицами тоже нет явных циклов «for», которые в NumPy реализуются на более низких уровнях архитектуры через язык программирования С. YOLO использует сетку из заранее заданных окон. Чтобы один и тот же объект не определялся многократно, используется коэффициент перекрытия окон (IoU, Intersection over Union). Данная архитектура работает в широком диапазоне и обладает высокой робастностью: модель может быть обучена на фотографиях, но при этом хорошо работать на рисованных картинах.
- SSD (Single Shot MultiBox Detector) – используются наиболее удачные «хаки» архитектуры YOLO (например, non-maximum suppression) и добавляются новые, чтобы нейросеть быстрее и точнее работала. Отличительная особенность: различение объектов за один прогон с помощью заданной сетки окон (default box) на пирамиде изображений. Пирамида изображений закодирована в сверточных тензорах при последовательных операциях свертки и пулинга (при операции max-pooling пространственная размерность убывает). Таким образом определяются как большие, так и маленькие объекты за один прогон сети.
- MobileSSD (MobileNetV2 + SSD) – комбинация из двух архитектур нейросетей. Первая сеть MobileNetV2 работает быстро и увеличивает точность распознавания. MobileNetV2 применяется вместо VGG-16, которая первоначально использовалась в оригинальной статье. Вторая сеть SSD определяет местоположение объектов на изображении.
- SqueezeNet – очень маленькая, но точная нейросеть. Сама по себе не решает задачу обнаружения объектов. Однако может применяться при комбинации различных архитектур. И использоваться в мобильных устройствах. Отличительной особенностью является то, что сначала данные сжимаются до четырех 1×1 сверточных фильтров, а затем расширяются до четырех 1×1 и четырех 3×3 сверточных фильтров. Одна такая итерация сжатия-расширения данных называется «Fire Module».
- DeepLab (Semantic Image Segmentation with Deep Convolutional Nets) – сегментация объектов на изображении. Отличительной особенностью архитектуры является разряженная (dilated convolution) свертка, которая сохраняет пространственное разрешение. Затем следует стадия постобработки результатов с использованием графической вероятностной модели (conditional random field), что позволяет убрать небольшие шумы в сегментации и улучшить качество отсегментированного изображения. За грозным названием «графическая вероятностная модель» скрывается обычный фильтр Гаусса, который аппроксимирован по пяти точкам.
- Пытался разобраться в устройстве RefineDet (Single-Shot Refinement Neural Network for Object Detection), но мало чего понял.
- Также посмотрел, как работает технология «внимание» (attention): видео1, видео2, видео3. Отличительной особенностью архитектуры «внимание» является автоматическое выделение регионов повышенного внимания на изображении (RoI, Regions of Interest) с помощью нейросети под названием Attention Unit. Регионы повышенного внимания похожи на ограниченные регионы (bounding boxes), но в отличие от них не зафиксированы на изображении и могут иметь размытые границы. Затем из регионов повышенного внимания выделяются признаки (фичи), которые «скармливаются» рекуррентным нейросетям с архитектурами LSDM, GRU или Vanilla RNN. Рекуррентные нейросети умеют анализировать взаимоотношение признаков в последовательности. Рекуррентные нейросети изначально применялись для переводов текста на другие языки, а теперь и для перевода изображения в текст и текста в изображение.
По мере изучения этих архитектур я понял, что ничего не понимаю. И дело не в том, что у моей нейросети есть проблемы с механизмом внимания. Создание всех этих архитектур похоже на какой-то огромный хакатон, где авторы соревнуются в хаках. Хак (hack) – быстрое решение трудной программной задачи. То есть между всеми этими архитектурами нет видимой и понятной логической связи. Все, что их объединяет – это набор наиболее удачных хаков, которые они заимствуют друг у друга, плюс общая для всех операция свертки с обратной связью (обратное распространение ошибки, backpropagation). Нет системного мышления! Не понятно, что менять и как оптимизировать имеющиеся достижения.
Как результат отсутствия логической связи между хаками, их чрезвычайно трудно запомнить и применить на практике. Это фрагментированные знания. В лучшем случае запоминаются несколько интересных и неожиданных моментов, но большинство из понятого и непонятного исчезает из памяти уже через несколько дней. Будет хорошо, если через неделю вспомнится хотя бы название архитектуры. А ведь на чтение статей и просмотр обзорных видео было потрачено несколько часов и даже дней рабочего времени!
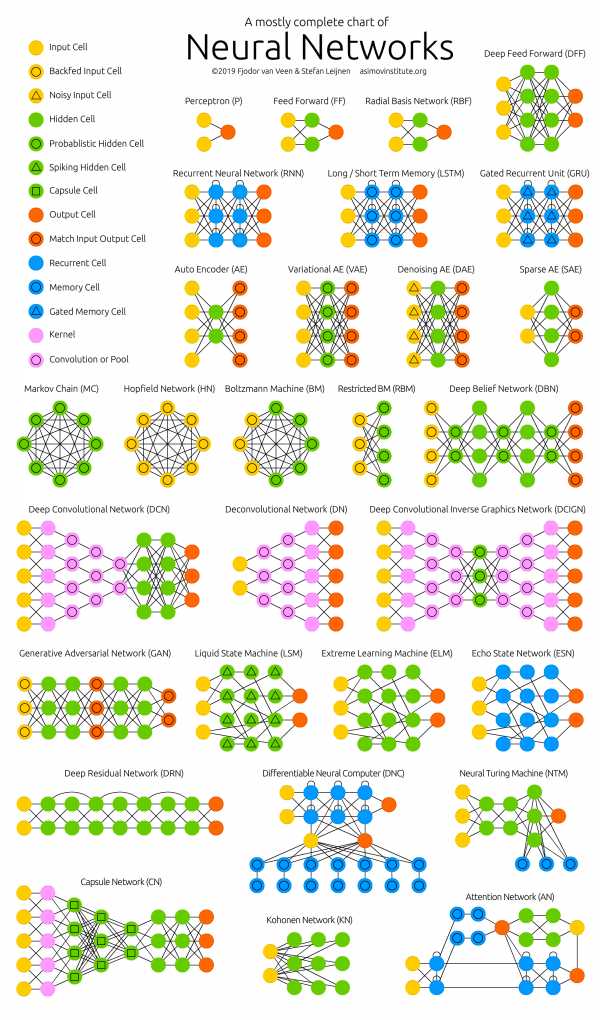
Рисунок 2 – Зоопарк нейронных сетей
Большинство авторов научных статей, по моему личному мнению, делают все возможное, чтобы даже эти фрагментированные знания были не поняты читателем. Но деепричастные обороты в десяти строковых предложениях с формулами, которые взяты «с потолка» – это тема для отдельной статьи (проблема publish or perish).
По этой причине появилась необходимость систематизировать информацию по нейросетям и, таким образом, увеличить качество понимания и запоминания. Поэтому основной темой разбора отдельных технологий и архитектур искусственных нейронных сетей стала следующая задача: узнать, куда это все движется, а не устройство какой-то конкретной нейросети в отдельности.
Куда все это движется. Основные результаты:
- Число стартапов в области машинного обучения в последние два года резко упало. Возможная причина: «нейронные сети перестали быть чем-то новым».
- Каждый сможет создать работающую нейросеть для решения простой задачи. Для этого возьмет готовую модель из «зоопарка моделей» (model zoo) и натренирует последний слой нейросети (transfer learning) на готовых данных из Google Dataset Search или из 25-ти тысяч датасетов Kaggle в бесплатном облаке Jupyter Notebook.
- Крупные производители нейросетей начали создавать «зоопарки моделей» (model zoo). С помощью них можно быстро сделать коммерческое приложение: TF Hub для TensorFlow, MMDetection для PyTorch, Detectron для Caffe2, chainer-modelzoo для Chainer и другие.
- Нейросети, работающие в реальном времени (real-time) на мобильных устройствах. От 10 до 50 кадров в секунду.
- Применение нейросетей в телефонах (TF Lite), в браузерах (TF.js) и в бытовых предметах (IoT, Internet of Things). Особенно в телефонах, которые уже поддерживают нейросети на уровне «железа» (нейроакселераторы).
- «Каждое устройство, предметы одежды и, возможно, даже пища будут иметь IP-v6 адрес и сообщаться между собой» – Себастьян Трун.
- Рост количества публикаций по машинному обучению начал превышать закон Мура (удвоение каждые два года) с 2015 года. Очевидно, нужны нейросети по анализу статей.
- Набирают популярность следующие технологии:
- PyTorch – популярность растет стремительно и, похоже, обгоняет TensorFlow.
- Автоматический подбор гиперпараметров AutoML – популярность растет плавно.
- Постепенное уменьшение точности и увеличение скорости вычислений: нечеткая логика, алгоритмы бустинга, неточные (приближенные) вычисления, квантизация (когда веса нейросети переводятся в целые числа и квантуются), нейроакселераторы.
- Перевод изображения в текст и текста в изображение.
- Создание трехмерных объектов по видео, теперь уже в реальном времени.
- Основное в DL – это много данных, но собрать и разметить их непросто. Поэтому развивается автоматизация разметки (automated annotation) для нейросетей с помощью нейросетей.
- С нейросетями Computer Science внезапно стала экспериментальной наукой и возник кризис воспроизводимости.
- ИТ-деньги и популярность нейросетей возникли одновременно, когда вычисления стали рыночной ценностью. Экономика из золотовалютной становится золото-валютно-вычислительной. Смотрите мою статью по эконофизике и причине появления IT-денег.
Постепенно появляется новая методология программирования ML/DL (Machine Learning & Deep Learning), которая основана на представлении программы, как совокупности обученных нейросетевых моделей.
Рисунок 3 – ML/DL как новая методология программирования
Однако так и не появилось «теории нейросетей», в рамках которой можно думать и работать системно. Что сейчас называется «теорией» на самом деле экспериментальные, эвристические алгоритмы.
Ссылки на мои и не только ресурсы:
Спасибо за внимание!
Пощупать нейросети или конструктор нейронных сетей / Habr
Я давно интересовался нейросетями, но только с позиции зрителя – следил за новыми возможностями, которые они дают по сравнению с обычным программированием. Но никогда не лез ни в теорию, ни в практику. И вдруг (после сенсационной новости о AlphaZero) мне захотелось сделать свою нейросеть. Посмотрев несколько уроков по этой теме на YouTube, я немного врубился в теорию и перешёл к практике. В итоге я сделал даже лучше, чем свою нейросеть. Получился конструктор нейросетей и наглядное пособие по ним (то есть можно смотреть, что творится внутри нейросети). Вот как это выглядит:
А теперь немного подробнее. С помощью этого конструктора можно создавать сети прямого распространения (Feedforward neural network) до 8 скрытых слоёв (плюс слой входов и слой выходов, итого 10 слоёв (обычно 4-х слоёв более чем достаточно)) в каждом слое до 30 нейронов (ограничение связано с тем, что всё это одновременно отображается на экране, если будут просьбы в комментариях выпущу версию без ограничений и визуализации). Функция активации всех нейронов – сигмоид на основе логистической функции. Также можно обучать получившиеся сети методом обратного распространения ошибки градиентным спуском по заданным примерам. И, самое главное, можно посмотреть на каждый нейрон в каждом отдельном случае (какое значение он передаёт дальше, его смещение (поправку, bias) – нейроны с отрицательным смещением белые, с положительным – ярко-зелёные), связи нейронов в зависимости от их веса помечены красным – положительные, синим – отрицательные, а также отличаются по толщине – чем больше модуль веса, тем толще. А если навести мышку на нейрон, то можно ещё посмотреть какой сигнал на него приходит, и какое конкретно у него смещение. Это полезно, чтобы понять, как работает конкретная сеть или показать студентам принцип работы сетей прямого распространения. Но самое главное – свою сеть можно сохранить в файл и поделиться с миром.
Далее будут инструкции по пользованию программой, встраиванию созданных сетей в свои проекты, а также разбор нескольких сетей, идущих в комплекте.
Как пользоваться конструктором
Для начала скачайте архив отсюда.
(Добавил в архив исходники, удалил сеть 4-5, теперь точно нет вирусов нигде)
Распакуйте в корень диска D:\
(Если нет D:\ отключите в диспетчере устройств дисковод, в Управление дисками создайте виртуальный D:\ — инициализируйте, создайте том)
Запустите NeuroNet.exe
Можете попробовать «Загрузить» какую-нибудь сеть, посмотреть на неё, нажать «Обучение», увидеть её точность, потыкать стрелки влево, вправо (по бокам), чтобы посмотреть различные варианты входных (левый столбец нейронов) и выходных (правый) данных, нажать «Стоп» и попробовать ввести свои входные данные (разрешены любые значения от 0 до 1, учитывайте это при создании своих сетей и нормализуйте входные и выходные данные).
Теперь как строить свои сети. Первым делом необходимо задать архитектуру сети (количество нейронов в каждом слое через запятую), нажать «Построить» (или сначала «Снести», затем построить, если у Вас на экране уже отображается другая сеть), нажать «Обучающая выборка», «Удалить всё» и ввести свои обучающие примеры, согласно инструкции на экране.
Например, если входные данные — это два нейрона со значениями 0.25(используем точку вместо запятой) и 0, а выходные — 1 и 0.01(все значения нормализуем от 0 до 1), то обучающий пример будет «0.25,0,1,0.01»
Также можно указать на вход и на выход маленькие квадратные картинки (максимум 5х5 пикселей), из которых будут определены нормализованные значения яркости пикселей (не учитывая их цвет), для чего нужно нажать на «in» и «out» соответственно. Нажать «Добавить пример», повторить процедуру нужное количество раз. Нажать «Готово», «Обучение» и как точность станет удовлетворительной (обычно 98%), нажать «Стоп», иконку в виде дискеты (сохранить), дать сети имя и радоваться, что Вы сами создали нейросеть. Дополнительно можете устанавливать скорость обучения ползунком «Точнее/Быстрее», а также визуализировать не каждый 50й шаг, а каждый 10й или 300й, как Вам угодно.
Интеграция созданных сетей в свои проекты
Чтобы использовать свои нейросети в собственных проектах, я создал отдельное приложение
doNet.exe, которое нужно запускать с параметрами: «D:\NeuroNet\doNet.exe <название сети> <входные данные через пробел>», дождаться завершения работы приложения, после чего считать выходные данные из D:\NeuroNet\temp.txtДля примера создано приложение 4-5.exe, использующее сеть «4-5» (об этой и других сетях ниже). В этом приложении подробно расписано как правильно запускать doNet.exe
Разбор сетей, идущих в комплекте
Начнём с классики – «XOR(Полусумматор)». Среди прочих, в частности, эту задачу – сложение по модулю 2 – в 1969 году приводили в качестве примера ограниченности нейросетей (а именно однослойных перцептронов). В общем, имеется два входа (со значениями либо 0, либо 1 у каждого), наша же задача — ответить 1, если значения входов разные, 0 – если одинаковые.
Далее «Количество-единиц». Три входа (0 либо 1 на каждом). Требуется посчитать, сколько было подано единиц. Реализовано как задача классификации – четыре выхода на каждый вариант ответа (0,1,2,3 единицы). На каком выходе максимальное значение, соответственно таков и ответ.
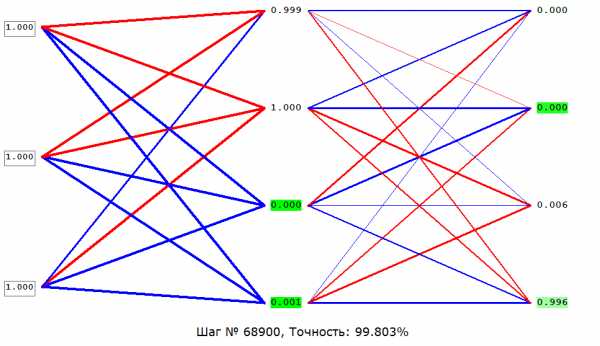
«Умножение» – Два входа (вещественные от 0 до 1), на выход их произведение.
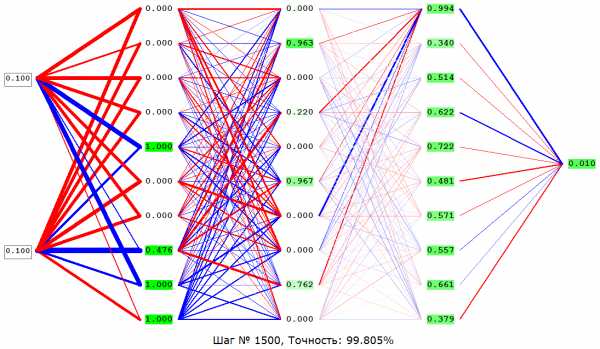
«4-5» – На вход подаются нормализованные значения яркости пикселей картинки 4х4, на выходе имеем нормализованные значения яркости пикселей картинки 5х5.
Сеть задумывалась, как увеличение качества большой картинки на 25%, вышел же интересный фильтр для фото:
UPD: В архив добавлено приложение NeuroNet2.exe (тот же конструктор, но без визуализации (благодаря чему работает в 2 раза быстрее) и ограничений на количество нейронов в слое (до 1024 вместо 30), также в обучающей выборке на вход и выход можно подавать квадратные картинки до 32х32). Также добавлен график обучения. Ускорена загрузка и в обучающую выборку можно закладывать большой объём данных.
Нейросетями теперь могут пользоваться (и встраивать в свои проекты (даже на сервере)) и те, кто не знает их теории! В полуавтоматическом режиме (после обучения вручную подавать на вход значения и получать результат на экране) их можно использовать даже без знания программирования!
Вот собственно и всё, жду комментариев.
P.S. Если вылезает ошибка, попробуйте зарегистрировать от администратора с помощью regsvr32 файлы comdlg32, которые также есть в архиве.
3. Основы ИНС – Нейронные сети
В предыдущей главе мы ознакомились с такими понятиями, как искусственный интеллект, машинное обучение и искусственные нейронные сети.
В этой главе я детально опишу модель искусственного нейрона, расскажу о подходах к обучению сети, а также опишу некоторые известные виды искусственных нейронных сетей, которые мы будем изучать в следующих главах.
Упрощение
В прошлой главе я постоянно говорил о каких-то серьезных упрощениях. Причина упрощений заключается в том, что никакие современные компьютеры не могут быстро моделировать такие сложные системы, как наш мозг. К тому же, как я уже говорил, наш мозг переполнен различными биологическими механизмами, не относящиеся к обработке информации.
Нам нужна модель преобразования входного сигнала в нужный нам выходной. Все остальное нас не волнует. Начинаем упрощать.
Биологическая структура → схема
В предыдущей главе вы поняли, насколько сложно устроены биологические нейронные сети и биологические нейроны. Вместо изображения нейронов в виде чудовищ с щупальцами давайте просто будем рисовать схемы.
Вообще говоря, есть несколько способов графического изображения нейронных сетей и нейронов. Здесь мы будем изображать искусственные нейроны в виде кружков.
Вместо сложного переплетения входов и выходов будем использовать стрелки, обозначающие направление движения сигнала.
Таким образом искусственная нейронная сеть может быть представлена в виде совокупности кружков (искусственных нейронов), связанных стрелками.
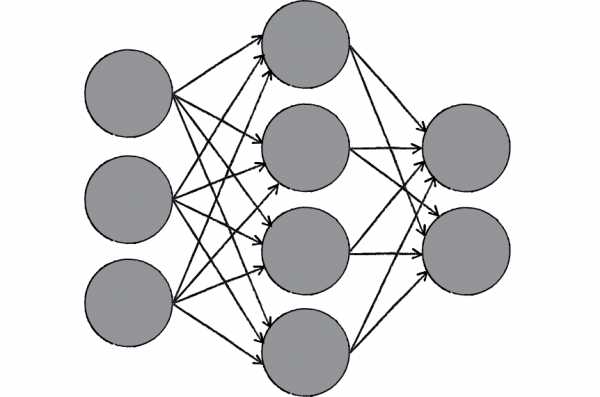
Электрические сигналы → числа
В реальной биологической нейронной сети от входов сети к выходам передается электрический сигнал. В процессе прохода по нейронной сети он может изменяться.

Электрический сигнал всегда будет электрическим сигналом. Концептуально ничего не изменяется. Но что же тогда меняется? Меняется величина этого электрического сигнала (сильнее/слабее). А любую величину всегда можно выразить числом (больше/меньше).
В нашей модели искусственной нейронной сети нам совершенно не нужно реализовывать поведение электрического сигнала, так как от его реализации все равно ничего зависеть не будет.
На входы сети мы будем подавать какие-то числа, символизирующие величины электрического сигнала, если бы он был. Эти числа будут продвигаться по сети и каким-то образом меняться. На выходе сети мы получим какое-то результирующее число, являющееся откликом сети.
Для удобства все равно будем называть наши числа, циркулирующие в сети, сигналами.
Синапсы → веса связей
Вспомним картинку из первой главы, на которой цветом были изображены связи между нейронами – синапсы. Синапсы могут усиливать или ослаблять проходящий по ним электрический сигнал.
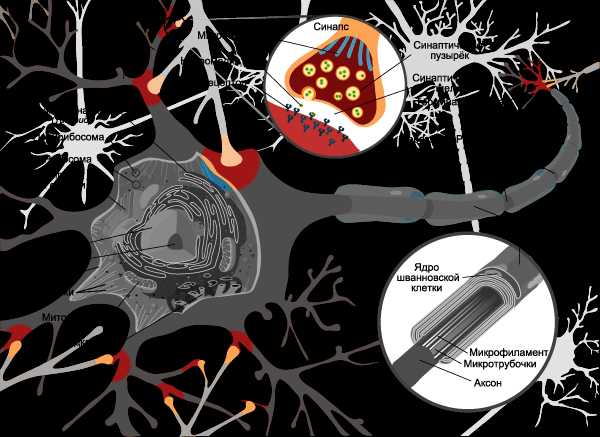
Давайте характеризовать каждую такую связь определенным числом, называемым весом данной связи. Сигнал, прошедший через данную связь, умножается на вес соответствующей связи.
Это ключевой момент в концепции искусственных нейронных сетей, я объясню его подробнее. Посмотрите на картинку ниже. Теперь каждой черной стрелке (связи) на этой картинке соответствует некоторое число \( w_i \) (вес связи). И когда сигнал проходит по этой связи, его величина умножается на вес этой связи.
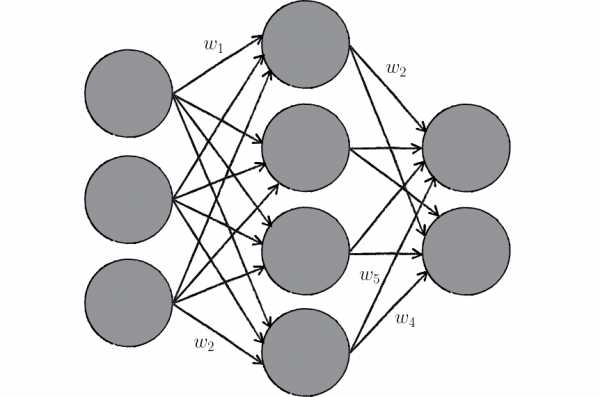
На приведенном выше рисунке вес стоит не у каждой связи лишь потому, что там нет места для обозначений. В реальности у каждой \( i \)-ой связи свой собственный \( w_i \)-ый вес.
Искусственный нейрон
Теперь мы переходим к рассмотрению внутренней структуры искусственного нейрона и того, как он преобразует поступающий на его входы сигнал.
На рисунке ниже представлена полная модель искусственного нейрона.

Не пугайтесь, ничего сложного здесь нет. Давайте рассмотрим все подробно слева направо.
Входы, веса и сумматор
У каждого нейрона, в том числе и у искусственного, должны быть какие-то входы, через которые он принимает сигнал. Мы уже вводили понятие весов, на которые умножаются сигналы, проходящие по связи. На картинке выше веса изображены кружками.
Поступившие на входы сигналы умножаются на свои веса. Сигнал первого входа \( x_1 \) умножается на соответствующий этому входу вес \( w_1 \). В итоге получаем \( x_1w_1 \). И так до \( n \)-ого входа. В итоге на последнем входе получаем \( x_nw_n \).
Теперь все произведения передаются в сумматор. Уже исходя из его названия можно понять, что он делает. Он просто суммирует все входные сигналы, умноженные на соответствующие веса:
\[ x_1w_1+x_2w_2+\cdots+x_nw_n = \sum\limits^n_{i=1}x_iw_i \]
Математическая справка
Сигма – ВикипедияКогда необходимо коротко записать большое выражение, состоящее из суммы повторяющихся/однотипных членов, то используют знак сигмы.
Рассмотрим простейший вариант записи:
\[ \sum\limits^5_{i=1}i=1+2+3+4+5 \]
Таким образом снизу сигмы мы присваиваем переменной-счетчику \( i \) стартовое значение, которое будет увеличиваться, пока не дойдет до верхней границы (в примере выше это 5).
Верхняя граница может быть и переменной. Приведу пример такого случая.
Пусть у нас есть \( n \) магазинов. У каждого магазина есть свой номер: от 1 до \( n \). Каждый магазин приносит прибыль. Возьмем какой-то (неважно, какой) \( i \)-ый магазин. Прибыль от него равна \( p_i \).
Если мы хотим посчитать общую прибыль от всех магазинов (обозначим ее за \( P \)), то нам пришлось бы писать длинную сумму:
\[ P = p_1+p_2+\cdots+p_i+\cdots+p_n \]
Как видно, все члены этой суммы однотипны. Тогда их можно коротко записать следующим образом:
\[ P=\sum\limits^n_{i=1}p_i \]
Словами: «Просуммируй прибыли всех магазинов, начиная с первого и заканчивая \( n \)-ым». В виде формулы это гораздо проще, удобнее и красивее.
Результатом работы сумматора является число, называемое взвешенной суммой.
Взвешенная сумма (Weighted sum) (\( net \)) — сумма входных сигналов, умноженных на соответствующие им веса.\[ net=\sum\limits^n_{i=1}x_iw_i \]
Роль сумматора очевидна – он агрегирует все входные сигналы (которых может быть много) в какое-то одно число – взвешенную сумму, которая характеризует поступивший на нейрон сигнал в целом. Еще взвешенную сумму можно представить как степень общего возбуждения нейрона.
Пример
Для понимания роли последнего компонента искусственного нейрона – функции активации – я приведу аналогию.
Давайте рассмотрим один искусственный нейрон. Его задача – решить, ехать ли отдыхать на море. Для этого на его входы мы подаем различные данные. Пусть у нашего нейрона будет 4 входа:
- Стоимость поездки
- Какая на море погода
- Текущая обстановка с работой
- Будет ли на пляже закусочная
Все эти параметры будем характеризовать 0 или 1. Соответственно, если погода на море хорошая, то на этот вход подаем 1. И так со всеми остальными параметрами.
Если у нейрона есть четыре входа, то должно быть и четыре весовых коэффициента. В нашем примере весовые коэффициенты можно представить как показатели важности каждого входа, влияющие на общее решение нейрона. Веса входов распределим следующим образом:
- 5
- 4
- 1
- 1
Нетрудно заметить, что очень большую роль играют факторы стоимости и погоды на море (первые два входа). Они же и будут играть решающую роль при принятии нейроном решения.
Пусть на входы нашего нейрона мы подаем следующие сигналы:
- 1
- 0
- 0
- 1
Умножаем веса входов на сигналы соответствующих входов:
- 5
- 0
- 0
- 1
Взвешенная сумма для такого набора входных сигналов равна 6:
\[ net=\sum\limits^4_{i=1}x_iw_i = 5 + 0 + 0 + 1 =6 \]
Все классно, но что делать дальше? Как нейрон должен решить, ехать на море или нет? Очевидно, нам нужно как-то преобразовать нашу взвешенную сумму и получить ответ.
Вот на сцену выходит функция активации.
Функция активации
Просто так подавать взвешенную сумму на выход достаточно бессмысленно. Нейрон должен как-то обработать ее и сформировать адекватный выходной сигнал. Именно для этих целей и используют функцию активации.
Она преобразует взвешенную сумму в какое-то число, которое и является выходом нейрона (выход нейрона обозначим переменной \( out \)).
Для разных типов искусственных нейронов используют самые разные функции активации. В общем случае их обозначают символом \( \phi(net) \). Указание взвешенного сигнала в скобках означает, что функция активации принимает взвешенную сумму как параметр.
Функция активации (Activation function) (\( \phi(net) \)) — функция, принимающая взвешенную сумму как аргумент. Значение этой функции и является выходом нейрона (\( out \)).\[ out=\phi(net) \]
Далее мы подробно рассмотрим самые известные функции активации.
Функция единичного скачка
Самый простой вид функции активации. Выход нейрона может быть равен только 0 или 1. Если взвешенная сумма больше определенного порога \( b \), то выход нейрона равен 1. Если ниже, то 0.
Как ее можно использовать? Предположим, что мы поедем на море только тогда, когда взвешенная сумма больше или равна 5. Значит наш порог равен 5:
\[ b=5 \]
В нашем примере взвешенная сумма равнялась 6, а значит выходной сигнал нашего нейрона равен 1. Итак, мы едем на море.
Однако если бы погода на море была бы плохой, а также поездка была бы очень дорогой, но имелась бы закусочная и обстановка с работой нормальная (входы: 0011), то взвешенная сумма равнялась бы 2, а значит выход нейрона равнялся бы 0. Итак, мы никуда не едем.
В общем, нейрон смотрит на взвешенную сумму и если она получается больше его порога, то нейрон выдает выходной сигнал, равный 1.
Графически эту функцию активации можно изобразить следующим образом.
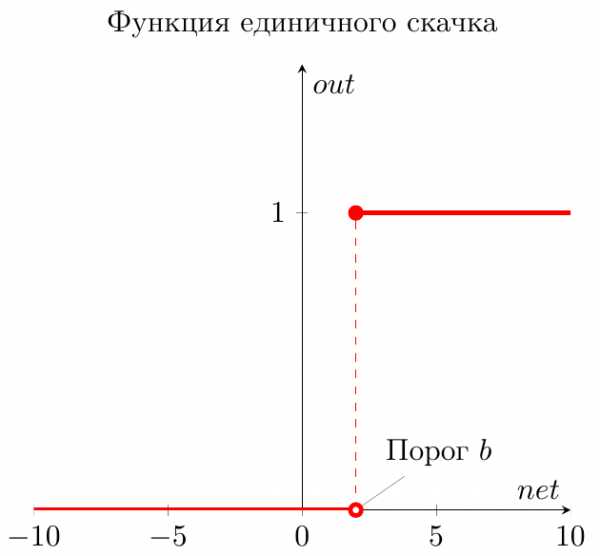
На горизонтальной оси расположены величины взвешенной суммы. На вертикальной оси — значения выходного сигнала. Как легко видеть, возможны только два значения выходного сигнала: 0 или 1. Причем 0 будет выдаваться всегда от минус бесконечности и вплоть до некоторого значения взвешенной суммы, называемого порогом. Если взвешенная сумма равна порогу или больше него, то функция выдает 1. Все предельно просто.
Теперь запишем эту функцию активации математически. Почти наверняка вы сталкивались с таким понятием, как составная функция. Это когда мы под одной функцией объединяем несколько правил, по которым рассчитывается ее значение. В виде составной функции функция единичного скачка будет выглядеть следующим образом:
\[ out(net) = \begin{cases} 0, net < b \\ 1, net \geq b \end{cases} \]
В этой записи нет ничего сложного. Выход нейрона (\( out \)) зависит от взвешенной суммы (\( net \)) следующим образом: если \( net \) (взвешенная сумма) меньше какого-то порога (\( b \)), то \( out \) (выход нейрона) равен 0. А если \( net \) больше или равен порогу \( b \), то \( out \) равен 1.
Сигмоидальная функция
На самом деле существует целое семейство сигмоидальных функций, некоторые из которых применяют в качестве функции активации в искусственных нейронах.
Все эти функции обладают некоторыми очень полезными свойствами, ради которых их и применяют в нейронных сетях. Эти свойства станут очевидными после того, как вы увидите графики этих функций.
Итак… самая часто используемая в нейронных сетях сигмоида — логистическая функция.
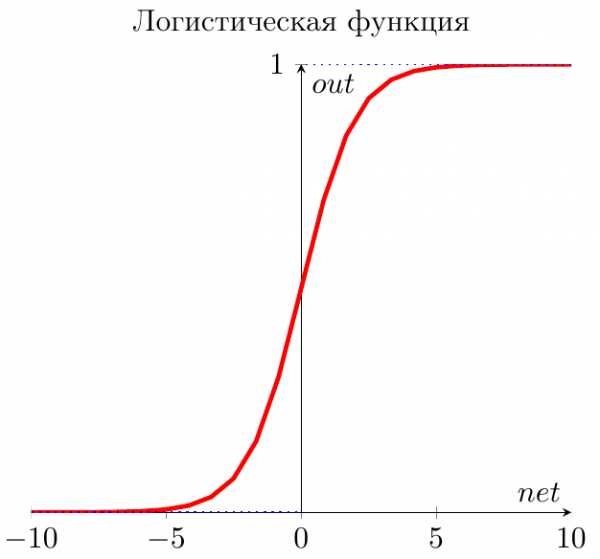
График этой функции выглядит достаточно просто. Если присмотреться, то можно увидеть некоторое подобие английской буквы \( S \), откуда и пошло название семейства этих функций.
А вот так она записывается аналитически:
\[ out(net)=\frac{1}{1+\exp(-a \cdot net)} \]
Что за параметр \( a \)? Это какое-то число, которое характеризует степень крутизны функции. Ниже представлены логистические функции с разным параметром \( a \).
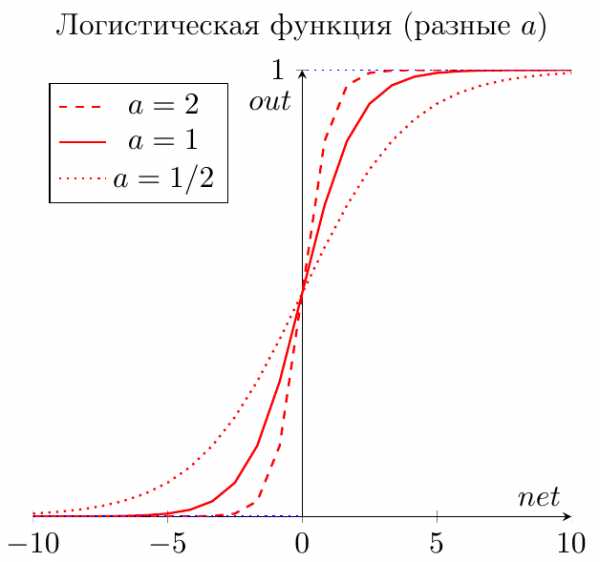
Вспомним наш искусственный нейрон, определяющий, надо ли ехать на море. В случае с функцией единичного скачка все было очевидно. Мы либо едем на море (1), либо нет (0).
Здесь же случай более приближенный к реальности. Мы до конца полностью не уверены (в особенности, если вы параноик) – стоит ли ехать? Тогда использование логистической функции в качестве функции активации приведет к тому, что вы будете получать цифру между 0 и 1. Причем чем больше взвешенная сумма, тем ближе выход будет к 1 (но никогда не будет точно ей равен). И наоборот, чем меньше взвешенная сумма, тем ближе выход нейрона будет к 0.
Например, выход нашего нейрона равен 0.8. Это значит, что он считает, что поехать на море все-таки стоит. Если бы его выход был бы равен 0.2, то это означает, что он почти наверняка против поездки на море.
Какие же замечательные свойства имеет логистическая функция?
- она является «сжимающей» функцией, то есть вне зависимости от аргумента (взвешенной суммы), выходной сигнал всегда будет в пределах от 0 до 1
- она более гибкая, чем функция единичного скачка – ее результатом может быть не только 0 и 1, но и любое число между ними
- во всех точках она имеет производную, и эта производная может быть выражена через эту же функцию
Именно из-за этих свойств логистическая функция чаще всего используются в качестве функции активации в искусственных нейронах.
Гиперболический тангенс
Однако есть и еще одна сигмоида – гиперболический тангенс. Он применяется в качестве функции активации биологами для более реалистичной модели нервной клетки.
Такая функция позволяет получить на выходе значения разных знаков (например, от -1 до 1), что может быть полезным для ряда сетей.
Функция записывается следующим образом:
\[ out(net) = \tanh\left(\frac{net}{a}\right) \]
В данной выше формуле параметр \( a \) также определяет степень крутизны графика этой функции.
А вот так выглядит график этой функции.
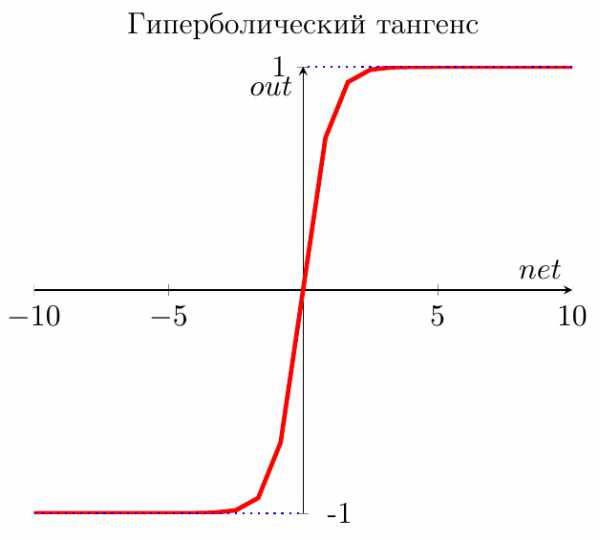
Как видите, он похож на график логистической функции. Гиперболический тангенс обладает всеми полезными свойствами, которые имеет и логистическая функция.
Что мы узнали?
Теперь вы получили полное представление о внутренней структуре искусственного нейрона. Я еще раз приведу краткое описание его работы.
У нейрона есть входы. На них подаются сигналы в виде чисел. Каждый вход имеет свой вес (тоже число). Сигналы на входе умножаются на соответствующие веса. Получаем набор «взвешенных» входных сигналов.
Далее этот набор попадает в сумматор, которой просто складывает все входные сигналы, помноженные на веса. Получившееся число называют взвешенной суммой.
Затем взвешенная сумма преобразуется функцией активации и мы получаем выход нейрона.
Сформулируем теперь самое короткое описание работы нейрона – его математическую модель:
Математическая модель искусственного нейрона с \( n \) входами:\[ out=\phi\left(\sum\limits^n_{i=1}x_iw_i\right) \]
где
\( \phi \) – функция активации
\( \sum\limits^n_{i=1}x_iw_i \) – взвешенная сумма, как сумма \( n \) произведений входных сигналов на соответствующие веса.
Виды ИНС
Мы разобрались со структурой искусственного нейрона. Искусственные нейронные сети состоят из совокупности искусственных нейронов. Возникает логичный вопрос – а как располагать/соединять друг с другом эти самые искусственные нейроны?
Как правило, в большинстве нейронных сетей есть так называемый входной слой, который выполняет только одну задачу – распределение входных сигналов остальным нейронам. Нейроны этого слоя не производят никаких вычислений.
А дальше начинаются различия…
Однослойные нейронные сети
В однослойных нейронных сетях сигналы с входного слоя сразу подаются на выходной слой. Он производит необходимые вычисления, результаты которых сразу подаются на выходы.
Выглядит однослойная нейронная сеть следующим образом:
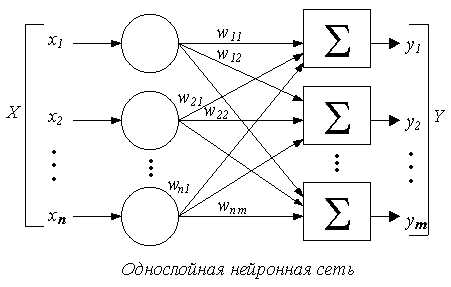
На этой картинке входной слой обозначен кружками (он не считается за слой нейронной сети), а справа расположен слой обычных нейронов.
Нейроны соединены друг с другом стрелками. Над стрелками расположены веса соответствующих связей (весовые коэффициенты).
Однослойная нейронная сеть (Single-layer neural network) — сеть, в которой сигналы от входного слоя сразу подаются на выходной слой, который и преобразует сигнал и сразу же выдает ответ.
Многослойные нейронные сети
Такие сети, помимо входного и выходного слоев нейронов, характеризуются еще и скрытым слоем (слоями). Понять их расположение просто – эти слои находятся между входным и выходным слоями.

Такая структура нейронных сетей копирует многослойную структуру определенных отделов мозга.
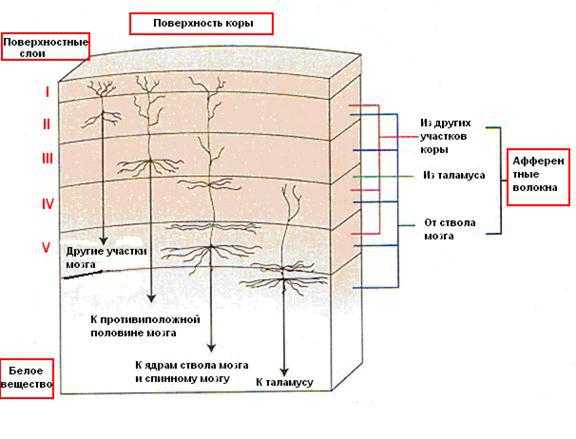
Название скрытый слой получил неслучайно. Дело в том, что только относительно недавно были разработаны методы обучения нейронов скрытого слоя. До этого обходились только однослойными нейросетями.
Многослойные нейронные сети обладают гораздо большими возможностями, чем однослойные.
Работу скрытых слоев нейронов можно сравнить с работой большого завода. Продукт (выходной сигнал) на заводе собирается по стадиям. После каждого станка получается какой-то промежуточный результат. Скрытые слои тоже преобразуют входные сигналы в некоторые промежуточные результаты.
Многослойная нейронная сеть (Multilayer neural network) — нейронная сеть, состоящая из входного, выходного и расположенного(ых) между ними одного (нескольких) скрытых слоев нейронов.
Сети прямого распространения
Можно заметить одну очень интересную деталь на картинках нейросетей в примерах выше.
Во всех примерах стрелки строго идут слева направо, то есть сигнал в таких сетях идет строго от входного слоя к выходному.
Сети прямого распространения (Feedforward neural network) (feedforward сети) — искусственные нейронные сети, в которых сигнал распространяется строго от входного слоя к выходному. В обратном направлении сигнал не распространяется.
Такие сети широко используются и вполне успешно решают определенный класс задач: прогнозирование, кластеризация и распознавание.
Однако никто не запрещает сигналу идти и в обратную сторону.
Сети с обратными связями
В сетях такого типа сигнал может идти и в обратную сторону. В чем преимущество?
Дело в том, что в сетях прямого распространения выход сети определяется входным сигналом и весовыми коэффициентами при искусственных нейронах.
А в сетях с обратными связями выходы нейронов могут возвращаться на входы. Это означает, что выход какого-нибудь нейрона определяется не только его весами и входным сигналом, но еще и предыдущими выходами (так как они снова вернулись на входы).
Возможность сигналов циркулировать в сети открывает новые, удивительные возможности нейронных сетей. С помощью таких сетей можно создавать нейросети, восстанавливающие или дополняющие сигналы. Другими словами такие нейросети имеют свойства кратковременной памяти (как у человека).
Сети с обратными связями (Recurrent neural network) — искусственные нейронные сети, в которых выход нейрона может вновь подаваться на его вход. В более общем случае это означает возможность распространения сигнала от выходов к входам.
Обучение нейронной сети
Теперь давайте чуть более подробно рассмотрим вопрос обучения нейронной сети. Что это такое? И каким образом это происходит?
Что такое обучение сети?
Искусственная нейронная сеть – это совокупность искусственных нейронов. Теперь давайте возьмем, например, 100 нейронов и соединим их друг с другом. Ясно, что при подаче сигнала на вход, мы получим что-то бессмысленное на выходе.
Значит нам надо менять какие-то параметры сети до тех пор, пока входной сигнал не преобразуется в нужный нам выходной.
Что мы можем менять в нейронной сети?
Изменять общее количество искусственных нейронов бессмысленно по двум причинам. Во-первых, увеличение количества вычислительных элементов в целом лишь делает систему тяжеловеснее и избыточнее. Во-вторых, если вы соберете 1000 дураков вместо 100, то они все-равно не смогут правильно ответить на вопрос.
Сумматор изменить не получится, так как он выполняет одну жестко заданную функцию – складывать. Если мы его заменим на что-то или вообще уберем, то это вообще уже не будет искусственным нейроном.
Если менять у каждого нейрона функцию активации, то мы получим слишком разношерстную и неконтролируемую нейронную сеть. К тому же, в большинстве случаев нейроны в нейронных сетях одного типа. То есть они все имеют одну и ту же функцию активации.
Остается только один вариант – менять веса связей.
Обучение нейронной сети (Training) — поиск такого набора весовых коэффициентов, при котором входной сигнал после прохода по сети преобразуется в нужный нам выходной.
Такой подход к термину «обучение нейронной сети» соответствует и биологическим нейросетям. Наш мозг состоит из огромного количества связанных друг с другом нейросетей. Каждая из них в отдельности состоит из нейронов одного типа (функция активации одинаковая). Мы обучаемся благодаря изменению синапсов – элементов, которые усиливают/ослабляют входной сигнал.
Однако есть еще один важный момент. Если обучать сеть, используя только один входной сигнал, то сеть просто «запомнит правильный ответ». Со стороны будет казаться, что она очень быстро «обучилась». И как только вы подадите немного измененный сигнал, ожидая увидеть правильный ответ, то сеть выдаст бессмыслицу.
В самом деле, зачем нам сеть, определяющая лицо только на одном фото. Мы ждем от сети способности обобщать какие-то признаки и узнавать лица и на других фотографиях тоже.
Именно с этой целью и создаются обучающие выборки.
Обучающая выборка (Training set) — конечный набор входных сигналов (иногда вместе с правильными выходными сигналами), по которым происходит обучение сети.
После обучения сети, то есть когда сеть выдает корректные результаты для всех входных сигналов из обучающей выборки, ее можно использовать на практике.
Однако прежде чем пускать свежеиспеченную нейросеть в бой, часто производят оценку качества ее работы на так называемой тестовой выборке.
Тестовая выборка (Testing set) — конечный набор входных сигналов (иногда вместе с правильными выходными сигналами), по которым происходит оценка качества работы сети.
Мы поняли, что такое «обучение сети» – подбор правильного набора весов. Теперь возникает вопрос – а как можно обучать сеть? В самом общем случае есть два подхода, приводящие к разным результатам: обучение с учителем и обучение без учителя.
Обучение с учителем
Суть данного подхода заключается в том, что вы даете на вход сигнал, смотрите на ответ сети, а затем сравниваете его с уже готовым, правильным ответом.
Важный момент. Не путайте правильные ответы и известный алгоритм решения! Вы можете обвести пальцем лицо на фото (правильный ответ), но не сможете сказать, как это сделали (известный алгоритм). Тут такая же ситуация.
Затем, с помощью специальных алгоритмов, вы меняете веса связей нейронной сети и снова даете ей входной сигнал. Сравниваете ее ответ с правильным и повторяете этот процесс до тех пор, пока сеть не начнет отвечать с приемлемой точностью (как я говорил в 1 главе, однозначно точных ответов сеть давать не может).
Обучение с учителем (Supervised learning) — вид обучения сети, при котором ее веса меняются так, чтобы ответы сети минимально отличались от уже готовых правильных ответов.
Где взять правильные ответы?
Если мы хотим, чтобы сеть узнавала лица, мы можем создать обучающую выборку на 1000 фотографий (входные сигналы) и самостоятельно выделить на ней лица (правильные ответы).
Если мы хотим, чтобы сеть прогнозировала рост/падение цен, то обучающую выборку надо делать, основываясь на прошлых данных. В качестве входных сигналов можно брать определенные дни, общее состояние рынка и другие параметры. А в качестве правильных ответов – рост и падение цены в те дни.
И так далее…
Стоит отметить, что учитель, конечно же, не обязательно человек. Дело в том, что порой сеть приходится тренировать часами и днями, совершая тысячи и десятки тысяч попыток. В 99% случаев эту роль выполняет компьютер, а точнее, специальная компьютерная программа.
Обучение без учителя
Обучение без учителя применяют тогда, когда у нас нет правильных ответов на входные сигналы. В этом случае вся обучающая выборка состоит из набора входных сигналов.
Что же происходит при таком обучении сети? Оказывается, что при таком «обучении» сеть начинает выделять классы подаваемых на вход сигналов. Короче говоря – сеть начинает кластеризацию.
Например, вы демонстрируете сети конфеты, пирожные и торты. Вы никак не регулируете работу сети. Вы просто подаете на ее входы данные о данном объекте. Со временем сеть начнет выдавать сигналы трех разных типов, которые и отвечают за объекты на входе.
Обучение без учителя (Unsupervised learning) — вид обучения сети, при котором сеть самостоятельно классифицирует входные сигналы. Правильные (эталонные) выходные сигналы не демонстрируются.
Выводы
В этой главе вы узнали все о структуре искусственного нейрона, а также получили полное представление о том, как он работает (и о его математической модели).
Более того, вы теперь знаете о различных видах искусственных нейронных сетей: однослойные, многослойные, а также feedforward сети и сети с обратными связями.
Вы также ознакомились с тем, что представляет собой обучение сети с учителем и без учителя.
Вы уже знаете необходимую теорию. Последующие главы – рассмотрение конкретных видов нейронных сетей, конкретные алгоритмы их обучения и практика программирования.
Вопросы и задачи
Материал этой главы надо знать очень хорошо, так как в ней содержатся основные теоретические сведения по искусственным нейронным сетям. Обязательно добейтесь уверенных и правильных ответов на все нижеприведенные вопросы и задачи.
Опишите упрощения ИНС по сравнению с биологическими нейросетями.
1. Сложную и запутанную структуру биологических нейронных сетей упрощают и представляют в виде схем. Оставляют только модель обработки сигнала.2. Природа электрических сигналов в нейронных сетях одна и та же. Разница только в их величине. Убираем электрические сигналы, а вместо них используем числа, обозначающие величину проходящего сигнала.
3. Синапсы упрощаем до обычных чисел (весов связей), характеризующих связи между нейронами. Проходящий по связи сигнал просто умножается на вес этой связи.
Из каких элементов состоит искусственный нейрон?
Искусственный нейрон состоит из входов, весовых коэффициентов, соответствующих этим входам, сумматора и функции активации.
Что такое взвешенная сумма? Какой компонент искусственного нейрона ее вычисляет?
Взвешенной суммой называют сумму всех входов, умноженных на соответствующие весовые коэффициенты. Обычно ее обозначают за \( net \).Взвешенную сумму вычисляет сумматор искусственного нейрона.

Вычислите взвешенную сумму нейрона (рисунок выше)
У данного нейрона 4 входа и 4 весовых коэффициента. Используем формулу расчета взвешенной суммы:\[ \sum\limits^4_{i=1}x_iw_i = 2 \cdot 0.5 + (-3) \cdot 2 + 1 \cdot 4 + 5 \cdot (-1) = -6 \]
Значит \( net=-6 \)
Что такое функция активации?
Функция активации – функция, преобразующая взвешенную сумму в выходной сигнал нейрона. Для разных целей используют разные функции активации, но чаще всего: функцию единичного скачка и различные сигмоиды.Функцию активации часто обозначают за \( \phi(net) \).
Запишите математическую модель искусственного нейрона.
Искусственный нейрон c \( n \) входами преобразовывает входной сигнал (число) в выходной сигнал (число) следующим образом:\[ out=\phi\left(\sum\limits^n_{i=1}x_iw_i\right) \]
Чем отличаются однослойные и многослойные нейронные сети?
Однослойные нейронные сети состоят из одного вычислительного слоя нейронов. Входной слой подает сигналы сразу на выходной слой, который и преобразует сигнал, и сразу выдает результат.Многослойные нейронные сети, помимо входного и выходного слоев, имеют еще и скрытые слои. Эти скрытые слои проводят какие-то внутренние промежуточные преобразования, наподобие этапов производства продуктов на заводе.
В чем отличие feedforward сетей от сетей с обратными связями?
Сети прямого распространения (feedforward сети) допускают прохождение сигнала только в одном направлении – от входов к выходам. Сети с обратными связями данных ограничений не имеют, и выходы нейронов могут вновь подаваться на входы.
Что такое обучающая выборка? В чем ее смысл?
Перед тем, как использовать сеть на практике (например, для решения текущих задач, ответов на которые у вас нет), необходимо собрать коллекцию задач с готовыми ответами, на которой и тренировать сеть. Это коллекция и называется обучающей выборкой.Если собрать слишком маленький набор входных и выходных сигналов, то сеть просто запомнит ответы и цель обучения не будет достигнута.
Что понимают под обучением сети?
Под обучением сети понимают процесс изменения весовых коэффициентов искусственных нейронов сети с целью подобрать такую их комбинацию, которая преобразует входной сигнал в корректный выходной.
Что такое обучение с учителем и без него?
При обучении сети с учителем ей на входы подают сигналы, а затем сравнивают ее выход с заранее известным правильным выходом. Этот процесс повторяют до тех пор, пока не будет достигнута необходимая точность ответов.Если сети только подают входные сигналы, без сравнения их с готовыми выходами, то сеть начинает самостоятельную классификацию этих входных сигналов. Другими словами она выполняет кластеризацию входных сигналов. Такое обучение называют обучением без учителя.