Биг дата что это такое
Принципы работы с большими данными, парадигма MapReduce / DCA (Data-Centric Alliance) corporate blog / Habr

Привет, Хабр! Этой статьёй я открываю цикл материалов, посвящённых работе с большими данными. Зачем? Хочется сохранить накопленный опыт, свой и команды, так скажем, в энциклопедическом формате – наверняка кому-то он будет полезен.
Проблематику больших данных постараемся описывать с разных сторон: основные принципы работы с данными, инструменты, примеры решения практических задач. Отдельное внимание окажем теме машинного обучения.
Начинать надо от простого к сложному, поэтому первая статья – о принципах работы с большими данными и парадигме MapReduce.
История вопроса и определение термина
Термин Big Data появился сравнительно недавно. Google Trends показывает начало активного роста употребления словосочетания начиная с 2011 года (ссылка):
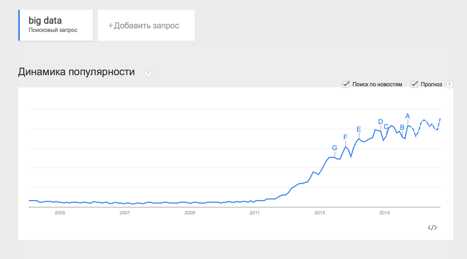
При этом уже сейчас термин не использует только ленивый. Особенно часто не по делу термин используют маркетологи. Так что же такое Big Data на самом деле? Раз уж я решил системно изложить и освятить вопрос – необходимо определиться с понятием.
В своей практике я встречался с разными определениями:
· Big Data – это когда данных больше, чем 100Гб (500Гб, 1ТБ, кому что нравится)
· Big Data – это такие данные, которые невозможно обрабатывать в Excel
· Big Data – это такие данные, которые невозможно обработать на одном компьютере
И даже такие:
· Вig Data – это вообще любые данные.
· Big Data не существует, ее придумали маркетологи.
В этом цикле статей я буду придерживаться определения с wikipedia:
Большие данные (англ. big data) — серия подходов, инструментов и методов обработки структурированных и неструктурированных данных огромных объёмов и значительного многообразия для получения воспринимаемых человеком результатов, эффективных в условиях непрерывного прироста, распределения по многочисленным узлам вычислительной сети, сформировавшихся в конце 2000-х годов, альтернативных традиционным системам управления базами данных и решениям класса Business Intelligence.
Таким образом под Big Data я буду понимать не какой-то конкретный объём данных и даже не сами данные, а методы их обработки, которые позволяют распредёлено обрабатывать информацию. Эти методы можно применить как к огромным массивам данных (таким как содержание всех страниц в интернете), так и к маленьким (таким как содержимое этой статьи).
Приведу несколько примеров того, что может быть источником данных, для которых необходимы методы работы с большими данными:
· Логи поведения пользователей в интернете
· GPS-сигналы от автомобилей для транспортной компании
· Данные, снимаемые с датчиков в большом адронном коллайдере
· Оцифрованные книги в Российской Государственной Библиотеке
· Информация о транзакциях всех клиентов банка
· Информация о всех покупках в крупной ритейл сети и т.д.
Количество источников данных стремительно растёт, а значит технологии их обработки становятся всё более востребованными.
Принципы работы с большими данными
Исходя из определения Big Data, можно сформулировать основные принципы работы с такими данными:
1. Горизонтальная масштабируемость. Поскольку данных может быть сколь угодно много – любая система, которая подразумевает обработку больших данных, должна быть расширяемой. В 2 раза вырос объём данных – в 2 раза увеличили количество железа в кластере и всё продолжило работать.
2. Отказоустойчивость. Принцип горизонтальной масштабируемости подразумевает, что машин в кластере может быть много. Например, Hadoop-кластер Yahoo имеет более 42000 машин (по этой ссылке можно посмотреть размеры кластера в разных организациях). Это означает, что часть этих машин будет гарантированно выходить из строя. Методы работы с большими данными должны учитывать возможность таких сбоев и переживать их без каких-либо значимых последствий.
3. Локальность данных. В больших распределённых системах данные распределены по большому количеству машин. Если данные физически находятся на одном сервере, а обрабатываются на другом – расходы на передачу данных могут превысить расходы на саму обработку. Поэтому одним из важнейших принципов проектирования BigData-решений является принцип локальности данных – по возможности обрабатываем данные на той же машине, на которой их храним.
Все современные средства работы с большими данными так или иначе следуют этим трём принципам. Для того, чтобы им следовать – необходимо придумывать какие-то методы, способы и парадигмы разработки средств разработки данных. Один из самых классических методов я разберу в сегодняшней статье.
MapReduce
Про MapReduce на хабре уже писали (раз, два, три), но раз уж цикл статей претендует на системное изложение вопросов Big Data – без MapReduce в первой статье не обойтись J
MapReduce – это модель распределенной обработки данных, предложенная компанией Google для обработки больших объёмов данных на компьютерных кластерах. MapReduce неплохо иллюстрируется следующей картинкой (взято по ссылке):
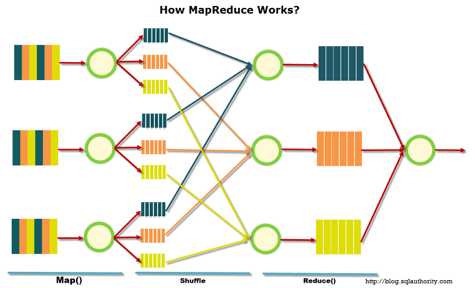
MapReduce предполагает, что данные организованы в виде некоторых записей. Обработка данных происходит в 3 стадии:
1. Стадия Map. На этой стадии данные предобрабатываются при помощи функции map(), которую определяет пользователь. Работа этой стадии заключается в предобработке и фильтрации данных. Работа очень похожа на операцию map в функциональных языках программирования – пользовательская функция применяется к каждой входной записи.
Функция map() примененная к одной входной записи и выдаёт множество пар ключ-значение. Множество – т.е. может выдать только одну запись, может не выдать ничего, а может выдать несколько пар ключ-значение. Что будет находится в ключе и в значении – решать пользователю, но ключ – очень важная вещь, так как данные с одним ключом в будущем попадут в один экземпляр функции reduce.
2. Стадия Shuffle. Проходит незаметно для пользователя. В этой стадии вывод функции map «разбирается по корзинам» – каждая корзина соответствует одному ключу вывода стадии map. В дальнейшем эти корзины послужат входом для reduce.
3. Стадия Reduce. Каждая «корзина» со значениями, сформированная на стадии shuffle, попадает на вход функции reduce().
Функция reduce задаётся пользователем и вычисляет финальный результат для отдельной «корзины». Множество всех значений, возвращённых функцией reduce(), является финальным результатом MapReduce-задачи.
Несколько дополнительных фактов про MapReduce:
1) Все запуски функции map работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
2) Все запуски функции reduce работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
3) Shuffle внутри себя представляет параллельную сортировку, поэтому также может работать на разных машинах кластера. Пункты 1-3 позволяют выполнить принцип горизонтальной масштабируемости.
4) Функция map, как правило, применяется на той же машине, на которой хранятся данные – это позволяет снизить передачу данных по сети (принцип локальности данных).
5) MapReduce – это всегда полное сканирование данных, никаких индексов нет. Это означает, что MapReduce плохо применим, когда ответ требуется очень быстро.
Примеры задач, эффективно решаемых при помощи MapReduce
Word Count
Начнём с классической задачи – Word Count. Задача формулируется следующим образом: имеется большой корпус документов. Задача – для каждого слова, хотя бы один раз встречающегося в корпусе, посчитать суммарное количество раз, которое оно встретилось в корпусе.
Решение:
Раз имеем большой корпус документов – пусть один документ будет одной входной записью для MapRreduce–задачи. В MapReduce мы можем только задавать пользовательские функции, что мы и сделаем (будем использовать python-like псевдокод):
|
|
Функция map превращает входной документ в набор пар (слово, 1), shuffle прозрачно для нас превращает это в пары (слово, [1,1,1,1,1,1]), reduce суммирует эти единички, возвращая финальный ответ для слова.
Обработка логов рекламной системы
Второй пример взят из реальной практики Data-Centric Alliance.
Задача: имеется csv-лог рекламной системы вида:
<user_id>,<country>,<city>,<campaign_id>,<creative_id>,<payment></p> 11111,RU,Moscow,2,4,0.3 22222,RU,Voronezh,2,3,0.2 13413,UA,Kiev,4,11,0.7 … Необходимо рассчитать среднюю стоимость показа рекламы по городам России.
Решение:
|
|
Функция map проверяет, нужна ли нам данная запись – и если нужна, оставляет только нужную информацию (город и размер платежа). Функция reduce вычисляет финальный ответ по городу, имея список всех платежей в этом городе.
Резюме
В статье мы рассмотрели несколько вводных моментов про большие данные:
· Что такое Big Data и откуда берётся;
· Каким основным принципам следуют все средства и парадигмы работы с большими данными;
· Рассмотрели парадигму MapReduce и разобрали несколько задач, в которой она может быть применена.
Первая статья была больше теоретической, во второй статье мы перейдем к практике, рассмотрим Hadoop – одну из самых известных технологий для работы с большими данными и покажем, как запускать MapReduce-задачи на Hadoop.
В последующих статьях цикла мы рассмотрим более сложные задачи, решаемые при помощи MapReduce, расскажем об ограничениях MapReduce и о том, какими инструментами и техниками можно обходить эти ограничения.
Спасибо за внимание, готовы ответить на ваши вопросы.
Youtube-Канал автора об анализе данных
Ссылки на другие части цикла:
Часть 2: Hadoop
Часть 3: Приемы и стратегии разработки MapReduce-приложений
Часть 4: Hbase
Что такое Big data простыми словами? Применение больших данных
Через 10 лет мир перейдет в новую эпоху — эпоху больших данных. Вместо виджета погоды на экране смартфона, он сам подскажет вам, что лучше одеть. За завтраком телефон покажет дорогу, по которой вы быстрее доберетесь до работы и когда нужно будет выехать.
Под влиянием Big Data изменится все, чего бы не коснулся человек. Разберемся, что это такое, а также рассмотрим реальное применение и перспективы технологии.
Навигация по материалу:
Что такое Big data?
Большие данные — технология обработки информации, которая превосходит сотни терабайт и со временем растет в геометрической прогрессии.
Такие данные настолько велики и сложны, что ни один из традиционных инструментов управления данными не может их хранить или эффективно обрабатывать. Проанализировать этот объем человек не способен. Для этого разработаны специальные алгоритмы, которые после анализа больших данных дают человеку понятные результаты.
В Big Data входят петабайты (1024 терабайта) или эксабайты (1024 петабайта) информации, из которых состоят миллиарды или триллионы записей миллионов людей и все из разных источников (Интернет, продажи, контакт-центр, социальные сети, мобильные устройства). Как правило, информация слабо структурирована и часто неполная и недоступная.
Как работает технология Big-Data?

Пользователи социальной сети Facebook загружают фото, видео и выполняют действия каждый день на сотни терабайт. Сколько бы человек не участвовало в разработке, они не справятся с постоянным потоком информации. Чтобы дальше развивать сервис и делать сайты комфортнее — внедрять умные рекомендации контента, показывать актуальную для пользователя рекламу, сотни тысяч терабайт пропускают через алгоритм и получают структурированную и понятную информацию.
Сравнивая огромный объем информации, в нем находят взаимосвязи. Эти взаимосвязи с определенной вероятностью могут предсказать будущее. Находить и анализировать человеку помогает искусственный интеллект.
Нейросеть сканирует тысячи фотографий, видео, комментариев — те самые сотни терабайт больших данных и выдает результат: сколько довольных покупателей уходит из магазина, будет ли в ближайшие часы пробка на дороге, какие обсуждения популярны в социальной сети и многое другое.
Методы работы с большими данными:
- Машинное обучение
- Анализ настроений
- Анализ социальной сети
- Ассоциация правил обучения
- Анализ дерева классификации
- Генетические алгоритмы
- Регрессионный анализ
Машинное обучение
Вы просматриваете ленту новостей, лайкаете посты в Instagram, а алгоритм изучает ваш контент и рекомендует похожий. Искусственный интеллект учится без явного программирования и сфокусирован на прогнозировании на основе известных свойств, извлеченных из наборов «обучающих данных».
Машинное обучение помогает:
- Различать спам и не спам в электронной почте
- Изучать пользовательские предпочтения и давать рекомендации
- Определять лучший контент для привлечения потенциальных клиентов
- Определять вероятность выигрыша дела и устанавливать юридические тарифы
Анализ настроений
Анализ настроений помогает:
- Улучшать обслуживание в гостиничной сети, анализируя комментарии гостей
- Настраивать стимулы и услуги для удовлетворения потребностей клиента
- Определить по мнениям в социальной сети о чем думают клиенты.
Анализ социальных сетей
Анализ социальных сетей впервые использовали в телекоммуникационной отрасли. Метод применяется социологами для анализа отношений между людьми во многих областях и коммерческой деятельности.
Этот анализ используют чтобы:
- Увидеть, как люди из разных групп населения формируют связи с посторонними лицами
- Выяснить важность и влияние конкретного человека в группе
- Найти минимальное количество прямых связей для соединения двух людей
- Понять социальную структуру клиентской базы
Изучение правил ассоциации
Люди, которые не покупают алкоголь, берут соки чаще, чем любители горячительных напитков?
Изучение правил ассоциации — метод обнаружения интересных взаимосвязей между переменными в больших базах данных. Впервые его использовали крупные сети супермаркетов для обнаружения интересных связей между продуктами, используя информацию из систем торговых точек супермаркетов (POS).
С помощью правил ассоциации:
- Размещают продукты в большей близости друг к другу, чтобы увеличились продажи
- Извлекают информацию о посетителях веб-сайтов из журналов веб-сервера
- Анализируют биологические данные
- Отслеживают системные журналы для обнаружения злоумышленников
- Определяют чаще ли покупатели чая берут газированные напитки
Анализ дерева классификации
Статистическая классификация определяет категории, к которым относится новое наблюдение.
Статистическая классификация используется для:
- Автоматического присвоения документов категориям
- Классификации организмов по группам
- Разработки профилей студентов, проходящих онлайн-курсы
Генетические алгоритмы
Генетические алгоритмы вдохновлены тем, как работает эволюция, то есть с помощью таких механизмов, как наследование, мутация и естественный отбор.
Генетические алгоритмы используют для:
- Составления расписания врачей для отделений неотложной помощи в больницах
- Расчет оптимальных материалов для разработки экономичных автомобилей
- Создания «искусственно творческого» контента, такого как игра слов и шутки
Регрессионный анализ
Как возраст человека влияет на тип автомобиля, который он покупает?
На базовом уровне регрессионный анализ включает в себя манипулирование некоторой независимой переменной (например, фоновой музыкой) чтобы увидеть, как она влияет на зависимую переменную (время, проведенное в магазине).
Регрессионный анализ используют для определения:
- Уровней удовлетворенности клиентов
- Как прогноз погоды за предыдущий день влияет на количество полученных звонков в службу поддержки
- Как район и размер домов влияют на цену жилья
Data Mining — как собирается и обрабатывается Биг Дата
Загрузка больших данных в традиционную реляционную базу для анализа занимает много времени и денег. По этой причине появились специальные подходы для сбора и анализа информации. Для получения и последующего извлечения информацию объединяют и помещают в “озеро данных”. Оттуда программы искусственного интеллекта, используя сложные алгоритмы, ищут повторяющиеся паттерны.
Хранение и обработка происходит следующими инструментами:
- Apache HADOOP — пакетно-ориентированная система обработки данных. Система хранит и отслеживает информацию на нескольких машинах и масштабируется до нескольких тысяч серверов.
- HPPC — платформа с открытым исходным кодом, разработанная LexisNexis Risk Solutions. HPPC известна как суперкомпьютер Data Analytics (DAS), поддерживающая обработку данных как в пакетном режиме, так и в режиме реального времени. Система использует суперкомпьютеры и кластеры из обычных компьютеров.
- Storm — обрабатывает информацию в реальном времени. Использует Eclipse Public License с открытым исходным кодом.
Реальное применение Big Data
Самый быстрый рост расходов на технологии больших данных происходит в банковской сфере, здравоохранении, страховании, ценных бумагах и инвестиционных услугах, а также в области телекоммуникаций. Три из этих отраслей относятся к финансовому сектору, который имеет множество полезных вариантов для анализа Big Data: обнаружение мошенничества, управление рисками и оптимизация обслуживания клиентов.
Банки и компании, выпускающие кредитные карты, используют большие данные, чтобы выявлять закономерности, которые указывают на преступную деятельность. Из-за чего некоторые аналитики считают, что большие данные могут принести пользу криптовалюте. Алгоритмы смогут выявить мошенничество и незаконную деятельность в крипто-индустрии.
Благодаря криптовалюте такой как Биткойн и Эфириум блокчейн может фактически поддерживать любой тип оцифрованной информации. Его можно использовать в области Big Data, особенно для повышения безопасности или качества информации.
Например, больница может использовать его для обеспечения безопасности, актуальности данных пациента и полного сохранения их качества. Размещая базы данных о здоровьи в блокчейн, больница обеспечивает всем своим сотрудникам доступ к единому, неизменяемому источнику информации.
Также, как люди связывают криптовалюту с волатильностью, они часто связывают большие данные со способностью просеивать большие объемы информации. Big Data поможет отслеживать тенденции. На цену влияет множество факторов и алгоритмы больших данных учтут это, а затем предоставят решение.
Перспективы использования Биг Дата
Blockchain и Big Data — две развивающиеся и взаимодополняющие друг друга технологии. С 2016 блокчейн часто обсуждается в СМИ. Это криптографически безопасная технология распределенных баз данных для хранения и передачи информации. Защита частной и конфиденциальной информации — актуальная и будущая проблема больших данных, которую способен решить блокчейн.
Почти каждая отрасль начала инвестировать в аналитику Big Data, но некоторые инвестируют больше, чем другие. По информации IDC, больше тратят на банковские услуги, дискретное производство, процессное производство и профессиональные услуги. По исследованиям Wikibon, выручка от продаж программ и услуг на мировом рынке в 2018 году составила $42 млрд, а в 2027 году преодолеет отметку в $100 млрд.
По оценкам Neimeth, блокчейн составит до 20% общего рынка больших данных к 2030 году, принося до $100 млрд. годового дохода. Это превосходит прибыль PayPal, Visa и Mastercard вместе взятые.
Аналитика Big Data будет важна для отслеживания транзакций и позволит компаниям, использующим блокчейн, выявлять скрытые схемы и выяснять с кем они взаимодействуют в блокчейне.
Рынок Big data в России

Весь мир и в том числе Россия используют технологию Big Data в банковской сфере, услугах связи и розничной торговле. Эксперты считают, что в будущем технологию будут использовать транспортная отрасль, нефтегазовая и пищевая промышленность, а также энергетика.
Аналитики IDC признали Россию крупнейшим региональным рынком BDA. По расчетам в текущем году выручка приблизится к 1,4 миллиардам долларов и будет составлять 40% общего объема инвестиций в секторе больших данных и приложений бизнес-аналитики.
Дата публикации 22.08.2019
Поделитесь этим материалом в социальных сетях и оставьте свое мнение в комментариях ниже.
5 / 5 ( 24 голоса )
Самые последние новости криптовалютного рынка и майнинга:The following two tabs change content below.Биг-дата что это такое? Простыми словами о Big-Data технологии
Термин «Биг-Дата», возможно, сегодня уже узнаваем, но вокруг него все еще довольно много путаницы относительно того, что же он означает на самом деле. По правде говоря, концепция постоянно развивается и пересматривается, поскольку она остается движущей силой многих продолжающихся волн цифрового преобразования, включая искусственный интеллект, науку о данных и Интернет вещей. Но что же представляет собой технология Big-Data и как она меняет наш мир? Давайте попробуем разобраться объяснить суть технологии Биг-Даты и что она означает простыми словами.
Удивительный рост Биг-Даты
Все началось со «взрыва» в объеме данных, которые мы создали с самого начала цифровой эпохи. Это во многом связано с развитием компьютеров, Интернета и технологий, способных «выхватывать» данные из окружающего нас мира. Данные сами по себе не являются новым изобретением. Еще до эпохи компьютеров и баз данных мы использовали бумажные записи транзакций, клиентские записи и архивные файлы, которые и являются данными. Компьютеры, в особенности электронные таблицы и базы данных, позволили нам легко и просто хранить и упорядочивать данные в больших масштабах. Внезапно информация стала доступной при помощи одного щелчка мыши.
Тем не менее, мы прошли долгий путь от первоначальных таблиц и баз данных. Сегодня через каждые два дня мы создаем столько данных, сколько мы получили с самого начала вплоть до 2000 года. Правильно, через каждые два дня. И объем данных, которые мы создаем, продолжает стремительно расти; к 2020 году объем доступной цифровой информации возрастет примерно с 5 зеттабайтов до 20 зеттабайтов.
В настоящее время почти каждое действие, которое мы предпринимаем, оставляет свой след. Мы генерируем данные всякий раз, когда выходим в Интернет, когда переносим наши смартфоны, оборудованные поисковым модулем, когда разговариваем с нашими знакомыми через социальные сети или чаты и т.д. К тому же, количество данных, сгенерированных машинным способом, также быстро растет. Данные генерируются и распространяются, когда наши «умные» домашние устройства обмениваются данными друг с другом или со своими домашними серверами. Промышленное оборудование на заводах и фабриках все чаще оснащается датчиками, которые аккумулируют и передают данные.
Термин «Big-Data» относится к сбору всех этих данных и нашей способности использовать их в своих интересах в широком спектре областей, включая бизнес.
Как работает технология Big-Data?
Биг Дата работает по принципу: чем больше вы знаете о том или ином предмете или явлении, тем более достоверно вы сможете достичь нового понимания и предсказать, что произойдет в будущем. В ходе сравнения большего количества точек данных возникают взаимосвязи, которые ранее были скрыты, и эти взаимосвязи позволяют нам учиться и принимать более взвешенные решения. Чаще всего это делается с помощью процесса, который включает в себя построение моделей на основе данных, которые мы можем собрать, и дальнейший запуск имитации, в ходе которой каждый раз настраиваются значения точек данных и отслеживается то, как они влияют на наши результаты. Этот процесс автоматизирован — современные технологии аналитики будут запускать миллионы этих симуляций, настраивая все возможные переменные до тех пор, пока не найдут модель — или идею — которые помогут решить проблему, над которой они работают.
 Бил Гейтс висит над бумажным содержимым одного компакт диска
Бил Гейтс висит над бумажным содержимым одного компакт дискаДо недавнего времени данные были ограничены электронными таблицами или базами данных — и все было очень упорядочено и аккуратно. Все то, что нельзя было легко организовать в строки и столбцы, расценивалось как слишком сложное для работы и игнорировалось. Однако прогресс в области хранения и аналитики означает, что мы можем фиксировать, хранить и обрабатывать большое количество данных различного типа. В результате «данные» на сегодняшний день могут означать что угодно, начиная базами данных, и заканчивая фотографиями, видео, звукозаписями, письменными текстами и данными датчиков.
Чтобы понять все эти беспорядочные данные, проекты, имеющие в основе Биг Дату, зачастую используют ультрасовременную аналитику с привлечением искусственного интеллекта и компьютерного обучения. Обучая вычислительные машины определять, что же представляют собой конкретные данные — например, посредством распознавания образов или обработки естественного языка – мы можем научить их определять модели гораздо быстрее и достовернее, чем мы сами.
Сейчас лучшее время для старта карьеры в области Data Science. В школе данных SkillFactory стартует онлайн-курс, позволяющий освоить профессию Data Scientist с нуля.
Как используется Биг-Дата?
Этот постоянно увеличивающийся поток информации о данных датчиков, текстовых, голосовых, фото- и видеоданных означает, что теперь мы можем использовать данные теми способами, которые невозможно было представить еще несколько лет назад. Это привносит революционные изменения в мир бизнеса едва ли не в каждой отрасли. Сегодня компании могут с невероятной точностью предсказать, какие конкретные категории клиентов захотят сделать приобретение, и когда. Биг Дата также помогает компаниям выполнять свою деятельность намного эффективнее.
Даже вне сферы бизнеса проекты, связанные с Big-Data, уже помогают изменить наш мир различными путями:
- Улучшая здравоохранение — медицина, управляемая данными, способна анализировать огромное количество медицинской информации и изображений для моделей, которые могут помочь обнаружить заболевание на ранней стадии и разработать новые лекарства.
- Прогнозируя и реагируя на природные и техногенные катастрофы. Данные датчиков можно проанализировать, чтобы предсказать, где могут произойти землетрясения, а модели поведения человека дают подсказки, которые помогают организациям оказывать помощь выжившим. Технология Биг Даты также используется для отслеживания и защиты потока беженцев из зон военных действий по всему миру.
- Предотвращая преступность. Полицейские силы все чаще используют стратегии, основанные на данных, которые включают их собственную разведывательную информацию и информацию из открытого доступа для более эффективного использования ресурсов и принятия сдерживающих мер там, где это необходимо.
Лучшие книги о технологии Big-Data

Проблемы с Big-Data
Биг Дата дает нам беспрецедентные идеи и возможности, но также поднимает проблемы и вопросы, которые необходимо решить:
- Конфиденциальность данных – Big-Data, которую мы сегодня генерируем, содержит много информации о нашей личной жизни, на конфиденциальность которой мы имеем полное право. Все чаще и чаще нас просят найти баланс между количеством персональных данных, которые мы раскрываем, и удобством, которое предлагают приложения и услуги, основанные на использовании Биг Даты.
- Защита данных — даже если мы решаем, что нас устраивает то, что у кого-то есть наши данные для определенной цели, можем ли мы доверять ему сохранность и безопасность наших данных?
- Дискриминация данных — когда вся информация будет известна, станет ли приемлемой дискриминация людей на основе данных из их личной жизни? Мы уже используем оценки кредитоспособности, чтобы решить, кто может брать деньги, и страхование тоже в значительной степени зависит от данных. Нам стоит ожидать, что нас будут анализировать и оценивать более подробно, однако следует позаботиться о том, чтобы это не усложняло жизнь тех людей, которые располагают меньшими ресурсами и ограниченным доступом к информации.
Выполнение этих задач является важной составляющей Биг Даты, и их необходимо решать организациям, которые хотят использовать такие данные. Неспособность осуществить это может сделать бизнес уязвимым, причем не только с точки зрения его репутации, но также с юридической и финансовой стороны.
Глядя в будущее
Данные меняют наш мир и нашу жизнь небывалыми темпами. Если Big-Data способна на все это сегодня — просто представьте, на что она будет способна завтра. Объем доступных нам данных только увеличится, а технология аналитики станет еще более продвинутой.
Для бизнеса способность применять Биг Дату будет становиться все более решающей в ближайшие годы. Только те компании, которые рассматривают данные как стратегический актив, выживут и будут процветать. Те же, кто игнорирует эту революцию, рискуют остаться позади.
Выберите подарок (PDF)
✔️ 2 способа нетворкинга, о которых все молчат: ссылка
✔️ 9 способов убить инстаграм и как набрать 1 млн подписчиков: ссылка
✔️ 7 секретов сторителлинга: ссылка
✔️ Как я раскрутил Telegram до 143 тысяч подписчиков: ссылка
что это такое, где и как использовать технологии больших данных
Определение Big data обычно расшифровывают довольно просто – это огромный объем информации, часто бессистемной, которая хранится на каком либо цифровом носителе. Однако массив данных с приставкой «Биг» настолько велик, что привычными средствами структурирования и аналитики «перелопатить» его невозможно. Поэтому под термином «биг дата» понимают ещё и технологии поиска, обработки и применения неструктурированной информации в больших объемах.

Экскурс в историю и статистику
Словосочетание «большие данные» появилось в 2008 году с легкой руки Клиффорда Линча. В спецвыпуске журнала Nature эксперт назвал взрывной рост потоков информации - big data. В него он отнес любые массивы неоднородных данных свыше 150 Гб в сутки.
Из статистических выкладок аналитических агентств в 2005 году мир оперировал 4-5 эксабайтами информации (4-5 миллиардов гигабайтов), через 5 лет объемы big data выросли до 0,19 зеттабайт (1 ЗБ = 1024 ЭБ). В 2012 году показатели возросли до 1,8 ЗБ, а в 2015 – до 7 ЗБ. Эксперты прогнозируют, что к 2020 году системы больших данных будут оперировать 42-45 зеттабайтов информации.
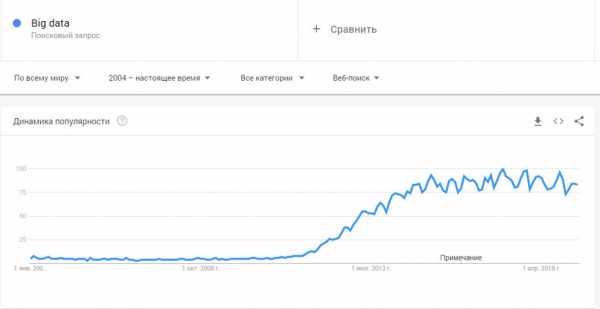
До 2011 года технологии больших данных рассматривались только в качестве научного анализа и практического выхода ни имели. Однако объемы данных росли по экспоненте и проблема огромных массивов неструктурированной и неоднородной информации стала актуальной уже в начале 2012 году. Всплеск интереса к big data хорошо виден в Google Trends.
К развитию нового направления подключились мастодонты цифрового бизнеса – Microsoft, IBM, Oracle, EMC и другие. С 2014 года большие данные изучают в университетах, внедряют в прикладные науки – инженерию, физику, социологию.
Как работает технология big data?
Чтобы массив информации обозначить приставкой «биг» он должен обладать следующими признаками:
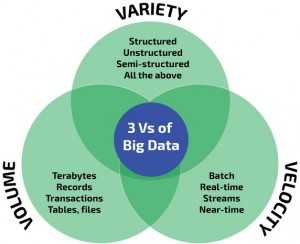
Правило VVV:
- Объем (Volume) – данные измеряются по физической величине и занимаемому пространству на цифровом носителе. К «биг» относят массивы свыше 150 Гб в сутки.
- Скорость, обновление (Velocity) – информация регулярно обновляется и для обработки в реальном времени необходимы интеллектуальные технологии больших данных.
- Разнообразие (Variety) – информация в массивах может иметь неоднородные форматы, быть структурированной частично, полностью и скапливаться бессистемно. Например, социальные сети используют большие данные в виде текстов, видео, аудио, финансовых транзакций, картинок и прочего.
В современных системах рассматриваются два дополнительных фактора:
- Изменчивость (Variability) – потоки данных могут иметь пики и спады, сезонности, периодичность. Всплески неструктурированной информации сложны в управлении, требует мощных технологий обработки.
- Значение данных (Value) – информация может иметь разную сложность для восприятия и переработки, что затрудняет работу интеллектуальным системам. Например, массив сообщений из соцсетей – это один уровень данных, а транзакционные операции – другой. Задача машин определить степень важности поступающей информации, чтобы быстро структурировать.
Принцип работы технологии big data основан на максимальном информировании пользователя о каком-либо предмете или явлении. Задача такого ознакомления с данными – помочь взвесить все «за» и «против», чтобы принять верное решение. В интеллектуальных машинах на основе массива информации строится модель будущего, а дальше имитируются различные варианты и отслеживаются результаты.
Современные аналитические агентства запускают миллионы подобных симуляций, когда тестируют идею, предположение или решают проблему. Процесс автоматизирован.
К источникам big data относят:
- интернет – блоги, соцсети, сайты, СМИ и различные форумы;
- корпоративную информацию – архивы, транзакции, базы данных;
- показания считывающих устройств – метеорологические приборы, датчики сотовой связи и другие.
Принципы работы с массивами данных включают три основных фактора:
- Расширяемость системы. Под ней понимают обычно горизонтальную масштабируемость носителей информации. То есть выросли объемы входящих данных – увеличились мощность и количество серверов для их хранения.
- Устойчивость к отказу. Повышать количество цифровых носителей, интеллектуальных машин соразмерно объемам данных можно до бесконечности. Но это не означает, что часть машин не будет выходить из строя, устаревать. Поэтому одним из факторов стабильной работы с большими данными является отказоустойчивость серверов.
- Локализация. Отдельные массивы информации хранятся и обрабатываются в пределах одного выделенного сервера, чтобы экономить время, ресурсы, расходы на передачу данных.
Для чего используют?
Чем больше мы знаем о конкретном предмете или явлении, тем точнее постигаем суть и можем прогнозировать будущее. Снимая и обрабатывая потоки данных с датчиков, интернета, транзакционных операций, компании могут довольно точно предсказать спрос на продукцию, а службы чрезвычайных ситуаций предотвратить техногенные катастрофы. Приведем несколько примеров вне сферы бизнеса и маркетинга, как используются технологии больших данных:
- Здравоохранение. Больше знаний о болезнях, больше вариантов лечения, больше информации о лекарственных препаратах – всё это позволяет бороться с такими болезнями, которые 40-50 лет назад считались неизлечимыми.
- Предупреждение природных и техногенных катастроф. Максимально точный прогноз в этой сфере спасает тысячи жизней людей. Задача интеллектуальных машин собрать и обработать множество показаний датчиков и на их основе помочь людям определить дату и место возможного катаклизма.
- Правоохранительные органы. Большие данные используются для прогнозирования всплеска криминала в разных странах и принятия сдерживающих мер, там, где этого требует ситуация.
Методики анализа и обработки

К основным способам анализа больших массивов информации относят следующие:
- Глубинный анализ, классификация данных. Эти методики пришли из технологий работы с обычной структурированной информацией в небольших массивах. Однако в новых условиях используются усовершенствованные математические алгоритмы, основанные на достижениях в цифровой сфере.
- Краудсорсинг. В основе этой технологии возможность получать и обрабатывать потоки в миллиарды байт из множества источников. Конечное число «поставщиков» не ограничивается ничем. Разве только мощностью системы.
- Сплит-тестирование. Из массива выбираются несколько элементов, которые сравниваются между собой поочередно «до» и «после» изменения. А\В тесты помогают определить, какие факторы оказывают наибольшее влияние на элементы. Например, с помощью сплит-тестирования можно провести огромное количество итераций постепенно приближаясь к достоверному результату.
- Прогнозирование. Аналитики стараются заранее задать системе те или иные параметры и в дальнейшей проверять поведение объекта на основе поступления больших массивов информации.
- Машинное обучение. Искусственный интеллект в перспективе способен поглощать и обрабатывать большие объемы несистематизированных данных, впоследствии используя их для самостоятельного обучения.
- Анализ сетевой активности. Методики big data используются для исследования соцсетей, взаимоотношений между владельцами аккаунтов, групп, сообществами. На основе этого создаются целевые аудитории по интересам, геолокации, возрасту и прочим метрикам.
Большие данные в бизнесе и маркетинге
Стратегии развития бизнеса, маркетинговые мероприятия, реклама основаны на анализе и работе с имеющимися данными. Большие массивы позволяют «перелопатить» гигантские объемы данных и соответственно максимально точно скорректировать направление развития бренда, продукта, услуги.
Например, аукцион RTB в контекстной рекламе работают с big data, что позволяет эффективно рекламировать коммерческие предложения выделенной целевой аудитории, а не всем подряд.
Какие выгоды для бизнеса:
- Создание проектов, которые с высокой вероятностью станут востребованными у пользователей, покупателей.
- Изучение и анализ требований клиентов с существующим сервисом компании. На основе выкладки корректируется работа обслуживающего персонала.
- Выявление лояльности и неудовлетворенности клиентской базы за счет анализа разнообразной информации из блогов, соцсетей и других источников.
- Привлечение и удержание целевой аудитории благодаря аналитической работе с большими массивами информации.
Технологии используют в прогнозировании популярности продуктов, например, с помощью сервиса Google Trends и Яндекс. Вордстат (для России и СНГ).
Методики big data используют все крупные компании – IBM, Google, Facebook и финансовые корпорации – VISA, Master Card, а также министерства разных стран мира. Например, в Германии сократили выдачу пособий по безработице, высчитав, что часть граждан получают их без оснований. Так удалось вернуть в бюджет около 15 млрд. евро.
Недавний скандал с Facebook из-за утечки данных пользователей говорит о том, что объемы неструктурированной информации растут и даже мастодонты цифровой эры не всегда могут обеспечить их полную конфиденциальность.

Например, Master Card используют большие данные для предотвращения мошеннических операций со счетами клиентов. Так удается ежегодно спасти от кражи более 3 млрд. долларов США.
В игровой сфере big data позволяет проанализировать поведение игроков, выявить предпочтения активной аудитории и на основе этого прогнозировать уровень интереса к игре.

Сегодня бизнес знает о своих клиентах больше, чем мы сами знаем о себе – поэтому рекламные кампании Coca-Cola и других корпораций имеют оглушительный успех.
Перспективы развития
В 2019 году важность понимания и главное работы с массивами информации возросла в 4-5 раз по сравнению с началом десятилетия. С массовостью пришла интеграция big data в сферы малого и среднего бизнеса, стартапы:
- Облачные хранилища. Технологии хранения и работы с данными в онлайн-пространстве позволяет решить массу проблем малого и среднего бизнеса: дешевле купить облако, чем содержать дата-центр, персонал может работать удаленно, не нужен офис.
- Глубокое обучение, искусственный интеллект. Аналитические машины имитируют человеческий мозг, то есть используются искусственные нейронные сети. Обучение происходит самостоятельно на основе больших массивов информации.
- Dark Data – сбор и хранение не оцифрованных данных о компании, которые не имеют значимой роли для развития бизнеса, однако они нужны в техническом и законодательном планах.
- Блокчейн. Упрощение интернет-транзакций, снижение затрат на проведение этих операций.
- Системы самообслуживания – с 2016 года внедряются специальные платформы для малого и среднего бизнеса, где можно самостоятельно хранить и систематизировать данные.
Резюме
Мы изучили, что такое big data? Рассмотрели, как работает эта технология, для чего используются массивы информации. Познакомились с принципами и методиками работы с большими данными.
Рекомендуем к прочтению книгу Рика Смолана и Дженнифер Эрвитт «The Human Face of Big Data», а также труд «Introduction to Data Mining» Майкла Стейнбаха, Випин Кумар и Панг-Нинг Тан.
Закат эпохи Big Data / Habr
Множество иностранных авторов сходятся к тому, что эпоха Big Data подошла к концу. И в данном случае под термином Big Data понимаются технологии, основанные на Hadoop. Многие авторы, даже могут с уверенностью назвать дату, когда Big Data оставила этот мир и эта дата — 05.06.2019.Что же произошло в этот знаменательный день?
В этот день, компания MAPR обещала приостановить свою работу, если не сможет найти средства для дальнейшего функционирования. Позднее, в августе 2019 года MAPR был приобретен компанией HP. Но возвращаясь к июню нельзя не отметить, трагичность этого периода для рынка Big Data. В этом месяце произошел обвал биржевых котировок акций компании CLOUDERA – ведущего игрока на обозначенном рынке, которая произвела слияние с хронически неприбыльным HORTOWORKS в январе этого же года. Обвал был весьма существенен и составил 43%, в конечном итоге капитализация CLOUDERA снизилась с 4,1 до 1,4 миллиарда долларов.
Невозможно не сказать, что слухи о надувании пузыря в сфере технологий, базирующихся на Hadoop, ходили еще с декабря 2014 года, но он мужественно продержался еще почти пять лет. Слухи эти основывались на отказе Google, компании в которой зародилась технология Hadoop, от своего изобретения. Но технология, прижилась, на время перехода компаний к облачным средствам обработки и бурного развития искусственного интеллекта. Поэтому, оборачиваясь назад, можно с уверенностью сказать, что кончина была ожидаемой.
Таким образом, эра Big Data подошла к концу, но в процессе работы над большими данными компании осознали все нюансы работы над ними, выгоды, которые Big Data может принести бизнесу, а также научились пользоваться искусственным интеллектом для извлечения ценности из сырых данных.
Тем интереснее становится вопрос о том, что же придет на смену этой технологии и как будут дальше развиваться технологии аналитики.
Дополненная аналитика
Во время описываемых событий, компании, работающие в сфере анализа данных, не сидели на месте. О чем можно судить исходя из информации о сделках, произошедших в 2019 году. В текущем году была осуществлена крупнейшая сделка рынка – приобретение Salesforce аналитической платформы Tableau за 15,7 млрд. долларов. Менее крупная сделка произошла между Google и Looker. Ну и конечно нельзя не отметить приобретение компанией Qlik — биг дата платформы Attunity.
Лидеры рынка BI и специалисты Gartner заявляют о грандиозном сдвиге в подходах к анализу данных этот сдвиг полностью разрушит рынок BI и приведет к замене BI на AI. В данном контексте необходимо отметить, что аббревиатура AI это не «Artificial intelligence» а «Augmented Intelligence». Давайте поближе рассмотрим, что скрывается за словами «Дополненная аналитика».
Дополненная аналитика, как и дополненная реальность базируется на нескольких общих постулатах:
- возможностью общаться с использованием NLP (Natural Language Processing), т.е. на человеческом языке;
- использование искусственного интеллекта, это значит, что данные будут предварительно обработаны машинным интеллектом;
- и конечно же рекомендации, доступные пользователю системы, которые как раз-таки сгенерировал искусственный интеллект.
По мнение производителей аналитических платформ, их использование будет доступно для пользователей не обладающим специальными навыками, такими как знание SQL или подобного скриптового языка, не имеющих статистической или математической подготовки, не обладающими знаниями в области популярных языков, специализирующихся на обработке данных и соответствующих библиотек. Такие люди, называемые «Citizen Data Scientist», должны обладать лишь выдающейся бизнес квалификацией. Их задача – уловить бизнес-инсайты из подсказок и прогнозов, которые будет давать им искусственный интеллект, а уточнять свои догадки они смогут, используя NLP.
Описывая процесс работы пользователей с системами такого класса можно представить себе следующую картину. Человек, приходя на работу и запуская соответствующее приложение помимо привычного набора отчетов и дэшбордов, которые можно анализировать стандартными подходами (сортировка, группировка, выполнение арифметических действий) видит определенные подсказки и рекомендации, что-то типа: «Для того, чтобы достичь KPI по количеству продаж вам следует применить скидку на продукты из категории «Садоводство»». Кроме этого человек, может обратиться к корпоративному мессенджеру: Skype, Slack т.д. Может задать роботу вопросы, текстом или голосом: «Выведи мне пять самых прибыльных клиентов». Получив соответствующий ответ, он должен принять оптимальное решения, исходя из своего опыта в бизнесе и принести компании прибыль.
Если сделать шаг назад, и взглянуть на состав анализируемой информации, и на этом этапе продукты класса дополненной аналитики могут упростить жизнь людям. В идеале предполагается, что пользователю потребуется лишь указать аналитическому продукту на источники желаемой информации, а программа сама позаботится о создании модели данных, связке таблиц и тому подобных задачах.
Все это должно, прежде всего, обеспечить «демократизацию» данных, т.е. любой человек может заниматься анализом всего массива имеющейся у компании информации. Процесс принятия решений должен быть подкреплен методами статистического анализа. Время доступа к данным должно быть минимальным, так как не требуется писать скрипты и SQL запросы. Ну и конечно, можно будет сэкономить на высокооплачиваемых Data Science специалистах.
Гипотетически технологии открывают весьма радужные перспективы для бизнеса.
Что заменяет Big Data
Но, собственно, начал я свою статью с Big Data. И развить эту тему я не мог без краткого экскурса в современные BI инструменты, базой для которых, часто и служит Big Data. Судьба больших данных теперь четко предрешена, и это облачные технологии. Я акцентировал внимание на сделки, совершенные с BI производителями с целью демонстрации, что теперь каждая аналитическая система имеет под собой облачное хранение, а облачные сервисы имеют BI в качестве front end.
Не забывая о таких столпах в сфере баз данных как ORACLE и Microsoft необходимо отметить избранное ими направление развития бизнеса и это облако. Все предлагаемые сервисы можно найти в облаке, но некоторые облачные сервисы уже нельзя получить on-premise. Ими проделана значительная работа по использованию моделей машинного обучения, созданы библиотеки доступные пользователям, настроены интерфейсы для удобства работы с моделями от ее выбора до установки времени старта.
Еще одним важным преимуществом использования облачных сервисов, которое озвучивается производителями, является наличие практически неограниченных дата сетов по любой тематике, для тренировки моделей.
Однако, возникает вопрос, насколько облачные технологии приживутся в нашей стране?
Что такое на самом деле Big Data и чем они прекрасны. Лекция Андрея Себранта в Яндексе
Директор по маркетингу сервисов Яндекса Андрей Себрант рассказал студентам Малого ШАДа о том, что такое большие данные, и о тех, зачастую неожиданных местах, где они находят своё применение.Bid Data как понятие у всех на слуху уже не первый год. Но точное представление о том, что же представляет собой это понятие, есть далеко не у всех, особенно это касается людей за пределами IT-сферы. Проще всего несведущему человеку объяснить это на практическом примере.
Два года назад огромная сеть магазинов Target стала использовать машинное обучение при взаимодействии с покупателями. В качестве обучающей выборки использовались данные, накопленные компанией за несколько лет. В качестве маркеров конкретных покупателей использовались банковские и именные скидочные карты. Алгоритмы проанализировали, как и в каких условиях менялись предпочтения покупателей и делали прогнозы. А на основе этих прогнозов покупателям делались всевозможные специальные предложения. Весной 2012 года разразился скандал, когда отец двенадцатилетней школьницы пожаловался, что его дочери присылают буклеты с предложениями для беременных. Когда сеть Target уже приготовилась признавать ошибку и извиняться перед обиженными покупателями, выяснилось, что девочка действительно была беременна, хотя ни она, ни ее отец на момент жалобы не знали об этом. Алгоритм отловил изменения в поведении покупательницы, характерные для беременных женщин.
Признаки больших данных
- Volume: действительно большие (хотя размер зависит от доступных ресурсов для их обработки).
- Variety: слабо структурированные и разнородные.
- Velocity: обрабатывать надо очень быстро (причем и результаты часто нужны оперативно, если речь об онлайновых сервисах).
Применения могут быть самыми разнообразными. Например, сайт ancestry.com пытается построить семейную историю всего человечества, основываясь на всех доступных на сегодняшний день типах данных: от рукописных записей во всевозможных книгах учета до ДНК-анализа. На сегодняшний день им удалось собрать уже около пяти миллиардов профилей людей, живших в самые разные исторические эпохи, и 45 миллионов генеалогических деревьев, описывающих связи внутри семей.
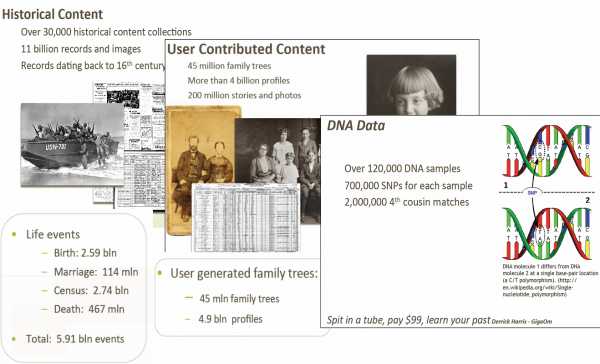
Главная сложность в этой работе заключается в том, что обрабатываемые данные страдают неполнотой, в них много неточностей, а идентифицировать людей нужно по отнюдь не уникальным именам, фамилиям, датам рождения, смерти и т.п. Стандартные алгоритмы не справляются с обработкой таких данных. Однако машинное обучение позволяет учитывать все эти неточности и с большой вероятностью выдавать правильные результаты.
Другой пример – проект eHarmony. Это сайт знакомств, на котором сейчас есть около 40 миллионов зарегистрированных пользователей. В анкетах можно указывать до 1000 различных признаков. Ежедневно система делает около 100 миллионов предположений о том, что два человека могут подходить друг другу.
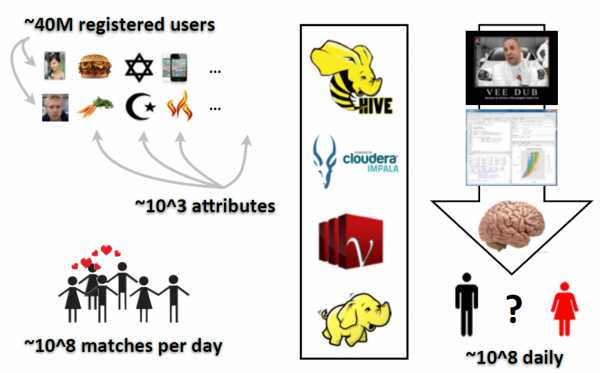
И предположения эти строятся не просто на банальном нахождении соответствий в указанных пользователями свойствах и пристрастиях. Например, выяснилось, что относительная площадь лица на фотографии в профиле может влиять на вероятность контакта между определенными людьми. Кроме того, оказалось, что люди с пристрастиями к определенным видам пищи могут обладать разной совместимостью друг с другом. Два вегетарианца с вероятностью в 44% найдут общий язык и начнут общение, в то время как два любителя гамбургеров с вероятностью 42% никаких отношений не заведут.

Самое интересное во всем этом, что применяя машинное обучение для принятия решений, мы перестаем понимать, на основе каких принципов они принимаются. Конечно, машинное обучение нельзя назвать искусственным интеллектом в прямом смысле, ведь решать он может только ту задачу, для которой был обучен. Но те сотни и тысячи факторов, которые принимает во внимание обученный алгоритм, могут просто не приходить нам в голову. Обучившись, алгоритм может лучше любого юзабелиста определять, какой дизайн кнопки показать конкретному пользователю, тут огромный объем данных сработает лучше опыта и умений человека. Но вот сконструировать хороший сайт с нуля при помощи машинного обучения пока не выйдет.
Посмотрев лекцию до конца, вы сможете составить общее представление о том, как работает машинное обучение. А подробнее ознакомиться с этой темой можно при помощи лекций о машинном обучении и компьютерном зрении.
Big Data: характеристики, классификация, полезность, примеры
Что такое Big Data (дословно — большие данные)? Обратимся сначала к оксфордскому словарю:
Данные — величины, знаки или символы, которыми оперирует компьютер и которые могут храниться и передаваться в форме электрических сигналов, записываться на магнитные, оптические или механические носители.
Термин Big Data используется для описания большого и растущего экспоненциально со временем набора данных. Для обработки такого количества данных не обойтись без машинного обучения.
Преимущества, которые предоставляет Big Data:
- Сбор данных из разных источников.
- Улучшение бизнес-процессов через аналитику в реальном времени.
- Хранение огромного объема данных.
- Инсайты. Big Data более проницательна к скрытой информации при помощи структурированных и полуструктурированных данных.
- Большие данные помогают уменьшать риск и принимать умные решения благодаря подходящей риск-аналитике
Примеры Big Data
Нью-Йоркская Фондовая Биржа ежедневно генерирует 1 терабайт данных о торгах за прошедшую сессию.
Социальные медиа: статистика показывает, что в базы данных Facebook ежедневно загружается 500 терабайт новых данных, генерируются в основном из-за загрузок фото и видео на серверы социальной сети, обмена сообщениями, комментариями под постами и так далее.
Реактивный двигатель генерирует 10 терабайт данных каждые 30 минут во время полета. Так как ежедневно совершаются тысячи перелетов, то объем данных достигает петабайты.
Классификация Big Data
Формы больших данных:
- Структурированная
- Неструктурированная
- Полуструктурированная
Структурированная форма
Данные, которые могут храниться, быть доступными и обработанными в форме с фиксированным форматом называются структурированными. За продолжительное время компьютерные науки достигли больших успехов в совершенствовании техник для работы с этим типом данных (где формат известен заранее) и научились извлекать пользу. Однако уже сегодня наблюдаются проблемы, связанные с ростом объемов до размеров, измеряемых в диапазоне нескольких зеттабайтов.
1 зеттабайт соответствует миллиарду терабайт
Глядя на эти числа, нетрудно убедиться в правдивости термина Big Data и трудностях сопряженных с обработкой и хранением таких данных.
Данные, хранящиеся в реляционной базе — структурированы и имеют вид ,например, таблицы сотрудников компании
Неструктурированная форма
Данные неизвестной структуры классифицируются как неструктурированные. В дополнении к большим размерам, такая форма характеризуется рядом сложностей для обработки и извлечении полезной информации. Типичный пример неструктурированных данных — гетерогенный источник, содержащий комбинацию простых текстовых файлов, картинок и видео. Сегодня организации имеют доступ к большому объему сырых или неструктурированных данных, но не знают как извлечь из них пользу.
Примером такой категории Big Data является результат Гугл поиска:
Полуструктурированная форма
Эта категория содержит обе описанные выше, поэтому полуструктурированные данные обладают некоторой формой, но в действительности не определяются с помощью таблиц в реляционных базах. Пример этой категории — персональные данные, представленные в XML файле.
<rec><name>Prashant Rao</name><sex>Male</sex><age>35</age></rec> <rec><name>Seema R.</name><sex>Female</sex><age>41</age></rec> <rec><name>Satish Mane</name><sex>Male</sex><age>29</age></rec> <rec><name>Subrato Roy</name><sex>Male</sex><age>26</age></rec> <rec><name>Jeremiah J.</name><sex>Male</sex><age>35</age></rec>
Характеристики Big Data
Рост Big Data со временем:
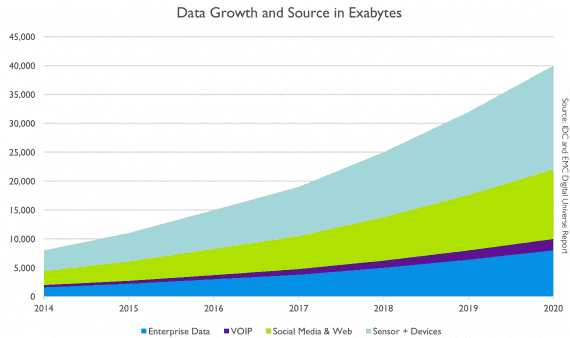
Синим цветом представлены структурированные данные (Enterprise data), которые сохраняются в реляционных базах. Другими цветами — неструктурированные данные из разных источников (IP-телефония, девайсы и сенсоры, социальные сети и веб-приложения).
В соответствии с Gartner, большие данные различаются по объему, скорости генерации, разнообразию и изменчивости. Рассмотрим эти характеристики подробнее.
- Объем. Сам по себе термин Big Data связан с большим размером. Размер данных — важнейший показатель при определении возможной извлекаемой ценности. Ежедневно 6 миллионов людей используют цифровые медиа, что по предварительным оценкам генерирует 2.5 квинтиллиона байт данных. Поэтому объем — первая для рассмотрения характеристика.
- Разнообразие — следующий аспект. Он ссылается на гетерогенные источники и природу данных, которые могут быть как структурированными, так и неструктурированными. Раньше электронные таблицы и базы данных были единственными источниками информации, рассматриваемыми в большинстве приложений. Сегодня же данные в форме электронных писем, фото, видео, PDF файлов, аудио тоже рассматриваются в аналитических приложениях. Такое разнообразие неструктурированных данных приводит к проблемам в хранении, добыче и анализе: 27% компаний не уверены, что работают с подходящими данными.
- Скорость генерации. То, насколько быстро данные накапливаются и обрабатываются для удовлетворения требований, определяет потенциал. Скорость определяет быстроту притока информации из источников — бизнес процессов, логов приложений, сайтов социальных сетей и медиа, сенсоров, мобильных устройств. Поток данных огромен и непрерывен во времени.
- Изменчивость описывает непостоянство данных в некоторые моменты времени, которое усложняет обработку и управление. Так, например, большая часть данных неструктурирована по своей природе.
Big Data аналитика: в чем польза больших данных
Продвижение товаров и услуг: доступ к данным из поисковиков и сайтов, таких как Facebook и Twitter, позволяет предприятиям точнее разрабатывать маркетинговые стратегии.
Улучшение сервиса для покупателей: традиционные системы обратной связи с покупателями заменяются на новые, в которых Big Data и обработка естественного языка применяется для чтения и оценки отзыва покупателя.
Расчет риска, связанного с выпуском нового продукта или услуги.
Операционная эффективность: большие данные структурируют, чтобы быстрее извлекать нужную информацию и оперативно выдавать точный результат. Такое объединение технологий Big Data и хранилищ помогает организациям оптимизировать работу с редко используемой информацией.
Интересные статьи:
Big Data - что такое системы больших данных? Развитие технологий Big Data
Содержание статьи:
Большие данные — определение
Под термином «большие данные» буквально понимают огромный объем хранящейся на каком-либо носителе информации. Причем данный объем настолько велик, что обрабатывать его с помощью привычных программных или аппаратных средств нецелесообразно, а в некоторых случаях и вовсе невозможно.
Big Data – это не только сами данные, но и технологии их обработки и использования, методы поиска необходимой информации в больших массивах. Проблема больших данных по-прежнему остается открытой и жизненно важной для любых систем, десятилетиями накапливающих самую разнообразную информацию.
С данным термином связывают выражение «Volume, Velocity, Variety» – принципы, на которых строится работа с большими данными. Это непосредственно объем информации, быстродействие ее обработки и разнообразие сведений, хранящихся в массиве. В последнее время к трем базовым принципам стали добавлять еще один – Value, что обозначает ценность информации. То есть, она должна быть полезной и нужной в теоретическом или практическом плане, что оправдывало бы затраты на ее хранение и обработку.
Источники больших данных

В качестве примера типичного источника больших данных можно привести социальные сети – каждый профиль или публичная страница представляет собой одну маленькую каплю в никак не структурированном океане информации. Причем независимо от количества хранящихся в том или ином профиле сведений взаимодействие с каждым из пользователей должно быть максимально быстрым.
Большие данные непрерывно накапливаются практически в любой сфере человеческой жизни. Сюда входит любая отрасль, связанная либо с человеческими взаимодействиями, либо с вычислениями. Это и социальные медиа, и медицина, и банковская сфера, а также системы устройств, получающие многочисленные результаты ежедневных вычислений. Например, астрономические наблюдения, метеорологические сведения и информация с устройств зондирования Земли.
Big Data на российском рынке наружной рекламы
Информация со всевозможных систем слежения в режиме реального времени также поступает на сервера той или иной компании. Телевидение и радиовещание, базы звонков операторов сотовой связи – взаимодействие каждого конкретного человека с ними минимально, но в совокупности вся эта информация становится большими данными.
Технологии больших данных стали неотъемлемыми от научно-исследовательской деятельности и коммерции. Более того, они начинают захватывать и сферу государственного управления – и везде требуется внедрение все более эффективных систем хранения и манипулирования информацией.
История появления и развития Big Data

Впервые термин «большие данные» появился в прессе в 2008 году, когда редактор журнала Nature Клиффорд Линч выпустил статью на тему развития будущего науки с помощью технологий работы с большим количеством данных. До 2009 года данный термин рассматривался только с точки зрения научного анализа, но после выхода еще нескольких статей пресса стала широко использовать понятие Big Data – и продолжает использовать его в настоящее время.
В 2010 году стали появляться первые попытки решить нарастающую проблему больших данных. Были выпущены программные продукты, действие которых было направлено на то, чтобы минимизировать риски при использовании огромных информационных массивов.
К 2011 году большими данными заинтересовались такие крупные компании, как Microsoft, Oracle, EMC и IBM – они стали первыми использовать наработки Big data в своих стратегиях развития, причем довольно успешно.
ВУЗы начали проводить изучение больших данных в качестве отдельного предмета уже в 2013 году – теперь проблемами в этой сфере занимаются не только науки о данных, но и инженерия вкупе с вычислительными предметами.
Техники и методы анализа и обработки больших данных

К основным методам анализа и обработки данных можно отнести следующие:
- Методы класса или глубинный анализ (Data Mining).
Данные методы достаточно многочисленны, но их объединяет одно: используемый математический инструментарий в совокупности с достижениями из сферы информационных технологий.
- Краудсорсинг.
Данная методика позволяет получать данные одновременно из нескольких источников, причем количество последних практически не ограничено.
- А/В-тестирование.
Из всего объема данных выбирается контрольная совокупность элементов, которую поочередно сравнивают с другими подобными совокупностями, где был изменен один из элементов. Проведение подобных тестов помогает определить, колебания какого из параметров оказывают наибольшее влияние на контрольную совокупность. Благодаря объемам Big Data можно проводить огромное число итераций, с каждой из них приближаясь к максимально достоверному результату.
- Прогнозная аналитика.
Специалисты в данной области стараются заранее предугадать и распланировать то, как будет вести себя подконтрольный объект, чтобы принять наиболее выгодное в этой ситуации решение.
- Машинное обучение (искусственный интеллект).
Основывается на эмпирическом анализе информации и последующем построении алгоритмов самообучения систем.
- Сетевой анализ.
Наиболее распространенный метод для исследования социальных сетей – после получения статистических данных анализируются созданные в сетке узлы, то есть взаимодействия между отдельными пользователями и их сообществами.
Перспективы и тенденции развития Big data
В 2017 году, когда большие данные перестали быть чем-то новым и неизведанным, их важность не только не уменьшилась, а еще более возросла. Теперь эксперты делают ставки на то, что анализ больших объемов данных станет доступным не только для организаций-гигантов, но и для представителей малого и среднего бизнеса. Такой подход планируется реализовать с помощью следующих составляющих:
- Облачные хранилища.
Хранение и обработка данных становятся более быстрыми и экономичными – по сравнению с расходами на содержание собственного дата-центра и возможное расширение персонала аренда облака представляется гораздо более дешевой альтернативой.
- Использование Dark Data.
Так называемые «темные данные» – вся неоцифрованная информация о компании, которая не играет ключевой роли при непосредственном ее использовании, но может послужить причиной для перехода на новый формат хранения сведений.
- Искусственный интеллект и Deep Learning.
Технология обучения машинного интеллекта, подражающая структуре и работе человеческого мозга, как нельзя лучше подходит для обработки большого объема постоянно меняющейся информации. В этом случае машина сделает все то же самое, что должен был бы сделать человек, но при этом вероятность ошибки значительно снижается.
Эта технология позволяет ускорить и упростить многочисленные интернет-транзакции, в том числе международные. Еще один плюс Блокчейна в том, что благодаря ему снижаются затраты на проведение транзакций.
- Самообслуживание и снижение цен.
В 2017 году планируется внедрить «платформы самообслуживания» – это бесплатные площадки, где представители малого и среднего бизнеса смогут самостоятельно оценить хранящиеся у них данные и систематизировать их.
Большие данные в маркетинге и бизнесе

Все маркетинговые стратегии так или иначе основаны на манипулировании информацией и анализе уже имеющихся данных. Именно поэтому использование больших данных может предугадать и дать возможность скорректировать дальнейшее развитие компании.
Методы машинного обучения для бизнеса
К примеру, RTB-аукцион, созданный на основе больших данных, позволяет использовать рекламу более эффективно – определенный товар будет показываться только той группе пользователей, которая заинтересована в его приобретении.
Чем выгодно применение технологий больших данных в маркетинге и бизнесе?
- С их помощью можно гораздо быстрее создавать новые проекты, которые с большой вероятностью станут востребованными среди покупателей.
- Они помогают соотнести требования клиента с существующим или проектируемым сервисом и таким образом подкорректировать их.
- Методы больших данных позволяют оценить степень текущей удовлетворенности всех пользователей и каждого в отдельности.
- Повышение лояльности клиентов обеспечивается за счет методов обработки больших данных.
- Привлечение целевой аудитории в интернете становится более простым благодаря возможности контролировать огромные массивы данных.
Например, один из самых популярных сервисов для прогнозирования вероятной популярности того или иного продукта – Google.trends. Он широко используется маркетологами и аналитиками, позволяя им получить статистику использования данного продукта в прошлом и прогноз на будущий сезон. Это позволяет руководителям компаний более эффективно провести распределение рекламного бюджета, определить, в какую область лучше всего вложить деньги.
Примеры использования Big Data
Активное внедрение технологий Big Data на рынок и в современную жизнь началось как раз после того, как ими стали пользоваться всемирно известные компании, имеющие клиентов практически в каждой точке земного шара.
Это такие социальные гиганты, как Facebook и Google, IBM., а также финансовые структуры вроде Master Card, VISA и Bank of America.
К примеру, IBM применяет методы больших данных к проводимым денежным транзакциям. С их помощью было выявлено на 15% больше мошеннических транзакций, что позволило увеличить сумму защищенных средств на 60%. Также были решены проблемы с ложными срабатываниями системы – их число сократилось более, чем наполовину.
Компания VISA аналогично использовала Big Data, отслеживая мошеннические попытки произвести ту или иную операцию. Благодаря этому ежегодно они спасают от утечки более 2 млрд долларов США.
Министерство труда Германии сумело сократить расходы на 10 млрд евро, внедрив систему больших данных в работу по выдаче пособий по безработице. При этом было выявлено, что пятая часть граждан данные пособия получает безосновательно.
Big Data не обошли стороной и игровую индустрию. Так, разработчики World of Tanks провели исследование информации обо всех игроках и сравнили имеющиеся показатели их активности. Это помогло спрогнозировать возможный будущий отток игроков – опираясь на сделанные предположения, представители организации смогли более эффективно взаимодействовать с пользователями.
К числу известных организаций, использующих большие данные, можно также отнести HSBC, Nasdaq, Coca-Cola, Starbucks и AT&T.
Проблемы Big Data

Самой большой проблемой больших данных являются затраты на их обработку. Сюда можно включить как дорогостоящее оборудование, так и расходы на заработную плату квалифицированным специалистам, способным обслуживать огромные массивы информации. Очевидно, что оборудование придется регулярно обновлять, чтобы оно не теряло минимальной работоспособности при увеличении объема данных.
Вторая проблема опять же связана с большим количеством информации, которую необходимо обрабатывать. Если, например, исследование дает не 2-3, а многочисленное количество результатов, очень сложно остаться объективным и выделить из общего потока данных только те, которые окажут реальное влияние на состояние какого-либо явления.
Проблема конфиденциальности Big Data. В связи с тем, что большинство сервисов по обслуживанию клиентов переходят на онлайн-использование данных, очень легко стать очередной мишенью для киберпреступников. Даже простое хранение личной информации без совершения каких-либо интернет-транзакций может быть чревато нежелательными для клиентов облачных хранилищ последствиями.
Проблема потери информации. Меры предосторожности требуют не ограничиваться простым однократным резервированием данных, а делать хотя бы 2-3 резервных копии хранилища. Однако с увеличением объема растут сложности с резервированием – и IT-специалисты пытаются найти оптимальное решение данной проблемы.
Рынок технологий больших данных в России и мире
По данным на 2014 год 40% объема рынка больших данных составляют сервисные услуги. Немного уступает (38%) данному показателю выручка от использования Big Data в компьютерном оборудовании. Оставшиеся 22% приходятся на долю программного обеспечения.
Наиболее полезные в мировом сегменте продукты для решения проблем Big Data, согласно статистическим данным, – аналитические платформы In-memory и NoSQL . 15 и 12 процентов рынка соответственно занимают аналитическое ПО Log-file и платформы Columnar. А вот Hadoop/MapReduce на практике справляются с проблемами больших данных не слишком эффективно.
Результаты внедрения технологий больших данных:
- рост качества клиентского сервиса;
- оптимизация интеграции в цепи поставок;
- оптимизация планирования организации;
- ускорение взаимодействия с клиентами;
- повышение эффективности обработки запросов клиентов;
- снижение затрат на сервис;
- оптимизация обработки клиентских заявок.
Лучшие книги по Big Data
«The Human Face of Big Data», Рик Смолан и Дженнифер Эрвитт
Подойдет для первоначального изучения технологий обработки больших данных – легко и понятно вводит в курс дела. Дает понять, как обилие информации повлияло на повседневную жизнь и все ее сферы: науку, бизнес, медицину и т. д. Содержит многочисленные иллюстрации, поэтому воспринимается без особых усилий.
«Introduction to Data Mining», Панг-Нинг Тан, Майкл Стейнбах и Випин Кумар
Также полезная для новичков книга по Big Data, объясняющая работу с большими данными по принципу «от простого к сложному». Освещает многие немаловажные на начальном этапе моменты: подготовку к обработке, визуализацию, OLAP, а также некоторые методы анализа и классификации данных.
«Python Machine Learning», Себастьян Рашка
Практическое руководство по использованию больших данных и работе с ними с применением языка программирования Python. Подходит как студентам инженерных специальностей, так и специалистам, которые хотят углубить свои знания.
«Hadoop for Dummies», Дирк Дерус, Пол С. Зикопулос, Роман Б. Мельник
Hadoop – это проект, созданный специально для работы с распределенными программами, организующими выполнение действий на тысячах узлов одновременно. Знакомство с ним поможет более детально разобраться в практическом применении больших данных.
Big Data головного мозга / Habr
Наверно, в мире данных нет подобного феномена настолько неоднозначного понимания того, что же такое Hadoop. Ни один подобный продукт не окутан таким большим количеством мифов, легенд, а главное непонимания со стороны пользователей. Не менее загадочным и противоречивым является термин "Big Data", который иногда хочется писать желтым шрифтом(спасибо маркетологам), а произносить с особым пафосом. Об этих двух понятиях — Hadoop и Big Data я бы хотел поделиться с сообществом, а возможно и развести небольшой холивар.
Возможно статья кого-то обидит, кого-то улыбнет, но я надеюсь, что не оставит никого равнодушным.

Демонстрация Hadoop пользователям
Начнем с истоков.
Первая половина 2000х, Google: мы сделали отличный инструмент — молоток, он хорошо забивает гвозди. Этот молоток состоит из ручки и бойка, но только мы с вами им не поделимся.
2006 год, Дуг Кайтинг: привет, народ, я тут сделал такой же молоток, как у Google и он действительно хорошо забивает гвозди, к слову сказать, я тут попробовал забивать им небольшие шурупы и вы не поверите, он более-менее справился с этим.
2010 год, Пол 30 лет: Парни, молоток работает, даже больше, он отлично забивает болты. Конечно, отверстие надо немного подготовить, но инструмент очень перспективный.
2012 год, Пол 32 года: Оказывается молотком можно рубить деревья, конечно, это немного дольше, чем топором, но он, мать его, работает! И за все за это мы не заплатили ни копейки Так же мы хотим построить с помощью молотка небольшой дом. Пожелайте нам удачи.
2013 год, Дуг: Мы оснастили молоток лазерным прицелом — теперь можно его метать, встроенный нож позволит вам более эффективно рубить деревья. Все бесплатно, все ради людей.
2015 год, Дэн, 25 лет: я кошу траву молотком… каждый день. Это немного сложно, но мне, черт возьми, нравится, мне нравится работать руками!
Если действительно разобраться и копнуть немного глубже, то Google, а потом и Дуг сделали инструмент(и далеко не идеальный, как призналось Google, спустя несколько лет), для решения конкретного класса задач — построение поискового индекса.
Инструмент получился неплохим, но есть одна проблема, в прочем, обо всем по порядку.
В начале 2012 года начался агрессивный тренд — "эпоха big data".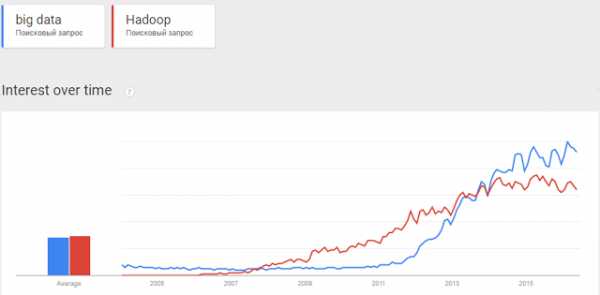
Именно с этого момента начали появляться бесполезные статьи и даже книги в стиле "Как стать big data company" или "Большие данные решают все". Ни одна из конференций больше не обходилась без рассуждений о том, "с какого терабайта начиналась big data" и повторяющихся историй о том, как "одна компания была почти на грани дефолта, но таки перешла на большие данные и она просто порвала рынок". Вся это пустая болтовня подкармливалась грамотным маркетингом от компаний, которые продавали поддержку на все это — спонсировались хакатоны, семинары и много-много всего.
В конечном итоге у большого количества людей сложилась конкретная картина мира, в которой традиционные решения — это медленно, это дорого, да и как минимум, это больше не модно.
Прошло уже много лет, но до сих пор я вижу обсуждения и статьи с заголовками "Map Reduce: first steps" или "Big Data: What Does it Really Mean?" на профессиональных ресурсах.
Hadoop как средство для индексирования
И так, что же все-таки такое Hadoop? В общих словах это файловая система HDFS и набор инструментов для обработки данных.
Все же этот блог технический, позволю себе вот такую вот картинку:
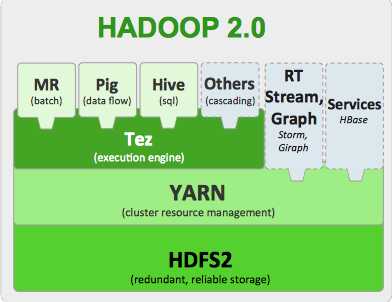
Компоненты Hadoop 2
Все это размазано по кластеру из "дешевого железа" и по мнению маркетологов должно в мановение ока завалить вас деньгами, которые будут приносить "большие данные".
Крупные интернет-компании, например Yahoo, в свое время, оценили Hadoop, как средство обработки больших объемов информации. Используя MapReduce, они могли строить поисковые индексы на кластерах из тысяч машин.
Надо сказать, тогда это было действительно прорывом — Open Source продукт умеет решать задачи такого класса и все это бесплатно. Yahoo сделало ставку на то, что возможно в будущем им бы не пришлось выращивать специалистов, а набирать со стороны уже готовых.
Но я не знаю когда первая обезьяна спустилась с дерева, взяла палку и начала использовать MapReduce для аналитики данных, но факт остается фактом, MapReduce начал реально появляться там, где это совершенно не нужно.
Hadoop MapReduce как средство для аналитики
Если у вас одна большая таблица, например, логи пользователей, то MR с натяжкой мог бы сгодиться для подсчета количества строк или уникальных записей. Но у этого фреймворка были фундаментальные недостатки:
Каждый шаг MapReduce порождает большую нагрузку на диски, что замедляет общую работу. Результаты работы каждого этапа сбрасываются на диск.
Инициализация "воркеров" занимает относительно большое время, что приводит к большим задержкам, даже для простых запросов.
Число "маперов" и "редьюсеров" постоянно во время выполнения, ресурсы делятся между этими группами процессов и если, например, маперы уже прекратили свою работу, то ресурсы редьюсерам уже не освободятся.
Все это более-менее эффективно работает на простых запросах. Операции JOIN больших таблиц будут работать крайне не эффективно — нагрузка на сеть.
Не смотря на весь этот комплекс проблем, MapReduce заслужил большую популярность в области анализа данных. Когда новички начинают свое знакомство с Hadoop, первое что они видят — MapReduce, "ну ок" — говорят они, — "надо изучать". По факту инструмент для аналитики бесполезен, но маркетинг сыграл злую шутку с MR. Интерес пользователей не только не угасает, но и подпитывается новичками(я пишу эту статью в июне 2016).
Для анализа заинтересованности в технологии со стороны бизнеса я решил использовать HeadHunter.ru как основную площадку поиска предложений по работе.
И еще можно встретить такие интересные вакансии на HH.ru по ключевым словам MapReduce:
На момент написания статьи было 30 вакансий только в Москве, и это от уважаемых и успешных фирм. Сразу скажу, что я не анализировал глубоко эти предложения, но позитивная динамика все же имеется, около года назад подобных предложений было больше.
Конечно, люди размещавшие вакансию могли просто написать, что попало и, возможно, HeadHunter это не лучшее средство для подобной аналитки, но более подходящих инструментов измерения заинтересованности бизнеса я найти не смог.
Spark как средство для аналитики
Конечно, умные люди сразу поняли, что c MR ловить нечего и придумали Spark, который кстати так же живет под крылом ASF. Spark — это MR на стероидах и как говорят разработчики быстрее MapReduce в более чем 100 раз.
Сферический Spark в вакууме быстрее MapReduce
Spark хорош тем, что лишен перечисленных недостатков MR.
Но мы уже выходим на другой уровень и недостатки снова появляются:
Хардкод и усердный код на Java превращает простые запросы в месиво, которое невозможно будет читать в будущем. Поддержка SQL пока слабая.
Нет стоимостной оптимизации. С этой проблемой можно столкнуться при соединении таблиц.
Spark не понимает, как данные лежат в HDFS. Это хоть и MPP-система, но при соединении больших таблиц возникает ситуация, когда соединяемые данные находятся на разных узлах, что приводит к нагрузке на сеть.
Хотя в целом Spark штука годная, но возможно его убьет рынок труда, так как искать дорогих специалистов на Java или Scala, которые будут хардкодить вам аналитику очень и очень тяжело, особенно если вы no-name-company(произносить с особым пафосом, если работаете в такой).
Так же вместе со Spark зародилось интересное решение — Spark Streaming и, возможно, это будет действительно таким "долгоиграющим" решением.
Spark штука простая, надежная и его можно развернуть без Hadoop.
Поживем увидим.
Предложение по вакансиями немного лучше чем по MapReduce, они более зрелые и похоже их писали плюс-минус понимающие люди
Количество подобных предложений — 56 штук.

А теперь несколько мифов о Hadoop и BigData
Миф 1. Hadoop — это бесплатно
В наши дни мы использует очень много OpenSource продуктов и даже не задумываемся о том, почему мы за них не платим. Конечно, бесплатный сыр бывает только в мышеловке и платить, в конце концов, приходится, особенно за Hadoop.
Hadoop и все что с ним связано, активно позиционируется маркетологами под флагами бесплатности, мира и братства. Но в действительности, использовать собственную сборку Hadoop рискнут не многие — продукт достаточно сырой и до сих пор многими непонятный.
Компании придется нанимать дорогих специалистов, при этом задачи они будут решать дольше и усерднее. В конце концов вместо того, что бы решать задачи обработки данных, сотрудники будут решать проблемы латания дыр в сыром софте и построению костылей.
Конечно, речь не касается других зрелых OpenSource продуктов, типа MySQL, Postgres и т.п., которые активно используются в боевых системах, но даже тут, множество компаний пользуется платной профессиональной поддержкой.
Прежде чем решать, нужен ли вам бесплатный продукт, посчитайте, так ли он бесплатен. Возможно, с вашими задачами по сбору зерна с полей, с одинаковым успехом справится и вчерашний студент на современном комбайне и группа дорогих Java-кодеров, с бесплатными молотками-серпами.
Ок, Hadoop, это не бесплатно, допустим, но Hadoop работает на дешевом железе! И снова мимо. Hadoop хоть и работает на дешевом железе, для быстрого и надежного решения задач вам все равно потребуются нормальные сервера — на "десктопах" это работать не будет. Для годной работы Hadoop потребуется железо такого же класса, как и для работы любых других аналитических MPP-систем. По рекомендации Cloudera в
зависимости от задач необходимо:
- 2 CPU c 4-8-16 Ядрами
- 12-24 JBOD дисков
- 64-512GB of RAM
- 10 Gbit Net
Прошу заметить, что RAID отсутствует, но избыточность Hadoop на уровне софта требует примерно такого же количества дисков.
Миф 2. Hadoop для обработки неструктурированной информации.
Другой не менее примечательный миф говорит нам о том, что "Hadoop необходим для обработки неструктурированной информации", а такой неструктурированной информацией как раз и является Big Data :-). Но давайте разберемся сначала, что же такое неструктурированная информация.
Таблицы — это точно структурированная информация, это бесспорно.
А вот JSON, XML, YAM — называют полу-структурированной информацией.
Но и такие форматы имеют структуру, только не такую явную как структура таблиц.
Другая актуальная тема — логи, по мнению популяризаторов BigData — не имеют структуры.
На самом деле структура есть, логи вполне себе нормально записываются в таблицы и обрабатываются без MapReduce
Твиттер:
На самом деле, структура есть почти у всех данных, которые нам могут пригодиться. Она может быть разрозненная, не удобная для обработки, но она есть.
Даже такие данные, например, видео или аудио информация могут быть представлены в виде виде структуры которую можно распределить на большое количество серверов и обрабатывать.
Видео-файлы:
Скорее всего, там, где вы работаете, нет неструктурированной информации. И ваша информация может быть разрозненной и "грязной", но какая-то структура у нее все равно имеется. В таком случае, у вас действительно проблемы и нужно решать в первую очередь их.
Конечно, есть информация, которую нельзя эффективно "размазать" по большому кластеру, например генетическая информация или огромный файловый архив, но таких кейсов чрезвычайно мало и для "бизнес-аналитики" они не интересны, такие задачи решаются другими средствами совершенно на другом уровне(если знаете, расскажите).
Если вы знаете какие-то действительно неструктурированные источники информации, которые нельзя просто так обработать в распределенном кластере, пожалуйста, пишите в комментариях.
Миф 3. Любая проблема решается через технологии Big Data
Еще один интересный термин навязанный обществу — "технологии Big Data". Конечно, никакого логического определения того, что такое Big Data конечно нет, тем более нет определения "технологий Big Data".
Принято считать, что все, что связано с Hadoop — это "технологии Big Data"
Но Hadoop и все что с ним связано, очень хорошо замаскированный, аккуратный суперфункциональный швейцарский нож-молоток. Им можно рубить деревья, косить траву, забивать болты. Он справляется со всеми задачами, но вот только когда дело доходит до решения конкретной задачи, особенно когда нужно сделать это качественно, такой швейцарский нож-молоток только усложнит вам жизнь.
Impala, Dill, Kudu — новые игроки
Конечно, еще более умные люди, чем все остальные, посмотрели на весь этот бардак и решили создать свой лунапарк.
Три зверька Impala, Drill и Kudu появились примерно одновременно и не совсем давно.
Это такие же МРР-движки поверх HDFS как Spark и MR, но разница между ними такая же, как между едой и закуской — огромная. Продукты так же находятся под крылом, многоуважаемого ASF. В принципе, всеми тремя проектами можно пользоваться уже сейчас, не смотря что они на стадии так называемой "инкубации".
Кстати, Impala и Kudu находятся под крылом Cloudera, а Drill вышел из компании Dremio.
Из всего зверинца я бы выделил Apache Kudu как самый интересный инструмент из представленных с четким и зрелым roadmap.
Преимущества Kudu следующие:
Kudu понимает, как лежат данные в HDFS и понимает как их правильно класть в HDFS, чтобы оптимизировать будущие запросы. Директива distributed by.
Только SQL и никакого хардкода.
Из явных недостатков можно выделить отсутствие Cost-based оптимизатора, но это лечится и возможно в будущих релизах мы Kudu предстанет во всей красе. Все эти 3 продукта плюс-минус примерно одинаковые, по этому, рассмотрим архитектуру на примере Apache Impala:
Как мы видим, имеются экземпляры СУБД — Impala, которые уже работает с данными на своей конкретной ноде. При подключении клиента к одному из узлов он становится управляющим. Архитектура достаточно похожа на Vertica, Teradata(верхнеуровнево и очень приближенно). Основная задача при работе с такими системами сводится к тому, чтобы правильно "размазать" данные по кластеру, чтобы в дальнейшем эффективно с ними работать.
При всех своих достоинствах, разработчики пиарят свои системы как "федеравтивные", то есть: берем таблицу Kuda, связываем ее с плоским файлом, все это смешиваем с Postgres и приправляем MySQL. То есть у нас появляется возможность работать с гетерогенными источниками как с обычными таблицами или нереляционными структурами(JSON) как с таблицами. Но у такого подхода есть своя цена — оптимизатор не понимает статистику внешних источников, так же такие внешние таблицы становятся узким горлышком при выполнении запросов, так как, по сути, работают в "один поток".
Другой важный момент — необходимость HDFS. HDFS в такой архитектуре превращается в бесполезный аппендикс, который только усложняет работу системы — лишний слой абстракции, который имеет свои накладные расходы. Так же, HDFS может быть развернута поверх не совсем эффективных или не правильно настроенных файловых систем, что может привести к фрагментации файлов данных и потери производительности.
Конечно, HDFS можно использовать как помойку всего и вся, скидывая в нее все нужное и ненужное. Такой подход последнее время называется "Data Lake", но не стоит забывать, что анализировать неподготовленные данные будет сложнее в будущем. Последователи такого подхода аргументируют преимущества тем, что данные, возможно, и не придется анализировать, следовательно, нет необходимости тратить времени на их подготовку. В общем, решать, по какому пути идти, все же, вам.
Никаких предложений по работе и интересов компаний в сторону Kudu-подобных продуктов нет, а зря.
Немного маркетинга
Вы, наверно, заметили явный тренд в сторону того, что весь этот цирк в области аналитики данных движется в сторону традиционных аналитических MPP-систем (Teradata, Vertica, GPDB и т.п.).
Все аналитические MPP-системы развиваются в одном направлении, только при этом две разные группы идут к этому с разных сторон.
Первая группа — идет по пути "шардирования" традиционных SQL СУБД.
Вторая группа — идет по родословной от MR и HDFS.
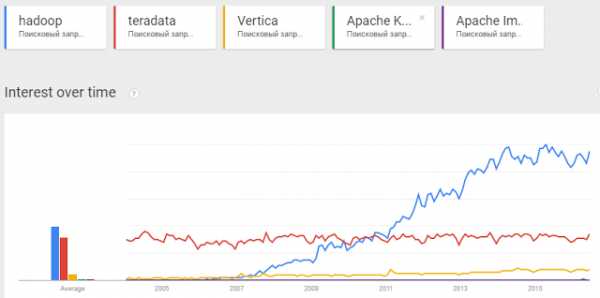
Пользователи проявляют интерес к слову Hadoop
Лавинообразный рост Hadoop конечно обусловлен очень грамотным маркетингом со стороны компаний, продающих эти решения.
Компании смогли вырастить в умах людей идею того, что Hadoop бесплатен, он прост и быстр и легок, а еще… нет бога кроме Hadoop.
Напор был таким сильным, что даже Teradata не смогла совладать с собой и вместо того, что бы самой формировать рынок, начала продавать решения на базе Hadoop и нанимать специалистов. Не говоря уже о других игроках рынка, которые дружно родили поделия под названием "AnyDumbSoft Big Data Edition", в большинстве случаев использующие стандартные коннекторы к HDFS.
Тренду поддался даже Oracle, выпустивший "Big data appliance" или "Golden Gate for Big data". Первый продукт — это просто готовая железка с "золотым" CDH от Cloudera, а в продукт номер два просто добавлены Java-коннекторы для Kafka(брокер сообщений), HBase и остального зоопарка. Сделать это мог любой пользователь самостоятельно.
Big Data больного человека
К сожалению, это тренд, это мейнстрим, который сметет любую стабильную компанию, если она рискнет пойти против течения. Кстати, я отчасти тоже рискую быть закиданным помидорами, освещая данную тему.
Apache HAWQ (Pivotal HDB).
Pivotal пошел дальше всех. Они взяли традиционный Greenplum и натянули его на HDFS. Весь движок обработки данных остался за Postgres, но сами файлы данных хранятся в HDFS. Какой-то практической целесообразности в этом мало.
Вы получаете в распоряжение такой же Greenplum, с более сложным администрированием, но продают вам его и рекламируют как Hadoop.
Apache HAWQ очень похож на Apache Kudu.
Cloudera Distributed Hadoop
Cloudera одна из первых компаний начавших монетизировать Hadoop и именно там работает Дуг, который изобрел Hadoop.
Cloudera в отличие от других игроков, не подстраивается под рынок, а сама делает его. Грамотный пиар и маркетинг позволили ей завоевать достаточно лакомый кусочек рынка — сейчас в списке клиентов более 100 крупных и известных компаний.
В отличие от других подобных компаний, Cloudera не просто продает зоопарк из уже готовых компонентов, но и сама активно участвует в их разработке.
По цене CDH выходит немного дешевле Vertica/Greenplum.
Но несмотря на большое количество историй успеха на сайте Cloudera, есть одна маленькая проблема — Kuda, Impala — немного сырые, продукты на стадии инкубации. Даже когда они созреют, этим системам нужно будет пройти долгий путь, чтобы обрасти всем необходимым функционалом Vertica или хотя бы Greenplum, а это не год и не два, пока же CDH можно оставить для хипстеров.
Так же надо отдать должное маркетологам Cloudera, сумевшим встряхнуть рынок.
Будущее Hadoop
Позволю себе пованговать и представить, что будет со стеком Hadoop через 5 лет.
MapReduce будет использоваться только в очень ограниченном количестве задач, проект скорее всего выпилят из общего стека, либо о нем забудут.
Появятся первые дистрибутивы CDH уже с частичным отказом от использования HDFS. В таком случае, файлы таблиц будут храниться на обычной файловой системе, но у нас будет небольшая помойка для хранения сырых данных.
Можно провести аналогию с Flex Zone в Vertica — свалка, в которую можно кидать все что угодно и обрабатывать далее по мере необходимости или забывать.
На самом деле иметь такую помойку не только удобно, но мы будем просто вынуждены иметь ее. Объемы дискового пространства растут непропорционально быстро по сравнению с производительностью процессоров. Когда количество узлов в кластере увеличивают в целях производительности мы увеличиваем и объем дискового пространства(больше необходимого). В следствие чего, всегда будет большое количество незанятого дискового пространства, в котором удобно хранить данные к которым обращение будет либо очень редкое, либо мы к ним не обратимся никогда.
Зоопарк имени Hadoop вряд ли оправдает кредит доверия, который предоставили ему пользователи, но надеюсь, что не уйдет с рынка.
Хотя бы, из интересов конкуренции.

Будут ли у Hadoop проблемы через 5 лет?
Что будет со Spark? Возможно, многие будут использовать его как движок для распределенной предобработки и подготовки данных в реальном времени — Spark Streaming, но и эта ниша тоже активно занимается другими игроками (Storm, производители ETL)
Будущее Vertica, Greenplum.
Vertica будет полировать свою интеграцию с HDFS, наращивать функционал и Vertica скорее всего не пойдет в OpenSource — сейчас продукт и так хорошо продается.
Greenpum сделает свой аналог Flex Zone, путем слияния кода с HAWQ, либо сам станет non-HDFS частью HAWQ, в конце концов, кого-то мы потеряем.
Каких то новых игроков на рынке аналитических MPP-систем, скорее всего, ожидать не придется. Открытие исходников Greenplum ставит целесообразность использования таких СУБД как Postgres-XL, как минимум, под сомнение.
Принципиальных изменений архитектуры в этих продуктах мы вряд ли увидим, изменения будут в улучшении имеющегося функционала.
Будущее Postgres-XL и подобных
Postgres-XL могла бы быть прекрасным MPP инструментом для аналитики больших объемов данных, если бы немного бы отошла от всего того, что дал ей Postgres. К сожалению СУБД не умеет работать с Column Store-таблицами, в ней нет нормального синтаксиса для управления партициями, а так же она имеет стандартный оптимизатор Postgres со всеми вытекающими.
Например, в Greenplum есть cost-based оптимизатор, заточенный для аналитических запросов. Это та штука, без которой жизнь аналитика и разработчика очень сильно усложнится.
Но ставить крест на таком замечательном продукте тоже не стоит, Postgres развивается, в 9.6 уже появилась многопоточность и, возможно, умельцы прикрутят Column Store и GPORCA в Postgres-XL.
Будущее Teradata, Netezza, SAP и подобных
В любом случае рынок аналитических систем будет расти и в любом случае клиенты на эти продукты будут. Будут эти решения продавать на полях для гольфа или на конференциях "Big Data — технология будущего" я не знаю.
Но скорее всего, этим игрокам придется уйти от текущей бизнес-модели программно-аппаратных средств и взглянуть в сторону Only-Software-продуктов.
Запрыгнуть в призрачный поезд "Big Data" у них не получится, но это и не нужно, ибо поезд мнимый и они отчасти сами его и придумали.
Будущее Redshift, BigQuery и облачных сервисов для аналитики
На первый взгляд, облачные сервисы выглядят очень и очень привлекательно: не нужно заморачиваться покупкой оборудования и лицензиями. Подразумевается, что при желании можно будет с легкостью отказаться от сервиса или перейти в другой.
С другой стороны, аналитика — проект долгосрочный, а разрабатывать аналитическое хранилище, абстрагируясь от конкретной технологии очень и очень сложно. Поэтому в будущем перейти безболезненно из одного облачного хранилища в другое будет сложно.
Клиенты у таких игроков точно будут, но очень специфичные — стартапы и небольшие компании.
Резюме: Я не коснулся большого количества продуктов из зверинца ASF, которые продают под соусом Big Data (Storm, Sqoop и т.п.), так как пока к ним мало интереса как с моей стороны, так и рынка в целом. Поэтому, буду рад любым комментариям, касаемым этих продуктов.
Также я не коснулся темы кликстрим-аналитики, которая набирает обороты. Надеюсь, опишу это в следующих статьях.
Второе резюме: Сложно не пойти на поводу у "творцов" рынка при выборе решений в области обработки и анализа данных. До сих пор пыль не осела и мы еще будем сталкиваться с компаниями, продающими "счастье" и мы будем сталкиваться с продуктами, позиционируемыми как "универсальное лекарство" от Big Data головного мозга.
Я постарался показать, куда развивается Hadoop, да и вся индустрия обработки данных. Попытался развеять несколько мифов прод Big Data и постарался представить в каком направлении будет развиваться вся область. Надеюсь, получилось — узнаем об этом уже через несколько лет.
В конце концов, рынок развивается и становится более доступным для потребителя, появляются новые продукты, появляются новые либо перерождаются старые технологии.
Big Data: размер имеет значение
Простыми словами рассказываем, что такое большие данные, где они используются, кто и как с ними работает.
Термину Big Data более десяти лет, но вокруг него до сих пор много путаницы. Доступно рассказываем, что же такое «большие данные», откуда эти данные берутся и где используются, кто такие аналитики данных и чем они занимаются.
Три признака больших данных
Традиционно большие данные характеризуют тремя признаками (так называемым правилом VVV):
- Большой объем (Volume). Термин Big Data предполагает большой информационный объем (терабайты и петабайты информации). Важно понимать, что для решения определенного бизнес-кейса ценность обычно имеет не весь объем, а лишь незначительная часть. Однако заранее эту ценную составляющую без анализа определить невозможно.
- Большая скорость обновлений (Velocity). Данные регулярно обновляются и требуют постоянной обработки. Обновление чаще всего подразумевает рост объема.
- Многообразие (Variety). Данные могут иметь различные форматы и быть структурированы лишь частично или быть вовсе сырыми, неоднородными. Необходимо учитывать, что часть данных почти всегда недостоверна или неактуальна на момент проведения исследования.
В качестве простейшего примера можно представить таблицу с миллионами строк клиентов крупной компании. Столбцы – это характеристики пользователей (Ф.И.О., пол, дата, адрес, телефон и т. д.), один клиент – одна строка. Информация обновляется постоянно: клиенты приходят и уходят, данные корректируются.

Но таблицы – это лишь одна из простейших форм отображения информации. Обычно представление больших данных имеет куда более витиеватый и менее структурированный характер. Так, ниже показана схема базы данных проекта MediaWiki:

Большой объем предполагает особую инфраструктуру хранения данных – распределенные файловые системы. Для работы с ними используются реляционные системы управления базами данных. Это требует от аналитика уметь составлять соответствующие запросы к базам данных.
Где живут большие данные?
Инструменты Big Data используются во многих сферах жизни современного человека. Перечислим некоторые из наиболее популярных областей с примерами бизнес-задач:
- Поисковая выдача (оптимизация отображаемых ссылок с учетом сведений о пользователе, его местоположении, предыдущих поисковых запросах).
- Интернет-магазины (повышение конверсии).
- Рекомендательные системы (жанровая классификация фильмов и музыки).
- Голосовые помощники (распознавание голоса, реакция на запрос).
- Цифровые сервисы (фильтрация спама в электронной почте, индивидуальная новостная лента).
- Социальные сети (персонализированная реклама).
- Игры (внутриигровые покупки, игровое обучение).
- Финансы (принятие банком решений о кредитовании, трейдинг).
- Продажи (прогнозирование остатков на складе для снижения издержек).
- Системы безопасности (распознавание объектов с видеокамер).
- Автопилотируемый транспорт (машинное зрение).
- Медицина (диагностика заболеваний на ранних стадиях).
- Городская инфраструктура (предотвращение пробок на дорогах, предсказание пассажиропотока в общественном транспорте).
- Метеорология (прогнозирование погоды).
- Промышленное производство товаров (оптимизация конвейера, снижение рисков).
- Научные задачи (расшифровка геномов, обработка астрономических данных, космических снимков).
- Обработка информации с фискальных накопителей (прогнозирование стоимости товаров).
Для каждой из перечисленных задач можно найти примеры решений с помощью технологий, входящих в сферу Data Science и Machine Learning. Объем используемых данных определяет стратегию и точность решения.
Чем занимаются люди в Big Data?
Анализ Big Data находится на стыке трех областей:
- Computer Science/IT
- Математика и статистика
- Специальные знания анализируемой области

Поэтому аналитик данных – междисциплинарный специалист, обладающий знаниями и в математике, и в программировании, и в базах данных. Вышеперечисленные примеры задач предполагают, что человек должен быстро разбираться в новой предметной области, иметь коммуникативные навыки. Особенно важно уметь находить аналитически обоснованный и полезный для бизнеса результат. Немаловажно грамотно эти выводы визуализировать и презентовать.
Очередность действий в проводимом исследовании примерно сводится к следующему:
- Работа с базами (структурирование, логика).
- Извлечение необходимой информации (написание SQL-запросов).
- Предобработка данных.
- Преобразование данных.
- Применение статистических методов.
- Поиск паттернов.
- Визуализация данных (выявление аномалий, наглядное представление для бизнеса).
- Поиск ответа, формулировка и проверка гипотезы.
- Внедрение в процесс.
Итог работы представляет сжатый отчет с визуализацией результата либо интерактивную панель (dashboard). На такой панели обновляемые данные после обработки предстают в удобной для восприятия форме.
Ключевые навыки и инструменты аналитика
Навыки и соответствующие инструменты, применяемые аналитиками, обычно следующие:
- Извлечение данных из источников данных (MS SQL, MySQL, NoSQL, Hadoop, Spark).
- Обработка данных (Python, R, Scala, Java).
- Визуализация (Plotly, Tableau, Qlik).
- Исследование по критериям бизнес-задачи.
- Формулировка гипотез.
Выбор языка программирования диктуется имеющимися наработками и необходимой скоростью конечного решения. Язык определяет среду разработки и инструменты анализа данных.
Большинство аналитиков используют в качестве языка программирования Python. В этом случае для анализа больших обычно применяется Pandas. При работе в команде общепринятым стандартом документов для хранения и обмена гипотезами являются ipynb-блокноты, обычно обрабатываемые в Jupyter. Этот формат представления данных позволяет совмещать ячейки с программным кодом, текстовые описания, формулы и изображения.

Выбор инструментария для решения задачи зависит от кейса и требований заказчика к точности, надежности и скорости выполнения алгоритма решения. Также важна возможность объяснить составляющие алгоритма от этапа ввода данных до вывода результата.
Так, для задач, связанных с обработкой изображений, чаще применяются нейросетевые инструменты, такие как TensorFlow или один из десятка других фреймворков глубокого обучения. Но, к примеру, при разработке финансовых инструментов нейросетевые решения могут выглядеть «опасными», ведь проследить путь нахождения результата оказывается затруднительно.

Выбор модели анализа и ее архитектуры не менее тривиален, чем вычислительный процесс. Из-за этого в последнее время развивается направление автоматического машинного обучения. Данный подход вряд ли сократит потребность в аналитиках данных, но уменьшит число рутинных операций.
Как разобраться в Big Data?
Как можно понять из приведенного обзора, большие данные предполагают от аналитика и большой объем знаний их различных областей. Разобраться с основами поможет наш учебный план. Если захочется углубиться и попытаться последовательно охватить все аспекты вопроса, изучите roadmap Data Science:

В упомянутом репозитории вы также найдете краткие описания и ссылки к некоторым из компонентов карты.
С чего начать, если хочется попробовать прямо сейчас, но нет данных?
Опытные аналитики советуют пораньше знакомиться с Kaggle. Это популярная платформа для организации конкурсов по анализу больших объемов данных. Здесь найдутся не только соревнования с денежными призами за первые места, но и ipynb-блокноты с идеями и решениями, а также интересные датасеты (наборы данных) различного объема.

Понравилась статья? Что бы еще вы хотели узнать о Big Data?
Что такое Big Data - Москва и Московская область
Решили выяснить, как это работает и почему с 2016 года отрасль растет на $6-7 млрд в год. Разбираемся вместе с коллегами из проектного офиса аналитики больших данных, которые развенчивают основные мифы о технологии больших данных и рассказывают о своей работе.
Big Data – это нечто новое
Технологии Big Data и Data Science новыми можно считать лишь условно. Они появились в результате развития вычислительной техники и математического аппарата еще в середине прошлого века.
Впервые термин Data Science упоминается в книге “Concise Survey of Computer Methods” датского ученого Петера Наура, которая вышла в 1974 году. В книге Петер явно определил науку о данных как дисциплину, изучающую жизненный цикл цифровых данных – от появления до преобразования для представления в других областях знаний. По сути Data Science – это методы и инструменты анализа данных: статистика, интеллектуальный анализ данных и приложения искусственного интеллекта для работы с данными.
Что касается Big Data, то этим термином обозначают большие массивы данных, обрабатываемые информационными системами. Часто этим термином обозначают и инфраструктуру для обработки больших массивов данных.
Развитие систем Big Data привело к взрывному росту интереса к Data Science. Были разработаны новые методы, а повышение производительности вычислительных систем позволило получать результаты работы ресурсоемких алгоритмов в приемлемое время.
Но вся эта революция случилась не вчера, она зародилась еще в эру ЭВМ. А вот, что действительно, новое в наше время – это появление новых мощных инструментов для хранения и обработки big data.
В этой статье мы решили рассмотреть наиболее часто встречающиеся утверждения и мифы про Big Data и узнать, правдивы ли они или нет.
Данные тем ценнее, чем меньше людей ими владеют
Это спорное утверждение. С одной стороны, владение данными действительно ценно: если компания смогла собрать уникальные данные и имеет ресурсы для их анализа, то она может получить серьезное конкурентное преимущество.
В качестве примера можно привести Facebook. Социальная сеть аккумулирует данные о пользователях и их поведении, что позволяет ей делать очень качественную таргетированную рекламу.
С другой стороны, чем больше людей имеют доступ к данным, тем больше идей по анализу данных может возникнуть. В настоящее время растет популярность соревнований по машинному обучению, где компании публикуют свои данные, а люди строят на них модели. Результаты победителей таких соревнований нередко превосходят все ожидания организаторов.
Кстати, мы в ближайшее время тоже планируем организовать хакатон в офисе Tele2, во время которого люди будут использовать наши данные для решения открытых бизнес-кейсов. Нам очень интересно, что же у них получится, а результатами мы с вами обязательно поделимся.
Машины на основе Big Data заменят людей
Бояться не стоит. Да, современные алгоритмы машинного обучения умеют принимать повторяющиеся решения на основе большого количества обучающих данных. Если у вас есть 10 000 фотографий собак, подписанных как «собака», и 10 000 подписанных фотографий кошек, то вы легко сможете обучить компьютер отличать одно животное от другого с высокой точностью. Однако, если после этого показать алгоритму кадр из мультфильма, где изображён нарисованный кот, то программа не будет знать, что делать, в то время как трехлетний ребенок при первом просмотре мультфильма легко распознает правильное животное.
На данный момент ничего похожего на настоящий искусственный интеллект не существует. Есть машины, которые очень хорошо запоминают паттерны от простых (кошка или собака) до сложных (как управлять автомобилем так, чтобы не произошло аварии), но и только. Более того, у меня есть большие сомнения, что текущими методами можно вообще достичь чего-то, похожего на искусственный интеллект. Так что, если в вашей работе время от времени нужно делать выводы и корректировать поведение, то пока можно не беспокоиться о том, что ваш следующий коллега будет сделан из металла и проводов.
При этом важно понимать, что автоматизация работы действительно идёт полным ходом, просто, по большей части, это касается механической работы. Все мы сталкиваемся с этим каждый день, когда вместо разговора с кассиром в магазине нам нужно нажать пару кнопок на экране. И это крайне удобно, однако сокращающееся число рабочих мест в ближайшем будущем станет настолько глобальной проблемой, что даже люди, получающие от автоматизации больше всего преимуществ – владельцы корпораций и миллиардеры – начинают говорить о том, что нам скоро понадобится безусловный базовый доход, но это уже совсем другая история.
Big Data может точно предсказывать будущее
В основе этой идеи лежит детерминизм – учение о взаимосвязи и взаимной определенности всех явлений и процессов. Вселенная развивается по определённым законам. Ее можно рассматривать как гигантскую динамическую систему. Значит, если учесть все законы, то состояние Вселенной можно рассчитать на любой момент времени.
Сторонники этой концепции считают, что Big Data поможет выявить скрытые закономерности, определить все ещё неизвестные законы Вселенной, собрать необходимые для расчета данные и по ним спрогнозировать развитие событий.
Но проблема заключается в том, что информации, доступной внутри системы, недостаточно, для понимания ее функционирования. На систему могут оказывать значительное влияние внешние факторы.
Например, фермер выращивает индюшку ко Дню благодарения. Он ее каждый день кормит, поит и ухаживает за ней. С точки зрения индейки так было всегда, она убеждена в дружественном отношении к ней людей, а ее уверенность в безопасности достигает максимума. Но затем наступает День благодарения, и фермер убивает индейку. На основании своего предыдущего опыта индейка не могла предсказать такого развития событий.
Такие очень редкие, но крайне катастрофические события Насим Талеб называет «черный лебедь». По его мнению, редкие события не моделируются, потому что эти события настолько редки, что они полностью непредсказуемы … и, как правило, гораздо хуже, чем можно было ожидать.
Да, Big Data может собрать большой набор данных, а Data Science может выявить закономерности и спрогнозировать развитие событий. Но всегда может прилететь «чёрный лебедь», и все пойдет не так. Если чего-то никогда не было, то это ещё не означает, что этого не может быть вовсе.
Есть определенный объем данных, с которого данные становятся «большими»
Слово big из термина Big Data – это обман, потому что даже данные, весящие петабайт – 1 000 000 ГБ – могут не вписываться в концепцию этого понятия. Для Big Data требуются новые подходы обработки, автоматизации и аналитики. За термином Big Data стоят разработанные фреймворки, платформы и решения, которые опираются на 3 главных свойства, необходимых и достаточных для того, чтобы ваши данные были не просто значительного объема, а стали вписываться в концепцию Big Data. Как же это понять? Воспользуйтесь правилом 3V.
Если ваши данные могут храниться в различных форматах, таких как excel, csv, тексты, видео, картинки, то это первый тревожный звоночек, что это Big Data.
Если ваши данные растут с высокой скоростью, и она становится все больше и больше, присмотритесь, возможно вы имеете дело с Big Data.
Если ваши данные имеют большой объем и им тесно на ваших рабочих серверах, значит, перед вами Big Data.
Чем больше данных, тем лучше
С одной стороны, когда в компании собираются все возможные данные, и при этом они структурированы, корректны и регулярно обновляемы – это хорошо. На практике идеальных данных не бывает: встречаются неточности и серьезные ошибки. Когда данных много, каждая ошибка в действительности меньше влияет на результат, но с ростом количества данных растет и количество ошибок. А качество данных гораздо важнее их количества.
С другой стороны, для хранения и обработки больших объемов данных потребуются большие мощности, что, в свою очередь, приведет к большим затратам. На анализ и обработку больших данных, как правило, уходит больше времени, требуются более квалифицированные кадры. Хранилища для таких данных более дорогостоящие.
Прежде чем внедрять хранилище, в котором будут данные на любой вкус, необходимо оценить их точность, затраты и возможность монетизации этих данных. Поэтому нет, нельзя однозначно сказать, что чем больше данных, тем лучше.
У нас очень мало данных для Big Data
В современном мире собирается огромное количество информации, и ежедневно этот массив данных растет. Проблемы в недостатке данных нет, проблема в том, чтобы суметь выделить из всего этого разнородного объема информации действительно полезные знания, на базе которых можно принимать ценные решения.
С другой стороны, большими и разнородными объемами данных о своих клиентах обладают лишь единичные компании – телекоммуникационные, банки, страховые, интернет-гиганты. Большинство организаций еще не успело накопить объем информации, достаточный для применения современных алгоритмов обработки данных.
Резюмируя: данных много, но доступ к ним есть у единичных игроков рынка.
Все уже используют Big Data
Далеко не все компании, даже очень крупные, имеющие огромные массивы разнообразных данных, используют в своей аналитике методы машинного обучения. Несмотря на то, что в ценности данных убеждены практически все компании, далеко не каждая из них готова инвестировать деньги на создание соответствующих отделов, инфраструктуры, оборудования.
Множество организаций привыкли к устоявшимся за долгие годы средствам аналитики «внутри себя». При этом экономический эффект от внедрения технологий Big Data изначально не ясен, сроки его получения не определены, даже размер необходимых инвестиций посчитать в компании некому. При этом отдавать такую аналитику на аутсорсинг компания не готова – придется делиться ценными данными, а «такая корова нужна самому».
Очень здорово, что в Tele2 не так: мы знаем, как и где использовать данные, чтобы наш бизнес был максимально эффективен.
Big Data дают мгновенный и волшебный результат
Однозначно, это не так. Анализ Big Data состоит из нескольких больших и трудозатратных по времени и ресурсам этапов.
Этап сбора и подготовки данных (Data Engineering). Зачастую приходится работать не только с хорошо структурированными табличными данными, но и слабо структурированными – тексты, отзывы в социальных сетях, картинки, видео. Все эти данные требуют предобработки, расчета метрик, понятных для машинного обучения, хранения, регулярного сбора и обновления. Иногда данный этап занимает более 50% времени команды Big Data. Однако, этот этап является одним из наиболее важных, так как «мусор на входе – мусор на выходе».
Этап обучения модели (Machine Learning). Процесс, в ходе которого обрабатывается большое число данных, выявляются закономерности и используются, чтобы прогнозировать характеристики новых данных.
Внедрение полученных результатов в бизнес-процесс и регулярный расчет. Подводя итог, хотелось бы сказать, что у Big Data нет одного быстрого и волшебного алгоритма под любую задачу. Под каждый проект собирается команда, формируются оптимальные данные, находится наилучший алгоритм. Процесс «сбор данных – выбор алгоритма – получение результатов» итеративный. Зачастую, в реальной практике после обсуждения промежуточных результатов с заказчиком он может повторяться и претерпевать изменения несколько раз – появляется необходимость подключать новые источники данных, оптимизировать алгоритмы машинного обучения.
Big Data – только для крупных бизнесов
Думаю, что данное утверждение верно в части «крупных», но не совсем верно, в том, что присваивает термин Big Data только бизнесу. В самом деле, если данных у вас не так уж много, то вполне можно обойтись без Big Data – возможности того, что можно сделать на одной машине, сейчас не так уж малы. Однако это не значит, что такие огромные объёмы данных могут быть только у бизнеса – не стоит забывать и про науку.
В 2015 году в летней школе по параллельным вычислениям, одним из организаторов которой был CERN (сразу приходит на ум адронный коллайдер), мы убедились в том, насколько огромны объемы экспериментальных данных, велика компьютерная сеть и сложен стек технологий, необходимый для их обработки и хранения. Она включает в себя примерно 350 000 узлов, находящихся в 170 городах и 40 странах, 500 петабайт хранимых данных, более 2 миллионов одновременно запущенных задач (по данным 2015 года – сейчас, наверняка, больше). Разумеется, все это требует огромных инвестиций, но и потенциальное влияние на фундаментальную науку может быть очень велико.
Таким образом, как минимум, такой пример показывает, что Big Data может быть достоянием не только бизнеса, но и академического сообщества.
Big Data – это сбор данных
Big Data – это собирательное понятие, которое, конечно же, включает в себя процесс поиска и сбора данных, но на этом взаимодействие с большими данными не заканчивается. В целом, стадии работы с Big Data включают в себя: сбор информации, её структурирование и хранение, обработку и, в конечном итоге, создание инсайтов.
Поскольку количество информации со временем только увеличивается, основная сложность состоит не в том, чтобы получить данные, а в том, как их хранить и обрабатывать с максимальной пользой.
Концепция больших данных предполагает взаимодействие с такими объемами, которые не умещаются на одном компьютере, поэтому необходимо налаживать процесс хранения и обработки на целом кластере из десятков вычислительных машин. Также нужно учитывать такие факторы, как различные форматы данных, степень их структурированности, изменчивость во времени, масштабируемость. От выбора способа хранения зависят скорость и удобство взаимодействия с данными для аналитиков и, соответственно, скорость получения полезной информации из данных.
Аналитика на основе больших данных делается автоматически, без участия человека
Как можно догадаться, анализ больших данных не обходится без аналитики. Для того, чтобы вытащить из данных что-то полезное, нужно прикинуть, есть ли в этих данных нужная информация. Даже если машина найдет положительную взаимосвязь между ростом продаж мороженого и ростом утопленников, это вовсе не означает, что чем больше мороженого мы продадим, тем больше людей утонут. Возможно, во всем «виновата» жаркая погода: больше людей купаются в водоемах, больше тонут. И это, конечно, не значит, что не стоит купаться в жаркую погоду.
Какие данные взять, какие гипотезы стоит выдвинуть, как данные лучше подготовить, как интерпретировать выводы – определяет человек.
Проектный офис больших данных работает с большинством подразделений Tele2. Мы убедились: аналитика больших данных — это не «совершенный мозг», а «сильные очки», улучшающие наше управленческое зрение. Вместе с тем, не для всех задач требуется стопроцентное зрение, а, там, где оно необходимо, важно понимание, что делать с этой более четкой картинкой, чтобы не растеряться в изобилии фактов. Поэтому успешность проектов по анализу больших данных зависит не только от интереса подразделений в увеличении собственной эффективности, но и от активного участия функциональных экспертов в формулировке и проверке гипотез и, в конечном итоге, в улучшении существующих процессов.