Кластерный анализ что это такое
Кластерный анализ — Википедия
Результат кластерного анализа обозначен раскрашиванием точек в соответствии с принадлежностью к одному из трёх кластеров.Кластерный анализ (англ. cluster analysis) — многомерная статистическая процедура, выполняющая сбор данных, содержащих информацию о выборке объектов, и затем упорядочивающая объекты в сравнительно однородные группы[1][2][3][4]. Задача кластеризации относится к статистической обработке, а также к широкому классу задач обучения без учителя.
Большинство исследователей (см., напр.,[5]) склоняются к тому, что впервые термин «кластерный анализ» (англ. cluster — гроздь, сгусток, пучок) был предложен математиком Р. Трионом[6]. Впоследствии возник ряд терминов, которые в настоящее время принято считать синонимами термина «кластерный анализ»: автоматическая классификация, ботриология.
Спектр применений кластерного анализа очень широк: его используют в археологии, медицине, психологии, химии, биологии, государственном управлении, филологии, антропологии, маркетинге, социологии, геологии и других дисциплинах. Однако универсальность применения привела к появлению большого количества несовместимых терминов, методов и подходов, затрудняющих однозначное использование и непротиворечивую интерпретацию кластерного анализа.
Кластерный анализ выполняет следующие основные задачи:
- Разработка типологии или классификации.
- Исследование полезных концептуальных схем группирования объектов.
- Порождение гипотез на основе исследования данных.
- Проверка гипотез или исследования для определения, действительно ли типы (группы), выделенные тем или иным способом, присутствуют в имеющихся данных.
Независимо от предмета изучения применение кластерного анализа предполагает следующие этапы:
- Отбор выборки для кластеризации. Подразумевается, что имеет смысл кластеризовать только количественные данные.
- Определение множества переменных, по которым будут оцениваться объекты в выборке, то есть признакового пространства.
- Вычисление значений той или иной меры сходства (или различия) между объектами.
- Применение метода кластерного анализа для создания групп сходных объектов.
- Проверка достоверности результатов кластерного решения.
Можно встретить описание двух фундаментальных требований, предъявляемых к данным — однородность и полнота. Однородность требует, чтобы все кластеризуемые сущности были одной природы, описывались сходным набором характеристик[7]. Если кластерному анализу предшествует факторный анализ, то выборка не нуждается в «ремонте» — изложенные требования выполняются автоматически самой процедурой факторного моделирования (есть ещё одно достоинство — z-стандартизация без негативных последствий для выборки; если её проводить непосредственно для кластерного анализа, она может повлечь за собой уменьшение чёткости разделения групп). В противном случае выборку нужно корректировать.
Типы входных данных[править | править код]
- Признаковое описание объектов. Каждый объект описывается набором своих характеристик, называемых признаками. Признаки могут быть числовыми или нечисловыми.
- Матрица расстояний между объектами. Каждый объект описывается расстояниями до всех остальных объектов метрического пространства.
- Матрица сходства между объектами [8]. Учитывается степень сходства объекта с другими объектами выборки в метрическом пространстве. Сходство здесь дополняет расстояние (различие) между объектами до 1.
В современной науке применяется несколько алгоритмов обработки входных данных. Анализ путём сравнения объектов, исходя из признаков, (наиболее распространённый в биологических науках) называется Q-типом анализа, а в случае сравнения признаков, на основе объектов — R-типом анализа. Существуют попытки использования гибридных типов анализа (например, RQ-анализ), но данная методология ещё должным образом не разработана.
Цели кластеризации[править | править код]
- Понимание данных путём выявления кластерной структуры. Разбиение выборки на группы схожих объектов позволяет упростить дальнейшую обработку данных и принятия решений, применяя к каждому кластеру свой метод анализа (стратегия «разделяй и властвуй»).
- Сжатие данных. Если исходная выборка избыточно большая, то можно сократить её, оставив по одному наиболее типичному представителю от каждого кластера.
- Обнаружение новизны (англ. novelty detection). Выделяются нетипичные объекты, которые не удаётся присоединить ни к одному из кластеров.
В первом случае число кластеров стараются сделать поменьше. Во втором случае важнее обеспечить высокую степень сходства объектов внутри каждого кластера, а кластеров может быть сколько угодно. В третьем случае наибольший интерес представляют отдельные объекты, не вписывающиеся ни в один из кластеров.
Во всех этих случаях может применяться иерархическая кластеризация, когда крупные кластеры дробятся на более мелкие, те в свою очередь дробятся ещё мельче, и т. д. Такие задачи называются задачами таксономии. Результатом таксономии является древообразная иерархическая структура. При этом каждый объект характеризуется перечислением всех кластеров, которым он принадлежит, обычно от крупного к мелкому.
Методы кластеризации[править | править код]
Общепринятой классификации методов кластеризации не существует, но можно выделить ряд групп подходов (некоторые методы можно отнести сразу к нескольким группам и потому предлагается рассматривать данную типизацию как некоторое приближение к реальной классификации методов кластеризации)[9]:
- Вероятностный подход. Предполагается, что каждый рассматриваемый объект относится к одному из k классов. Некоторые авторы (например, А. И. Орлов) считают, что данная группа вовсе не относится к кластеризации и противопоставляют её под названием «дискриминация», то есть выбор отнесения объектов к одной из известных групп (обучающих выборок).
- Подходы на основе систем искусственного интеллекта: весьма условная группа, так как методов очень много и методически они весьма различны.
- Логический подход. Построение дендрограммы осуществляется с помощью дерева решений.
- Теоретико-графовый подход.
- Иерархический подход. Предполагается наличие вложенных групп (кластеров различного порядка). Алгоритмы в свою очередь подразделяются на агломеративные (объединительные) и дивизивные (разделяющие). По количеству признаков иногда выделяют монотетические и политетические методы классификации.
- Другие методы. Не вошедшие в предыдущие группы.
Подходы 4 и 5 иногда объединяют под названием структурного или геометрического подхода, обладающего большей формализованностью понятия близости[10]. Несмотря на значительные различия между перечисленными методами все они опираются на исходную «гипотезу компактности»: в пространстве объектов все близкие объекты должны относиться к одному кластеру, а все различные объекты соответственно должны находиться в различных кластерах.
Формальная постановка задачи кластеризации[править | править код]
Пусть X{\displaystyle X} — множество объектов, Y{\displaystyle Y} — множество номеров (имён, меток) кластеров. Задана функция расстояния между объектами ρ(x,x′){\displaystyle \rho (x,x')}. Имеется конечная обучающая выборка объектов Xm={x1,…,xm}⊂X{\displaystyle X^{m}=\{x_{1},\dots ,x_{m}\}\subset X}. Требуется разбить выборку на непересекающиеся подмножества, называемые кластерами, так, чтобы каждый кластер состоял из объектов, близких по метрике ρ{\displaystyle \rho }, а объекты разных кластеров существенно отличались. При этом каждому объекту xi∈Xm{\displaystyle x_{i}\in X^{m}} приписывается номер кластера yi{\displaystyle y_{i}}.
Алгоритм кластеризации — это функция a:X→Y{\displaystyle a\colon X\to Y}, которая любому объекту x∈X{\displaystyle x\in X} ставит в соответствие номер кластера y∈Y{\displaystyle y\in Y}. Множество Y{\displaystyle Y} в некоторых случаях известно заранее, однако чаще ставится задача определить оптимальное число кластеров, с точки зрения того или иного критерия качества кластеризации.
Кластеризация (обучение без учителя) отличается от классификации (обучения с учителем) тем, что метки исходных объектов yi{\displaystyle y_{i}} изначально не заданы, и даже может быть неизвестно само множество Y{\displaystyle Y}.
Решение задачи кластеризации принципиально неоднозначно, и тому есть несколько причин (как считает ряд авторов):
- не существует однозначно наилучшего критерия качества кластеризации. Известен целый ряд эвристических критериев, а также ряд алгоритмов, не имеющих чётко выраженного критерия, но осуществляющих достаточно разумную кластеризацию «по построению». Все они могут давать разные результаты. Следовательно, для определения качества кластеризации требуется эксперт предметной области, который бы мог оценить осмысленность выделения кластеров.
- число кластеров, как правило, неизвестно заранее и устанавливается в соответствии с некоторым субъективным критерием. Это справедливо только для методов дискриминации, так как в методах кластеризации выделение кластеров идёт за счёт формализованного подхода на основе мер близости.
- результат кластеризации существенно зависит от метрики, выбор которой, как правило, также субъективен и определяется экспертом. Но стоит отметить, что есть ряд рекомендаций к выбору мер близости для различных задач.
В биологии[править | править код]
В биологии кластеризация имеет множество приложений в самых разных областях. Например, в биоинформатике с помощью неё анализируются сложные сети взаимодействующих генов, состоящие порой из сотен или даже тысяч элементов. Кластерный анализ позволяет выделить подсети, узкие места, концентраторы и другие скрытые свойства изучаемой системы, что позволяет в конечном счете узнать вклад каждого гена в формирование изучаемого феномена.
В области экологии широко применяется для выделения пространственно однородных групп организмов, сообществ и т. п. Реже методы кластерного анализа применяются для исследования сообществ во времени. Гетерогенность структуры сообществ приводит к возникновению нетривиальных методов кластерного анализа (например, метод Чекановского).
В общем стоит отметить, что исторически сложилось так, что в качестве мер близости в биологии чаще используются меры сходства, а не меры различия (расстояния).
В социологии[править | править код]
При анализе результатов социологических исследований рекомендуется осуществлять анализ методами иерархического агломеративного семейства, а именно методом Уорда, при котором внутри кластеров оптимизируется минимальная дисперсия, в итоге создаются кластеры приблизительно равных размеров. Метод Уорда наиболее удачен для анализа социологических данных. В качестве меры различия лучше квадратичное евклидово расстояние, которое способствует увеличению контрастности кластеров. Главным итогом иерархического кластерного анализа является дендрограмма или «сосульчатая диаграмма». При её интерпретации исследователи сталкиваются с проблемой того же рода, что и толкование результатов факторного анализа — отсутствием однозначных критериев выделения кластеров. В качестве главных рекомендуется использовать два способа — визуальный анализ дендрограммы и сравнение результатов кластеризации, выполненной различными методами.
Визуальный анализ дендрограммы предполагает «обрезание» дерева на оптимальном уровне сходства элементов выборки. «Виноградную ветвь» (терминология Олдендерфера М. С. и Блэшфилда Р. К.[11]) целесообразно «обрезать» на отметке 5 шкалы Rescaled Distance Cluster Combine, таким образом будет достигнут 80 % уровень сходства. Если выделение кластеров по этой метке затруднено (на ней происходит слияние нескольких мелких кластеров в один крупный), то можно выбрать другую метку. Такая методика предлагается Олдендерфером и Блэшфилдом.
Теперь возникает вопрос устойчивости принятого кластерного решения. По сути, проверка устойчивости кластеризации сводится к проверке её достоверности. Здесь существует эмпирическое правило — устойчивая типология сохраняется при изменении методов кластеризации. Результаты иерархического кластерного анализа можно проверять итеративным кластерным анализом по методу k-средних. Если сравниваемые классификации групп респондентов имеют долю совпадений более 70 % (более 2/3 совпадений), то кластерное решение принимается.
Проверить адекватность решения, не прибегая к помощи другого вида анализа, нельзя. По крайней мере, в теоретическом плане эта проблема не решена. В классической работе Олдендерфера и Блэшфилда «Кластерный анализ» подробно рассматриваются и в итоге отвергаются дополнительные пять методов проверки устойчивости:
- кофенетическая корреляция — не рекомендуется и ограничена в использовании;
- тесты значимости (дисперсионный анализ) — всегда дают значимый результат;
- методика повторных (случайных) выборок, что, тем не менее, не доказывает обоснованность решения;
- тесты значимости для внешних признаков пригодны только для повторных измерений;
- методы Монте-Карло очень сложны и доступны только опытным математикам[источник не указан 2772 дня].
В информатике[править | править код]
- Кластеризация результатов поиска — используется для «интеллектуальной» группировки результатов при поиске файлов, веб-сайтов, других объектов, предоставляя пользователю возможность быстрой навигации, выбора заведомо более релевантного подмножества и исключения заведомо менее релевантного — что может повысить юзабилити интерфейса по сравнению с выводом в виде простого сортированного по релевантности списка.
- Сегментация изображений (англ. image segmentation) — кластеризация может быть использована для разбиения цифрового изображения на отдельные области с целью обнаружения границ (англ. edge detection) или распознавания объектов.
- Интеллектуальный анализ данных (англ. data mining) — кластеризация в Data Mining приобретает ценность тогда, когда она выступает одним из этапов анализа данных, построения законченного аналитического решения. Аналитику часто легче выделить группы схожих объектов, изучить их особенности и построить для каждой группы отдельную модель, чем создавать одну общую модель для всех данных. Таким приемом постоянно пользуются в маркетинге, выделяя группы клиентов, покупателей, товаров и разрабатывая для каждой из них отдельную стратегию.
- ↑ Айвазян С. А., Бухштабер В. М., Енюков И. С., Мешалкин Л. Д. Прикладная статистика: Классификация и снижение размерности. — М.: Финансы и статистика, 1989. — 607 с.
- ↑ Мандель И. Д. Кластерный анализ. — М.: Финансы и статистика, 1988. — 176 с.
- ↑ Хайдуков Д. С. Применение кластерного анализа в государственном управлении// Философия математики: актуальные проблемы. — М.: МАКС Пресс, 2009. — 287 с.
- ↑ Классификация и кластер. Под ред. Дж. Вэн Райзина. М.: Мир, 1980. 390 с.
- ↑ Мандель И. Д. Кластерный анализ. — М.: Финансы и статистика, 1988. — С. 10.
- ↑ Tryon R.C. Cluster analysis. — London: Ann Arbor Edwards Bros, 1939. — 139 p.
- ↑ Жамбю М. Иерархический кластер-анализ и соответствия. — М.: Финансы и статистика, 1988. — 345 с.
- ↑ Дюран Б., Оделл П. Кластерный анализ. — М.: Статистика, 1977. — 128 с.
- ↑ Бериков В. С., Лбов Г. С. Современные тенденции в кластерном анализе Архивная копия от 10 августа 2013 на Wayback Machine // Всероссийский конкурсный отбор обзорно-аналитических статей по приоритетному направлению «Информационно-телекоммуникационные системы», 2008. — 26 с.
- ↑ Вятченин Д. А. Нечёткие методы автоматической классификации. — Минск: Технопринт, 2004. — 219 с.
- ↑ Олдендерфер М. С., Блэшфилд Р. К. Кластерный анализ / Факторный, дискриминантный и кластерный анализ: пер. с англ.; Под. ред. И. С. Енюкова. — М.: Финансы и статистика, 1989—215 с.
- На русском языке
- www.MachineLearning.ru — профессиональный вики-ресурс, посвященный машинному обучению и интеллектуальному анализу данных
- На английском языке
- COMPACT — Comparative Package for Clustering Assessment. A free Matlab package, 2006.
- P. Berkhin, Survey of Clustering Data Mining Techniques, Accrue Software, 2002.
- Jain, Murty and Flynn: Data Clustering: A Review, ACM Comp. Surv., 1999.
- for another presentation of hierarchical, k-means and fuzzy c-means see this introduction to clustering. Also has an explanation on mixture of Gaussians.
- David Dowe, Mixture Modelling page — other clustering and mixture model links.
- a tutorial on clustering [1] (недоступная ссылка с 13-05-2013 [2529 дней] — история)
- The on-line textbook: Information Theory, Inference, and Learning Algorithms, by David J.C. MacKay includes chapters on k-means clustering, soft k-means clustering, and derivations including the E-M algorithm and the variational view of the E-M algorithm.
- An overview of non-parametric clustering and computer vision
- «The Self-Organized Gene», tutorial explaining clustering through competitive learning and self-organizing maps.
- kernlab (недоступная ссылка с 13-05-2013 [2529 дней] — история) — R package for kernel based machine learning (includes spectral clustering implementation)
- Tutorial — Tutorial with introduction of Clustering Algorithms (k-means, fuzzy-c-means, hierarchical, mixture of gaussians) + some interactive demos (java applets)
- Data Mining Software — Data mining software frequently utilizes clustering techniques.
- Java Competitve Learning Application (недоступная ссылка с 13-05-2013 [2529 дней] — история) A suite of Unsupervised Neural Networks for clustering. Written in Java. Complete with all source code.
- Machine Learning Software — Also contains much clustering software.
- Fuzzy Clustering Algorithms and their Application to Medical Image Analysis PhD Thesis, 2001, by AI Shihab.
- Cluster Computing and MapReduce Lecture 4
- PyClustering Library — Python library contains clustering algorithms (C++ source code can be also used — CCORE part of the library) and collection of neural and oscillatory networks with examples and demos.
Кластерный анализ графиков. Основы и рыночные примеры.
Cluster analysis (кластерный анализ) – это анализ данных на основе сбора статистических, в более точечном спектре сведений, об общей структуризации предложенных материалов, включающий в себя набор различных алгоритмов классификаций. Основанный на объёме, дельте или других параметрах.
Согласен, звучит абсолютно непонятно. Мне самому́ не по нраву такие определения, из прочтения которых, ничего не осваивается. Но дать определение необходимо, поэтому сегодня мы с вами попытаемся разобраться, что такое кластерный анализ на живых, проиллюстрированных примерах.
Основатель кластерного анализаКластерный анализ впервые ввёл математик Роберт Трион в 1939 году. Вообще, кластерный анализ охватывает множество дисциплин, таких как математика, архитектура, маркетинг, археология, медицина, философия, психология… Но нас интересует Биржевое дело, поэтому и вектор усилия будем направлять на эту сферу деятельности.
Вид кластерного графика
Кластерные объёмы в терминале Sbpro. Идеальны для кластерного анализа.Вот так эмпирически выглядит кластерный график. Вообще-то кластера могут быть с разными показателями данных. Например, в кластерах могут отображаться объёмы пройденных контрактов значения Ask и Bid, то есть цена покупки и цена продажи, дельта показатели (разница между ценой аск и бид) или как на нашем скриншоте, профиль кластера.
Так, если мы возьмём на рассмотрение абсолютно любой кластер, то его можно объяснить в сравнении японской свечи. Слева от кластера находится полоска красного или зелёного цвета, в зависимости от того какая была бы свеча. Если свеча бычья, то есть зелёная, значит и полоска-бар на бычьем, восходящем кластере будет зелёная. Противоположно верно будет и по отношению к нисходящие, красному цвету.
Описание кластерного графика в терминале и кластерного анализа
Скорее всего, вы уже успели заметить, что некоторые бары не доходят до конца кластеров. Верно, вы эмпирически внимательные читатели, бары это тела японских свечей. А тот участок кластера, который без полоски, это и есть хвосты, фитильки или тени японских свечей. Обратите внимание, они почти совпадают с закрытием одного кластера с открытием следующего. Разумеется плюс/минус пару пунктов, из-за волатильности рынка.
А вот о чём нам сигнализируют числа, распложенные в каждой из ячеек. Кстати, каждая из горизонтальных полосок, ячеек в каждом кластере, является отметкой одного пункта. Длина каждого пункта соответствует значению цифры, расположенной в этой са́мой ячейке. Белой рамочкой обводится ячейка или пункт с максимально пройденным количеством контрактов по соответствующему ценовому уровню. Но сто́ит поправиться, что значения максимальных объёмов, можно задавать самостоятельно.
Как правильно интерпретировать кластерные значения
Перед вами скриншот графика с периодом М1, с продолжительным нисходящим движением. Наша с вами задача, разобраться, а вернее изучить данную ситуацию на активе фьючерса на Сбербанк. Надо отметить, что такое падение на тайм фрейме М1, это очень неординарный случай. То есть 250 пунктов практически за 45 минут, для данного инструмента, я бы назвал редчайшим падением.
Совет! Не используйте кластерный график постоянно, из-за сложности анализа, вам будет трудно. Включайте его только в важных моментах. Например у уровней.
Итак, красным прямоугольником отмечена область, в которой, как мне кажется, мы с вами найдём ключ для разгадки, что же спровоцировало такое падение. Согласитесь, с помощью отображения японских свечей довольно проблематично искать зацепку на данном участке. Единственное что мы можем констатировать, это факт выхода ценой из баланса. Но это бы мы поняли в режиме реального времени, пройдя уже около 75 пунктов. То есть нам опять пришлось бы запрыгивать в уходящий поезд, отдавая рынку львиную долю потенциального заработка.
Так же на скриншоте японских свечей, непосредственно перед падением, мы видим ретест области. К сожалению больше никаких подсказок нам не видно на данном отображении графика. Теперь, для более тщательного анализа и полноты информации, давайте переключимся на кластерный график с отображением объёмов.
Переключение графика на кластеры.
Большинство объёма сконцентрированы в верхних частях графика.Мы видим, что большинство максимальных объёмов сконцентрировались в верхних частях кластеров. О чём нам это говорит? Если вернёмся к нашим японским свечам, то мы обратим внимание на центральную область красного прямоугольника. По опыту могу утверждать, что именно в центральной части прямоугольника, расположены лимитные заявки на продажу, более-менее, крупных участников рынка. Иначе как объяснить, что цена при каждом подходе к этим ценовым уровням, отскакивала обратно вниз!? Возвращаемся к кластерам.
Кластерный анализ пытается найти следы крупных игроков на графике. Это происходит за счёт (чаще всего) анализа прошедших крупных заявок.
Видите, примерно посередине красного прямоугольника есть скопление максимальных объёмов – здесь были лимитники на продажу. Я смею предположить, что «последней каплей» стал объём размером в 121 контракт, при ретесте области. К тому же он сформировался на том же ценовом уровне 21 922, что и объём в кластере чуть поодаль, со значением в 219 контрактов. По моему субъективному мнению, там на ретесте, стоял ордер Sell Stop, смотрите подсказку ниже. Обращаю ваше внимание, что цветовая гамма окрашивания ячеек в кластерах, не при всех лимитных ордерах совпадают по соответствующим цветам бид и аск!
Кластерный анализ и механика рынка – неделимы.
Верно-истинная интерпретация значений Bid и Ask
Немного уйдя в сторону от нашей непосредственной темы о кластерном анализе, изучим верные значения предложения и спроса, то есть Bid и Ask. Стоит осознать, уважаемые читатели, что без понимания, что и с чем здесь едят, и как вообще это работает, дальнейшее чтение и просматривания «обыкновенных» картинок, бессмысленно напрасно. С таким же успехом лучше смотрите приколы с котами на You Tube, пользы будет больше и голова ясная и свежая. Только лишь по этой причине, вам просто важно, либо прочитать лекцию о механике рынка. Либо посмотреть видео ниже.
Видео “введение в механику рынка”.
Изучаем кластерный график шаг за шагом.
Давайте начнём изучение кластеров шаг за шагом. Опираемся на скриншот ниже и шаг за шагом следим за ходом мыслей:
Выход лонгистов для снижение ценыНа графике с отображением бид-аск, при ретесте (обведённый маркером кластер), есть две значимых ячейки. Тот пункт, что на уровне 21 922, вероятнее всего отработал отложенным ордером на продажу, т.к. во-первых, сам уровень значимый, во-вторых, пик кластера. Вряд ли получилось бы такое соотношение между бид и аск, на вершине кластера – 0 к 121 (к тому же мы держим в голове действующий флэт плотности лимитных заявок). В данной ситуации, ещё за мгновение до ретеста, кто-то из опытных участников рынка вовремя подсуетился и выставил (а возможно и выставилИ), отложенный ордер Sell Stop на уровне 21 922.
В дальнейших секундах, по мере снижения цены, очевидно, другие трейдеры подхватили данное развитие событий, запрыгнув в тронувшийся паровоз, допустив типичные ошибки большинства. Тем самым ещё больше подкинув дровишек в топку парораспределительного механизма… На чуть нижерасположенной ячейке, красного цвета на продажу видно, тоже не равномерное распределение спроса и предложения. Отчётливо заметно, как продавцы превзошли покупателей на 111 контрактов, 150-44=111. По причине превосходства, ячейка и окрасилась в красный цвет, цвет продаж. А имя этой разнице, между бид и аск – Дельта.
Дельта это разница между объёмом сделок, прошедших по цене бид и аск. Грубо говоря (примитивно) между покупками и продажами.
Кластерный анализ и интерпретация Дельта показателей
Дельта и провокация в кластерном графикеКак упоминалось выше, дельта это разница между бидом и аском, спросом и предложением, покупателями и продавцами. Так, на выше расположенном скриншоте, мы наблюдаем отрицательную дельту. Можно ли сказать, что после формирования этой дельты, цена устремилась вниз? Несомненно, можно. Но так же можно допустить, что эта дельта наоборот приостановила цену, при подъёме наверх. К сожалению, на истории мы этого не узнаем. Увы, мы не в курсе того, что было первоочередным, подъём или спуск. Или цена вообще 3-5 раз дёргалась туда-сюда. Но мы здесь о том и говорим, что в режиме реального времени, нам было бы в разы проще понимать концепцию движений.
Но как бы там не было, мы с вами нашли и разобрали очаг возгорания огромного нисходящего движения. Понимаете, ведь нам нужно было лишь убедиться в отношении объёмов между быками и медведями. Это важно при выходе ценой из баланса. На последнем скриншоте, кластер дельта, мы узрели инициативную сделку, а дальше, отталкиваясь от флэта, пошло как понакатанной. Примерно так происходит кластерный анализ. Понимаю, сложно. А что делать? Вы сами первые начали.
Резюме кластерного анализа
Итак, резюмируем эффективность кластерного анализа, с признанием фишек технического анализа. В данной сложившейся ситуации на рынке, «глобального» нисходящего движения фьючерса на Сбербанк, загибаем пальцы: Плотность отложенных ордеров в виде флэта, выход ценой из баланса, ретест областей, инициативная сделка, максимальные объёмы на верхних частях кластеров, правильно-истинная интерпретация бид-аск значений, обнаружение Sell Stop ордера и выявление значимой дельты.
По факту, в этой ситуации мы нащупали 8 признаков активности продавцов. Пять, из которых являются частью анализа по Футпринт, т.к. анализ кластеров, это один из подвидов футпринта. Но мы с вами тщательно разобрали кластерный анализ, а посему я смею предположить, что читатели этого материала довольно чётко впитали азы кластерного анализа.
Уважаемые начинающие трейдеры, изучайте всю «подноготную» ордеров, объёмов, психологии трейдинга и сферу рынка в целом, в рубрике Азбука Трейдера. И только в таком случае у вас появится шанс не бороться с ценой, а брать, что вам даёт рынок!
Эта статья – материал из рубрики “Азбука Трейдинга”. Загляните в неё. Там ещё много интересного!
Сложно? “Трейдинг для чайников” – бесплатное обучение рынкам.
Подпишитесь на наш телеграм канал и получите самую лучшую информацию.
Обзор алгоритмов кластеризации данных / Habr
Приветствую!В своей дипломной работе я проводил обзор и сравнительный анализ алгоритмов кластеризации данных. Подумал, что уже собранный и проработанный материал может оказаться кому-то интересен и полезен.
О том, что такое кластеризация, рассказал sashaeve в статье «Кластеризация: алгоритмы k-means и c-means». Я частично повторю слова Александра, частично дополню. Также в конце этой статьи интересующиеся могут почитать материалы по ссылкам в списке литературы.
Так же я постарался привести сухой «дипломный» стиль изложения к более публицистическому.
Понятие кластеризации
Кластеризация (или кластерный анализ) — это задача разбиения множества объектов на группы, называемые кластерами. Внутри каждой группы должны оказаться «похожие» объекты, а объекты разных группы должны быть как можно более отличны. Главное отличие кластеризации от классификации состоит в том, что перечень групп четко не задан и определяется в процессе работы алгоритма.
Применение кластерного анализа в общем виде сводится к следующим этапам:
- Отбор выборки объектов для кластеризации.
- Определение множества переменных, по которым будут оцениваться объекты в выборке. При необходимости – нормализация значений переменных.
- Вычисление значений меры сходства между объектами.
- Применение метода кластерного анализа для создания групп сходных объектов (кластеров).
- Представление результатов анализа.
После получения и анализа результатов возможна корректировка выбранной метрики и метода кластеризации до получения оптимального результата.
Меры расстояний
Итак, как же определять «похожесть» объектов? Для начала нужно составить вектор характеристик для каждого объекта — как правило, это набор числовых значений, например, рост-вес человека. Однако существуют также алгоритмы, работающие с качественными (т.н. категорийными) характеристиками.
После того, как мы определили вектор характеристик, можно провести нормализацию, чтобы все компоненты давали одинаковый вклад при расчете «расстояния». В процессе нормализации все значения приводятся к некоторому диапазону, например, [-1, -1] или [0, 1].
Наконец, для каждой пары объектов измеряется «расстояние» между ними — степень похожести. Существует множество метрик, вот лишь основные из них:
- Евклидово расстояние
Наиболее распространенная функция расстояния. Представляет собой геометрическим расстоянием в многомерном пространстве: - Квадрат евклидова расстояния
Применяется для придания большего веса более отдаленным друг от друга объектам. Это расстояние вычисляется следующим образом: - Расстояние городских кварталов (манхэттенское расстояние)
Это расстояние является средним разностей по координатам. В большинстве случаев эта мера расстояния приводит к таким же результатам, как и для обычного расстояния Евклида. Однако для этой меры влияние отдельных больших разностей (выбросов) уменьшается (т.к. они не возводятся в квадрат). Формула для расчета манхэттенского расстояния: - Расстояние Чебышева
Это расстояние может оказаться полезным, когда нужно определить два объекта как «различные», если они различаются по какой-либо одной координате. Расстояние Чебышева вычисляется по формуле: - Степенное расстояние
Применяется в случае, когда необходимо увеличить или уменьшить вес, относящийся к размерности, для которой соответствующие объекты сильно отличаются. Степенное расстояние вычисляется по следующей формуле:
,
где r и p – параметры, определяемые пользователем. Параметр p ответственен за постепенное взвешивание разностей по отдельным координатам, параметр r ответственен за прогрессивное взвешивание больших расстояний между объектами. Если оба параметра – r и p — равны двум, то это расстояние совпадает с расстоянием Евклида.
Выбор метрики полностью лежит на исследователе, поскольку результаты кластеризации могут существенно отличаться при использовании разных мер.
Классификация алгоритмов
Для себя я выделил две основные классификации алгоритмов кластеризации.
- Иерархические и плоские.
Иерархические алгоритмы (также называемые алгоритмами таксономии) строят не одно разбиение выборки на непересекающиеся кластеры, а систему вложенных разбиений. Т.о. на выходе мы получаем дерево кластеров, корнем которого является вся выборка, а листьями — наиболее мелкие кластера.
Плоские алгоритмы строят одно разбиение объектов на кластеры. - Четкие и нечеткие.
Четкие (или непересекающиеся) алгоритмы каждому объекту выборки ставят в соответствие номер кластера, т.е. каждый объект принадлежит только одному кластеру. Нечеткие (или пересекающиеся) алгоритмы каждому объекту ставят в соответствие набор вещественных значений, показывающих степень отношения объекта к кластерам. Т.е. каждый объект относится к каждому кластеру с некоторой вероятностью.
Объединение кластеров
В случае использования иерархических алгоритмов встает вопрос, как объединять между собой кластера, как вычислять «расстояния» между ними. Существует несколько метрик:
- Одиночная связь (расстояния ближайшего соседа)
В этом методе расстояние между двумя кластерами определяется расстоянием между двумя наиболее близкими объектами (ближайшими соседями) в различных кластерах. Результирующие кластеры имеют тенденцию объединяться в цепочки. - Полная связь (расстояние наиболее удаленных соседей)
В этом методе расстояния между кластерами определяются наибольшим расстоянием между любыми двумя объектами в различных кластерах (т.е. наиболее удаленными соседями). Этот метод обычно работает очень хорошо, когда объекты происходят из отдельных групп. Если же кластеры имеют удлиненную форму или их естественный тип является «цепочечным», то этот метод непригоден. - Невзвешенное попарное среднее
В этом методе расстояние между двумя различными кластерами вычисляется как среднее расстояние между всеми парами объектов в них. Метод эффективен, когда объекты формируют различные группы, однако он работает одинаково хорошо и в случаях протяженных («цепочечного» типа) кластеров. - Взвешенное попарное среднее
Метод идентичен методу невзвешенного попарного среднего, за исключением того, что при вычислениях размер соответствующих кластеров (т.е. число объектов, содержащихся в них) используется в качестве весового коэффициента. Поэтому данный метод должен быть использован, когда предполагаются неравные размеры кластеров. - Невзвешенный центроидный метод
В этом методе расстояние между двумя кластерами определяется как расстояние между их центрами тяжести. - Взвешенный центроидный метод (медиана)
Этот метод идентичен предыдущему, за исключением того, что при вычислениях используются веса для учета разницы между размерами кластеров. Поэтому, если имеются или подозреваются значительные отличия в размерах кластеров, этот метод оказывается предпочтительнее предыдущего.
Обзор алгоритмов
Алгоритмы иерархической кластеризации
Среди алгоритмов иерархической кластеризации выделяются два основных типа: восходящие и нисходящие алгоритмы. Нисходящие алгоритмы работают по принципу «сверху-вниз»: в начале все объекты помещаются в один кластер, который затем разбивается на все более мелкие кластеры. Более распространены восходящие алгоритмы, которые в начале работы помещают каждый объект в отдельный кластер, а затем объединяют кластеры во все более крупные, пока все объекты выборки не будут содержаться в одном кластере. Таким образом строится система вложенных разбиений. Результаты таких алгоритмов обычно представляют в виде дерева – дендрограммы. Классический пример такого дерева – классификация животных и растений.
Для вычисления расстояний между кластерами чаще все пользуются двумя расстояниями: одиночной связью или полной связью (см. обзор мер расстояний между кластерами).
К недостатку иерархических алгоритмов можно отнести систему полных разбиений, которая может являться излишней в контексте решаемой задачи.
Алгоритмы квадратичной ошибки
Задачу кластеризации можно рассматривать как построение оптимального разбиения объектов на группы. При этом оптимальность может быть определена как требование минимизации среднеквадратической ошибки разбиения:
где cj — «центр масс» кластера j (точка со средними значениями характеристик для данного кластера).
Алгоритмы квадратичной ошибки относятся к типу плоских алгоритмов. Самым распространенным алгоритмом этой категории является метод k-средних. Этот алгоритм строит заданное число кластеров, расположенных как можно дальше друг от друга. Работа алгоритма делится на несколько этапов:
- Случайно выбрать k точек, являющихся начальными «центрами масс» кластеров.
- Отнести каждый объект к кластеру с ближайшим «центром масс».
- Пересчитать «центры масс» кластеров согласно их текущему составу.
- Если критерий остановки алгоритма не удовлетворен, вернуться к п. 2.
В качестве критерия остановки работы алгоритма обычно выбирают минимальное изменение среднеквадратической ошибки. Так же возможно останавливать работу алгоритма, если на шаге 2 не было объектов, переместившихся из кластера в кластер.
К недостаткам данного алгоритма можно отнести необходимость задавать количество кластеров для разбиения.
Нечеткие алгоритмы
Наиболее популярным алгоритмом нечеткой кластеризации является алгоритм c-средних (c-means). Он представляет собой модификацию метода k-средних. Шаги работы алгоритма:
- Выбрать начальное нечеткое разбиение n объектов на k кластеров путем выбора матрицы принадлежности U размера n x k.
- Используя матрицу U, найти значение критерия нечеткой ошибки:
,
где ck — «центр масс» нечеткого кластера k:
. - Перегруппировать объекты с целью уменьшения этого значения критерия нечеткой ошибки.
- Возвращаться в п. 2 до тех пор, пока изменения матрицы U не станут незначительными.
Этот алгоритм может не подойти, если заранее неизвестно число кластеров, либо необходимо однозначно отнести каждый объект к одному кластеру.
Алгоритмы, основанные на теории графов
Суть таких алгоритмов заключается в том, что выборка объектов представляется в виде графа G=(V, E), вершинам которого соответствуют объекты, а ребра имеют вес, равный «расстоянию» между объектами. Достоинством графовых алгоритмов кластеризации являются наглядность, относительная простота реализации и возможность вносения различных усовершенствований, основанные на геометрических соображениях. Основными алгоритмам являются алгоритм выделения связных компонент, алгоритм построения минимального покрывающего (остовного) дерева и алгоритм послойной кластеризации.
Алгоритм выделения связных компонент
В алгоритме выделения связных компонент задается входной параметр R и в графе удаляются все ребра, для которых «расстояния» больше R. Соединенными остаются только наиболее близкие пары объектов. Смысл алгоритма заключается в том, чтобы подобрать такое значение R, лежащее в диапазон всех «расстояний», при котором граф «развалится» на несколько связных компонент. Полученные компоненты и есть кластеры.
Для подбора параметра R обычно строится гистограмма распределений попарных расстояний. В задачах с хорошо выраженной кластерной структурой данных на гистограмме будет два пика – один соответствует внутрикластерным расстояниям, второй – межкластерным расстояния. Параметр R подбирается из зоны минимума между этими пиками. При этом управлять количеством кластеров при помощи порога расстояния довольно затруднительно.
Алгоритм минимального покрывающего дерева
Алгоритм минимального покрывающего дерева сначала строит на графе минимальное покрывающее дерево, а затем последовательно удаляет ребра с наибольшим весом. На рисунке изображено минимальное покрывающее дерево, полученное для девяти объектов.
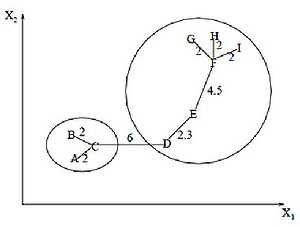
Путём удаления связи, помеченной CD, с длиной равной 6 единицам (ребро с максимальным расстоянием), получаем два кластера: {A, B, C} и {D, E, F, G, H, I}. Второй кластер в дальнейшем может быть разделён ещё на два кластера путём удаления ребра EF, которое имеет длину, равную 4,5 единицам.
Послойная кластеризация
Алгоритм послойной кластеризации основан на выделении связных компонент графа на некотором уровне расстояний между объектами (вершинами). Уровень расстояния задается порогом расстояния c. Например, если расстояние между объектами , то .
Алгоритм послойной кластеризации формирует последовательность подграфов графа G, которые отражают иерархические связи между кластерами:
,
где Gt = (V, Et) — граф на уровне сt,
,
сt – t-ый порог расстояния,
m – количество уровней иерархии,
G0 = (V, o), o – пустое множество ребер графа, получаемое при t0 = 1,
Gm = G, то есть граф объектов без ограничений на расстояние (длину ребер графа), поскольку tm = 1.
Посредством изменения порогов расстояния {с0, …, сm}, где 0 = с0 < с1 < …< сm = 1, возможно контролировать глубину иерархии получаемых кластеров. Таким образом, алгоритм послойной кластеризации способен создавать как плоское разбиение данных, так и иерархическое.
Сравнение алгоритмов
Вычислительная сложность алгоритмов
| Алгоритм кластеризации | Вычислительная сложность |
| Иерархический | O(n2) |
| k-средних | O(nkl), где k – число кластеров, l – число итераций |
|---|---|
| c-средних | |
| Выделение связных компонент | зависит от алгоритма |
| Минимальное покрывающее дерево | O(n2 log n) |
| Послойная кластеризация | O(max(n, m)), где m < n(n-1)/2 |
Сравнительная таблица алгоритмов
| Алгоритм кластеризации | Форма кластеров | Входные данные | Результаты |
| Иерархический | Произвольная | Число кластеров или порог расстояния для усечения иерархии | Бинарное дерево кластеров |
| k-средних | Гиперсфера | Число кластеров | Центры кластеров |
| c-средних | Гиперсфера | Число кластеров, степень нечеткости | Центры кластеров, матрица принадлежности |
| Выделение связных компонент | Произвольная | Порог расстояния R | Древовидная структура кластеров |
| Минимальное покрывающее дерево | Произвольная | Число кластеров или порог расстояния для удаления ребер | Древовидная структура кластеров |
| Послойная кластеризация | Произвольная | Последовательность порогов расстояния | Древовидная структура кластеров с разными уровнями иерархии |
Немного о применении
В своей работе мне нужно было из иерархических структур (деревьев) выделять отдельные области. Т.е. по сути необходимо было разрезать исходное дерево на несколько более мелких деревьев. Поскольку ориентированное дерево – это частный случай графа, то естественным образом подходят алгоритмы, основанными на теории графов.
В отличие от полносвязного графа, в ориентированном дереве не все вершины соединены ребрами, при этом общее количество ребер равно n–1, где n – число вершин. Т.е. применительно к узлам дерева, работа алгоритма выделения связных компонент упростится, поскольку удаление любого количества ребер «развалит» дерево на связные компоненты (отдельные деревья). Алгоритм минимального покрывающего дерева в данном случае будет совпадать с алгоритмом выделения связных компонент – путем удаления самых длинных ребер исходное дерево разбивается на несколько деревьев. При этом очевидно, что фаза построения самого минимального покрывающего дерева пропускается.
В случае использования других алгоритмов в них пришлось бы отдельно учитывать наличие связей между объектами, что усложняет алгоритм.
Отдельно хочу сказать, что для достижения наилучшего результата необходимо экспериментировать с выбором мер расстояний, а иногда даже менять алгоритм. Никакого единого решения не существует.
Список литературы
1. Воронцов К.В. Алгоритмы кластеризации и многомерного шкалирования. Курс лекций. МГУ, 2007.
2. Jain A., Murty M., Flynn P. Data Clustering: A Review. // ACM Computing Surveys. 1999. Vol. 31, no. 3.
3. Котов А., Красильников Н. Кластеризация данных. 2006.
3. Мандель И. Д. Кластерный анализ. — М.: Финансы и Статистика, 1988.
4. Прикладная статистика: классификация и снижение размерности. / С.А. Айвазян, В.М. Бухштабер, И.С. Енюков, Л.Д. Мешалкин — М.: Финансы и статистика, 1989.
5. Информационно-аналитический ресурс, посвященный машинному обучению, распознаванию образов и интеллектуальному анализу данных — www.machinelearning.ru
6. Чубукова И.А. Курс лекций «Data Mining», Интернет-университет информационных технологий — www.intuit.ru/department/database/datamining
Кластерный анализ в трейдинге - основы, паттерны и программы
Как говорил великий трейдер — объем это единственный индикатор в вашем терминале, который действительно помогает торговать в профит. Это действительно так, умение работать с объемами поможет вам уверенно действовать и в скапельперских сделках и в среднесрочных и в долгосрочных. Но в последнее время стал популярен кластерный анализ, который основан именно на объемах. В этой статье мы рассмотрим, как использовать кластерный анализ в трейдинге и какие плюсы от этого вы сможете получить.
Что такое кластерный анализ
Кластерный анализ — это, по сути, профиль объема для каждой свечи графика на выбранном таймфрейме. Т.е. с помощью кластерного анализа вы можете заглянуть внутрь свечи и увидеть на каком уровне цены, какой объем контрактов был проторгован.
Кластер представляет собой уровень в свече, который отображает объем проторгованных контрактов, либо дельту, смотря, что вы выбираете в настройках программы.
Какую информацию открывает кластерный анализ
С помощью кластеров вы можете узнать следующее:
- Объем проторгованных контрактов по каждому уровню цены внутри свечи графика.
- Объем сделок по Ask — цене продавцов.
- Объем сделок по Bid — цене покупателей.
- Дельту — разницу объемов покупателей и продавцов.
- Общий объем все проторгованных контрактов.
- Рыночный профиль.
Логика кластерного анализа
Поскольку вы видите точные размеры проторгованных объемов на каждом ценовом уровне, то вы можете применять эту информацию следующим образом:
- Строить объемные уровни поддержки и сопротивления. Т.е. находить на графике скопления больших объемов и строить на их основе уровни, поскольку в будущем цена обязательно будет на них реагировать.
- Понимать, кто в данный момент преобладает на рынке — покупатель или продавец. Вы можете использовать дельту, чтобы понять, в какую сторону в данный момент может двинуться рынок с большей долей вероятности.
Плюс к этому вы должны понимать, что рынок толкает рыночный ордер, а останавливает движение лимитный ордер. Все крупные игроки всегда входят в рынок с помощью лимитных заявок, при этом движение или тренд останавливается, а то и во все разворачивается. Поскольку рыночный ордер не в силах выкупить все лимитные заявки.
Основные типы баров
Это довольно важная информация, поскольку на ней строятся торговые системы для кластерного анализа, поэтому рассмотрим здесь основные типы баров.
В зависимости от того, где в свече (баре) расположен максимальный объем, бары делятся на:
- Тормозные.
- Толкающие.
Толкающие бары — своего рода создатели движения, т.к. они толкают цену, а тормозящие, как уже понятно наоборот тормозят и разворачивают цену.
Что было более понятно, я подобрал изображения этих баров.
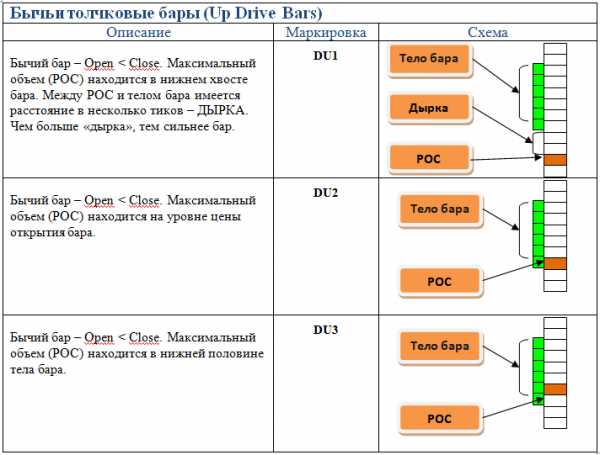
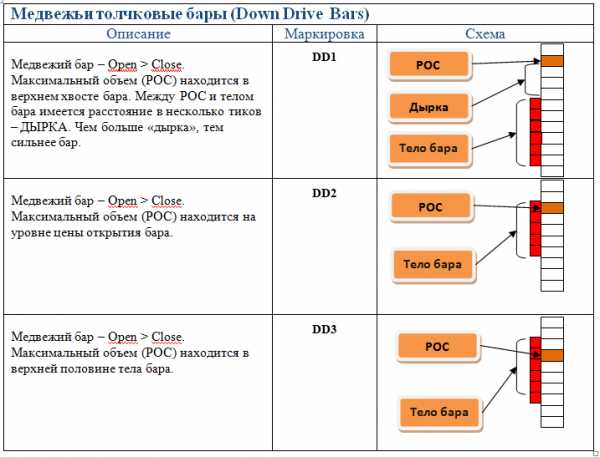
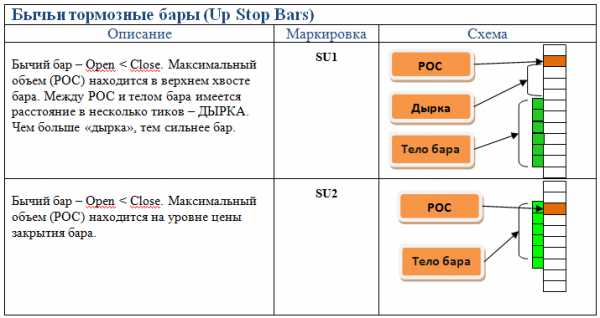
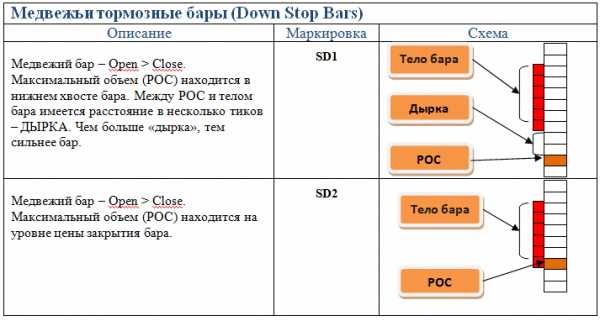
В общем контексте рынка это выглядит так:
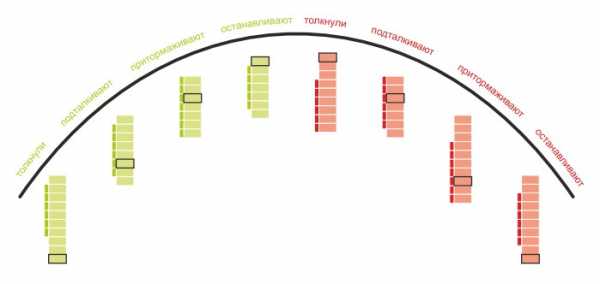
Как использовать кластерный анализ в торговле
Сейчас я вам покажу простейшую стратегию.
Для этого находим на графике флетовую проторговку, натягиваем на нее профиль объема. Это поможет нам определить, где именно в этой проторговке сосредоточен максимальный объем.
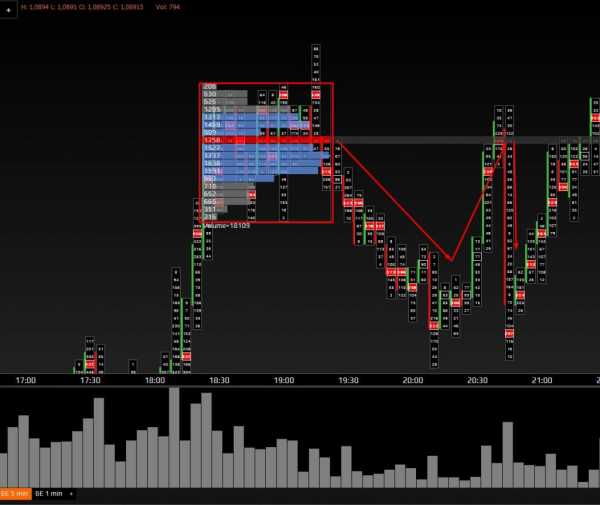
На скриншоте это отчётливо видно, это красная полоса, в которой проторговали 1758 контрактов. Это так называем уровень POC.
Далее ожидаем, когда мы выйдем из этого флета. И после того, как выйдем, мы обязательно подойдем к уровню, где сосредоточен максимальный объем.
В 80% случаев мы получаем от этого уровню реакцию в виде отскока. Так вот, при касании этого уровня мы можем входить в сделку. Ставим стоп-лосс за вершиной проторговки.
Точно таким же образом можно работать не только на форексе, но и на бинарных опционах. Мы заключаем ставку, на отскок от уровня.
Как видите довольно простая стратегия и очень эффективная, попробуйте сами.
Дельта в кластерном анализе
Помимо объема, кластера могу показывать нам и дельту. Это разница между проторгованными объемами продавцов и покупателей.
Дельта = ASK — BID
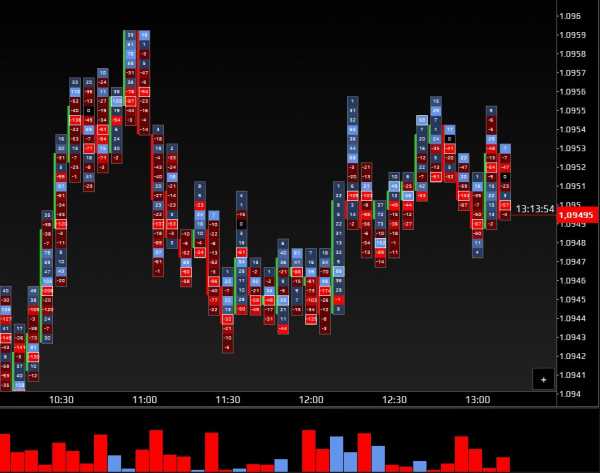
Если дельта положительная, это значит что покупателей больше, чем продавцов, если дельта отрицательная, то на оборот — продавцов больше, чем покупателей на данном ценовом уровне.
Трейдеры разделяют несколько видов дельты:
- Умеренная (возникает, как правило, во флете, примерно одинаковое количество покупателей и продавцов, так называем баланс).
- Нормальная (это обычно трендовая фаза, где видно сильно преобладание какой либо стороны).
- Критическая (разворот и зарождение нового тренда).
Программы для кластерного графика
Представляю вам самые популярные программы для кластерного анализа на данный момент:
1) SBPro
Основные преимущества:
Кластеры
Кластерные графики для отображения объемов, дельты и Bid-Ask.
Симулятор
Тестирование стратегий на истории.
Лента сделок
Лента сделок прямо на графике! Гибкая аккумуляция принтов.
Профили
Множество типов Profile графиков с фильтрацией по объему и дельте.
Сайт — https://www.sb-professional.com/
2) ATAS
Основные преимущества:
Smart Tape
“Умная Лента Принтов” агрегирует и фильтрует рыночные сделки, что позволит Вам увидеть реальных крупных игроков рынка.
Графики
6 видов построения графиков, в том числе профильные и кластерные графики (25 вариантов футпринта).
Smart DOM
“Умный Стакан” позволит проводить анализ биржевой ликвидности и отслеживать заявки крупных игроков.
Торговля
Удобная торговля и управление позициями, как через торговый стакан, так и прямо с графика (Chart Trader).
Сайт — https://orderflowtrading.ru/
3) Volfix
Основные преимущества:
Многоуровневая система алертов.
Широкий набор инструментов для объемного и профильного анализа.
Интегрированный DOM Analyzer можно адаптировать под любые Ваши торговые идеи.
Более семи лет исторических данных — цена, Tick , Trade и Bid & Ask объем, Block Trades и др.
Сайт — http://volfix.net/ru/
4) NinjaTrader
Основные преимущества:
Вам доступны самые крупные мировые рынки, включая:
— Фьючерсы.
— Форекс.
— Опционы.
— CFD’s.
— Акции.
Многочисленные встроенные индикаторы для принятия важных торговых решений.
Большой выбор провайдеров данных.
Сайт — https://ninjatrader.com/ru/
5) TigerTrade
Основные преимущества:
Свечные графики и футпринт.
Динамический стакан.
Лента сделок.
Проигрыватель истории.
Аналитические инструменты.
Статистика сделок.
История.
Риск-менеджер.
Сайт — https://tigertradesoft.ru/
Если вы не хотите использовать какие либо сторонние программы, то вы можете использовать индикаторы для MetaTrader, но как правило эти индикаторы показывают не реальный объем, а тиковый.
Заключение
Как вы уже поняли, кластерный анализ дает возможность взглянуть на движение цены изнутри, теперь вы можете строить действительно мощные уровни сопротивления и поддержки, которые отрабатывают в разы лучше, обычных визуальных уровней.
Поэтому, если вы занимаетесь трейдингом, но еще включили кластера в свою торговую систему, то советую вам попробовать. Ведь это может стать отличным фильтром, для отсеивания неуверенных сделок.
Кластерный анализ - это... Что такое Кластерный анализ?
Результат кластерного анализа обозначен раскрашиванием точек в соответствии с принадлежностью к одному из трёх кластеров.Кластерный анализ (англ. cluster analysis) — задача разбиения заданной выборки объектов (ситуаций) на подмножества, называемые кластерами, так, чтобы каждый кластер состоял из схожих объектов, а объекты разных кластеров существенно отличались. Задача кластеризации относится к статистической обработке, а также к широкому классу задач обучения без учителя.
Большинство исследователей склоняются к тому, что впервые термин «кластерный анализ» (англ. cluster — гроздь, сгусток, пучок) был предложен математиком Р.Трионом[1]. Впоследствии возник ряд терминов, которые в настоящее время принято считать синонимами термина «кластерный анализ»: автоматическая классификация; ботриология.
Кластерный анализ — это многомерная статистическая процедура, выполняющая сбор данных, содержащих информацию о выборке объектов, и затем упорядочивающая объекты в сравнительно однородные группы[2][3][4][5](кластеры)(Q-кластеризация, или Q-техника, собственно кластерный анализ). Кластер — группа элементов, характеризуемых общим свойством, главная цель кластерного анализа — нахождение групп схожих объектов в выборке. Спектр применений кластерного анализа очень широк: его используют в археологии, медицине, психологии, химии, биологии, государственном управлении, филологии, антропологии, маркетинге, социологии и других дисциплинах. Однако универсальность применения привела к появлению большого количества несовместимых терминов, методов и подходов, затрудняющих однозначное использование и непротиворечивую интерпретацию кластерного анализа. Орлов А. И. предлагает различать следующим образом:
В дискриминантном анализе классы предполагаются заданными — плотностями вероятностей или обучающими выборками. Задача состоит в том, чтобы вновь поступающий объект отнести в один из этих классов. У понятия «дискриминация» имеется много синонимов: диагностика, распознавание образов с учителем, автоматическая классификация с учителем, статистическая классификация и т. д. При кластеризации и группировке целью является выявление и выделение классов. Синонимы: построение классификации, распознавание образов без учителя, автоматическая классификация без учителя, таксономия и др. Задача кластер-анализа состоит в выяснении по эмпирическим данным, насколько элементы «группируются» или распадаются на изолированные «скопления», «кластеры» (от cluster (англ.) — гроздь, скопление). Иными словами, задача — выявление естественного разбиения на классы, свободного от субъективизма исследователя, а цель — выделение групп однородных объектов, сходных между собой, при резком отличии этих групп друг от друга[6]
Задачи и условия
Кластерный анализ выполняет следующие основные задачи:
- Разработка типологии или классификации.
- Исследование полезных концептуальных схем группирования объектов.
- Порождение гипотез на основе исследования данных.
- Проверка гипотез или исследования для определения, действительно ли типы (группы), выделенные тем или иным способом, присутствуют в имеющихся данных.
Независимо от предмета изучения применение кластерного анализа предполагает следующие этапы:
- Отбор выборки для кластеризации. Подразумевается, что имеет смысл кластеризовать только количественные данные.
- Определение множества переменных, по которым будут оцениваться объекты в выборке, то есть признакового пространства.
- Вычисление значений той или иной меры сходства (или различия) между объектами.
- Применение метода кластерного анализа для создания групп сходных объектов.
- Проверка достоверности результатов кластерного решения.
Кластерный анализ предъявляет следующие требования к данным[источник не указан 302 дня]:
- показатели не должны коррелировать между собой;
- показатели не должны противоречить теории измерений;
- распределение показателей должно быть близко к нормальному;
- показатели должны отвечать требованию «устойчивости», под которой понимается отсутствие влияния на их значения случайных факторов;
- выборка должна быть однородна, не содержать «выбросов».
Можно встретить описание двух фундаментальных требований предъявляемых к данным — однородность и полнота:
-
Однородность требует, чтобы все сущности, представленные в таблице, были одной природы. Требование полноты состоит в том, чтобы множества I и J представляли полную опись проявлений рассматриваемого явления. Если рассматривается таблица в которой I — совокупность, а J — множество переменных, описывающих эту совокупность, то должно должно быть представительной выборкой из изучаемой совокупности, а система характеристик J должна давать удовлетворительное векторное представление индивидов i с точки зрения исследователя[7].
Если кластерному анализу предшествует факторный анализ, то выборка не нуждается в «ремонте» — изложенные требования выполняются автоматически самой процедурой факторного моделирования (есть ещё одно достоинство — z-стандартизация без негативных последствий для выборки; если её проводить непосредственно для кластерного анализа, она может повлечь за собой уменьшение чёткости разделения групп). В противном случае выборку нужно корректировать.
Типология задач кластеризации
Типы входных данных
- Признаковое описание объектов. Каждый объект описывается набором своих характеристик, называемых признаками. Признаки могут быть числовыми или нечисловыми.
- Матрица расстояний между объектами. Каждый объект описывается расстояниями до всех остальных объектов метрического пространства.
- Матрица сходства между объектами[8]. Учитывается степень сходства объекта с другими объектами выборки в метрическом пространстве. Сходство здесь дополняет расстояние (различие) между объектами до 1.
В современной науке применяется несколько алгоритмов обработки входных данных. Анализ путём сравнения объектов, исходя из признаков, (наиболее распространённый в биологических науках) называется Q-типом анализа, а в случае сравнения признаков, на основе объектов — R-типом анализа. Существуют попытки использования гибридных типов анализа (например, RQ-анализ), но данная методология ещё должным образом не разработана.
Цели кластеризации
- Понимание данных путём выявления кластерной структуры. Разбиение выборки на группы схожих объектов позволяет упростить дальнейшую обработку данных и принятия решений, применяя к каждому кластеру свой метод анализа (стратегия «разделяй и властвуй»).
- Сжатие данных. Если исходная выборка избыточно большая, то можно сократить её, оставив по одному наиболее типичному представителю от каждого кластера.
- Обнаружение новизны (англ. novelty detection). Выделяются нетипичные объекты, которые не удаётся присоединить ни к одному из кластеров.
В первом случае число кластеров стараются сделать поменьше. Во втором случае важнее обеспечить высокую степень сходства объектов внутри каждого кластера, а кластеров может быть сколько угодно. В третьем случае наибольший интерес представляют отдельные объекты, не вписывающиеся ни в один из кластеров.
Во всех этих случаях может применяться иерархическая кластеризация, когда крупные кластеры дробятся на более мелкие, те в свою очередь дробятся ещё мельче, и т. д. Такие задачи называются задачами таксономии. Результатом таксономии является древообразная иерархическая структура. При этом каждый объект характеризуется перечислением всех кластеров, которым он принадлежит, обычно от крупного к мелкому.
Методы кластеризации
Общепринятой классификации методов кластеризации не существует, но можно отметить солидную попытку В. С. Берикова и Г. С. Лбова[9]. Если обобщить различные классификации методов кластеризации, то можно выделить ряд групп (некоторые методы можно отнести сразу к нескольким группам и потому предлагается рассматривать данную типизацию как некоторое приближение к реальной классификации методов кластеризации):
- Вероятностный подход. Предполагается, что каждый рассматриваемый объект относится к одному из k классов. Некоторые авторы (например, А. И. Орлов) считают, что данная группа вовсе не относится к кластеризации и противопоставляют её под названием «дискриминация», то есть выбор отнесения объектов к одной из известных групп (обучающих выборок).
- Подходы на основе систем искусственного интеллекта. Весьма условная группа, так как методов AI очень много и методически они весьма различны.
- Логический подход. Построение дендрограммы осуществляется с помощью дерева решений.
- Теоретико-графовый подход.
- Графовые алгоритмы кластеризации
- Иерархический подход. Предполагается наличие вложенных групп (кластеров различного порядка). Алгоритмы в свою очередь подразделяются на агломеративные (объединительные) и дивизивные (разделяющие). По количеству признаков иногда выделяют монотетические и политетические методы классификации.
- Иерархическая дивизивная кластеризация или таксономия. Задачи кластеризации рассматриваются в количественной таксономии.
- Другие методы. Не вошедшие в предыдущие группы.
- Статистические алгоритмы кластеризации
- Ансамбль кластеризаторов
- Алгоритмы семейства KRAB
- Алгоритм, основанный на методе просеивания
- DBSCAN и др.
Подходы 4 и 5 иногда объединяют под названием структурного или геометрического подхода, обладающего большей формализованностью понятия близости[10]. Несмотря на значительные различия между перечисленными методами все они опираются на исходную «гипотезу компактности»: в пространстве объектов все близкие объекты должны относиться к одному кластеру, а все различные объекты соответственно должны находиться в различных кластерах.
Формальная постановка задачи кластеризации
Пусть — множество объектов, — множество номеров (имён, меток) кластеров. Задана функция расстояния между объектами . Имеется конечная обучающая выборка объектов . Требуется разбить выборку на непересекающиеся подмножества, называемые кластерами, так, чтобы каждый кластер состоял из объектов, близких по метрике , а объекты разных кластеров существенно отличались. При этом каждому объекту приписывается номер кластера .
Алгоритм кластеризации — это функция , которая любому объекту ставит в соответствие номер кластера . Множество в некоторых случаях известно заранее, однако чаще ставится задача определить оптимальное число кластеров, с точки зрения того или иного критерия качества кластеризации.
Кластеризация (обучение без учителя) отличается от классификации (обучения с учителем) тем, что метки исходных объектов изначально не заданы, и даже может быть неизвестно само множество .
Решение задачи кластеризации принципиально неоднозначно, и тому есть несколько причин (как считает ряд авторов):
- не существует однозначно наилучшего критерия качества кластеризации. Известен целый ряд эвристических критериев, а также ряд алгоритмов, не имеющих чётко выраженного критерия, но осуществляющих достаточно разумную кластеризацию «по построению». Все они могут давать разные результаты. Следовательно, для определения качества кластеризации требуется эксперт предметной области, который бы мог оценить осмысленность выделения кластеров.
- число кластеров, как правило, неизвестно заранее и устанавливается в соответствии с некоторым субъективным критерием. Это справедливо только для методов дискриминации, так как в методах кластеризации выделение кластеров идёт за счёт формализованного подхода на основе мер близости.
- результат кластеризации существенно зависит от метрики, выбор которой, как правило, также субъективен и определяется экспертом. Но стоит отметить, что есть ряд рекомендаций к выбору мер близости для различных задач.
Применение
В биологии
В биологии кластеризация имеет множество приложений в самых разных областях. Например, в биоинформатике с помощью нее анализируются сложные сети взаимодействующих генов, состоящие порой из сотен или даже тысяч элементов. Кластерный анализ позволяет выделить подсети, узкие места, концентраторы и другие скрытые свойства изучаемой системы, что позволяет в конечном счете узнать вклад каждого гена в формирование изучаемого феномена.
В области экологии широко применяется для выделения пространственно однородных групп организмов, сообществ и т. п. Реже методы кластерного анализа применяются для исследования сообществ во времени. Гетерогенность структуры сообществ приводит к возникновению нетривиальных методов кластерного анализа (например, метод Чекановского).
В общем стоит отметить, что исторически сложилось так, что в качестве мер близости в биологии чаще используются меры сходства, а не меры различия (расстояния).
В социологии
При анализе результатов социологических исследований рекомендуется осуществлять анализ методами иерархического агломеративного семейства, а именно методом Уорда, при котором внутри кластеров оптимизируется минимальная дисперсия, в итоге создаются кластеры приблизительно равных размеров. Метод Уорда наиболее удачен для анализа социологических данных. В качестве меры различия лучше квадратичное евклидово расстояние, которое способствует увеличению контрастности кластеров. Главным итогом иерархического кластерного анализа является дендрограмма или «сосульчатая диаграмма». При её интерпретации исследователи сталкиваются с проблемой того же рода, что и толкование результатов факторного анализа — отсутствием однозначных критериев выделения кластеров. В качестве главных рекомендуется использовать два способа — визуальный анализ дендрограммы и сравнение результатов кластеризации, выполненной различными методами.
Визуальный анализ дендрограммы предполагает «обрезание» дерева на оптимальном уровне сходства элементов выборки. «Виноградную ветвь» (терминология Олдендерфера М. С. и Блэшфилда Р. К.[11]) целесообразно «обрезать» на отметке 5 шкалы Rescaled Distance Cluster Combine, таким образом будет достигнут 80 % уровень сходства. Если выделение кластеров по этой метке затруднено (на ней происходит слияние нескольких мелких кластеров в один крупный), то можно выбрать другую метку. Такая методика предлагается Олдендерфером и Блэшфилдом.
Теперь возникает вопрос устойчивости принятого кластерного решения. По сути, проверка устойчивости кластеризации сводится к проверке её достоверности. Здесь существует эмпирическое правило — устойчивая типология сохраняется при изменении методов кластеризации. Результаты иерархического кластерного анализа можно проверять итеративным кластерным анализом по методу k-средних. Если сравниваемые классификации групп респондентов имеют долю совпадений более 70 % (более 2/3 совпадений), то кластерное решение принимается.
Проверить адекватность решения, не прибегая к помощи другого вида анализа, нельзя. По крайней мере, в теоретическом плане эта проблема не решена. В классической работе Олдендерфера и Блэшфилда «Кластерный анализ» подробно рассматриваются и в итоге отвергаются дополнительные пять методов проверки устойчивости:
- кофенетическая корреляция — не рекомендуется и ограниченна в использовании;
- тесты значимости (дисперсионный анализ) — всегда дают значимый результат;
- методика повторных (случайных) выборок, что, тем не менее, не доказывает обоснованность решения;
- тесты значимости для внешних признаков пригодны только для повторных измерений;
- методы Монте-Карло очень сложны и доступны только опытным математикам[источник не указан 96 дней].
В информатике
- Кластеризация результатов поиска — используется для «интеллектуальной» группировки результатов при поиске файлов, веб-сайтов, других объектов, предоставляя пользователю возможность быстрой навигации, выбора заведомо более релевантного подмножества и исключения заведомо менее релевантного — что может повысить юзабилити интерфейса по сравнению с выводом в виде простого сортированного по релевантности списка.
- Clusty[1] — кластеризующая поисковая машина компании Vivísimo
- Nigma — российская поисковая система с автоматической кластеризацией результатов
- Quintura — визуальная кластеризация в виде облака ключевых слов
- Сегментация изображений (англ. image segmentation) — Кластеризация может быть использована для разбиения цифрового изображения на отдельные области с целью обнаружения границ (англ. edge detection) или распознавания объектов.
- Интеллектуальный анализ данных (англ. data mining) — Кластеризация в Data Mining приобретает ценность тогда, когда она выступает одним из этапов анализа данных, построения законченного аналитического решения. Аналитику часто легче выделить группы схожих объектов, изучить их особенности и построить для каждой группы отдельную модель, чем создавать одну общую модель для всех данных. Таким приемом постоянно пользуются в маркетинге, выделяя группы клиентов, покупателей, товаров и разрабатывая для каждой из них отдельную стратегию.
См. также
Примечания
- ↑ Tryon R.C. Cluster analysis. — London: Ann Arbor Edwards Bros, 1939. — 139 p.
- ↑ Айвазян С. А., Бухштабер В. М., Енюков И. С., Мешалкин Л. Д. Прикладная статистика: Классификация и снижение размерности. — М.: Финансы и статистика, 1989. — 607 с.
- ↑ Мандель И. Д. Кластерный анализ. — М.: Финансы и статистика, 1988. — 176 с.
- ↑ Хайдуков Д. С. Применение кластерного анализа в государственном управлении// Философия математики: актуальные проблемы. – М.: МАКС Пресс, 2009. — 287 с.
- ↑ Классификация и кластер. Под ред. Дж. Вэн Райзина. М.: Мир, 1980. 390 с.
- ↑ Орлов А. И. Эконометрика. — М.: Экзамен, 2002. — 576 с.
- ↑ Жамбю М. Иерархический кластер-анализ и соответствия. — М.: Финансы и статистика, 1988. — 345 с.
- ↑ Дюран Б., Оделл П. Кластерный анализ. — М.: Статистика, 1977. — 128 с.
- ↑ Бериков В. С., Лбов Г. С. Современные тенденции в кластерном анализе // Всероссийский конкурсный отбор обзорно-аналитических статей по приоритетному направлению «Информационно-телекоммуникационные системы», 2008. — 26 с.
- ↑ Вятченин Д. А. Нечёткие методы автоматической классификации. — Минск: Технопринт, 2004. — 219 с.
- ↑ Олдендерфер М. С., Блэшфилд Р. К. Кластерный анализ / Факторный, дискриминантный и кластерный анализ: пер. с англ.; Под. ред. И. С. Енюкова. — М.: Финансы и статистика, 1989—215 с.
Ссылки
- На русском языке
- На английском языке
- COMPACT — Comparative Package for Clustering Assessment. A free Matlab package, 2006.
- P. Berkhin, Survey of Clustering Data Mining Techniques, Accrue Software, 2002.
- Jain, Murty and Flynn: Data Clustering: A Review, ACM Comp. Surv., 1999.
- for another presentation of hierarchical, k-means and fuzzy c-means see this introduction to clustering. Also has an explanation on mixture of Gaussians.
- David Dowe, Mixture Modelling page — other clustering and mixture model links.
- a tutorial on clustering [2]
- The on-line textbook: Information Theory, Inference, and Learning Algorithms, by David J.C. MacKay includes chapters on k-means clustering, soft k-means clustering, and derivations including the E-M algorithm and the variational view of the E-M algorithm.
- An overview of non-parametric clustering and computer vision
- «The Self-Organized Gene», tutorial explaining clustering through competitive learning and self-organizing maps.
- kernlab — R package for kernel based machine learning (includes spectral clustering implementation)
- Tutorial — Tutorial with introduction of Clustering Algorithms (k-means, fuzzy-c-means, hierarchical, mixture of gaussians) + some interactive demos (java applets)
- Data Mining Software — Data mining software frequently utilizes clustering techniques.
- Java Competitve Learning Application A suite of Unsupervised Neural Networks for clustering. Written in Java. Complete with all source code.
- Machine Learning Software — Also contains much clustering software.
- Fuzzy Clustering Algorithms and their Application to Medical Image Analysis PhD Thesis, 2001, by AI Shihab.
- Cluster Computing and MapReduce Lecture 4
Кластерный анализ (на примере сегментации потребителей) часть 1 / Habr
Мы знаем, что Земля – это одна из 8 планет, которые вращаются вокруг Солнца. Солнце – это всего лишь звезда среди порядка 200 миллиардов звезд в галактике Млечный Путь. Очень тяжело осознать это число. Зная это, можно сделать предположение о количестве звезд во вселенной – приблизительно 4X10^22. Мы можем видеть около миллиона звезд на небе, хотя это всего лишь малая часть от всего фактического количества звезд. Итак, у нас появилось два вопроса:- Что такое галактика?
- И какая связь между галактиками и темой статьи (кластерный анализ)

Галактика – это скопление звезд, газа, пыли, планет и межзвездных облаков. Обычно галактики напоминают спиральную или эдептическую фигуру. В пространстве галактики отделены друг от друга. Огромные черные дыры чаще всего являются центрами большинства галактик.
Как мы будем обсуждать в следующем разделе, есть много общего между галактиками и кластерным анализом. Галактики существуют в трехмерном пространстве, кластерный анализ – это многомерный анализ, проводимый в n-мерном пространстве.
Заметка: Черная дыра – это центр галактики. Мы будем использовать похожую идею в отношении центроидов для кластерного анализа.
Кластерный анализ
Предположим вы глава отдела по маркетингу и взаимодействию с потребителями в телекоммуникационной компании. Вы понимаете, что все потребители разные, и что вам необходимы различные стратегии для привлечения различных потребителей. Вы оцените мощь такого инструмента как сегментация клиентов для оптимизации затрат. Для того, чтобы освежить ваши знания кластерного анализа, рассмотрим следующий пример, иллюстрирующий 8 потребителей и среднюю продолжительность их разговоров (локальных и международных). Ниже данные:
Для лучшего восприятия нарисуем график, где по оси x будет откладываться средняя продолжительность международных разговоров, а по оси y — средняя продолжительность локальных разговоров. Ниже график:
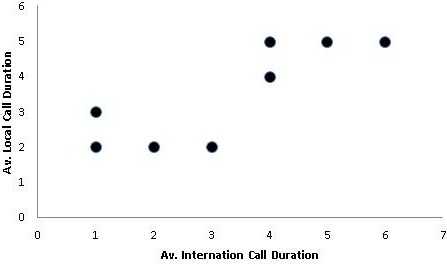
Заметка: Это похоже на анализ расположения звезд на ночном небе (здесь звезды заменены потребителями). В дополнение, вместо трехмерного пространства у нас двумерное, заданное продолжительностью локальных и международных разговоров, в качестве осей x и y.
Сейчас, разговаривая в терминах галактик, задача формулируется так – найти положение черных дыр; в кластерном анализе они называются центроидами. Для обнаружения центроидов мы начнем с того, что возьмем произвольные точки в качестве положения центроидов.
Евклидово расстояние для нахождения Центроидов для Кластеров
В нашем случае два центроида (C1 и C2) мы произвольным образом поместим в точки с координатами (1, 1) и (3, 4). Почему мы выбрали именно эти два центроида? Визуальное отображение точек на графике показывает нам, что есть два кластера, которые мы будем анализировать. Однако, впоследствии мы увидим, что ответ на этот вопрос будет не таким уж простым для большого набора данных.
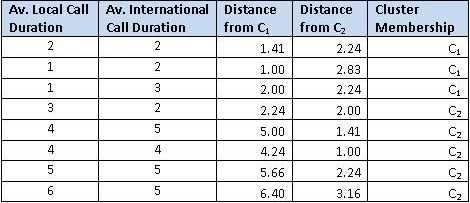
Далее, мы измерим расстояние между центроидами (C1 и C2) и всеми точками на графике использую формулу Евклида для нахождения расстояния между двумя точками.
Примечание: Расстояние может быть вычислено и по другим формулам, например,
- квадрат евклидова расстояния – для придания веса более отдаленным друг от друга объектам
- манхэттенское расстояние – для уменьшения влияния выбросов
- степенное расстояние – для увеличения/уменьшения влияния по конкретным координатам
- процент несогласия – для категориальных данных
- и др.
Колонка 3 и 4 (Distance from C1 and C2) и есть расстояние, вычисленное по этой формуле. Например, для первого потребителя
Принадлежность к центроидам (последняя колонка) вычисляется по принципу близости к центроидам (C1 и C2). Первый потребитель ближе к центроиду №1 (1.41 по сравнению с 2.24) следовательно, принадлежит к кластеру с центроидом C1.
Ниже график, иллюстрирующий центроиды C1 и C2 (изображенные в виде голубого и оранжевого ромбика). Потребители изображены цветом соответствующего центроида, к кластеру которого они были отнесены.
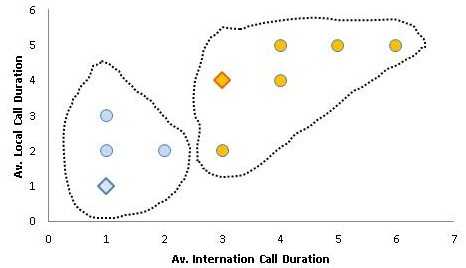
Так как мы произвольным образом выбрали центроиды, вторым шагом мы сделать этот выбор итеративным. Новая позиция центроидов выбирается как средняя для точек соответствующего кластера. Так, например, для первого центроида (это потребители 1, 2 и 3). Следовательно, новая координата x для центроида C1 э то средняя координат x этих потребителей (2+1+1)/3 = 1.33. Мы получим новые координаты для C1 (1.33, 2.33) и C2 (4.4, 4.2).Новый график ниже:
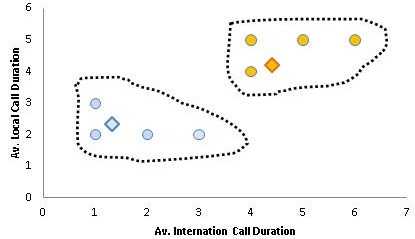
В конце концов, мы поместим центроиды в центр соответствующего кластера. График ниже:
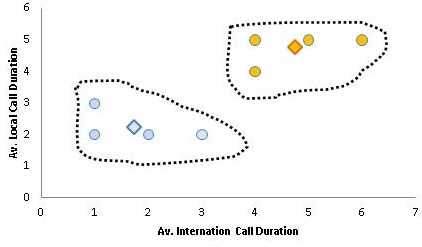
Позиции наших черных дыр (центров кластеров) в нашем примере C1 (1.75, 2.25) и C2(4.75, 4.75). Два кластера выше подобны двум галактикам, разделенным в пространстве друг от друга.
Итак, рассмотрим примеры дальше. Пусть перед нами стоит задача по сегментации потребителей по двум параметрам: возраст и доход. Предположим, что у нас есть 2 потребителя с возрастом 37 и 44 лет и доходом в $90,000 и $62,000 соответственно. Если мы хотим измерить Евклидово расстояние между точками (37, 90000) и (44, 62000), мы увидим, что в данном случае переменная доход «доминирует» над переменной возраст и ее изменение сильно сказывается на расстоянии. Нам необходима какая-нибудь стратегия для решения данной проблемы, иначе наш анализ даст неверный результат. Решение данной проблемы это приведение наших значений к сравнимым шкалам. Нормализация – вот решение нашей проблемы.
Нормализация данных
Существует много подходов для нормализации данных. Например, нормализация минимума-максимума. Для данной нормализации используется следующая формула
в данном случае X* — это нормализованное значение, min и max – минимальная и максимальная координата по всему множеству X
(Примечание, данная формула располагает все координаты на отрезке [0;1])
Рассмотрим наш пример, пусть максимальный доход $130000, а минимальный — $45000. Нормализованное значение дохода для потребителя A равно
Мы сделаем это упражнение для всех точек для каждых переменных (координат). Доход для второго потребителя (62000) станет 0.2 после процедуры нормализации. Дополнительно, пусть минимальный и максимальный возрасты 23 и 58 соответственно. После нормализации возрасты двух наших потребителей составит 0.4 и 0.6.
Легко увидеть, что теперь все наши данные расположены между значениями 0 и 1. Следовательно, у нас теперь есть нормализованные наборы данных в сравнимых шкалах.
Запомните, перед процедурой кластерного анализа необходимо произвести нормализацию.
Статью нашел kuznetsovin
Кластерный анализ
Кластерный анализКластерный анализ
Основная цель
Термин кластерный анализ (впервые ввел Tryon, 1939) в действительности включает в себя набор различных алгоритмов классификации. Общий вопрос, задаваемый исследователями во многих областях, состоит в том, как организовать наблюдаемые данные в наглядные структуры, т.е. развернуть таксономии. Например, биологи ставят цель разбить животных на различные виды, чтобы содержательно описать различия между ними. В соответствии с современной системой, принятой в биологии, человек принадлежит к приматам, млекопитающим, амниотам, позвоночным и животным. Заметьте, что в этой классификации, чем выше уровень агрегации, тем меньше сходства между членами в соответствующем классе. Человек имеет больше сходства с другими приматами (т.е. с обезьянами), чем с "отдаленными" членами семейства млекопитающих (например, собаками) и т.д. В последующих разделах будут рассмотрены общие методы кластерного анализа, см. Объединение (древовидная кластеризация), Двувходовое объединение и Метод K средних.
Проверка статистической значимости
Заметим, что предыдущие рассуждения ссылаются на алгоритмы кластеризации, но ничего не упоминают о проверке статистической значимости. Фактически, кластерный анализ является не столько обычным статистическим методом, сколько "набором" различных алгоритмов "распределения объектов по кластерам". Существует точка зрения, что в отличие от многих других статистических процедур, методы кластерного анализа используются в большинстве случаев тогда, когда вы не имеете каких-либо априорных гипотез относительно классов, но все еще находитесь в описательной стадии исследования. Следует понимать, что кластерный анализ определяет "наиболее возможно значимое решение". Поэтому проверка статистической значимости в действительности здесь неприменима, даже в случаях, когда известны p-уровни (как, например, в методе K средних).
Области применения
Техника кластеризации применяется в самых разнообразных областях. Хартиган (Hartigan, 1975) дал прекрасный обзор многих опубликованных исследований, содержащих результаты, полученные методами кластерного анализа. Например, в области медицины кластеризация заболеваний, лечения заболеваний или симптомов заболеваний приводит к широко используемым таксономиям. В области психиатрии правильная диагностика кластеров симптомов, таких как паранойя, шизофрения и т.д., является решающей для успешной терапии. В археологии с помощью кластерного анализа исследователи пытаются установить таксономии каменных орудий, похоронных объектов и т.д. Известны широкие применения кластерного анализа в маркетинговых исследованиях. В общем, всякий раз, когда необходимо классифицировать "горы" информации к пригодным для дальнейшей обработки группам, кластерный анализ оказывается весьма полезным и эффективным.
Объединение (древовидная кластеризация)
Общая логика
Приведенный в разделе Основная цель пример поясняет цель алгоритма объединения (древовидной кластеризации). Назначение этого алгоритма состоит в объединении объектов (например, животных) в достаточно большие кластеры, используя некоторую меру сходства или расстояние между объектами. Типичным результатом такой кластеризации является иерархическое дерево.
Иерархическое дерево
Рассмотрим горизонтальную древовидную диаграмму. Диаграмма начинается с каждого объекта в классе (в левой части диаграммы). Теперь представим себе, что постепенно (очень малыми шагами) вы "ослабляете" ваш критерий о том, какие объекты являются уникальными, а какие нет. Другими словами, вы понижаете порог, относящийся к решению об объединении двух или более объектов в один кластер.
В результате, вы связываете вместе всё большее и большее число объектов и агрегируете (объединяете) все больше и больше кластеров, состоящих из все сильнее различающихся элементов. Окончательно, на последнем шаге все объекты объединяются вместе. На этих диаграммах горизонтальные оси представляют расстояние объединения (в вертикальных древовидных диаграммах вертикальные оси представляют расстояние объединения). Так, для каждого узла в графе (там, где формируется новый кластер) вы можете видеть величину расстояния, для которого соответствующие элементы связываются в новый единственный кластер. Когда данные имеют ясную "структуру" в терминах кластеров объектов, сходных между собой, тогда эта структура, скорее всего, должна быть отражена в иерархическом дереве различными ветвями. В результате успешного анализа методом объединения появляется возможность обнаружить кластеры (ветви) и интерпретировать их.
Меры расстояния
Объединение или метод древовидной кластеризации используется при формировании кластеров несходства или расстояния между объектами. Эти расстояния могут определяться в одномерном или многомерном пространстве. Например, если вы должны кластеризовать типы еды в кафе, то можете принять во внимание количество содержащихся в ней калорий, цену, субъективную оценку вкуса и т.д. Наиболее прямой путь вычисления расстояний между объектами в многомерном пространстве состоит в вычислении евклидовых расстояний. Если вы имеете двух- или трёхмерное пространство, то эта мера является реальным геометрическим расстоянием между объектами в пространстве (как будто расстояния между объектами измерены рулеткой). Однако алгоритм объединения не "заботится" о том, являются ли "предоставленные" для этого расстояния настоящими или некоторыми другими производными мерами расстояния, что более значимо для исследователя; и задачей исследователей является подобрать правильный метод для специфических применений.
Евклидово расстояние. Это, по-видимому, наиболее общий тип расстояния. Оно попросту является геометрическим расстоянием в многомерном пространстве и вычисляется следующим образом:
расстояние(x,y) = {i (xi - yi)2 }1/2
Заметим, что евклидово расстояние (и его квадрат) вычисляется по исходным, а не по стандартизованным данным. Это обычный способ его вычисления, который имеет определенные преимущества (например, расстояние между двумя объектами не изменяется при введении в анализ нового объекта, который может оказаться выбросом). Тем не менее, на расстояния могут сильно влиять различия между осями, по координатам которых вычисляются эти расстояния. К примеру, если одна из осей измерена в сантиметрах, а вы потом переведете ее в миллиметры (умножая значения на 10), то окончательное евклидово расстояние (или квадрат евклидова расстояния), вычисляемое по координатам, сильно изменится, и, как следствие, результаты кластерного анализа могут сильно отличаться от предыдущих.
Квадрат евклидова расстояния. Иногда может возникнуть желание возвести в квадрат стандартное евклидово расстояние, чтобы придать большие веса более отдаленным друг от друга объектам. Это расстояние вычисляется следующим образом (см. также замечания в предыдущем пункте):
расстояние(x,y) = i (xi - yi)2
Расстояние городских кварталов (манхэттенское расстояние). Это расстояние является просто средним разностей по координатам. В большинстве случаев эта мера расстояния приводит к таким же результатам, как и для обычного расстояния Евклида. Однако отметим, что для этой меры влияние отдельных больших разностей (выбросов) уменьшается (так как они не возводятся в квадрат). Манхэттенское расстояние вычисляется по формуле:
расстояние(x,y) = i |xi - yi|
Расстояние Чебышева. Это расстояние может оказаться полезным, когда желают определить два объекта как "различные", если они различаются по какой-либо одной координате (каким-либо одним измерением). Расстояние Чебышева вычисляется по формуле:
расстояние(x,y) = Максимум|xi - yi|
Степенное расстояние. Иногда желают прогрессивно увеличить или уменьшить вес, относящийся к размерности, для которой соответствующие объекты сильно отличаются. Это может быть достигнуто с использованием степенного расстояния. Степенное расстояние вычисляется по формуле:
расстояние(x,y) = (i |xi - yi|p)1/r
где r и p - параметры, определяемые пользователем. Несколько примеров вычислений могут показать, как "работает" эта мера. Параметр p ответственен за постепенное взвешивание разностей по отдельным координатам, параметр r ответственен за прогрессивное взвешивание больших расстояний между объектами. Если оба параметра - r и p, равны двум, то это расстояние совпадает с расстоянием Евклида.
Процент несогласия. Эта мера используется в тех случаях, когда данные являются категориальными. Это расстояние вычисляется по формуле:
расстояние(x,y) = (Количество xi yi)/ i
Правила объединения или связи
На первом шаге, когда каждый объект представляет собой отдельный кластер, расстояния между этими объектами определяются выбранной мерой. Однако когда связываются вместе несколько объектов, возникает вопрос, как следует определить расстояния между кластерами? Другими словами, необходимо правило объединения или связи для двух кластеров. Здесь имеются различные возможности: например, вы можете связать два кластера вместе, когда любые два объекта в двух кластерах ближе друг к другу, чем соответствующее расстояние связи. Другими словами, вы используете "правило ближайшего соседа" для определения расстояния между кластерами; этот метод называется методом одиночной связи. Это правило строит "волокнистые" кластеры, т.е. кластеры, "сцепленные вместе" только отдельными элементами, случайно оказавшимися ближе остальных друг к другу. Как альтернативу вы можете использовать соседей в кластерах, которые находятся дальше всех остальных пар объектов друг от друга. Этот метод называется метод полной связи. Существует также множество других методов объединения кластеров, подобных тем, что были рассмотрены.
Одиночная связь (метод ближайшего соседа). Как было описано выше, в этом методе расстояние между двумя кластерами определяется расстоянием между двумя наиболее близкими объектами (ближайшими соседями) в различных кластерах. Это правило должно, в известном смысле, нанизывать объекты вместе для формирования кластеров, и результирующие кластеры имеют тенденцию быть представленными длинными "цепочками".
Полная связь (метод наиболее удаленных соседей). В этом методе расстояния между кластерами определяются наибольшим расстоянием между любыми двумя объектами в различных кластерах (т.е. "наиболее удаленными соседями"). Этот метод обычно работает очень хорошо, когда объекты происходят на самом деле из реально различных "рощ". Если же кластеры имеют в некотором роде удлиненную форму или их естественный тип является "цепочечным", то этот метод непригоден.
Невзвешенное попарное среднее. В этом методе расстояние между двумя различными кластерами вычисляется как среднее расстояние между всеми парами объектов в них. Метод эффективен, когда объекты в действительности формируют различные "рощи", однако он работает одинаково хорошо и в случаях протяженных ("цепочного" типа) кластеров. Отметим, что в своей книге Снит и Сокэл (Sneath, Sokal, 1973) вводят аббревиатуру UPGMA для ссылки на этот метод, как на метод невзвешенного попарного арифметического среднего - unweighted pair-group method using arithmetic averages.
Взвешенное попарное среднее. Метод идентичен методу невзвешенного попарного среднего, за исключением того, что при вычислениях размер соответствующих кластеров (т.е. число объектов, содержащихся в них) используется в качестве весового коэффициента. Поэтому предлагаемый метод должен быть использован (скорее даже, чем предыдущий), когда предполагаются неравные размеры кластеров. В книге Снита и Сокэла (Sneath, Sokal, 1973) вводится аббревиатура WPGMA для ссылки на этот метод, как на метод взвешенного попарного арифметического среднего - weighted pair-group method using arithmetic averages.
Невзвешенный центроидный метод. В этом методе расстояние между двумя кластерами определяется как расстояние между их центрами тяжести. Снит и Сокэл (Sneath and Sokal (1973)) используют аббревиатуру UPGMC для ссылки на этот метод, как на метод невзвешенного попарного центроидного усреднения - unweighted pair-group method using the centroid average.
Взвешенный центроидный метод (медиана). тот метод идентичен предыдущему, за исключением того, что при вычислениях используются веса для учёта разницы между размерами кластеров (т.е. числами объектов в них). Поэтому, если имеются (или подозреваются) значительные отличия в размерах кластеров, этот метод оказывается предпочтительнее предыдущего. Снит и Сокэл (Sneath, Sokal 1973) использовали аббревиатуру WPGMC для ссылок на него, как на метод невзвешенного попарного центроидного усреднения - weighted pair-group method using the centroid average.
Метод Варда. Этот метод отличается от всех других методов, поскольку он использует методы дисперсионного анализа для оценки расстояний между кластерами. Метод минимизирует сумму квадратов (SS) для любых двух (гипотетических) кластеров, которые могут быть сформированы на каждом шаге. Подробности можно найти в работе Варда (Ward, 1963). В целом метод представляется очень эффективным, однако он стремится создавать кластеры малого размера.
Для обзора других методов кластеризации, см. Двухвходовое объединение и Метод K средних.
Двувходовое объединение
Вводный обзор
Ранее этот метод обсуждался в терминах "объектов", которые должны быть кластеризованы (см. Объединение (древовидная кластеризация)). Во всех других видах анализа интересующий исследователя вопрос обычно выражается в терминах наблюдений или переменных. Оказывается, что кластеризация, как по наблюдениям, так и по переменным может привести к достаточно интересным результатам. Например, представьте, что медицинский исследователь собирает данные о различных характеристиках (переменные) состояний пациентов (наблюдений), страдающих сердечными заболеваниями. Исследователь может захотеть кластеризовать наблюдения (пациентов) для определения кластеров пациентов со сходными симптомами. В то же самое время исследователь может захотеть кластеризовать переменные для определения кластеров переменных, которые связаны со сходным физическим состоянием.
Двувходовое объединение
После этого обсуждения, относящегося к тому, кластеризовать наблюдения или переменные, можно задать вопрос, а почему бы не проводить кластеризацию в обоих направлениях? Модуль Кластерный анализ содержит эффективную двувходовую процедуру объединения, позволяющую сделать именно это. Однако двувходовое объединение используется (относительно редко) в обстоятельствах, когда ожидается, что и наблюдения и переменные одновременно вносят вклад в обнаружение осмысленных кластеров.
Так, возвращаясь к предыдущему примеру, можно предположить, что медицинскому исследователю требуется выделить кластеры пациентов, сходных по отношению к определенным кластерам характеристик физического состояния. Трудность с интерпретацией полученных результатов возникает вследствие того, что сходства между различными кластерами могут происходить из (или быть причиной) некоторого различия подмножеств переменных. Поэтому получающиеся кластеры являются по своей природе неоднородными. Возможно это кажется вначале немного туманным; в самом деле, в сравнении с другими описанными методами кластерного анализа (см. Объединение (древовидная кластеризация) и Метод K средних), двувходовое объединение является, вероятно, наименее часто используемым методом. Однако некоторые исследователи полагают, что он предлагает мощное средство разведочного анализа данных (за более подробной информацией вы можете обратиться к описанию этого метода у Хартигана (Hartigan, 1975)).
Метод K средних
Общая логика
Этот метод кластеризации существенно отличается от таких агломеративных методов, как Объединение (древовидная кластеризация) и Двувходовое объединение. Предположим, вы уже имеете гипотезы относительно числа кластеров (по наблюдениям или по переменным). Вы можете указать системе образовать ровно три кластера так, чтобы они были настолько различны, насколько это возможно. Это именно тот тип задач, которые решает алгоритм метода K средних. В общем случае метод K средних строит ровно K различных кластеров, расположенных на возможно больших расстояниях друг от друга.
Пример
В примере с физическим состоянием (см. Двувходовое объединение), медицинский исследователь может иметь "подозрение" из своего клинического опыта, что его пациенты в основном попадают в три различные категории. Далее он может захотеть узнать, может ли его интуиция быть подтверждена численно, то есть, в самом ли деле кластерный анализ K средних даст три кластера пациентов, как ожидалось? Если это так, то средние различных мер физических параметров для каждого кластера будут давать количественный способ представления гипотез исследователя (например, пациенты в кластере 1 имеют высокий параметр 1, меньший параметр 2 и т.д.).
Вычисления
С вычислительной точки зрения вы можете рассматривать этот метод, как дисперсионный анализ (см. Дисперсионный анализ) "наоборот". Программа начинает с K случайно выбранных кластеров, а затем изменяет принадлежность объектов к ним, чтобы: (1) - минимизировать изменчивость внутри кластеров, и (2) - максимизировать изменчивость между кластерами. Данный способ аналогичен методу "дисперсионный анализ (ANOVA) наоборот" в том смысле, что критерий значимости в дисперсионном анализе сравнивает межгрупповую изменчивость с внутригрупповой при проверке гипотезы о том, что средние в группах отличаются друг от друга. В кластеризации методом K средних программа перемещает объекты (т.е. наблюдения) из одних групп (кластеров) в другие для того, чтобы получить наиболее значимый результат при проведении дисперсионного анализа (ANOVA).
Интерпретация результатов
Обычно, когда результаты кластерного анализа методом K средних получены, можно рассчитать средние для каждого кластера по каждому измерению, чтобы оценить, насколько кластеры различаются друг от друга. В идеале вы должны получить сильно различающиеся средние для большинства, если не для всех измерений, используемых в анализе. Значения F-статистики, полученные для каждого измерения, являются другим индикатором того, насколько хорошо соответствующее измерение дискриминирует кластеры.
Все права на материалы электронного учебника принадлежат компании StatSoft
Обзор алгоритмов кластеризации числовых пространств данных / Habr
Задача кластеризации – частный случай задачи обучения без учителя, которая сводится к разбиению имеющегося множества объектов данных на подмножества таким образом, что элементы одного подмножества существенно отличались по некоторому набору свойств от элементов всех других подмножеств. Объект данных обычно рассматривается как точка в многомерном метрическом пространстве, каждому измерению которого соответствует некоторое свойство (атрибут) объекта, а метрика – есть функция от значений данных свойств. От типов измерений этого пространства, которые могут быть как числовыми, так и категориальными, зависит выбор алгоритма кластеризации данных и используемая метрика. Этот выбор продиктован различиями в природе разных типов атрибутов.В этой статье приведён краткий обзор методов кластеризации числовых пространств данных. Она будет полезна тем, кто только начинает изучать Data Mining и кластерный анализ и поможет сориентироваться в многообразии современных алгоритмов кластеризации и получить о них общее представление. Статья не претендует на полноту изложения материала, напротив, описание алгоритмов в ней максимально упрощено. Для более подробного изучения того или иного алгоритма рекомендуется использовать научную работу, в которой он был представлен (см. список литературы в конце статьи).
Методы разбиения
Наиболее известные представители этого семейства методов – алгоритмы k-means[1] и k-medoids[2]. Они принимают входной параметр k и разбивают пространство данных на k кластеров таких, что между объектами одного кластера сходство максимально, а между объектами разных кластеров минимально. Сходство измеряется по отношению к некоторому центру кластера как дистанция от рассматриваемого объекта до центра. Основное различие между этими методами заключается в способе определения центра кластера.
В алгоритме k-means сходство рассматривается по отношению к центру масс кластера – среднему значению координат объектов кластера в пространстве данных. Сначала произвольно выбираются k объектов, каждый из которых является прототипом кластера и представляет его центр масс. Затем для каждого из оставшихся объектов выполняется присоединение к тому кластеру, с которым сходство больше. После этого центр масс каждого кластера вычисляется заново. Для каждого полученного разбиения рассчитывается некоторая оценочная функция, значения которой на каждом шаге образуют сходящейся ряд. Процесс продолжается до тех пор, пока указанный ряд не сойдётся к своему предельному значению. Иными словами, перемещение объектов из кластера в кластер заканчивается тогда, когда с каждой итерацией кластеры будут оставаться неизменными. Минимизация оценочной функции позволяет сделать результирующие кластеры настолько компактными и раздельными, насколько это возможно. Метод k-means хорошо работает, когда кластеры представляют собой значительно разделённые между собой компактные «облака». Он эффективен для обработки больших объёмов данных, однако не применим для обнаружения кластеров невыпуклой формы или сильно различающегося размера. Более того, метод очень чувствителен к шуму и обособленным точкам пространства, поскольку даже малое количество таких точек может существенно влиять на вычисление центра масс кластера.
Чтобы сократить влияние шума и обособленных точек пространства на результат кластеризации, алгоритм k-medoids, в отличие от k-means, использует для представления центра кластера не центр масс, а представительный объект – один из объектов кластера. Как и в методе k-means, сначала произвольным образом выбирается k представительных объектов. Каждый из оставшихся объектов объединяется в кластер с ближайшим представительным объектом. Затем итеративно для каждого представительного объекта производится его замена произвольным непредставительным объектом пространства данных. Процесс замены продолжается до тех пор, пока улучшается качество результирующих кластеров. Качество кластеризации определяется суммой отклонений между каждым объектом и представительным объектом соответствующего кластера, которую метод стремится минимизировать.То есть, итерации продолжаются до тех пор, пока в каждом кластере его представительный объект не станет медоидом – наиболее близким к центру кластера объектом. Алгоритм плохо масштабируем для обработки больших объёмов данных, но эту проблему решает дополняющий метод k-medoids алгоритм CLARANS [3]. Для кластеризации многомерных пространств на основе CLARANS построен алгоритм PROCLUS [4].
Иерархические методы
Общая идея методов данной группы заключается в последовательной иерархической декомпозиции множества объектов. В зависимости от направления построения иерархии различают дивизимный и агломеративный методы. В случае агломеративного метода (снизу вверх) процесс декомпозиции начитается с того, что каждый объект представляет собой самостоятельный кластер. Затем на каждой итерации пары близлежащих кластеров последовательно объединяются в общий кластер. Итерации продолжаются до тех пор, пока все объекты не будут объединены в один кластер или пока не выполнится некоторое условие остановки. Дивизимный метод (сверху вниз) напротив, подразумевает, что на начальном этапе все объекты объединены в единый кластер. На каждой итерации он разделяется на более мелкие до тех пор, пока каждый объект не окажется в отдельном кластере или не будет выполнено условие остановки. В качестве условия остановки можно использовать пороговое число кластеров, которое необходимо получить, однако обычно используется пороговое значение расстояния между кластерами.
Основная проблема иерархических методов заключается в сложности определения условия остановки таким образом, чтобы выделить «естественные» кластеры и в то же время не допустить их разбиения. Еще одна проблема иерархических методов кластеризации заключается в выборе точки разделения или слияния кластеров. Этот выбор критичен, поскольку после разделения или слияния кластеров на каждом последующем шаге метод будет оперировать только вновь образованными кластерами, поэтому неверный выбор точки слияния или разделения на каком-либо шаге может привести к некачественной кластеризации. Кроме того, иерархические методы не могут быть применены к большим наборам данных, потому как решение о разделении или слиянии кластеров требует анализа большого количества объектов и кластеров, что ведёт к большой вычислительной сложности метода. Примерами алгоритмов, основанных на иерархическом методе являются BIRCH[5] и CHAMELEON[6].
Плотностные методы
Кластеры рассматриваются как регионы пространства данных с высокой плотностью объектов, которые разделены регионами с низкой плотностью объектов.
Алгоритм DBSCAN [7] – один из первых алгоритмов кластеризации плотностным методом. В основе этого алгоритма лежит несколько определений:
- ε-окрестностью объекта называется окрестность радиуса ε некоторого объекта.
- Корневым объектом называется объект, ε-окрестность которого содержит не менее некоторого минимального числа MinPts объектов.
- Объект p непосредственно плотно-достижим из объекта q если p находится в ε-окрестности q и q является корневым объектом.
- Объект p плотно-достижим из объекта q при заданных ε и MinPts, если существует последовательность объектов p1, …, pn, где p1 = q и pn = p, такая что pi+1 непосредственно плотно достижим из pi, 1 ≤ i ≤ n.
- Объект p плотно-соединён с объектом q при заданных ε и MinPts, если существует объект o такой, что p и q плотно-достижимы из o.
Для поиска кластеров алгоритм DBSCAN проверяет ε-окрестность каждого объекта. Если ε-окрестность объекта p содержит больше точек чем MinPts, то создаётся новый кластер с корневым объектом p. Затем DBSCAN итеративно собирает объекты непосредственно плотно-достижимые из корневых объектов, которые могут привести к объединению нескольких плотно-достижимых кластеров. Процесс завершается, когда ни к одному кластеру не может быть добавлено ни одного нового объекта.
Хотя, в отличие от методов разбиения, DBSCAN не требует заранее указывать число получаемых кластеров, требуется указание значений параметров ε и MinPts, которые непосредственно влияют на результат кластеризации. Оптимальные значения этих параметров сложно определить, особенно для многомерных пространств данных. Кроме того, распределение данных в таких пространствах часто несимметрично, что не позволяет использовать для их кластеризации глобальные параметры плотности. Для кластеризации многомерных пространств данных на базе DBSCAN был создан алгоритм SUBCLU [8].
Сетевые методы
Общая идея методов заключается в том, что пространство объектов разбивается на конечное число ячеек, образующих сетевую структуру, в рамках которой выполняются все операции кластеризации. Главное достоинство методов этой группы в малом времени выполнения, которое обычно не зависит от количества объектов данных, а зависит только от количества ячеек в каждом измерении пространства.
Алгоритм CLIQUE [9], адаптированный под кластеризацию данных высокой размерности, является одним из классических сетевых алгоритмов. Метод основан на том предположении, что если в многомерном пространстве данных распределение объектов не равномерно – встречаются регионы плотности и разрежения, то проекция региона плотности в подпространство с меньшей размерностью будет частью региона плотности в этом подпространстве. Алгоритм CLIQUE производит кластеризацию многомерного пространства данных следующим образом: пространство данных разбивается на не пересекающиеся ячейки фиксированного размера, среди них идентифицируются плотные ячейки – такие, плотность объектов данных в которых превышает заданное пороговое значение. Далее из найденных ячеек формируется пространство, в котором могут существовать плотные ячейки большей размерности. Процесс начинается с одномерных пространств (описанная процедура выполняется для каждого измерения) с последующим переходом к подпространствам более высокой размерности.
Этот алгоритм масштабируем для обработки большого количества данных, однако при большом количестве измерений число рассматриваемых комбинаций растёт нелинейно, следовательно, требуется использовать эвристики для сокращения количества рассматриваемых комбинаций. Кроме того, получаемый результат очень сильно зависит от выбора размера ячейки и порогового значения плотности объектов в ячейке. Это является большой проблемой, поскольку одни и те же значения этих параметров используются при рассмотрении всех комбинаций измерений. Эту проблему решает алгоритм MAFIA [10], работающий по схожему принципу, но использующий адаптивный размер ячеек при разбиении подпространств.
Модельные методы
Методы этого семейства предполагают, что имеется некоторая математическая модель кластера в пространстве данных и стремятся максимизировать сходство этой модели и имеющихся данных. Часто при этом используется аппарат математической статистики.
Алгоритм EM [11] основан на предположении, что исследуемое множество данных может быть смоделировано с помощью линейной комбинации многомерных нормальных распределений. Его целью является оценка параметров распределения, которые максимизируют функцию правдоподобия, используемую в качестве меры качества модели. Иными словами, предполагается, что данные в каждом кластере подчиняются определенному закону распределения, а именно, нормальному распределению. С учетом этого предположения можно определить оптимальные параметры закона распределения – математическое ожидание и дисперсию, при которых функция правдоподобия максимальна. Таким образом, мы предполагаем, что любой объект принадлежит ко всем кластерам, но с разной вероятностью. Тогда задача будет заключаться в «подгонке» совокупности распределений к данным, а затем в определении вероятностей принадлежности объекта к каждому кластеру. Очевидно, что объект должен быть отнесен к тому кластеру, для которого данная вероятность выше.
Алгоритм EM прост и лёгок в реализации, не чувствителен к изолированным объектам и быстро сходится при удачной инициализации. Однако он требует для инициализации указания количества кластеров k, что подразумевает наличие априорных знаний о данных. Кроме того, при неудачной инициализации сходимость алгоритма может оказаться медленной или может быть получен некачественный результат.
Очевидно, что подобные алгоритмы не применимы к пространствам с высокой размерностью, поскольку в этом случае крайне сложно предположить математическую модель распределения данных в этом пространстве.
Концептуальная кластеризация
В отличие от традиционной кластеризации, которая обнаруживает группы схожих объектов на основе меры сходства между ними, концептуальная кластеризация определяет кластеры как группы объектов, относящейся к одному классу или концепту – определённому набору пар атрибут-значение.
Алгоритм COBWEB [12] – классический метод инкрементальной концептуальной кластеризации. Он создаёт иерархическую кластеризацию в виде дерева классификации: каждый узел этого дерева ссылается на концепт и содержит вероятностное описание этого концепта, которое включает в себя вероятность принадлежности концепта к данному узлу и условные вероятности вида: P(Ai = vij|Ck), где Ai = vij – пара атрибут-значение, Ck – класс концепта.
Узлы, находящейся на определённом уровне дерева классификации, называют срезом. Алгоритм использует для построения дерева классификации эвристическую меру оценки, называемую полезностью категории – прирост ожидаемого числа корректных предположений о значениях атрибутов при знании об их принадлежности к определённой категории относительно ожидаемого числа корректных предположений о значениях атрибутов без этого знания. Чтобы встроить новый объект в дерево классификации, алгоритм COBWEB итеративно проходит всё дерево в поисках «лучшего» узла, к которому отнести этот объект. Выбор узла осуществляется на основе помещения объекта в каждый узел и вычисления полезности категории получившегося среза. Также вычисляется полезность категории для случая, когда объект относится к вновь создаваемому узлу. В итоге объект относится к тому узлу, для которого полезность категории больше.
Однако COBWEB имеет ряд ограничений. Во-первых, он предполагает, что распределения вероятностей значений различных атрибутов статистически независимы друг от друга. Однако это предположение не всегда верно, потому как часто между значениями атрибутов существует корреляция. Во-вторых, вероятностное представление кластеров делает очень сложным их обновление, особенно в том случае, когда атрибуты имеют большое число возможных значений. Это вызвано тем, что сложность алгоритма зависит не только от количества атрибутов, но и от количества их возможных значений.
Список литературы
- MacQueen, J. Some methods for classification and analysis of multivariate observations/ J. MacQueen // In Proc. 5th Berkeley Symp. Оn Math. Statistics and Probability, 1967. -С.281-297.
- Kaufman, L. Clustering by means of Medoids, in Statistical Data Analysis Based on the l–Norm and Related Methods / L. Kaufman, P.J. Rousseeuw, Y. Dodge, 1987. -С.405-416.
- Ng, R.T. Efficient and Effective Clustering Methods for Spatial Data Mining / R.T. Ng, J. Han // Proc. 20th Int. Conf. on Very Large Data Bases. Morgan Kaufmann Publishers, San Francisco, CA, 1994. -С.144-155.
- Aggarwal, C.C. Fast Algorithms for Projected Clustering / C.C. Aggarwal, C. Procopiuc // In Proc. ACM SIGMOD Int. Conf. on Management of Data, Philadelphia, PA, 1999. 12 с.
- Zhang, T. BIRCH: An Efficient Data Clustering Method for Very Large Databases / T. Zhang, R. Ramakrishnan, M. Linvy // In Proc. ACM SIGMOD Int. Conf. on Management of Data. ACM Press, New York, 1996. -С.103-114.
- Karypis, G. CHAMELEON: A Hierarchical Clustering Algorithm Using Dynamic Modeling / G. Karypis, E.-H. Han, V. Kumar // Journal Computer Volume 32 Issue 8. IEEE Computer Society Press Los Alamitos, CA, 1999. -С.68-75
- Ester, M. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise / M. Ester, H.-P. Kriegel, J. Sander, X. Xu // In Proc. ACM SIGMOD Int. Conf. on Management of Data, Portland, OR, 1996. –С. 226-231.
- Kailing, K. Density-Connected Subspace Clustering for High-Dimensional Data / K. Kailing, H.-P. Kriegel, P. Kröger // In Proceedings of the 4th SIAM International Conference on Data Mining (SDM), 2004. -С.246-257.
- Agrawal, R. Automatic Subspace Clustering of High Dimensional Data for Data Mining Applications / R. Agrawal, J. Gehrke, D. Gunopulos, P. Raghavan // In Proc. ACM SIGMOD Int. Conf. on Management of Data, Seattle, Washington, 1998. -С.94-105.
- Nagesh, H. MAFIA: Efficient and Scalable Subspace Clustering for Very Large Data Sets / H. Nagesh, S. Goil, A. Choudhary // Technical Report Number CPDC-TR-9906-019, Center for Parallel and Distributed Computing, Northwestern University, 1999. 20 с.
- Demster, A. Maximum Likelihood from Incomplete Data via the EM Algorithm /A.P. Demster, N.M. Laird, D.B. Rubin //JOURNAL OF THE ROYAL STATISTICAL SOCIETY, SERIES B, Vol. 39, No. 1, 1977. -С.1-38.
- Fisher, D.H. Knowledge acquisition via incremental conceptual clustering / D.H. Fisher // Machine Learning 2, 1987. -С.139-172.
Что такое кластерный анализ? | Основы торговли по кластерам
Кластер – это цена актива в определенный промежуток времени, на котором совершались сделки. Результирующий объём покупок и продаж указан цифрой внутри кластера. Бар любого ТФ вмещает в себя ,как правило, несколько кластеров. Это позволяет детально видеть объемы покупок, продаж и их баланс в каждом отдельном баре, по каждому ценовому уровню.
Рис. 1 Построение кластерного графика
Изменение цены одного актива, неизбежно влечёт за собой цепочку ценовых движений и на других инструментах. В большинстве случаев понимание трендового движения происходит уже в тот момент, когда оно бурно развивается, и вход в рынок по тренду чреват попаданием в коррекционную волну. Для успешных сделок необходимо понимать текущую ситуацию и уметь предвидеть будущие ценовые движения. Этому можно научиться, анализируя график кластеров.
С помощью кластерного анализа можно видеть активность участников рынка внутри даже самого маленького ценового бара. Это наиболее точный и детальный анализ, так как показывает точечное распределение объёмов сделок по каждому ценовому уровню актива.
Особенности кластерного анализа
На рынке постоянно идёт противоборство интересов продавцов и покупателей. И каждое самое маленькое движение цены (тик), является тем ходом к компромиссу – ценовому уровню – который в данный момент устраивает обе стороны.
Но рынок динамичен, количество продавцов и покупателей непрерывно изменяется. Если в один момент времени на рынке доминировали продавцы, то в следующий момент, вероятнее всего, будут покупатели. Не одинаковым оказывается и количество совершённых сделок на соседних ценовых уровнях. И всё же сначала рыночная ситуация отражается на суммарных объёмах сделок, а уж затем на цене.
Если видеть действия доминирующих участников рынка (продавцов или покупателей), то можно предсказывать и само движение цены.
Для успешного применения кластерного анализа прежде всего следует понять, что такое кластер и дельта. Кластером называют ценовое движение, которое разбито на уровни, на которых совершались сделки с известными объёмами. Дельта показывает разницу между покупками и продажами, происходящими в каждом кластере.
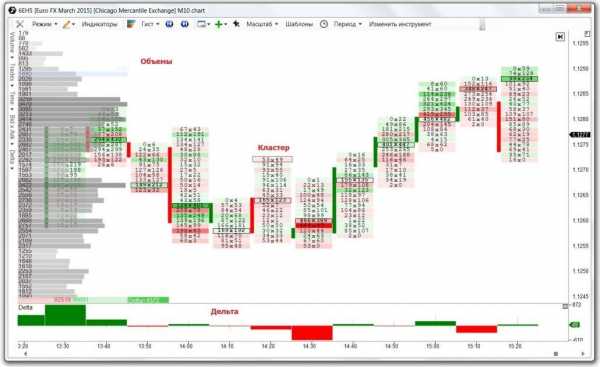
Рис. 2 Кластерный график
Каждый кластер, или группа дельт, позволяет разобраться в том, покупатели или продавцы преобладают на рынке в данный момент времени. Достаточно лишь подсчитать общую дельту, просуммировав продажи и покупки. Если дельта отрицательна, то рынок перепродан, на нём избыточными являются сделки на продажу. Когда же дельта положительна, то на рынке явно доминируют покупатели.
Сама дельта может принимать нормальное или критическое значение. Значение объёма дельты сверх нормального в кластере выделяют красным цветом.
Если дельта умеренна, то это характеризует флетовое состояние на рынке. При нормальном значении дельты на рынке наблюдается трендовое движение, а вот критическое значение всегда является предвестником разворота цены.
Торговля с помощью кластерного анализа
Для получения максимальной прибыли нужно уметь определить переход дельты из умеренного уровня в нормальный. Ведь в этом случае можно заметить само начало перехода от флета к трендовому движению и суметь получить наибольшую прибыль.
Более наглядным является кластерный график на нём можно увидеть значимые уровни накопления и распределения объемов, построить уровни поддержки и сопротивления. Это позволяет трейдеру найти точный вход в сделку.
Используя дельту, можно судить о преобладании на рынке продаж или покупок. Кластерный анализ позволяет наблюдать сделки и отслеживать их объёмы внутри бара любого ТФ. Особо это важно при подходе к значимым уровням поддержки или сопротивления. Суждения по кластерам – ключ к пониманию рынка.
Видео о настройке и торговле в ATAS по кластерам (футпринт).
Кластерный анализ в трейдинге
Кластерный анализ в трейдинге
Время прочтения: 10 минут
Роберт Чоут Трион, американский поведенческий психолог, является основоположником кластерного анализа. Впервые его применил в 1939 году. С его помощью он анализировал и классифицировал данные в психологии личности.
Кластеризация или кластерный анализ собирает кластеры (группы) по схожим элементам. Применяется в математике, маркетинге, медицине, психологии и трейдинге.
Применение кластерного анализа в маркетинге.
Что такое кластерный анализ в трейдинге?
Кластерный анализ (Cluster analysis) — это анализ статистических данных по торговым операциям, основанный на объеме, дельте и открытом интересе.
Пример кластерного графика.
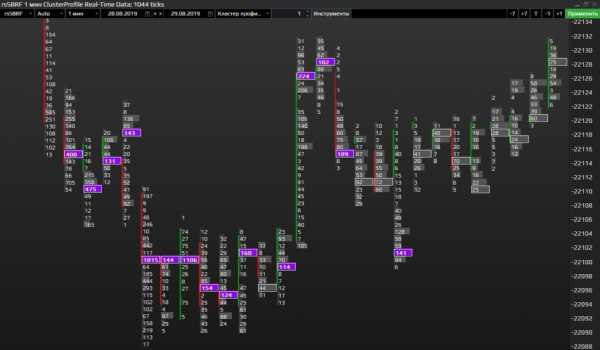
Проще говоря, кластерный анализ рынка показывает нам количество сделок (покупок и продаж) и их объемы, в каждом конкретном промежутке времени (тайм-фрейме). Благодаря чему, мы можем прогнозировать дальнейшее движение цены, исходя из количества спроса и предложения на конкретный актив в конкретный промежуток времени.
То есть, мы видим прямо на графике цены сколько сейчас контрактов на покупку и продажу, можем посмотреть дельту (разницу между объемом на покупку и на продажу) и увидеть начало формирования движения цен.
Механика формирования цены
Любая цена какого-либо актива или продукта формируется от спроса и предложения. Также происходит и на финансовых рынках. Чем больше желающих купить какой-либо актив, тем выше его стоимость и наоборот, чем больше желающих продать, тем дешевле.
Графический анализ дает нам представление только о том, что уже произошло, но дает нам понимание почему это произошло. Кластерный анализ позволяет взглянуть внутрь свечи и понять механику формирования цены на нужном нам таймфрейме.
Стаканы цен акции Сбербанка и фьючерса Сбербанк
То есть, мы видим стакан цен внутри свечи прямо графике.
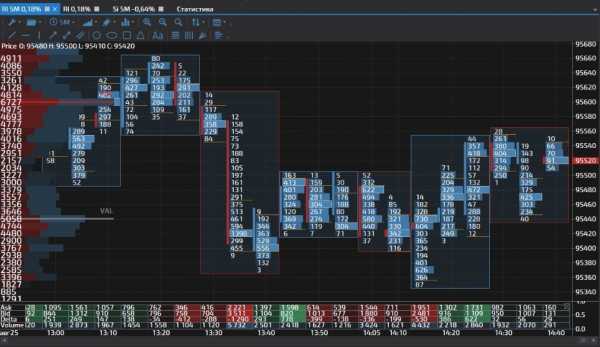
Что такое дельта?
Дельта — это разница Bid Ask/ спрос-предложение/ покупки-продажи какого-то актива в конкретный промежуток времени (таймфрейм).
Когда дельта положительная, в этот промежуток времени (в этой свече) преобладают покупки, когда отрицательная преобладают продажи, превосходят именно на ту величину, которая и указана в данном кластере.
Если же дельта отрицательная и объемы достаточно большие, а на рынке доминируют продажи, то и цена будет снижаться.
Delta.
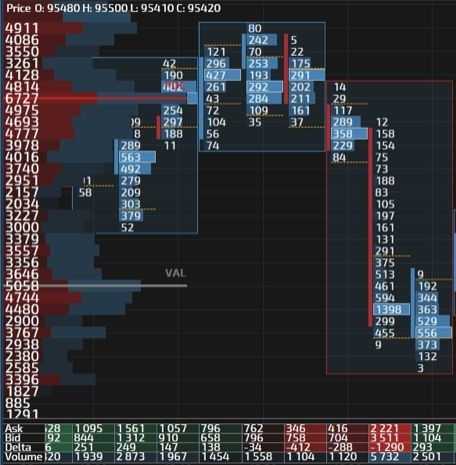
Что такое профиль кластера?
Профиль кластера — это объем сделок по каждой цене в рамках одного дня (для среднесрочной торговли) или в рамках определенного таймфрейма.
Дает возможность точно увидеть по какой именно цене (внутри конкретного бара/свечи) зашел самый большой объем и использовать эти цены, как уровни поддержки и сопротивления.
Профиль кластера.
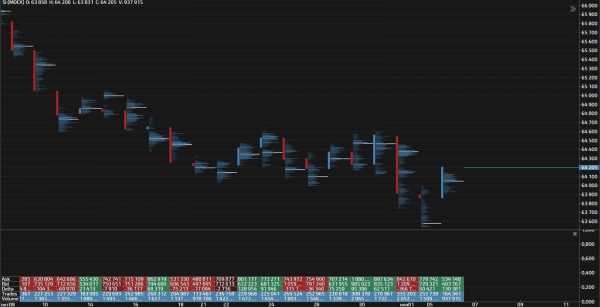
Логика кластерного анализа
Кластерный анализ основывается на точном изучении всех объемов на рынке в конкретный период времени.
Для чего применяется:
-
Для поиска уровней, куда заходили наибольшие объемы, от таких уровней цена с большой долей вероятности будет отскакивать.
В данном случае более правильно применять маркет-профиль, так узнаем точные цены.
-
Можно использовать именно для изучения преобладания на рынке (кого больше, продавцов или покупателей) и делать из этого выводы, куда пойдет цена.
В данном случае правильнее применять дельту.
Также необходимо всегда помнить, что рыночный ордер (сделка с текущих цен) всегда толкает рынок (котировки), а отложенный ордер (лимитные ордера) останавливают цену.
Крупные/умные деньги заходят в рынок по отложенным ордерам, и там где будет наибольший объем, там движение рынка будет останавливаться или разворачиваться (или просто отскакивать).
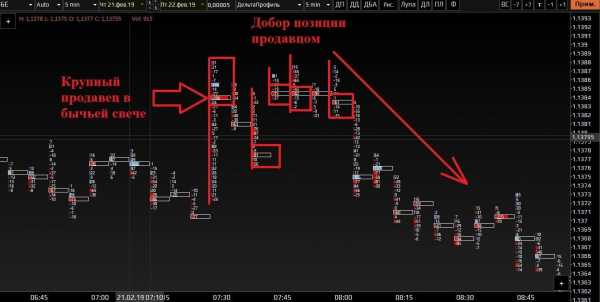
Что такой Футпринт
Футпринт — это точное отображение на графике уже совершенных сделок в конкретное время по покупке и продаже.
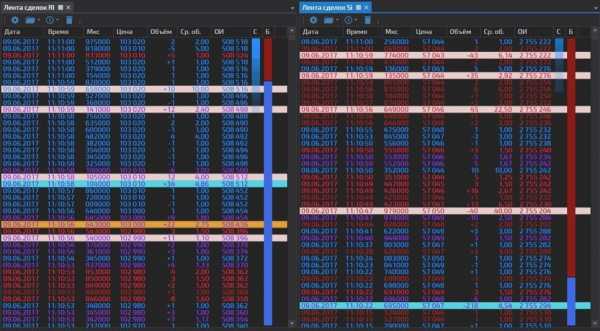
Вывод
С помощью кластерного анализа можно с высокой точностью прогнозировать цены, основываясь на объемах торгов. Он подходит для любой торговли, не важно торгуете вы интрадей или в долгосрок.
На мастер-классе Владимир Чернов дал рекомендацию по EUR/USD. На 12 ноября 15:36 МСК сделка еще являлась актуальной.
График EUR/USD за 06.11.19г.
Зарегистрируйтесь на сайте и получите курсы по фондовому и валютному рынкам.
Зарегистрироваться
На сайте вы также можете выбрать и скачать терминал для удобной торговли, который подойдет идеально именно вам.
Выбрать терминал
Поделись с другом
Мне нравится
0
Владимир ЧерновВедущий финансовый аналитик
ФОРЕКСКРИПТОВАЛЮТЫФОНДОВЫЙ РЫНОК
Кластеризация - это... Что такое Кластеризация?
Кластерный анализ (англ. Data clustering) — задача разбиения заданной выборки объектов (ситуаций) на непересекающиеся подмножества, называемые кластерами, так, чтобы каждый кластер состоял из схожих объектов, а объекты разных кластеров существенно отличались.
Задача кластеризации относится к статистической обработке, а также к широкому классу задач обучения без учителя.
Типология задач кластеризации
Типы входных данных
- Признаковое описание объектов. Каждый объект описывается набором своих характеристик, называемых признаками. Признаки могут быть числовыми или нечисловыми.
- Матрица расстояний между объектами. Каждый объект описывается расстояниями до всех остальных объектов обучающей выборки.
Цели кластеризации
- Понимание данных путём выявления кластерной структуры. Разбиение выборки на группы схожих объектов позволяет упростить дальнейшую обработку данных и принятия решений, применяя к каждому кластеру свой метод анализа (стратегия «разделяй и властвуй»).
- Сжатие данных. Если исходная выборка избыточно большая, то можно сократить её, оставив по одному наиболее типичному представителю от каждого кластера.
- Обнаружение новизны (англ. novelty detection). Выделяются нетипичные объекты, которые не удаётся присоединить ни к одному из кластеров.
В первом случае число кластеров стараются сделать поменьше. Во втором случае важнее обеспечить высокую степень сходства объектов внутри каждого кластера, а кластеров может быть сколько угодно. В третьем случае наибольший интерес представляют отдельные объекты, не вписывающиеся ни в один из кластеров.
Во всех этих случаях может применяться иерархическая кластеризация, когда крупные кластеры дробятся на более мелкие, те в свою очередь дробятся ещё мельче, и т. д. Такие задачи называются задачами таксономии.
Результатом таксономии является древообразная иерархическая структура. При этом каждый объект характеризуется перечислением всех кластеров, которым он принадлежит, обычно от крупного к мелкому.
Классическим примером таксономии на основе сходства является биноминальная номенклатура живых существ, предложенная Карлом Линнеем в середине XVIII века. Аналогичные систематизации строятся во многих областях знания, чтобы упорядочить информацию о большом количестве объектов.
Методы кластеризации
Формальная постановка задачи кластеризации
Пусть — множество объектов, — множество номеров (имён, меток) кластеров. Задана функция расстояния между объектами . Имеется конечная обучающая выборка объектов . Требуется разбить выборку на непересекающиеся подмножества, называемые кластерами, так, чтобы каждый кластер состоял из объектов, близких по метрике , а объекты разных кластеров существенно отличались. При этом каждому объекту приписывается номер кластера .
Алгоритм кластеризации — это функция , которая любому объекту ставит в соответствие номер кластера . Множество в некоторых случаях известно заранее, однако чаще ставится задача определить оптимальное число кластеров, с точки зрения того или иного критерия качества кластеризации.
Кластеризация (обучение без учителя) отличается от классификации (обучения с учителем) тем, что метки исходных объектов изначально не заданы, и даже может быть неизвестно само множество .
Решение задачи кластеризации принципиально неоднозначно, и тому есть несколько причин:
- не существует однозначно наилучшего критерия качества кластеризации. Известен целый ряд эвристических критериев,
а также ряд алгоритмов, не имеющих чётко выраженного критерия, но осуществляющих достаточно разумную кластеризацию «по построению». Все они могут давать разные результаты.
- число кластеров, как правило, неизвестно заранее и устанавливается в соответствии с некоторым субъективным критерием.
- результат кластеризации существенно зависит от метрики, выбор которой, как правило, также субъективен и определяется экспертом.
Применение
В биологии
В социологии
В информатике
- Группирование результатов поиска: Кластеризация используется для "интеллектуального" группирования результатов при поиске файлов, веб-сайтов, других объектов, предоставляя пользователю возможность быстрой навигации, выбора заведомо более релевантного подмножества и исключения заведомо менее релевантного — что может повысить юзабилити интерфейса по сравнению с выводом в виде простого сортированного по релевантности списка.
- Clusty[1] - кластеризующая поисковая машина компании Vivísimo
- поисковая система с автоматической кластеризацией результатов
- Сегментация изображений (image segmentation): Кластеризация может быть использована для разбиения цифрового изображения на отдельные области с целью обнаружения границ (edge detection) или распознавания объектов.
- Интеллектуальный анализ данных (data mining):Кластеризация в Data Mining приобретает ценность тогда, когда она выступает одним из этапов анализа данных, построения законченного аналитического решения. Аналитику часто легче выделить группы схожих объектов, изучить их особенности и построить для каждой группы отдельную модель, чем создавать одну общую модель для всех данных. Таким приемом постоянно пользуются в маркетинге, выделяя группы клиентов, покупателей, товаров и разрабатывая для каждой из них отдельную стратегию.
См. также
Литература
- Айвазян С. А., Бухштабер В. М., Енюков И. С., Мешалкин Л. Д. Прикладная статистика: классификация и снижение размерности. — М.: Финансы и статистика, 1989.
- Журавлев Ю. И., Рязанов В. В., Сенько О. В. «Распознавание». Математические методы. Программная система. Практические применения. — М.: Фазис, 2006. ISBN 5-7036-0108-8.
- Загоруйко Н. Г. Прикладные методы анализа данных и знаний. — Новосибирск: ИМ СО РАН, 1999. ISBN 5-86134-060-9.
- Мандель И. Д. Кластерный анализ. — М.: Финансы и статистика, 1988. ISBN 5-279-00050-7.
- Шлезингер М., Главач В. Десять лекций по статистическому и структурному распознаванию. — Киев: Наукова думка, 2004. ISBN 966-00-0341-2.
- Hastie T., Tibshirani R., Friedman J. The Elements of Statistical Learning. — Springer, 2001. ISBN 0-387-95284-5.
- Jain, Murty, Flynn Data clustering: a review. // ACM Comput. Surv. 31(3) , 1999
Внешние ссылки
На русском языке
На английском языке
- COMPACT - Comparative Package for Clustering Assessment. A free Matlab package, 2006.
- P. Berkhin, Survey of Clustering Data Mining Techniques, Accrue Software, 2002.
- Jain, Murty and Flynn: Data Clustering: A Review, ACM Comp. Surv., 1999.
- for another presentation of hierarchical, k-means and fuzzy c-means see this introduction to clustering. Also has an explanation on mixture of Gaussians.
- David Dowe, Mixture Modelling page - other clustering and mixture model links.
- a tutorial on clustering [2]
- The on-line textbook: Information Theory, Inference, and Learning Algorithms, by David J.C. MacKay includes chapters on k-means clustering, soft k-means clustering, and derivations including the E-M algorithm and the variational view of the E-M algorithm.
- An overview of non-parametric clustering and computer vision
- "The Self-Organized Gene", tutorial explaining clustering through competitive learning and self-organizing maps.
- kernlab - R package for kernel based machine learning (includes spectral clustering implementation)
- Tutorial - Tutorial with introduction of Clustering Algorithms (k-means, fuzzy-c-means, hierarchical, mixture of gaussians) + some interactive demos (java applets)
- Data Mining Software - Data mining software frequently utilizes clustering techniques.
- Java Competitve Learning Application A suite of Unsupervised Neural Networks for clustering. Written in Java. Complete with all source code.
- Machine Learning Software - Also contains much clustering software.
- Fuzzy Clustering Algorithms and their Application to Medical Image Analysis PhD Thesis, 2001, by AI Shihab.
- Cluster Computing and MapReduce Lecture 4
Wikimedia Foundation. 2010.