Снапшот что это такое
Снимок файловой системы — Википедия
Снимок файловой системы, или снапшот, или снепшот (от англ. snapshot — мгновенный снимок) — моментальный снимок, копия файлов и каталогов файловой системы на определённый момент времени.
Создание резервной копии большого объёма данных может занять длительное время. В многозадачных или многопользовательских системах во время резервного копирования может происходить запись или изменение файлов и каталогов, что может привести к неверной резервной копии данных. Например, пользователь перемещает файл из каталога, который ещё не был сохранён при резервном копировании (в резервную копию — бэкап), в каталог, который уже сохранён. Такой файл может вообще не войти в резервную копию. Также, файл, предназначенный для резервного копирования, может записываться в момент его чтения процедурой резервного копирования и может быть сохранён в неверной версии.
Одним из методов безопасного создания резервной копии является запрещение записи в данные, которые подлежат резервному копированию, на время создания резервной копии. Ещё одним из методов является остановка всех приложений, которые могут изменять эти данные, или блокировка этих приложений форсированным включением режима только для чтения средствами интерфейса программирования приложений (API) операционной системы (ОС). Эти методы используются в системах низкой доступности (домашние компьютеры, серверы небольших рабочих групп, для которых регулярная недоступность (downtime) позволительна). В системах высокой доступности 24/7 эти методы применять нельзя, так как это может повлечь отказ в обслуживании сервисов.
Для избежания недоступности (downtime) системы высокой доступности могут вместо прямого резервного копирования сначала создать снапшот — копию информации только для чтения, «замороженную» в определённый момент времени. А затем, позволив приложениям продолжить обновлять данные, создавать резервную копию. Большинство реализаций снапшотов эффективно, они создают снапшот за O(1). Другими словами, время и количество операций ввода-вывода, необходимое для создания снапшота, не увеличивается с ростом объёма данных, в то время, как те же параметры для создания прямой резервной копии пропорциональны размеру сохраняемых данных.
Снапшоты для чтения-записи иногда приводят к ветвлению снапшотов, так как они неявно создают различные версии своих данных. Помимо резервного копирования и восстановления данных, снапшоты часто используются в виртуализации, в различных песочницах и в виртуальном хостинге благодаря их эффективности в ведении изменений большого набора данных.
Управление томами[править | править код]
Некоторые операционные системы из семейства UNIX, например, HP-UX, а также Linux обладают менеджером логического раздела, в котором реализована поддержка снапшотов. Эта реализация копирования при записи на целых блочных устройствах путём копирования изменённых блоков до того, как они будут перезаписаны, в другое место, сохраняет целостность снапшота на блочном устройстве. Файловые системы на этом снапшоте могут быть позднее подключены только в режиме чтения. Снапшоты блочного уровня почти всегда менее эффективно используют место, чем снапшоты в файловых системах, которые их поддерживают.
Файловые системы[править | править код]
Некоторые файловые системы, такие как WAFL, fossil для Plan 9 или ODS-5, внутренне отслеживают старые версии файлов и делают снапшоты доступными через специальное пространство имён. Другие, например UFS2, предоставляют для операционной системы API для доступа к своей истории файлов. В NTFS доступ к снапшотам предоставляется через Volume Shadow Copy (VSS) в Windows XP и Windows Server 2003, и через Shadow Copy в Windows Vista. Снапшоты также доступны в Novell Storage Services (NSS) — файловой системе для Netware, начиная с версии 4.11, и более новых на Linux-платформах в продуктах Open Enterprise Server (OES).
ZFS имеет гибридную реализацию, которая отслеживает чтение-запись снапшотов на блочном уровне, но создает разветвлённые наборы файлов, известные пользовательским приложениям как «клоны».
В базах данных[править | править код]
Спецификация SQL определяет четыре уровня изоляции транзакций. На самом высоком уровне — сериализационном, снапшот создается при старте каждой транзакции. Утилиты для резервного копирования большинства популярных SQL — баз данных используют эту технологию для создания самосогласованного образа таблицы данных.
Другие приложения[править | править код]
Программная транзакционная память — это схема, которая применяет сходную концепцию для структур данных, хранящихся в оперативной памяти.
Чем Backup отличается от Snapshot
Но файлы снепшотов обычно хранятся рядом с «замороженными» исходными данными для быстроты доступа. Поэтому, в отличие от бэкапа, снепшот не требует отдельного хранилища.
Можно сделать как моментальный снимок системы целиком, так и каких-то отдельных данных. Моментальный снимок удастся сделать и с выключенным компьютером – у бэкапа такой возможности нет.
Когда используют бэкап
Создание бэкапа (резервное копирование) позволяет сохранить данные на длительный срок, чтобы их можно было восстановить в случае сбоя, повреждения или утраты носителя.
Лучше всего бэкап подходит в следующих ситуациях:
- Архивирование: необходимо на длительный срок сохранить данные (более недели).
- Миграция: требуется перенести данные на другое устройство.
- Восстановление: нужно обеспечить возможность восстановления системы в случае сбоя.
Когда лучше использовать снепшот
Смысл снепшотов − не в надежности, а в быстром и удобном восстановлении состояния системы. Если бэкапы надо хранить подальше от основной системы, чтобы не складывать все яйца в одну корзину, то есть – застраховаться от физического уничтожения системы вместе с бэкапами, то данные снепшота должны быть как можно ближе, чтобы сама передача данных не затягивала восстановление.
Использовать снепшот можно, чтобы потестировать приложения, обновления, патчи, обезопасить данные, если есть вероятность их повреждения.
Бэкапы и снепшоты работают вместе
Бэкапы и снепшоты − для разного: одни для надежности, другие для гибкости. Но когда нужно и то, и другое, они работают вместе.
Например, полное бэкапирование занимает много времени, это мешает сделать точную копию. В бэкапе может оказаться копия данных, отличная от оригинала, так что его нельзя будет восстановить из бэкапа. Представьте себе три папки: «Кошки», «Еноты» и «Ежи». Кошки уже скопировались в бэкап, сейчас копируются еноты. Если в этот момент взять ежа #8 и из «Ежей» перенести в «Кошек», система создания бэкапов этого не заметит. Когда она дойдет до «Ежей», #8 не попадет в бэкап− копия не будет содержать его ни в «Ежах», ни в «Кошках».
Конечно, на время создания копии можно переключить данные в режим «только для чтения», но в этот момент придется заблокировать работу с данными для всех приложений. Это подходит для домашнего компьютера, но не подходит для систем, которые должны быстро отвечать на запросы. В этом случае сначала создается снепшот системы − а это гораздо быстрее бэкапа. Потом системе разрешают меняться дальше, а бэкап создается уже с файла со снепшотом. Когда бэкап готов, к снепшоту применяются все дальнейшие изменения, после этого он удаляется.
Резюме
Бэкапы − для надежности хранения данных и возможности их восстановления или «клонирования» на другие компьютеры.
Снепшоты − для быстрого и удобного возвращения системы в прошлое состояние. Это помогает проводить «опасные» эксперименты.
Что такое снапшот? Значение термина SnapShot
Снапшот (SnapShot) – это снимок состояния виртуальной машины в определенный момент времени. Сюда входит настройки ВМ, содержимое памяти и дисков.
Revert to snapshot (возврат к снапшоту) восстанавливает текущее состояние ВМ до сохраненного.
Создание резервной копии достаточно большого объема данных как правило занимает не мало времени. В многозадачных системах, во время бэкапа может происходить изменение или запись папок и файлов, а это иногда приводит к неправильному копированию данных. Например, юзер перемещает файл из папки, которая еще не была сохранена при бэкапе, в директорию, которая уже попала в бэкап. Такой файл может вообще не попасть в резервную копию. Или файл, предназначенный для копирования, может записываться в момент его чтения процедурой резервного копирования и возможно он будет сохранен в неправильной версии.
Одним из методов безопасного копирования является запрещение записи в данные, которые подлежат бэкапу, на время создания копии. Есть еще один метод – это остановка всех приложений, которые эти данные изменять. Такие методы применяются в системах низкой доступности (домашние ПК, сервера малых рабочих групп). Для этой категории позволительна регулярная недоступность. Однако же в системах высокой доступности (24/7) такие методы недопустимы, так как они могут повлечь отказ в обслуживании сервисов.
Для того, чтобы избежать downtime, системы высокой доступности могут вместо прямого бэкапа сначала сделать спашот, то есть копию информации в определенный момент времени. А уже затем, позволив приложениям продолжать работать, создать резервную копию.
Кроме резервного копирования снапшоты, благодаря своей эффективности в ведении изменений огромного набора данных, используются в виртуализации и виртуальном хостинге.
Помогло? Делись!
Весь список терминов →Что такое снапшоты виртуальной машины и зачем они нужны.
«Snapshot» переводится с английского, как «выстрел навскидку» или «моментальный фотоснимок». Снапшот – это снимок виртуальной машины (ВМ), слепок её состояния. Для чего нам нужна ВМ? Ну конечно же, прежде всего для того, чтобы ставить различные эксперименты! И, чтобы каждый раз не заниматься мучительным отмыванием ВМ от осколков очередного эксперимента с помощью всяких чистильщиков, можно воспользоваться такой любопытной функцией, как «снимок» и быстро вернуться к исходному состоянию. Но надо уметь это делать, иначе можно угробить ВМ. Далее я буду излагать свои соображения для самой популярной ВМ – VirtualBox.
Немного теории для тех, кто не в курсе.
ВМ – это не что иное, как файл. В этом файле записана информация, которая представляет собой виртуальную ОС плюс пользовательский софт. Файл этот довольно большой, например, 10 Гбайт. Файл ВМ имеет расширение .vdi, например, machine.vdi, и называется образом ВМ. Если сделать снимок включённой ВМ, то на диске машины-хозяйки в файле ВМ сверх этих 10 ГБ ничего не прибавится, однако файл machine.vdi заморозится («зафризится», как любят говорить .юные айтишники) и далее будет использоваться только для чтения ( в режиме «ридоунли» на сленге). С этого момента всё, что в ВМ будет изменяться, будет писаться в отдельный файл uuid.vdi, где uuid – уникальный идентификатор пользователя. C точки зрения пользователя, uuid представляет собой бесполезную алфавитно-цифровую ахинею, но ВМ прекрасно в ней разбирается. Дальнейшая работа ВМ ведёт к накоплению изменений в этом файле. В любой момент можно создать новый снимок ВМ или же откатиться на один из сделанных ранее.
Снимки образуют цепочку (если снимки делаются подряд) или дерево (если делаются откаты на снимки). Даже если часть из исходных 10Гбайт образа удалить, они сотрутся с точки зрения машины-гостьи, но останутся в файле ВМ до момента снимка.
Итак, текущий образ ВМ складывается из первоначального образа плюс все промежуточные снимки, которые наслаиваются сверху. Если удалить какой-то из снимков, то все состояния после него будут потеряны. Отмена (discard) снимка будет объединять его содержимое с последующим снимком или с текущим состоянием ВМ, если это последний снимок. Восстановление ВМ из снимка влияет на все виртуальные жесткие диски подключенные к вашей ВМ, поскольку данные на диске будут также восстановлены из снимка.
Короче, вы можете создавать снимки, восстанавливать ВМ из снимков и удалять снимки. Несложно, правда? Всего три базовых операции! Однако, учитывайте, что, хотя создание и восстановление снимков выполняется за несколько секунд, удаление снимка может занять несколько минут, поскольку при этом будет копироваться большой объем данных.
Вы можете увидеть все снимки вашей ВМ, выбрав ее в окне менеджера VirtualBox и кликнув на "Снимки" в верхнем правом углу. Пока вы не сделали ни одного снимка, список снимков, естественно, будет пуст, за исключением элемента "Текущее состояние", который символизирует отправную точку жизненного цикла вашей ВМ.
Будем что-нибудь тестировать.
Вообще-то описанным далее способом можно тестировать что угодно. Но пользователи почему-то очень любят тестировать именно браузеры. Идея простая: делаем снимок ВМ без браузеров, устанавливаем очередной браузер, делаем снимок, возвращаемся к исходному состоянию ВМ без браузеров, устанавливаем следующий браузер и т.д. В итоге получаем одну и ту же ВМ, но с разными браузерами. Этим мы, во-первых, исключили влияние браузеров друг на друга, и, во-вторых, избавились от чистки ОС. Поехали!
-
Первоначальный снимок. Загрузите VirtualBox (VB), выберите ОС, но не запускайте её! Сделайте снимок:
Поименуйте этот снимок, как org. Итак, первоначальное состояние ВМ зафиксировано:
-
Запустите виртуальную ОС и установите что-нибудь, например, браузер1. Когда он установится, откройте окно ВМ и сделайте новый снимок. Дайте снимку имя и нажмите ОК. Потребуется несколько. секунд, чтобы записать снимок. Почему так мало? Потому что на самом деле новый снимок будет содержать всего лишь разницу по сравнению с оригинальным снимком.
Протестируйте установленный браузер, если хотите. Впрочем, вы это можете сделать и позже, восстановив всё из снимка. Завершите работу виртуальной ОС.
-
Чтобы начать тестировать следующий браузер, в окне VB изберите обязательно! корневой снапшот (он поименован, как org) и кликните «восстановить снапшот». Иконка «восстановить снапшот» похожа на стрелку на вкладке.
Далее откроется дополнительное окно, предупреждающее, о возможных потерях. Снимите птичку в чекбоксе «сохранить текущее состояние», так как вы его уже сохранили, и жмите «Восстановить». Пройдёт несколько секунд, пока состояние ВМ будет восстанавливаться из корневого снимка. Теперь стартуйте свою ВМ.
-
Установите следующий браузер2. Когда он установится, откройте окно ВМ и сделайте новый снимок. Дайте снимку имя и нажмите ОК.
Завершите работу ВМ. -
Повторяйте шаги 3 и 4 со всеми браузерами, которые желаете протестировать.
-
Получится линейка снимков, порождённых корневым снимком.
Каждый из снимков в этой линейке – это разница с корневым снимком.
-
И теперь можете запускать разные состояния ОС с установленными браузерами и тестировать их столько раз, сколько требуется. Надо просто выбрать нужный снимок и начать кнопку «Восстановить». Как только снимок с тестируемым браузером будет загружен, стартуйте свою ВМ и тестируйте выбранный браузер.
Не правда ли просто? Но это далеко не всё, что можно вытворять с помощью снимков ВМ. (Продолжение следует.)
Snapshots — «фото на память (дисковую;)» / NetApp corporate blog / Habr

Всегда странно представлять себе времена, когда чего-то не было. Сложно сегодня представить себе, как мы жили без персональных компьютеров, без интернета, без торрентов, mp3, или без электрокопировальных аппаратов, в просторечии «ксероксов». Тем не менее всегда были времена, когда что-то привычное нам еще не существовало. Также обстояло дело и с понятием «снэпшота данных». Но сперва — что же такое «снэпшот»?
"Снэпшот" (дословно — «фотография», «моментальный снимок», здесь и далее под этим словом мы будем понимать конкретно, не уточняя, «снэпшот данных») это моментальная копия состояния данных в системе хранения, или программе, зафиксированная на определенный момент времени. Это может быть моментальное состояние содержимого файла, базы данных, или файловой системы (как частного случая «базы данных»).
В применении к системам хранения данных этот термин появился вместе с первыми системами хранения NetApp и был, на тот момент первой и главной их «фичей».
Ранее я уже рассказывал о внутренней файловой структуре WAFL, придуманной основателями NetApp для своего продукта, и о том, каким образом она работает. Интересующихся техническими деталями отошлю к прекрасной авторской публикации, которая сейчас переведена на русский язык. Именно эта, несколько необычная, на первый взгляд, по принципам работы, файловая структура сделала возможной реализацию концепции снэпшотов — мгновенных копий состояния данных, хранимых на дисках такой системы.
Как я уже рассказывал в статье про WAFL, основной принцип ее работы состоит в том, что однажды записанные на диск данные, в дальнейшем, не изменяются. Данные (например файл) можно на WAFL либо записать (целиком), либо стереть (целиком). В случае же необходимости изменения его содержимого эти изменения «дописываются» в свободное место дискового пространства, после чего на блоки с записанным содержимым изменений переставляется указатель содержимого файла (старый блок содержимого помечается как свободный, или не помечается, если на него ссылается более одного файла, или он использован в снэпшоте). Следовательно, для того, чтобы сохранить текущее состояние данных, при таком алгоритме работы записи, все что нам нужно, это сохранить «корневой inode» на данный момент времени.
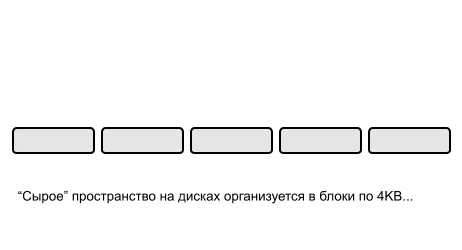
Inode, напомню, это блок данных, определяющий содержимое файла. Он может ссылаться либо прямо на конкретные блоки, либо, для больших файлов, на промежуточные inodes, образуя «дерево» от «корня», единственного на всю файловую систему тома, так называемого «корневого» inode.
Таким образом, создав копию ровно одного блока, корневого inode данной файловой системы, мы получим, обратившись к нему, вместо текущего «корня», «псевдо-файловую систему», хранящую без изменений (read-only) все данные на момент времени, когда мы скопировали этот inode. Ведь, как вы помните, однажды записанные блоки данных файлов в дальнейшем не изменяются.
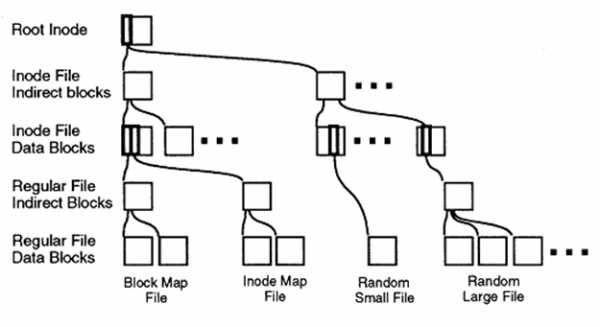
Каким же образом это выглядит на практике?
Для упрощения рассказа я буду рассматривать NAS-вариант работы NetApp, хотя, как вы знаете, аналогичным образом тот же самый сторадж может работать и как SAN-устройство.
Каждый том на системе хранения NetApp является отдельной файловой системой. На каждой файловой системе можно создать до 254 снэпшотов ее состояния, по методике, описанной выше.
Все созданные снэпшоты автоматически доступны через директорию /.snapshot (или /~snapshot) в корне тома. Зайдя туда, мы увидим имена созданных снэпшотов (они могут носить либо «собственное имя», например "/lets_fix_this_small_bug…oh_shit!..", будучи созданными вручную, либо, если создаются по расписанию, будут располагаться в поддиректориях hourly.0(1,2,3…), daily.0(1,2,3) и так далее.
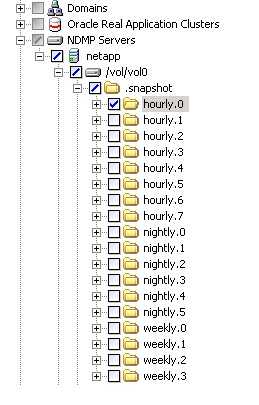
Войдя в такую папку мы увидим полностью все содержимое нашего тома, со всеми файлами в нем, причем все файлы будут доступны на чтение, и читаться из них будет все то содержимое, которое было в них на момент взятия снэпшота.
Причем это даже выглядит несколько странно, на первый взгляд.
Допустим, что у вас есть том, размером 1TB, на котором лежит файл базы данных, размером 750GB. Для этого тома вы создаете снэпшоты каждый час по расписанию. Войдя в /.snapshot вы увидите в ней поддиректории /hourly.0, /hourly.1, и так далее, причем в каждой из них будет лежать «файл размером 750GB». При этом на собственно томе, емкостью 1TB, на котором как бы и лежат эти 24 (каждый час) копии базы по 750 гиг размером каждая, еще будет гигабайт 200 свободного места.
При этом любой из этих 24 «файлов» мы можем скопировать в резервную копию на внешнее хранилище, смонтировать как независимый read-only и использовать (читать) эти данные, как если бы это была реальная база данных, восстановить из нее данные, скопировав ее на место «активной», например в случае «все сломали, надо откатится на состояние час назад», и так далее.
Где же все это хранится?
Дело в том, что все эти «файлы», это просто ссылки на одни и те же блоки неизмененных данных. Место же на диске занимают только изменения, между снятыми снэпшотами. Допустим, что за сутки мы наменяли в этой базе блоков на 50 гигабайт. Тогда занятое место на дисках, в томе размером 1TB, на котором лежит файл базы на 750GB, и снэпшоты каждый час, будет 1TB — 750GB файл — 50GB изменений = 200GB свободно.
Если изменений за час между двумя снэпшотами (hourly.0 и hourly.1) получилось на 1% объема базы, то hourly.1 займет 7,5GB места на диске, указывая своими inodes на измененные, по сравнению с предыдущим снэпшотом, блоки. Все же остальные inodes по прежнему будут ссылаться на прежние, неизмененные блоки.
Чем удобно использование снэпшотов?
Простейший пример я уже привел. Допустим мы, или наши пользователи, «все сломали». Это может быть база данных, или же, допустим, экселевский файл, в котором, случайно, грохнули не те данные, успели записать, а потом обнаружили это, а восстановить надо срочно, «или нас всех убьют». Но мы знаем, что час (два, три, сутки, неделю, месяц назад, все зависит от частоты и регулярности снэпшотов) нужный нам файл был исправен.
Мы (это может сделать, кстати, даже сам пользователь) просто заходим в папку /.snapshots и вытаскиваем оттуда простым копированием нужный нам файл, на нужный момент времени, час, два, сутки, и так далее назад.
Либо, если у нас есть специальная лицензия SnapRestore, одной командой из консоли стораджа, «откатываем» состояние тома на нужный момент времени целиком (что удобно, если нужно восстановить не отдельный одиночный файл, а содержимое всего тома, в целом).
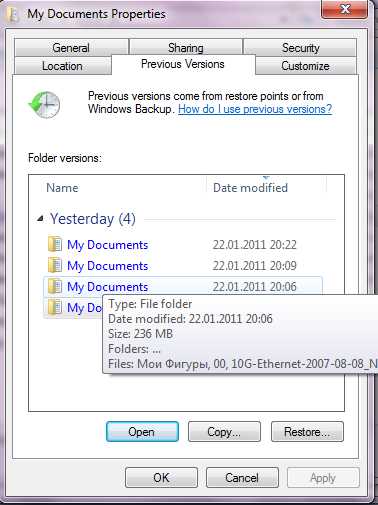
Таким образом, снэпшоты это, для пользователя, очень оперативная резервная копия, доступная тут же, на этом же сторадже. Кстати, в случае использования Windows XP или 7, вы будете видеть файлы в снэпшоте в панели «Previous versions» свойства файла или папки, NetApp интегрируется в этот механизм Windows как VSS-provider.
Теперь рассмотрим более сложный вариант. Допустим, мы эксплуатируем большую, ответственную, mission-critical SQL-базу данных предприятия.
Разумеется, каждый вечер, эта база данных бэкапится на ленту, для создания резервной копии.
База большая, и резервная копия копируется на ленту примерно час.
«Ничто не предвещало беды», но однажды, посреди рабочего дня, допустим в 3 часа дня, база необратимо портится.
Какие действия предпринимает сисадмин, для того, чтобы базу восстановить?
Мы считываем резервную копию по состоянию на конец прошлого рабочего дня (читаться она будет, допустим, столько же, сколько писалась — час), а затем нам следует «накатить» на нее redo-log-и, от момента создания бэкапа, вечером, и до момента, предшествующего сбою, то есть до 3 часов следующего дня. Этот «накат» часто довольно объемен, и также занимает какое-то время, ведь операции в SQL происходят не мгновенно. Допустим, через 30 минут, после окончания считывания бэкапа, база восстановлена в рабочем состоянии на момент предшествующий сбою, и мы готовы продолжать работу. Итого — 1:30.
В случае использования снэпшотов дела будут происходить следующим образом. У нас также делается ежедневная копия на ленту для обеспечения безопасности хранения, например на случай полного выхода из строя системы хранения, но у нас хранилище живо, повреждены только данные на нем. Мы знаем, что час назад база была жива и здорова. Мы восстанавливаем базу по состоянию на 2 часа дня, и так как снэпшот создается и восстанавливается практически мгновенно, то это занимает не час, а всего несколько секунд, и накатываем на нее redo-logs, но не со вчерашнего вечера, как в предыдущем случае, а всего за один час, с 2 часов, то есть момента создания снэпшота, до момента аварии, в 3 часа дня. Это занимает также не полчаса, а всего несколько минут.
Итог: спустя несколько минут, а не полтора часа, как обычно, наша база вновь в рабочем состоянии.
Очевидные преимущества использования снэпшотов привели к тому, что, на сегодня, практически все производители систем хранения предлагают для своих систем ту или иную реализацию «снэпшотов» как идеи.
Однако, как мы помним, «не все йогурты одинаково полезны».
В чем же принципиальное отличие «настоящих снэпшотов» (Название Snapshots (tm) для систем хранения это зарегистрированная торговая марка NetApp) от всех остальных, «контрафактных копий». ;)
Принципиальное отличие, позволяющее реализовать снэпшоты так, как это было описано мной выше — устройство WAFL, которое, как я уже рассказывал, не позволяет изменять уже записанные данные. Такая модель позволяет реализовать снэпшоты легко и просто. Но все обстоит хуже, если структура записи традиционна. При этом нам придется сперва, до начала использования, выделить зарезервированное пространство блоков, заранее отняв его у данных, затем, при каждом изменении блока на диске, копировать его содержимое в специальный зарезервированный пул, затем изменять его содержимое на его прежнем месте, затем изменять метаданные, указывающие на старое содержимое, для снэпшота.
Эта технология носит название Copy-on-Write (COW), и широко применяется в системах хранения других производителей, в их реализации снэпшотов.
Как вы видите из описания выше, даже само наличие включенного механизма снэпшотов для тома превращает одну операцию записи для системы хранения в три (чтение исходного содержимого, запись исходного содержимого на новое место, запись измененного содержимого на старое место).
Результат не заставляет себя ждать. Использование COW-snapshots резко ухудшает производительность системы хранения его использующего. Это разительный контраст с системами NetApp, в которых снэпшоты вообще никак не влияют на производительность, ведь никакого копирования при записи в них не происходит, все данные остаются на своих местах.
(демонстрация результатов производительности на тесте SPC-1)
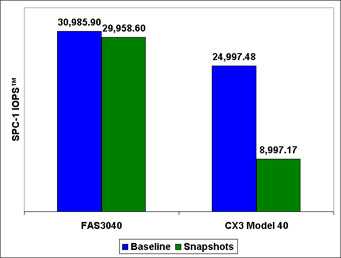
Следствием такого неприятного поведения при использовании COW-snapshots является рекомендация вендоров свести использование таких «неправильных снэпшотов» к минимуму, или не использовать их вовсе на primary-системах, предъявляющих повышенные требования к производительности.
Однако системы NetApp такой проблемой не страдают и никаких ограничений на использование снэпшотов не предъявляют.
Кроме этого, часто (по той же причине) общее количество снэпшотов на таких системах ограничено всего парой десятков максимум, отмечу, для контраста, что на системах NetApp можно использовать до 254 снэпшотов на каждый том, что, при общем количестве томов, допустимых систему, равного 500, достигает теоретического максимума в 127 тысяч.
Это позволяет, при использовании классической «ротации» резервных копий, хранить в 254 снэпшотах резервные копии данных тома до года включительно.
Также немаловажной является возможность создавать «по настоящему мгновенные» копии данных, причем независимо от размера «копируемых» данных. Хоть базу на 100MB, хоть на 100TB, снэпшот с нее будет всегда создан мгновенно. Например, мы можем создать «резервную копию» не «за час», а «за секунду», а затем, уже не нагружая нашей задачей реальную боевую базу, потихоньку копировать на резервное хранилище содержимое такого снэпшота.
Практика показывает, что люди, попробовавшие простоту и удобство использования снэпшотов, очень скоро уже просто не представляют себе жизни без них, считая это «само собой разумеющейся» возможностью любой системы хранения. Попробуйте и вы.
Напомню, что взять на тестирование систему хранения NetApp можно у любого партнера, список которых можно посмотреть на российской странице вебсайта NetApp.
www.netapp.com/ru/how-to-buy/resellers/distributor-ru.html
www.netapp.com/ru/how-to-buy/resellers/platinum-ru.html
www.netapp.com/ru/how-to-buy/resellers/gold-ru.html
PS: На традиционном «фото для привлечения внимания» в заголовке — задняя часть контроллера самой младшей модели NetApp — FAS2020. Самой младшей, но, тем не менее, обладающей всеми возможностями хранилищ NetApp, в том числе и работой со снэпшотами.
На фото, слева направо — два порта FC 4Gb/s, порт последовательной консоли, порт out-of-band микроконтроллера удаленного администрирования, и два порта Gigabit Ethernet.
PPS: А еще можно было бы написать на этой неделе про 5 место NetApp в Fortune's list Best Plaсes to Work, вон Intel стррашно гордится аж 51-м местом (из ста), но мне показалось, что все эти радости пиар-отдела Хабру не очень интересны, поэтому упомяну об этом «бегущей строкой» в самом конце. Да, пятое место в сотне лучших работодателей США, и пятнадцатое (выше Google (30) и Apple (20), кстати) по списку сайта Glassdoor, оценивающего компании не «снаружи», как Fortune, а изнутри, анонимными голосами самих работников. «Пустячок, а приятно».
Использование моментальных снимков (Snapshots) в Hyper-V / Habr
Моментальные снимки: сложно о простомНаверняка многие знакомы с достаточно полезной функцией многих продуктов виртуализации – моментальными снимками, в простонародье – «снапшоты» (snapshots). Снапшот виртуальной машины – это как сохранение в игре: в случае, если где-то сильно накосячил (патч Бармина применил, например) – можно вернуться назад и повторить все заново. В этой статье я попытаюсь более-менее подробно рассказать о работе моментальных снимках и о некоторых нюансах их применения. В статье речь пойдет о Microsoft Hyper-V, но с некоторыми натяжками материал статьи применим и для других систем виртуализации (в частности — VMWare).
Прежде, чем продолжать – вспомним, из каких компонентов состоит виртуальная машина:
Файл конфигурации – основа виртуальной машины, хранит все настройки, касающиеся виртуалки. Представляет собой XML-файл, имеющий, как ни странно, расширение XML. В VirtualPC/Virtual Server этот файл имел расширение VMC.
Файл виртуального диска. Обычно в качестве жесткого диска виртуальные машины используют специальные файлы-образы, имеющие расширение VHD. Этот формат, изначально разработанный фирмой Connectix, после приобретения ее корпорацией Microsoft стал использоваться в продуктах виртуализации, и не только в них: в частности, они используются в Microsoft Software iSCSI Target, а в ОС Windows 7 и Windows Server 2008 R2 с VHD-дисками можно работать на уровне ОС, вплоть до загрузки с них самой операционки.
Дифференциальные диски – основа технологии снапшотов. При создании снапшота запись в VHD-файл прекращается, и все последующие изменения записываются в отдельный файл, имеющий расширение VHD.
Сохранение состояния (Save State) – одна из полезных функций системы виртуализации. При сохранении состояния все содержимое памяти виртуальной машины, регистров процессора и т.д. сохраняется в специальные файлы, и виртуалка переходит в состояние «Выключено». После этого можно делать все что угодно, вплоть до перезагрузки хостовой машины, а потом снова запустить виртуалку – и она будет работать, как ни в чем не бывало, ровно в том же состоянии, в каком она была до сохранения. Примерно так же работает функция Hibernate в Microsoft Windows с единственным лишь отличием – сохранение состояния происходит на уровне самой виртуальной машины, а не на уровне гостевой ОС. В VirtualPC и Virtual Server для сохранения содержимого памяти использовался файл с расширением VSV, в Hyper-V же их стало аж целых два – BIN и VSV.
Файл экспорта. Если виртуальную машину Hyper-V нужно склонировать, или же перенести на другой хост – необходимо произвести операцию экспорта, а затем импорта. При экспорте конфигурационный XML-файл преобразуется в файл с расширением EXP. В VirtualPC и Virtual Server для этого достаточно просто скопировать файлы виртуальной машины, а в Hyper-V придумали импорт/экспорт – как они сами говорят, в целях безопасности.
Различают два типа моментальных снимков: онлайновый и оффлайновый. Онлайновым называют снапшот, сделанный на виртуальной машине с запущенной гостевой ОС. Соответственно, если виртуальная машина была в состоянии «выключено» — то снапшот будет называться оффлайновым. Для пользователя нет абсолютно никаких различий между онлайновыми и оффлайновыми снапшотами. Различаются они только по составу файлов, потому что при создании снапшота на запущенной виртуалке происходит операция Save State, и данные Save State включаются в состав снапшота
Онлайн-снапшот:
- Копия файла конфигурации
- Дифференциальный диск AVHD
- Файлы Save State – BIN+VSV
- Копия файла конфигурации
- Дифференциальный диск AVHD
Что можно и что нельзя делать с моментальными снимками?
Как уже было сказано, снапшоты виртуальных машин – это то же самое, что и сохранение в игре. И единственное их назначение – обеспечение точки возврата на случай возможных ошибок. Снапшоты – это не бэкап, и использовать их для аварийного восстановления не получится. Использовать моментальные снимки в production-среде не рекомендуется, потому что это может привести к падению производительности, почему это так – будет понятно далее из статьи. Если необходимо часто создавать резервные копии для защиты от ошибок пользователей – необходимо использовать другие средства, к примеру – инкрементные бэкапы или журналы транзакций, если речь идет о базах данных.
Помимо этого, необходимо помнить, что управлять снапшотами можно и нужно только через стандартные средства Hyper-V (оснастка MMC Hyper-V Manager, WMI-провайдеры, командлеты PowerShell) и сторонний софт, использующий такие средства – например Microsoft SystemCenter Virtual Machine Manager.
Итак, что же происходит при создании снапшота?
Для простоты представим виртуальную машину с одним жестким диском (см. рисунок). Только что мы установили на нее операционную систему, и, прежде чем двигаться дальше – хотим сделать снапшот. При выборе Create Snapshot текущая конфигурация виртуальной машины сохраняется в отдельный файл (Копия конфигурации 1), и создается файл AVHD (Дифференциальный диск AVHD 1). При этом в саму конфигурацию виртуальной машины вносятся изменения, и с этого момента из файла VHD производится только чтение, а вся запись производится только в AVHD-файл (зеленая стрелка). Диск виртуальной машины состоит уже из двух файлов: VHD и AVHD. У нас получился первый моментальный снимок, который для удобства можно назвать «OS Installed» (по умолчанию снапшотам дается имя из имени виртуальной машины с добавлением даты и времени создания).
Теперь, допустим, что мы что-то сделали (к примеру, установили приложение) и делаем еще один снапшот. Точно так же, как и до этого – конфигурация сохраняется в отдельный файл, создается новый AVHD, и запись перенаправляется уже в него (желтая стрелка). Виртуальный диск состоит уже из трех файлов: VHD и двух AVHD. Для простоты получившийся снапшот можно назвать «Apps Installed».
Допустим, мы создали один или несколько моментальных снимков. Что же теперь с ними можно сделать? Выбор тут, в принципе, не слишком богат: снапшот можно либо применить (Apply), либо удалить (Delete). По факту, это означает:
- Apply – возвратиться к точке создания снапшота, при этом все изменения, произошедшие с момента создания снапшота и до настоящего времени будут потеряны.
- Delete – точка возврата удалится, а все внесенные изменения сохранятся на веки вечные.
Это нужно четко для себя уяснить, чтобы потом не «наломать дров». Как говорил один специалист – «Delete means Apply, Apply means Delete», и даже еще лучше будет сказать в стиле Маяковского: «Мы говорим «Удалить» — подразумеваем «Применить», мы говорим «Применить» — подразумеваем «Удалить».
Посмотрим, как это происходит.
Хотим мы откатиться назад, к моменту окончания установки приложений. Для этого выбираем снапшот «Apps Installed» («Моментальный снимок 2»)и делаем «Apply». Как только мы это делаем – текущая конфигурация виртуалки заменяется копией из состава снапшота (т.е. «Конфигурация» перепишется из «Копии конфигурации 2»). После этого AVHD со внесенными до «отката» изменениями («Дифференциальный диск AVHD 2») удаляется, и создается новый AVHD, в который сразу же перенаправляется запись.
Теперь, допустим, мы закончили наши эксперименты, и перед вводом виртуальной машины в продакшн хотим удалить все наши снапшоты. Если мы удалим снапшот «Apps Installed» то произойдет следующее:
- Во-первых, удаляется копия файла конфигурации, и сам снапшот исчезает из списка.
- Если в данный момент виртуальная машина запущена – AVHD, связанный с этим снапшотом остается, и запись в него продолжается.
- Как только виртуальная машина останавливается (шатдаун или перезагрузка) – все данные из AVHD записываются в предыдущий AVHD, или в VHD, если мы удаляем первый снапшот, а сам AVHD удаляется. Эта операция называется «Объединение» (Merging). Операция объединения может занять определенное время (в зависимости от объемов данных), в течение которого запустить виртуалку нельзя.
При откате к снапшоту «OS Installed» действующий на тот момент AVHD (в составе снапшота «Apps Installed») удаляется, создается новая копия конфигурации и новый AVHD(«Дифференциальный диск AVHD 3»), относящийся, в нашем случае, к самому VHD. Далее, если мы, к примеру, создадим еще один снапшот (для простоты обзовем его «New Snapshot») – то новый AVHD создастся уже на основе «Дифференциального диска AVHD 3»). Таких ветвей может быть и больше – например, от снапшота «OS Installed» может идти и три, и больше ветвей. Операции Delete/Apply при ветвлении происходят так же, как и было описано, но с некоторыми нюансами. К примеру, если мы теперь захотим удалить снапшот «OS Installed» — то он исчезнет из списка, и удалится копия конфигурации, но объединения после останова виртуальной машины не произойдет. Почему? А все очень просто: поскольку от нашего VHD образуются не один, а аж целых два AVHD – перезаписать сам VHD нельзя: если при перезаписи используется AVHD1 – то AVHD3, и соответственно – все, что на него опираются (в нашем случае это AVHD4) при возможном откате на них работать не будут.
Вот еще одно «исключение из правил»: допустим, мы удаляем снапшот «Apps Installed». Как мы видим, своего AVHD у него нет. Поэтому удален будет предыдущий по времени AVHD1.
Если же мы захотим вернуться к снапшоту «Apps Installed» — то создастся новый AVHD на основе AVHD1 (ну то есть новый AVHD2, грубо говоря), а удалится активный на данный момент AVHD4.
Ну и теперь скажу несколько слов в заключение.
Во-первых – как я уже говорил, нужно помнить про «Delete means Apply, Apply means Delete», и думать перед нажатием кнопки, дабы не потерять ничего.
Во-вторых, если виртуальная машина содержит онлайновые снапшоты – ее крайне не рекомендуется экспортировать и переносить на другой сервер. Дело в том, что онлайновый снапшот содержит состояние регистров процессора и содержимое памяти, и применение такого снапшота в другом аппаратном окружении может привести к краху гостевой ОС.
В-третьих, как уже было сказано – снапшоты не рекомендуется использовать в производственной среде. Наверняка вам известно, что для продакшна рекомендуется использовать виртуальные диски фиксированного размера – для того, чтобы избавиться от фрагментации VHD-файла. Создавая же снапшоты, мы искусственно делим наш виртуальный диск на отдельные файлы – VHD и множество AVHD. На высоконагруженных системах это может привести к некоторому падению производительности. Кроме этого, при удалении снапшотов происходит операция объединения, которая тоже может сказаться на общей производительности системы, а к тому же может повысить время простоя при перезагрузках виртуальной машины. К примеру, если вы удалили один или несколько снапшотов на виртуальной машине, а потом потребовалось ее перезагрузить (к примеру – при установке апдейтов), то загрузка ОС не начнется, пока не завершится полностью операция объединения. Поэтому снапшоты можно использовать перед вводом в продакшн, для экономии времени при установке ПО и начальной настройке. После этого все снапшоты нужно удалить, дождаться окончания объединения, и только затем вводить в продакшн.
Еще один небольшой момент: в настройках Hyper-V можно задавать отдельно путь для размещения файлов виртуальных машин и путь для размещения VHD. По умолчанию и то и другое хранится на диске C:. Если для хранения VHD планируется использовать, к примеру, высокоскоростной RAID-массив – необходимо хранить на нем не только VHD, но и файлы виртуальных машин. Дело в том, что при создании снапшотов файлы AVHD будут храниться именно в том месте, которое было выбрано для хранения виртуальных машин. И может получиться так, что сам VHD будет храниться на отдельном дисковом массиве, а куча AVHD будет на диске С:, что не есть хорошо.
На этом я закончу этот пост, и без того уже большой. Прошу прощения за некоторый сумбур, тема при кажущейся простоте немного нетривиальна для объяснения. Для лучшего понимания советую посмотреть скринкаст, с анимированной презентацией и демонстрацией: www.techdays.ru/videos/1490.html
Если хаброобщественность не будет возражать – я могу дать ссылки на другие свои скринкасты и статьи про Hyper-V, дабы не кросспостить и не копипастить. Надеюсь, кого-то моя статья заинтересовала, в любом случае – спасибо заранее.
Бэкап для Linux, или как создать снапшот / Veeam Software corporate blog / Habr
Всем привет! Я работаю в Veeam над проектом Veeam Agent for Linux. С помощью этого продукта можно бэкапить машину с ОС Linux. «Agent» в названии означает, что программа позволяет бэкапить физические машины. Виртуалки тоже бэкапит, но располагается при этом на гостевой ОС.Вдохновением для этой статьи послужил мой доклад на конференции Linux Piter, который я решил оформить в виде статьи для всех интересующихся хабражителей.
В статье я раскрою тему создания снапшота, позволяющего произвести бэкап и поведаю о проблемах, с которыми мы столкнулись при создании собственного механизма создания снапшотов блочных устройств.
Всех заинтересовавшихся прошу под кат!
Немного теории в начале
Исторически так сложилось, что есть два подхода к созданию бэкапов: File backup и Volume backup. В первом случае мы копируем каждый файл как отдельный объект, во втором – копируем всё содержимое тома в виде некоего образа.
У обоих способов есть масса своих плюсов и минусов, но мы рассмотрим их через призму восстановления после сбоя:
- В случае File backup для полноценного восстановления сервера целиком, нам потребуется вначале установить ОС, потом — необходимые сервисы и только после этого восстановить файлы из бэкапа.
- В случае же Volume backup для полного восстановления достаточно просто восстановить все тома машины без лишних усилий со стороны человека.
Очевидно, что в случае Volume backup восстановить систему можно быстрее, а это важная характеристика системы. Поэтому, для себя отмечаем volume backup как более предпочтительный вариант.
Как же нам взять и сохранить весь том целиком? Само собой, простым копированием мы ничего хорошего не добьёмся. Во время копирования на томе будет происходить какая-то активность с данными, в итоге в бэкапе окажутся несогласованные данные. Структура файловой системы будет нарушена, файлы баз данных повреждены, как и прочие файлы, с которыми во время копирования будут производиться операции.
Чтобы избежать всех этих проблем, прогрессивное человечество придумало технологию моментального снимка – снапшота. В теории всё просто: создаём неизменную копию – снапшот – и бэкапим данные с него. Когда бэкап окончен – снапшот уничтожаем. Звучит просто, но, как водится, есть нюансы.
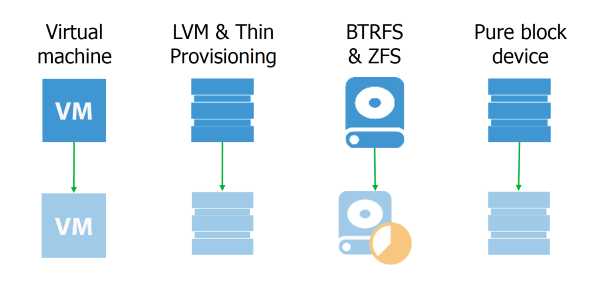
Из-за них было рождено множество реализаций этой технологи. Например, решения на основе device mapper, такие, как LVM и Thin provisioning, обеспечивают полноценные снапшоты томов, но требуют специальной разметки дисков ещё на этапе установки системы, а значит, в общем случае не подходят.
BTRFS и ZFS дают возможность создавать моментальные снимки подструктур файловой системы, что очень здорово, но на данный момент их доля на серверах невелика, а мы пытаемся сделать универсальное решение.
Предположим, на нашем блочном девайсе есть банальная EXT. В этом случае мы можем использовать dm-snap (кстати, сейчас разрабатывается dm-bow), но тут — свой нюанс. Нужно иметь на готове свободное блочное устройство, чтобы было куда отбрасывать данные снапшота.
Обратив внимание на альтернативные решения для бэкапа, мы заметили что они, как правило, используют свой модуль ядра для создания снапшотов блочных устройств. Этим путём решили пойти и мы, написав свой модуль. Решено было распространять его по GPL лицензии, так что в открытом доступе он доступен на github.
How it works — в теории
Снапшот под микроскопом
Итак, теперь рассмотрим общий принцип работы модуля и более подробно остановимся на ключевых проблемах.
По сути, veeamsnap (так мы назвали свой модуль ядра) – это фильтр драйвера блочного устройства.
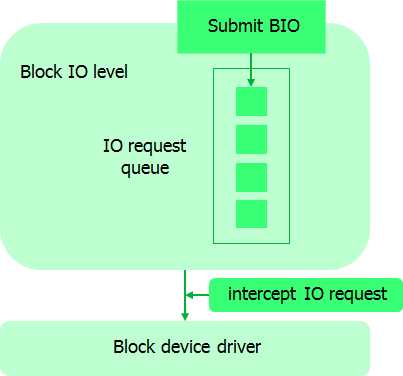
Его работа заключена в перехвате запросов к драйверу блочного устройства.
Перехватив запрос на запись, модуль производит копирование данных с оригинального блочного устройства в область данных снапшота. Назовём эту область снапсторой.
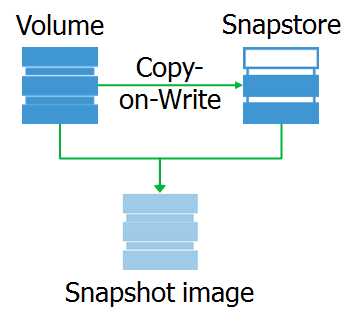
А что такое сам снапшот? Это виртуальное блочное устройство, копия оригинального устройства на конкретный момент времени. При обращении к блокам данных на этом устройстве они могут быть считаны либо со снапсторы, либо с оригинального устройства.
Хочу отметить, что снапшот – это именно блочное устройство, полностью идентичное оригинальному на момент снятия снапшота. Благодаря этому мы можем смонтировать файловую систему на снапшоте и произвести необходимый предпроцессинг.
Например, мы можем получить карту занятых блоков от файловой системы. Самый простой способ это сделать – воспользоваться ioctl GETFSMAP.
Данные о занятых блоках позволяют читать со снапшота только актуальные данные.
Также, можно исключить некоторые файлы. Ну, и совсем опциональное действие: проиндексировать файлы, которые попадают в бэкап, для возможности гранулярного рестора в будущем.
CoW vs RoW
Давайте немного остановимся на выборе алгоритма работы снапшота. Выбор тут не особо обширен: Copy-on-Write или Redirect-on-Write.
Redirect-on-Write при перехвате запроса на запись перенаправит его в снапстору, после чего все запросы на чтение этого блока будут уходить туда же. Замечательный алгоритм для систем хранения, построенных на базе В+ деревьев, таких, как BTRFS, ZFS и Thin Provisioning. Технология стара как мир, но особенно хорошо она проявляет себя в гипервизорах, где можно создать новый файл и писать туда новые блоки на время жизни снапшота. Производительность – отличная, по сравнению с CoW. Но есть жирный минус – структура оригинального устройства меняется, а при удалении снапшота надо скопировать все блоки из снапсторы в оригинальное место.
Copy-on-Write при перехвате запроса копирует в снапстору данные, которые должны подвергнуться изменению, после чего позволяет их перезаписать в оригинальном месте. Используется для создания снапшотов для LVM томов и теневых копий VSS. Очевидно, для создания снапшотов блочных устройств он подходит больше, т.к. не меняет структуру оригинального устройства, и при удалении (или аварии) снапшот можно просто отбросить, не рискуя данными. Минус такого подхода – снижение производительности, так как на каждую операцию записи добавляется пара операций чтение/запись.
Поскольку обеспечение сохранности данных для нас основной приоритет, мы остановились именно на CoW.
Пока всё выглядит просто, поэтому давайте пройдёмся по проблемам из реальной жизни.
How it works — на практике
Согласованное состояние
Ради него всё и задумывалось.
Например, если в момент создания снапшота (в первом приближении можно считать, что создаётся он моментально) в какой-то файл будет производиться запись, то в снапшоте файл окажется недописанным, а значит — повреждённый и бессмысленный. Аналогичная ситуация и с файлам баз данных и самой файловой системой.
Но мы же в 21-м веке живём! Есть же механизмы журналирования, предохраняющие от подобных проблем! Замечание верное, правда, есть важное “но”: эта защита не от сбоя, а от его последствий. При восстановлении в согласованное состояние по журналу незавершённые операции будут отброшены, а значит — потеряны. Поэтому важно сместить приоритет на защиту от причины, а не лечить последствия.
Систему можно предупредить о том, что сейчас будет создан снапшот. Для этого в ядре есть функции freeze_bdev и thaw_bdev. Они дёргают функции файловой системы freeze_fs и unfreeze_fs. При вызове первой система должна сбросить кэш, приостановить создание новых запросов к блочному устройству и дождаться завершения всех ранее сформированных запросов. А при вызове unfreeze_fs файловая система восстанавливает своё нормальное функционирование.
Получается, что файловую систему мы можем предупредить. А что с приложениями? Тут, к сожалению, всё плохо. В то время, как в Windows существует механизм VSS, который с помощью Writer-ов обеспечивает взаимодействие с другими продуктами, в Linux каждый идёт своим путём. На данный момент это привело к ситуации, что задача администратора системы самостоятельно написать (скопировать, украсть, купить, etc) pre-freeze и post-thaw скрипты, которые будут подготавливать их приложение к снапшоту. Со своей стороны, в ближайшем релизе мы внедрим поддержку Oracle Application Processing, как наиболее часто запрашиваемую нашими клиентами функцию. Потом, возможно, будут поддержаны и другие приложения, но в целом ситуация довольно печальна.
Где расположить снапстору?
Это вторая встающая на нашем пути проблема. С первого взгляда проблема не очевидна, но, немного разобравшись, увидим, что это та ещё заноза.
Конечно же, самое простое решение — расположить снапстору в RAM. Для разработчика вариант просто отличный! Всё быстро, очень удобно делать отладку, но есть косяк: оперативка — ресурс ценный, и расположить там большую снапстору нам никто не даст.
ОК, давайте сделаем снапстору обычным файлом. Но возникает другая проблема – нельзя бэкапить том, на котором расположена снапстора. Причина проста: мы перехватываем запросы на запись, а значит, будем и перехватывать свои собственные запросы на запись в снапстору. Кони бегали по кругу, по-научному — deadlock. Следом возникает острое желание использовать для этого отдельный диск, но никто ради нас в сервера диски добавлять не будет. Работать надо уметь на том что есть.
Расположить снапстору удалённо — идея отличная, но реализуема в очень уж узких кругах сетей с большой пропускной способностью и микроскопических латенси. Иначе во время удержания снапшота на машине будет пошаговая стратегия.
Значит, надо как-то хитро расположить снапстору на локальном диске. Но, как правило, всё место на локальных дисках уже распределено между файловыми системами, и заодно надо крепко подумать, как обойти проблему deadlock’a.
Направление для раздумий, в принципе, одно: надо как-то аллоцировать у файловой системы пространство, но с блочным устройством работать напрямую. Решение этой проблемы было реализовано в user-space коде, в сервисе.
Существует системный вызов fallocate, который позволяет создать пустой файл нужного размера. При этом фактически на файловой системе создаются только метаданные, описывающие расположение файла на томе. А ioctl FIEMAP позволяет нам получить карту расположения блоков файла.
И вуаля: мы создаём файл под снапстору с помощью fallocate, FIEMAP отдаёт нам карту расположения блоков этого файла, которую мы можем передать для работы в наш модуль veeamsnap. Далее при обращении к снапсторе модуль делает запросы напрямую к блочному устройству в известные нам блоки, и никаких deadlock’ов.
Но тут есть нюанс. Системный вызов fallocate поддерживается только XFS, EXT4 и BTRFS. Для остальных файловых систем вроде EXT3 для аллокации файла его приходится полностью записывать. На функционале это сказывается увеличением времени на подготовку снапсторы, но выбирать не приходится. Опять таки, работать надо уметь на том что есть.
А что, если ioctl FIEMAP тоже не поддерживается? Это реальность NTFS и FAT32, где нет даже поддержки древнего FIBMAP. Пришлось реализовать некий generic алгоритм, работа которого не зависит от особенностей файловой системы. В двух словах алгоритм такой:
- Сервис создаёт файл и начинает записывать в него определённый паттерн.
- Модуль перехватывает запросы на запись, проверяет записываемые данные.
- Если данные блока соответствуют заданному паттерну, то блок помечается как относящийся к снапсторе.
Да, сложно, да, медленно, но лучше чем ничего. Применяется он в единичных случаях для файловых систем без поддержки FIEMAP и FIBMAP.
Переполнение снапшота
Вернее, заканчивается место, которые мы выделили под снапстору. Суть проблемы в том, что новые данные некуда отбрасывать, а значит, снапшот становится непригоден для использования.
Что делать?
Очевидно, надо увеличивать размер снапсторы. А насколько? Самый простой способ задания размера снапсторы – это определить процент от свободного места на томе (как сделано для VSS). Для тома в 20 TB 10% будет 2TB – что очень много для ненагруженного сервера. Для тома в 200 GB 10% составит 20GB, что может оказаться слишком мало для сервера, интенсивно обновляющего свои данные. А есть ещё тонкие тома…
В общем, заранее прикинуть оптимальный размер требуемой снапсторы может только системный администратор сервера, то есть придётся заставить человака подумать и выдать своё экспертное мнение. Это не соотвествует принципу «It just work».
Для решения этой проблемы мы разработали алгоритм stretch snapshot. Идея состоит в разбиении снапсторы на порции. При этом, новые порции создаются уже после создания снапшота по мере необходимости.
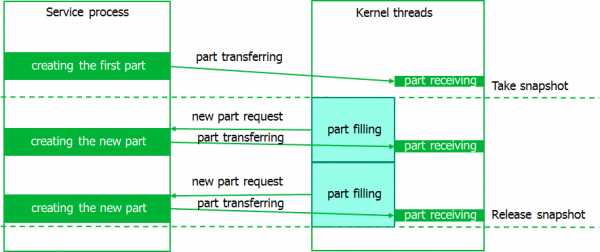
Опять же коротенько алгоритм:
- Перед созданием снапшота создаётся первая порция снапсторы и отдаётся модулю.
- Когда снапшот создан, порция начнёт заполняться.
- Как только половина порции оказывается заполнена, посылается запрос сервису на создание новой.
- Сервис создаёт её, отдаёт данные модулю.
- Модуль начинает заполнять следующую порцию.
- Алгоритм повторяется пока или бэкап не завершится, или пока не упрёмся в лимит использования свободного места на диске.
Важно отметить, что модуль должен успевать создавать новые порции снапсторы по мере необходимости, иначе — переполнение, сброс снапшота и никакого бэкапа. Поэтому, работа такого алгоритма возможна только на файловых системах с поддержкой fallocate, где можно быстро создать пустой файл.
Что делать в других случаях? Пытаемся угадать необходимый размер и создаём всю снапстору целиком. Но по нашей статистике, подавляющее большинство Linux серверов сейчас используют EXT4 и XFS. EXT3 встречается на старых машинах. Зато в SLES/openSUSE можно наткнуться на BTRFS.
Change Block Tracking (CBT)
Инкрементальный или дифференциальный бэкап (кстати, слаще хрен редьки или нет, предлагаю читать тут) – без него нельзя представить ни один взрослый продукт для бэкапа. А чтобы это работало, нужен CBT. Если кто-то пропустил: CBT позволяет отслеживать изменения и записывать в бэкап только изменённые с последнего бэкапа данные.
Свои наработки в этой области есть у многих. Например, в VMware vSphere эта функция доступна с 4-ой версии в 2009 году. В Hyper-V поддержка внедрена с Windows Server 2016, а для поддержки более ранних релизов был разработотан собственный драйвер VeeamFCT ещё в 2012-м. Поэтому, для нашего модуля мы не стали оригинальничать и использовали уже работающие алгоритмы.
Коротенько о том, как это работает.
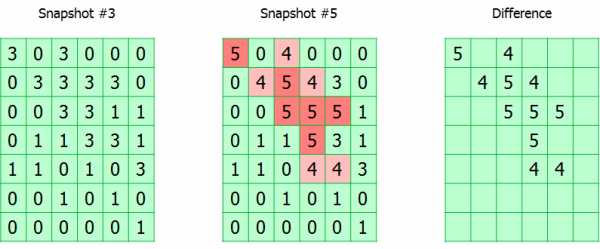
Весь отслеживаемый том разбит на блоки. Модуль просто отслеживает все запросы на запись, помечая изменившиеся блоки в таблице. Фактически, таблица CBT – это массив байт, где каждый байт соответствует блоку и содержит номер снапшота, в котором он был изменён.
Во время бэкапа номер снапшота записывается в метаданные бэкапа. Таким образом, зная номера текущего снапшота и того, с которого был сделан предыдущий успешный бэкап, можно вычислить карту расположения изменившихся блоков.
Тут есть два нюанса.
Как я сказал, под номер снапшота в таблице CBT выделен один байт, значит, максимальная длина инкрементальной цепочки не может быть больше 255. При достижении этого порога таблица сбрасывается и происходит полный бэкап. Может показаться неудобным, но на самом деле цепочка в 255 инкрементов – далеко не самое лучшее решение при создании бэкап-плана.
Вторая особенность – это хранение CBT таблицы только в оперативной памяти. А значит, при перезагрузке целевой машины или выгрузке модуля она будет сброшена, и опять-таки, понадобится создавать полный бэкап. Такое решение позволяет не решать проблему старта модуля при старте системы. Кроме того, отпадает необходимость сохранять CBT таблицы при выключении системы.
Проблема производительности
Бекап — это всегда хорошая такая нагрузка на IO вашего оборудования. Если на нём и так хватает активных задач, то процесс резервного копирования может превратить вашу систему в этакого ленивца.
Давайте посмотрим, почему.
Представим, что сервер просто линейно пишет какие-то данные. Скорость записи в таком случае максимальна, все задержки минимизированы, производительность стремится к максимуму. Теперь добавим сюда процесс бэкапа, которому при каждой записи надо ещё успеть выполнить алгоритм Copy-on-Write, а это дополнительная операция чтения с последующей записью. И не забывайте, что для бэкапа надо ещё читать данные с этого же тома. Словом, ваш красивый linear access превращается в беспощадный random access со всеми вытекающими.
С этим явно надо что-то делать, и мы реализовали конвейер, чтобы обрабатывать запросы не по одному, а целыми пачками. Работает это так.
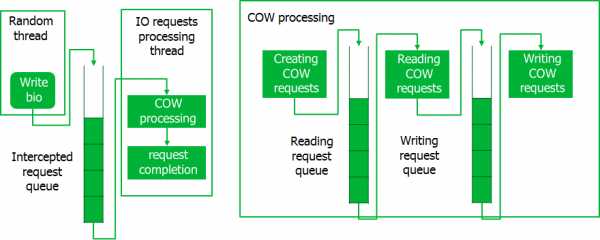
При перехвате запросов они укладываются в очередь, откуда их порциями забирает специальный поток. В это время создаются CoW-запросы, которые также обрабатываются порциями. При обработке CoW-запросов вначале производятся все операции чтения для всей порции, после чего выполняются операции записи. Только после завершения обработки всей порции CoW-запросов выполняются перехваченные запросы. Такой конвейер обеспечивает обращения к диску крупными порциями данных, что минимизирует временные потери.
Throttling
Уже на стадии отладки всплыл ещё нюанс. Во время бэкапа система становилась неотзывчивой, т.е. системные запросы ввода-вывода начинали выполняться с большими задержками. Зато, запросы на чтение данных со снапшота выполнялись на скорости, близкой к максимальной.
Пришлось немного придушить процесс бэкапа, реализовав механизм тротлинга. Для этого читающий из образа снапшота процесс переводится в состояние ожидания, если очередь перехваченных запросов не пуста. Ожидаемо, система ожила.
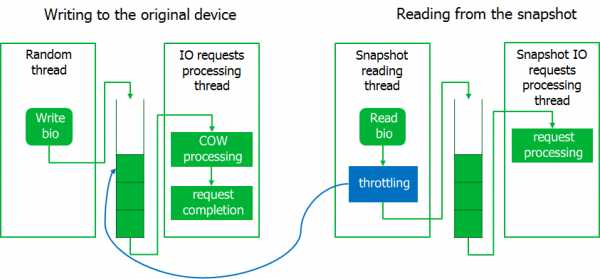
В результате, если нагрузка на систему ввода-вывода резко возрастает, то процесс чтения со снапшота будет ждать. Тут мы решили руководствоваться принципом, что лучше мы завершим бэкап ошибкой, чем нарушим работу сервера.
Deadlock
Я думаю, надо немного подробней объяснить, что это такое.
Уже на этапе тестирования мы стали сталкиваться с ситуациями полного повисания системы с диагнозом: семь бед – один ресет.
Стали разбираться. Выяснилось, что такую ситуацию можно наблюдать, если например создать снапшот блочного устройства, на котором расположен LVM-том, а снапстору расположить на том же LVM-томе. Напомню, что LVM использует модуль ядра device mapper.
В данной ситуации при перехвате запроса на запись, модуль, копируя данные в снапстору, отправит запрос на запись LVM-тому. Device mapper перенаправит этот запрос на блочное устройство. Запрос от device mapper-а снова будет перехвачен модулем. Но новый запрос не может быть обработан, пока не обработан предыдущий. В итоге, обработка запросов заблокирована, вас приветствует deadlock.
Чтобы не допустить подобной ситуации, в самом модуле ядра предусмотрен таймаут для операции копирования данных в снапстору. Это позволяет выявить deadlock и аварийно завершить бэкап. Логика здесь всё та же: лучше не сделать бэкап, чем подвесить сервер.
Round Robin Database
Это уже проблема, подкинутая пользователями после релиза первой версии.
Оказалось, есть такие сервисы, которые только и занимаются тем, что постоянно перезаписывают одни и те же блоки. Яркий пример – сервисы мониторинга, которые постоянно генерируют данные о состоянии системы и перезаписывают их по кругу. Для таких задач используют специализированные циклические базы данных (RRD).
Выяснилось, что при бэкапе таких баз снапшот гарантированно переполнится. При детальном изучении проблемы мы обнаружили недочёт в реализации CoW алгоритма. Если перезаписывался один и тот же блок, то в снапстору каждый раз копировались данные. Результат: дублирование данных в снапсторе.
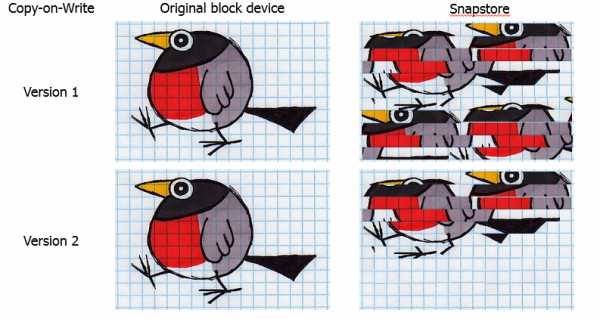
Естественно, алгоритм мы изменили. Теперь том разбит на блоки, и данные копируются в снапстору блоками. Если блок уже был один раз скопирован, то повторно этот процесс не производится.
Выбор размера блока
Теперь, когда снапстора разбита на блоки встает вопрос: а какого, собственно, размера делать блоки для разбиения снапсторы?
Проблема двоякая. Если блок сделать большим, им легче оперировать, но при изменении хотя-бы одного сектора, придётся отправить весь блок в снапостору и, как следствие, повышаются шансы на переполнение снапсторы.
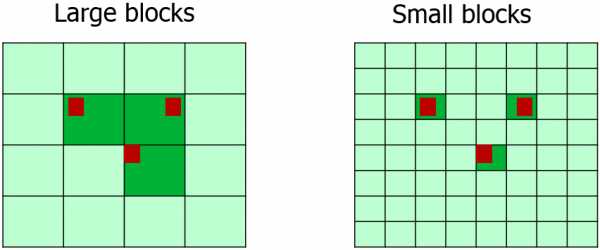
Очевидно, что чем меньше размер блока, тем больший процент полезных данных отправляется в снапстору, но как это ударит по производительности?
Правду искали эмпирическим путём и пришли в результату в 16KiB. Также отмечу, что в Windows VSS тоже используются блоки в 16 KiB.
Вместо заключения
На этом пока всё. За бортом оставлю множество других, не менее интересных проблем, таких, как зависимость от версий ядра, выбор вариантов распространения модуля, kABI совместимость, работа в условиях бекпортов и т.д. Статья и так получилась объёмной, поэтому я решил остановиться на самых интересных проблемах.
Сейчас мы готовим к релизу версию 3.0, код модуля лежит на github, и каждый желающий может использовать его в рамках GPL лицензии.
снапшот — Викисловарь
Содержание
- 1 Русский
- 1.1 Морфологические и синтаксические свойства
- 1.2 Произношение
- 1.3 Семантические свойства
- 1.3.1 Значение
- 1.3.2 Синонимы
- 1.3.3 Антонимы
- 1.3.4 Гиперонимы
- 1.3.5 Гипонимы
- 1.4 Родственные слова
- 1.5 Этимология
- 1.6 Фразеологизмы и устойчивые сочетания
- 1.7 Перевод
- 1.8 Библиография
| В Викиданных есть лексема снапшот (L164199). |
Морфологические и синтаксические свойства[править]
| падеж | ед. ч. | мн. ч. |
|---|---|---|
| Им. | снапшо́т | снапшо́ты |
| Р. | снапшо́та | снапшо́тов |
| Д. | снапшо́ту | снапшо́там |
| В. | снапшо́т | снапшо́ты |
| Тв. | снапшо́том | снапшо́тами |
| Пр. | снапшо́те | снапшо́тах |
снап-шо́т
Существительное, неодушевлённое, мужской род, 2-е склонение (тип склонения 1a по классификации А. А. Зализняка).
Корень: --.
Произношение[править]
- МФА: [snɐˈpʂot]
Семантические свойства[править]
Значение[править]
- информ. копия файлов и каталогов файловой системы на определённый момент времени ◆ Отсутствует пример употребления (см. рекомендации).
Синонимы[править]
Антонимы[править]
Гиперонимы[править]
Гипонимы[править]
Родственные слова[править]
| Ближайшее родство | |
Этимология[править]
От англ. snapshot.
Фразеологизмы и устойчивые сочетания[править]
Перевод[править]
| Список переводов | |
Библиография[править]
Для улучшения этой статьи желательно:
|
что это такое? Как сделать снапшот?
Стандартный набор снимков, в который входит не менее шести фотографий, – именно это представляет собой снапшот. Что это такое, сегодня знают в основном только профессиональные фотографы, но понятие давным-давно уже ушло за пределы этой области.
При этом в зависимости от того, где именно делается снапшот, изменяется и суть этого понятия, а также то, как он должен выполняться.
Фотография

В профессиональной фотографии снапшоты делаются безо всякого макияжа, обработки, а также явно выраженного позирования. Достаточно просто подобрать мягкое освещение, ровную заливку, а также обеспечить минимум теней. На фоне используется нейтральный цвет, на котором отсутствует какой-либо рисунок. Именно так профессиональный специалист делает снапшот. Что это такое на самом деле и какие имеет преимущества, знают в основном мастера, в то время как начинающие подобные технологии не используют.
Стоит отметить, что достаточно часто snaphot включает в себя более объемный набор фотографий, однако такое применение является сугубо индивидуальным. С точки зрения преимущественного большинства экспертов, какие-либо дополнительные снимки не несут никакой дополнительной информации для мастера, поэтому именно шесть снимков предусматривает собой универсальную основу, в которой находятся все требуемые сведения. Все, что превышает это значение, считается простой раскруткой клиента на дополнительную оплату или же обеспечение каких-либо узкоспециализированных стандартов агентства.
Как определить?
Различать эти понятия можно достаточно просто, то есть нет ничего сложного в том, чтобы определить, для чего будет делаться более объемный снапшот. Что это такое, вам расскажут, но вот для чего делать больше шести снимков, не смогут четко объяснить, рассказывая только о том, что это действительно необходимо и такой-то конкретный фотограф может выполнить такую работу. Это явно говорит о том, что речь идет о стандартной раскрутке вас на дополнительную оплату.
Если же вам достаточно спокойно и четко объяснили полный перечень, а также основные требования к тому, какой должен делаться снапшот, что это такое, и при этом без всякой навязки сказали, что сделать подобные снимки вы сможете там, где сами захотите, то в таком случае вполне вероятно, что в проведении такого снимка действительно есть реальная необходимость.
Зачем они нужны?

Любой человек, который даже только начал заниматься фотографией, прекрасно понимает, что правильное наложение одежды и макияжа, выбор позы, ракурса, света и всего остального в конечном итоге позволяет сделать такой снимок, на котором и сам человек узнает себя с трудом. Именно по этой причине для того человека, который разбирается в этой сфере, всевозможные эффектные снимки не несут практически никакой информативности.
Если человек собирается нанимать на работу модель, а не команду визажистов, фотографов и ретушеров, то его в любом случае будет интересовать именно снапшот. Что это такое, мы с вами уже рассмотрели.
Действительно качественные снимки позволят специалисту, который будет нанимать вас на работу, понять, что вы собой представляете и что он может с вами сделать. Если вас интересует, как сделать снапшот, просто обратитесь в любое профессиональное агентство.
Можно ли сделать самому?

Стоит отметить, что многие люди даже ищут, как сделать снапшот самостоятельно, и это действительно возможно. Для этого вполне достаточно использовать стандартную цифровую «мыльницу», а также иметь специализированный штатив, пусть даже не самый дорогой. В данном случае достаточно важно отметить тот факт, что ни в коем случае не предусматривается использование мобильного телефона. Даже если он самый современный и продвинутый.
Конечно, можно пробовать использовать функцию задержки съемки, чтобы бегать постоянно на место и ждать, пока фотоаппарат сделает снимок, но это очень тяжелая работа. Гораздо проще просто взять себе помощника или помощницу и объяснить, как правильно делается снапшот.
Snapshot в Minecraft
Более «приземленные» пользователи достаточно часто задаются также вопросом о том, что такое снапшоты Minecraft, ведь здесь это понятие имеет абсолютно иное значение. В данном случае snapshot представляют собой предварительные сборки игры, которые выкладываются разработчиками для того, чтобы они могли их беспрепятственно тестировать. В преимущественном большинстве случаев используется в конечном итоге несколько версий таких снапшотов, из которых собирается абсолютно новая версия игры.
На сегодняшний день в Рунете можно найти большое количество специализированных сайтов, которые имеют основную направленность именно на рассмотрение всевозможных новых снапшотов, то есть предварительных серверов. Вы можете следить за новостями на таких ресурсах, просматривать обзоры более опытных игроков и определять, какие именно «снапы» для вас будут более интересными.
Snapshot в Aliexpress

Некоторые пользователи достаточно часто также ищут, что такое снапшот в «Алиэкспресс». На самом деле, если вы видите в ссылке на этот сайт слово snapshot – это значит, что вы будете просматривать фотографию определенного товара, которой она была на момент его размещения в сети.
На ссылке такого типа будет то изображение, которое продавец загружал изначально на сайт. Такие ссылки нужны людям для того, чтобы посмотреть на товарную позицию в том случае, если продавец решит удалить или же заменить товар.
Ведь не стоит забывать о том, что достаточно часто на получение товара может уйти достаточно большое количество времени, на протяжении которого может произойти что угодно. К примеру, нередко случается так, что после заказа определенного товара приходится ждать его несколько месяцев, а в течение этого времени владелец товарной позиции может уже ее давным-давно удалить. Но вам же после покупки все равно захочется понять, действительно ли вам прислали именно то, что вы заказывали.
Таким образом, вы просто открываете сохраненный «снап» и смотрите, соответствует ли полученная вами посылка тому, что вы изначально покупали. Помимо всего прочего, если вы знаете, как сделать снапшот на «Алиэкспресс», вы можете опубликовать ссылку на купленный вами товар.
Снапшоты в VMware vSphere и все о них
Всем привет сегодня хочу затронуть вопрос снапшотов (snapshots) в VMware vSphere. Поговорим, что это такое, из чего состоит, плохо это или хорошо и где применяется. Думаю это актуальный вопрос и многие хотели бы в нем разобраться, да и я освежу это в памяти, и что то может переосмыслить.
Что такое snapshot
Снапшот это сохранение состояния виртуальной машины в определенной точке, необходимой именно вам, его еще называют снимком виртуальной машины.
Где применим снапшот
Применяют его чаще всего при резервном копировании виртуальных машин либо в тестовых целях, для тестирования софта или обновления например, чтобы можно было потом быстро откатиться если что то пошло не так.
Как создать снапшот в VMware vSphere
Сама процедура очень простая и сейчас будет описана. Если же вы захотите ее автоматизировать, то советую почитать Как создать snapshot виртуальной машины по расписанию в VMware vCenter 5.5.
сразу подчеркиваю shapshot это не замена бэкапа, запомните это
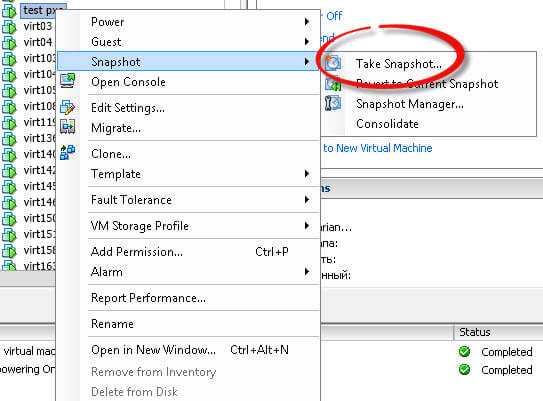
Вибираете любую виртуальную машину, щелкаете по ней правым кликом и из контекстного меню выбираете Snapshot > Take Snapshot
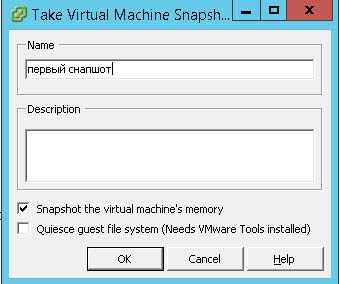
В следующем окне задаем имя snapshot и при желании описание в поле description/ Обратите внимание на две возможные галки
Описание параметров снимка
- Snapshot the virtual machine's memory > данная опция нужна для того, чтобы во время снятия snapshot esxi виртуалки было состояние оперативной памяти, что при откате даст работающую виртуальную машину. Если вы ее снимите, то вернувшись из снапшота виртуальная машина будет выключена, но зато такой снапшот будет создаваться быстрее, так как нет необходимости сохранять оперативную память в файл, особенно если память большая и постоянно обновляется.
- Quiesce guest file system (need VMware Tools installed) > Это процесс при котором подготавливаются данные на виртуальном диске в состояние требуемое для резервного копирования. Заморозить гостевую файловую систему (требуется установка VMware Tools и ее драйвер Sync Driver) позволяет гарантировать, что данные гостевой операционной системы останутся не поврежденными в снимке.
В итоге VMware Tools с помощью VMware Snapshot Provider запускает создание VSS snapshot внутри гостевой ОС. После чего все VSS writers (смотрим их командой "vssadmin list writers") в гостевой ОС получают запрос и подготавливают соответствующие приложения к бэкапу (происходит запись всех транзакций из памяти на диск). Когда все VSS writers заканчивают работу, они сообщают службе VMware Tools через VMware Snapshot Provider, который, в свою очередь, говорит VMware о том, что снапшот можно снять.
Таким образом все приложения резервного копирования для VMware vSphere используют следующие комбинации при отдании команды на создание снапшота VMware (заметьте, что процесс непосредственно создания снапшота целиком и полностью контролируется самой VMware)
Если делать бэкап без опции Quiesce guest file system, то могут быть большие проблемы при восстановлении контроллера домена или Exchange сервера.
Вот как выглядит структура файлов до снятия снапшота в VMware vSphere. Более подробно о форматах esxi файлов читайте по ссылке.
Теперь посмотрим, что изменится после снятия снимка виртуальной машины esxi 5.5. Как видите добавились файлы с форматом vmsn и добавленным в название 000001. Это и есть жесткий диск новых данных после снапшота.
Если посмотреть на эти же файлы в консоли ssh, то этот файл на самом деле состоит из четырех. У меня на скриншоте два снапшота и в сумме они занимают 8 фалов.
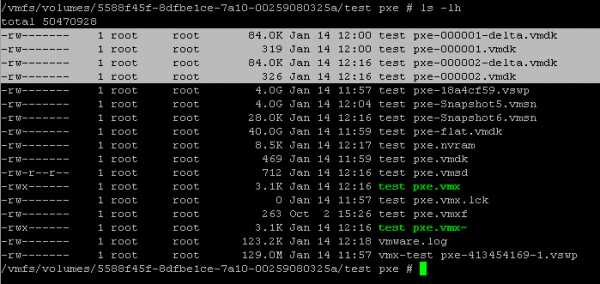
- <name VM>-[шесть цифр]-delta.vmdk - файл данных диска отличий от базового диска
- <name VM>-[шесть цифр].vmdk - заголовочный файл
- <name VM>.vmsd - текстовый файл с параметрами снапшота (связи в дереве, SCSI-нода, время создания и т.п.)
- <name VM>.vmsn - файл с сохраненной памятью виртуальной машины
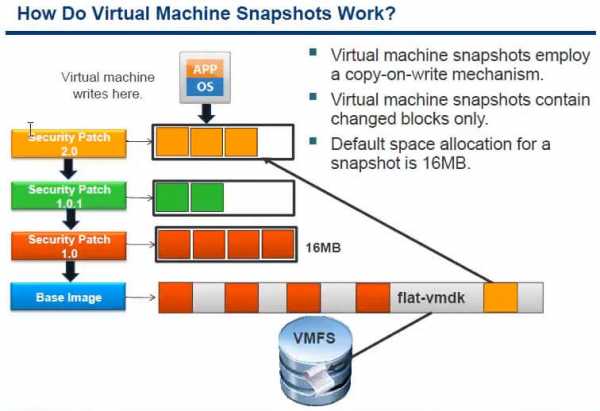
Как можно предположить основной файл это delta, который включает в себя все отличительные данные после снапшота от основного виртуального диска. Данный виртуальный диск состоит из блоков данных хранимых в формате redo-логов (или просто дочерний диск - child disk). Он же sparse-диск, то есть диск, который использует технологию Copy-On-Write (COW) при работе с данными. Идея технологии copy-on-write — при копировании областей данных создавать реальную копию только когда ОС обращается к этим данным с целью записи. Таким образом, этот виртуальный диск содержит только измененные от родительского диска области данных (delta).
файл.vmsd. Это текстовый файл, открыв в редакторе вы увидите все отношения между родительским и дочерними дисками, а также другую интересную информацию
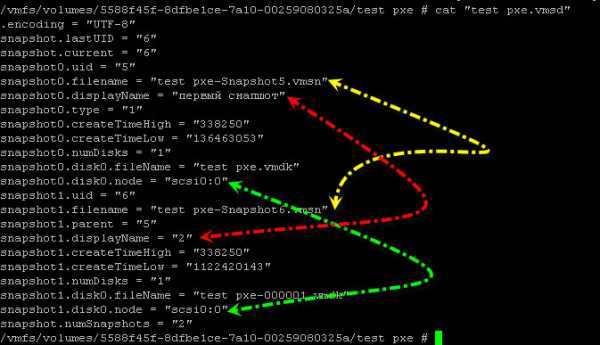
Хочу напомнить, что снапшоты лежат вместе с виртуальной машиной но их расположение можно поменять.
В гостевой ос
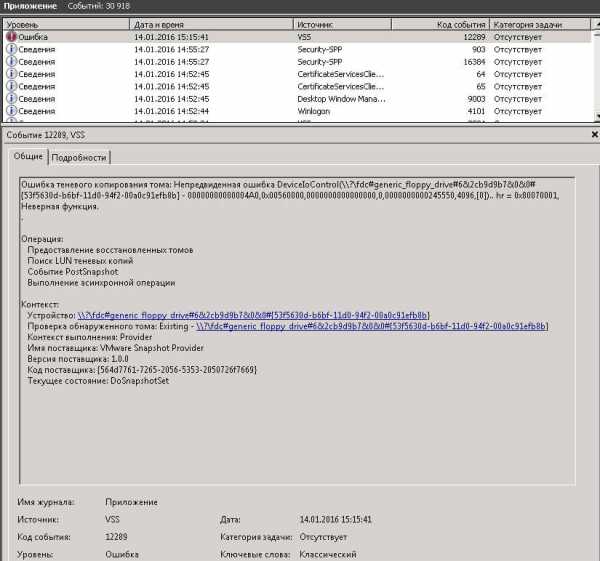
Что вы обнаружите например в событиях гостевой системы при создании снапшота без галки Snapshot the virtual machine's memory и включенной на Quiesce guest file system. Вы в просмотре событий, в журнале Приложения обнаружите ошибку VSS с кодом 12289 (Ошибка теневого копирования тома: Непредвиденная ошибка DeviceIoControl). Можете на нее забить, так как она происходит из за флоппи диска в конфигурации виртуальной машины.
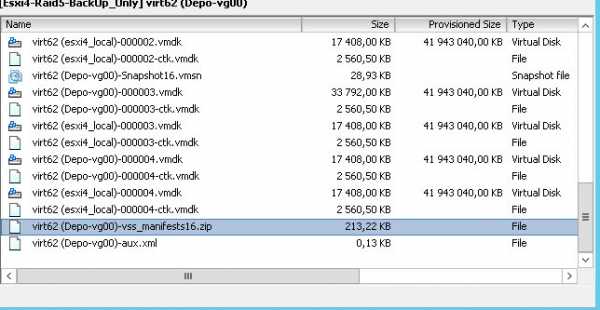
так же если посмотреть через клиента VMware vSphere датастор на котором лежит виртуалка то вы обнаружите файл архив vss_manifests*.zip с конфигами с описанием всех найденных VSS writers в гостевой ОС.
Содержимое vss_manifests*.zip.
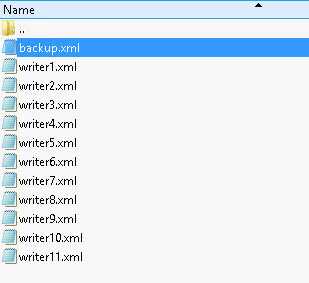
если в архиве vss_manifests.zip только файл backup.xml — это означает, что снапшот по факту был сделан без использования VSS
Также стоит добавить некоторые требования к Quiesce guest file system
- Поддержка Операционной системой консистентных снимков (VSS)
- VSS компоненты VMware Tools установлены
- Отсутствие динамических дисков внутри гостевой машины (Если внутри гостевой системы будет присутствовать хоть один динамический диск — не важно системный он или нет, то VSS задействован не будет. Снапшот будет создаваться успешно, но vss_manifests.zip будет пустым, как и логи событий внутри гостевой ОСи. Это правило действует для гостевых ОСей Windows 2008 и выше)
- Должна работать служба VSS в гостевой ОС
VSS- это сервис, который всего навсего перед бэкапом заставляет базу данных записать все транзакции на диск, далее БД приостанавливает свою работу, затем создаётся теневая копия тома, на что уходит несколько секунд, Далее БД продолжает свою работу в обычном режиме, а бэкап сливается уже с теневой копии. В VMWare теневая копия не создаётся, а создаётся delta vdmk, при этом исходный vdmk становится доступным на чтение и содержит консистентные данные, что позволяет его скопировать в качестве бэкапа.
Чем плохи снапшоты
На своей практике могу точно сказать, что минусов в разы больше чем плюсов.
Плюсы снапшотов
- Возможность тестирования новых настроек или обновлений с возможностью легкого отката
- Резервное копирование виртуальных машин на лету без остановки
Такие снапшоты делаются на небольшой промежуток времени, до суток. Потестили и удалили.
Минусы снапшотов
- snapshot быстро растут особенно при часто обновляемых данных. Растут они блоками по 16 мб. Если у вас например приложение СУБД, которое имеет много транзакций, то оно заполонит ваш датастор очень быстро, и может получиться так что на нем кончится место и виртуальная машина может перестать работать.
- Еще большой проблемой являются длинные цепочки снапшотов, сделанных на разных этапах настройки, штук так по 15 или 20. Все это вызывает торможение виртуальной машины и хранилище отжирая лишние iops. Чем больше у вас цепочка тем дольше по ней идти до последнего снимка.
- Так же когда снапшот делает или удаляется хранилище испытывает дополнительную нагрузку, так как на датастор сбрасывается память и снимок
- Из за снапшотов вы не сможете использовать Fault Tolerance или Storage VMotion, так как привязаны к хранилищу с вашими snapshot.
- Вы не сможете расширить виртуальный диск со снапшотом
Ну думаю вы поняли, что в продакшине их лучше не делать, по возможности сразу их удаляйте, а если уж они у вас есть, то не делайте их более 3
Консолидация и удаление снапшотов
Удаление snapshot vmware
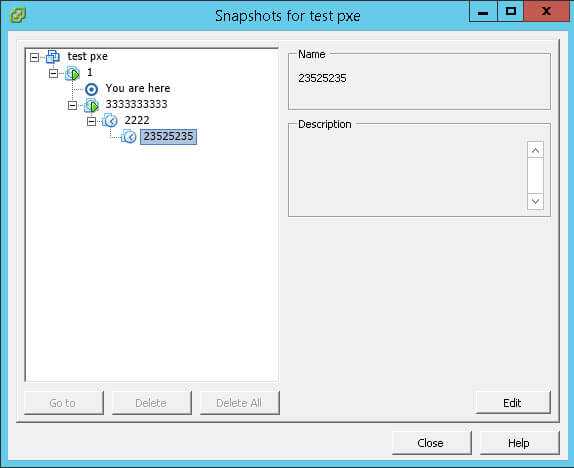
И так рассмотрим процедуру удаления снапшота. Выше мы узнали, что это снимки это зло, и вот еще почему. Не совсем понятное поведение снапшота при его удалении и слиянии с основным виртуальным диском vm машины. Для удаления и слияния вам потребуется свободное место на вашем сторадже VMFS, это еще более актуально когда снимков несколько. Выше я привет снапшот как это может выглядеть. Предположим у вас виртуалка с тремя снимками вот таких вот размеров.
Вы допустим хотите удалить все снапшоты и жмакаете Delete All в Snapshot Manager, далее идет вот такая операция Snapshot 3 сливается со Snapshot 2, но при этом сам Snapshot 3 остается на томе VMFS
В итоге первого шага мы получаем уже 90 гб (60+30). Теперь Snapshot 2 который весит уже 50 гб сливается с Snapshot 1, при этом Snapshot 2 и 3 не удаляются пока. Из этого следует что у нас уже занято 140 гб на хранилище.
Как только результирующий Snaphot 1 в 60 гб сольется с основным виртуальным диском при этом сам виртуальный диск flat в размере не меняется, поскольку он фиксирован (изменяется только содержимое блоков). И только затем все снапшоты удаляются (все 140 ГБ).
так что видите запас нужно всегда иметь, минимум 10 процентов.
Консолидация snapshot vmware
И так consolidation или консолидация, это по сути удаление снапшота, чаще всего оставленного каким нибудь средством резервного копирования, например veeam. Процесс consolidation vm я уже описывал, там все просто, но не понятно на сколько это влияет на датастор в плане производительности.
Что влияет на время консолидации в виртуальной машине
- Размер delta-дисков - очень важный параметр. Чем больше данных в дельта-диске, тем дольше их нужно применять к основному (базовому) диску.
- Число снимков и их размеры. Чем их больше, тем все будет дольше идти по времени. Кроме того, при нескольких снапшотах консолидация происходит в несколько этапов, описано выше.
- Производительность подсистемы хранения, включая FC-фабрику, Storage Processor хранилищ, LUN (число дисков в группе, тип RAID массива).
- Тип данных в файлах снапшотов (нули или случайные данные).
- Нагрузка на хост-сервер ESXi при создании снапшота.
- Нагрузка виртуальной машины на подсистему хранения в процессе консолидации. Например, почтовый сервер, работающий на полную мощность, может очень долго находится в процессе консолидации снапшотов.
Хочется подчеркнуть, что процесс консолидации - это очень требовательный к подсистеме ввода-вывода процесс, поэтому не рекомендуется делать это в рабочие часы, когда производственные виртуальные машины нагружены.
Замирание stun виртуальной машины в VMware vSphere
Если вы как и я долго уже работаете с гипервизором Vmware ESXI 5.5, то наверняка обращали внимание, что бывают случаи, что виртуалка подвисает на какое то время, или дико тормозит, а потом работает как ни в чем не бывало. За это в vmware отвечает параметр stun или как мы выше смотрели quiescence. Когда это происходит виртуалка не может ничего делать, она чаще всего падает по пингу и недоступна, и перестает отвечать на операции ввода/вывода. Если сказать по простому то ее как будто поставили на паузу, а на уровне ввода-вывода совершаются только операции, касающиеся выполняемой задачи (например, закрытие прежнего VMDK-диска и переключение операций чтения-записи на новый диск при операциях со снапшотами).
Параметр Stun в виртуальной машины нужен, в большинстве случаев, для того, чтобы сделать ее на время изолированной от окружающего мира для выполнения значимых дисковых операций, например, консолидация. Это может занимать несколько секунд (и даже десятков), но часто это происходит на время около секунды и даже меньше, все зависит от нагрузки хранилища, у меня бывали случаи, что если виртуалка толстая и снапшот здоровый, время stun доходило и до минуты, что сразу вызывало бурю паники, что у нас все сломалось и что вообще блин происходит, паникеры одним словом, просто не знающие как это работает.
Когда может быть заметен stun vm машины
- Во время выполнения процедуры приостановки виртуальной машины (suspend). Тут происходит такое подмораживание, чтобы скинуть память VM на диск, после чего перевести ее в приостановленное состояние.
- Ну как все уже поняли во время создания снапшота, нужно закрыть старый диск и начать писать в новый.
- Консолидация (удаление) снапшота, подробно описано выше.
- При выполнении миграции с помощью vMotion. Слегка напомню данный механизм, во первых оперативная память передается от одной машины к целевой VM без подмораживания, но затем происходит такой же stun, как и при операции suspend, с тем только отличием, что маленький остаток памяти (минимальная дельта) передается не на диск, а по сети. После этого происходит операция resume уже на целевом хосте. Пользователь этого переключения, как правило, не замечает, так как время этого переключения очень жестко контролируется и чаще всего не достигает 1 секунды. Если память гостевой ОС будет меняться очень быстро, то vMotion может затянуться именно во время этого переключения (нужно передать последнюю дельту).
- Горячая миграция хранилищ Storage vMotion. Здесь stun случается дважды: сначала vSphere должна поставить Mirror Driver, который будет реплицировать в синхронном режиме операции ввода-вывода на целевое хранилище. При постановке этого драйвера происходит кратковременный stun (нужно также закрыть диски). Но и при переключении работы ВМ на второе хранилище происходит stun, так как нужно удалить mirror driver, а значит снова пере открыть диски уже на целевом хранилище.
Думаю вы теперь чуть больше представляете что такое снапшот и как и для чего он нужен.
Материал сайта pyatilistnik.org
Моя борьба со snapshot’ами | vMind.ru
Пару дней потратил на зачистку снапшотов в своей инфраструктуре, так как наши администраторы серверов используют снапшоты как бэкапы и хранят их по несколько месяцев. Решил поделиться опытом с нашими читателями.
Снапшоты
Описывать что такое снапшоты не буду — дам набор ссылок:
Как определить у каких машин есть снапшоты?
Предложу следующие варианты (гуёвые):
- Пробежать по каждой VM, по правой кнопке мыши Snapshot-Snapshot Manager
- Поставить утилиту VMware Guest Console и переключиться на режим Snapshot Manager
- Воспользоваться утилитой Trilead VMX, которая нам поможет в дальнейшем
- Использовать утилиту RVtools, закладка vSnapshots.
- Storage View в vClient (подсказывают в комментариях).
Проблемы со снапшотами
Первая проблема — это ошибки удаления/создания снапшотов, решилась запуском описанной выше процедуры консолидации снапшотов.
Вторая проблема, потрепавшая нервы — это проблема «зависания» на 99%, как при консолидации, так и при удалении. Выглядит она, как часами наблюдаемый прогресс-бар в состояни 99%.
Для понимая, что процесс идёт, VMware рекомендует мониторить наличие delta-файлов через команды консоли в этой статье.
Я же воспользовался Trilead VMX.
В разделе DataCenter добавляем хосты и находим нужную виртуалку со снапшотами, по правой мышке кликаем на Locate Files…
В проводнике файлов видим delta-файлы, а также время последней модификации файлов. Не забываем прибавить временную зону. При обновление панели убеждаемся, что с файлами в текущий момент идут операции.
Для оценки какую угрозу представляют снапшоты сортируем по размеру и видим печальную картину. В-третьих, не забудьте, что свободного места на хранилище должно быть не меньше самого большого снапшота, до 4.0u2 требовалось для удаления снапшотов места в размере суммы снапшотов.
Проблема четвертая, скорее частная, чем общая, при удалении снапшотов резко растёт лог БД vim_vcdb — гигабайты в минуту, что приводит к его переполнению и остановке vCenter. К сожалению, советы эти мне не помогли. Проблема существенная, так как может происходит во время операции по резервному копированию виртуальных машин. Дальнейшее решение по этой проблеме в комментариях к статье.
Выводы
Будьте осторожны в использовании снапшотов, проблемы могут вылезти в различных местах: от остановки виртуальных машин по причине заполнения места на хранилищах до остановки vCenter. Следуйте рекомендациям лучших вмвареводов…